江湖小白之一起学Python (十二)开发视频网之获取m3u8真实播放地址
雨一直下,气氛还算融洽……,我这边下了一周的雨了,趁着目前有个把小时的间歇时间,赶紧接着上一篇更一波,哎,时间就是这么不够用,来吧,抓紧时间今天来实现一下提取m3u8真实的播放地址,实现上篇页面展示的在线播放功能.
既然要获取地址,首先还是得跟踪下目标网站的页面代码,把流程搞懂了,代码就好写了,具体操作这里就不多说了,之前的内容讲过,这里我们就把分析的结果提出来:

我们可以看到他是通过JS渲染后加载了一个iframe框架,如果我们直接查看源代码的话是没有这个内容的,那怎么获取这个链接地址呢,我们看下源代码:
![]()
找了半天没找到播放地址,但找到了这段JS,我们打开看下:
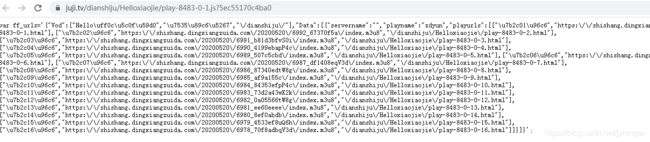
解析一下好看点:

果然,这段JS就是放视频地址的文件,它这里输出是中文转义过了,playname是播放的云接口,比如高清云,云播3什么什么的,playurls里是集合,每个集合第1个参数是集数,第2个就是视频播放地址,第3个是它对应的播放网址,这里其实有想法的同学可以按自己的方式去提取,这里包含了这个电视剧所有的剧集数,我们再看看这个播放地址是不是正确的,我们打开源网站查看下视频链接:
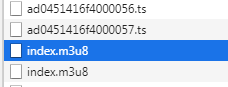
我们看到这里有2个index.m3u8,打开第1个内容看看:

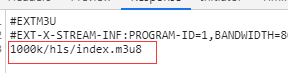
第2个再看看:

上面可以看出,第2个才是我们想要的真实的m3u8地址:

由此可以看出,这真实的m3u8地址是通过一次访问js中给出的https://shishang.dingxiangzuida.com/20200520/6979_4533ef88/index.m3u8,在获取内容后拼接后得到真实的地址,但这里有点区别,我们通过JS获取的网址:https://shishang.dingxiangzuida.com/20200520/6979_4533ef8uQ6h/index.m3u8,这里6979_4533ef8uQ6h多了后面一段文字,如果直接访问这个链接是找不到文件的,
![]()
它是内部通过https://www.juji.tv/Player/dp.html?v=转换后得到的真实地址:
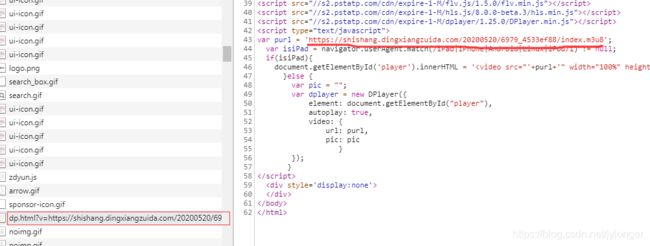
通过上面的仔细分析,我们搞懂了它执行及获取真实地址的方法,那接下来我们就通过代码来实现提取从而获得真实的视频播放地址,下面贴上代码部分:
#获取m3u8地址
def get_video_m3u8(self,videourl,videoname):
#赋值给全局变量值
self.videourl = videourl
self.videoname = videoname
#截取网址域名部分
domainurl=re.search('http[s]?://[-\w.]+', videourl).group()
#请求视频播放网址
r = requests.get(url=videourl, timeout=self.timeout)
#提取包含视频m3u8地址的js网址
jsurl = re.search(r'src=\"\/dian(.*?)">', r.text).group(1)
jsurl="{}/dian{}".format(domainurl,jsurl)
#请求获取JS网址的内容
response = requests.get(url=jsurl,timeout=self.timeout)
videostr=re.search(r'ff_urls=\'(.*?)\';',response.text).group(1)
#格式化JS
videojson=json.loads(videostr,encoding="utf-8")
print(videojson)
#定义一下我们显示的云类型及播放地址集合
videotype='swyun'
playurls = []
#首先我们判断我们选择的swyun云端是否存在
for p in videojson["Data"]:
if p["playname"]==videotype:
playurls=p["playurls"]
break
#如果不存在,我们再尝试提取zdyun云端的内容,这里可以依次,因为这个视频网的云端比较多
if len(playurls)==0:
for p in videojson["Data"]:
if p["playname"]=="zdyun":
videotype='zdyun'
playurls=p["playurls"]
break
#获取对应的播放地址
for vp in playurls:
if videoname.split("_")[1] == vp[0]:
playurl = vp[1]
break
#通过下面地址转换,获取真正的播放地址,这里一定要加referer,否则请求不到内容
zurl = "https://www.juji.tv/Player/dp.html?v="+playurl
headers = {
'referer': videourl
}
response = requests.get(url=zurl, headers=headers, timeout=self.timeout)
#用正则获取到真正的播放地址
realurl=re.search(r'purl\s=\s\'(.*?)\';',response.text).group(1)
#这里我们为了方便,发现有出现2次index.m3u8这样的,里面的内容都是/1000k/hls/*.m3u8,所以直接判断加上
if videotype == 'zdyun' or videotype == 'okyun':
playurl = realurl[:realurl.rfind("/")] + "/1000k/hls/" + realurl.split("/")[-1]
else:
playurl=realurl
print("真正的地址:",playurl)
return playurl
下面我们运行打印看看:
![]()
我们在主文件里创建一个post方法,成功后返回该地址:
#在线播放
@app.route("/play",methods=["post"])
def play():
args = request.args if request.method == 'GET' else request.form
name = args.get('name', "", type=str)
url = args.get('url', "", type=str)
#载入Video类调用获取地址的方法
v = Video()
url = v.get_video_m3u8(url,name)
#成功后返回地址信息
msg={"code":200,"url":url}
return jsonify(msg)html部分通过jquery的ajax请求的,在线播放是引用了videojs,html中的JS我们全部引用的是别人CDN的镜像文件,你也可以下载到本地放到static文件夹中的JS文件夹中,我会提供源码作为参考,这里不做过多的说明,接下来我们就可以输出给页面实现进行点击播放:

好了,由于时间关系,今天就讲到这里,这篇实现了获取真实视频地址并实现在线播放,下篇会讲实现m3u8的下载并使用ffmpeg将多个ts文件合并成为web支持的MP4视频文件,敬请期待!
需要源码的童鞋请关注公众号回复:韩剧播放
江湖不说再见,咱们下篇见!

关注公众号,超越平凡才能成就自己