机器学习之随机森林(手推公式版)
文章目录
-
- 前言
- 1. 集成学习
-
- 1.1 Boosting
- 1.2 Bagging
- 2. 随机森林
-
- 2.1 投票法
- 2.2 平均法
- 3. 模型实现
- 结束语
前言
随机森林 ( R a n d o m (Random (Random F o r e s t , R F ) Forest,RF) Forest,RF)是非常具有代表性的 B a g g i n g Bagging Bagging集成算法,在以决策树为基学习器(评估器)的基础之上,进一步在决策树的训练过程中引入随机特征选择(不然也不叫“随机”森林了,哈哈哈哈)。本篇博客就来简单介绍一下随机森林的相关知识及其在分类问题上的应用。
基学习器,即若集成器中只包含同种类型的个体学习器,则该个体学习器称为基学习器,相应的学习算法称为基学习算法。
弱学习器,常指泛化性能略优于随机猜测的学习器,即精度略高于50%的学习器。一般基学习器也称为弱学习器。
个体学习器,通常是由一个现有的学习算法从训练数据中产生的。
1. 集成学习
集成学习 ( E n s e m b l e (Ensemble (Ensemble L e a r n i n g ) Learning) Learning)本身不是一个单独的机器学习算法,而是通过构建并结合多个学习器(评估器)来完成学习任务。集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的分类或回归表现。
1.1 Boosting
B o o s t i n g Boosting Boosting是一种可将弱学习器提升为强学习器的算法,所以也称为提升法,工作机制为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器预测错的训练样本在后续训练中受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;不断重复上述过程,直至基学习器数目达到实现指定的值,最终将这指定数目的基学习器进行加权结合。
所以, B o o s t i n g Boosting Boosting集成算法是一种串行式算法,即后面的基学习器依赖于前面的基学习器。
B o o s t i n g Boosting Boosting算法中最著名的代表是 A d a B o o s t AdaBoost AdaBoost算法。
1.2 Bagging
B a g g i n g Bagging Bagging是一种并行式的集成算法,即多个基学习器之间没有依赖关系,是相互独立的。如何使基学习器之间相互独立呢?该算法是这样做的:先对训练集进行采样(自助采样法),需要多少个基学习器,就采样出多少个训练子集(采样集),然后基于每个采样出来的训练子集来训练一个基学习器,再将这些基学习器进行结合,在对预测输出进行结合时,分类任务通常要采用投票法,回归任务使用平均法。
B a g g i n g Bagging Bagging算法中最著名的代表是 R F RF RF算法。
自助采样法 ( B o o t s t r a p (Bootstrap (Bootstrap S a m p l i n g ) Sampling) Sampling):给定包含 m m m个样本的数据集 D D D,我们先从中随机选取一个样本放入到采样集 D ′ D^\prime D′中,然后再把该样本放回到原始数据集 D D D中,使得下次采样时该样本仍有可能被选中,这样,经过 m m m次随机采样操作,我们得到了含 m m m个样本的采样集 D ′ D^\prime D′。显然,原始数据集 D D D中会有一部分样本在 D ′ D^\prime D′中多次出现,而另一部分样本不会出现。可以做一下简单的估计:每个样本被采样到的概率为 1 m \frac {1} {m} m1,那么不会被采样到的概率就是 1 − 1 m 1-\frac {1} {m} 1−m1,那么样本在 m m m次采样中一次也没被采样到的概率为 ( 1 − 1 m ) m (1-\frac {1} {m})^m (1−m1)m,取极限可得 lim m → ∞ ( 1 − 1 m ) m = 1 e ≈ 0.368 \lim_{m \to \infty} (1-\frac {1} {m})^m=\frac {1} {e} \approx 0.368 m→∞lim(1−m1)m=e1≈0.368
通过自主采样法,初始数据集 D D D中约有36.8%的样本未出现在数据集 D ′ D^\prime D′中,于是我们可以将 D ′ D^\prime D′用作训练集, D − D ′ D-D^\prime D−D′用做测试集,这样的测试称为包外估计(out-of-bag estimate,oob)。

2. 随机森林
传统决策树在选择划分特征时是在当前结点的特征集合中选择一个最优特征(假设有 d d d个特征),而在随机森林中,对基决策树的每个结点,先从该结点的特征集中随机选择一个包含 k k k个特征的子集,然后再从这个子集中选择一个最优特征用于划分。
在上面介绍随机森林的时候我们引入了一个参数 k k k来控制随机性的引入程度:若令 k = d k=d k=d,则及决策树的构建与传统决策树相同;若令 k = 1 k=1 k=1,则是随机选择一个特征进行划分;一般情况下,推荐值 k = log 2 d k=\log_2d k=log2d。
下面来看看集成算法是如何保证集成的效果一定好于单个学习器的:
假设集成包含 T T T个基学习器 { h 1 , h 2 , … , h T } \{h_1,h_2,\dots,h_T\} { h1,h2,…,hT},其中 h i h_i hi在示例 x \bm x x上的输出为 h i ( x ) h_i(\bm x) hi(x)。
2.1 投票法
对分类任务来说,最常使用的结合策略是投票法 ( v o t i n g ) (voting) (voting)。假设类别的集合为 { c 1 , c 2 , … , c N } \{c_1,c_2,\dots,c_N\} { c1,c2,…,cN},为方便讨论,这里将 h i h_i hi在样本 x \bm x x上的预测输出表示为一个 N N N维向量 ( h i 1 ( x ) , h i 2 ( x ) , … , h i N ( x ) , ) T \big(h_i^1(\bm x), h_i^2(\bm x), \dots,h_i^N(\bm x), \big)^T (hi1(x),hi2(x),…,hiN(x),)T,其中 h i j ( x ) h_i^j(\bm x) hij(x)表示 h i h_i hi在类别 c j c_j cj上的输出。
∙ \bullet ∙ 绝对多数投票法 ( m a j o r i t y (majority (majority v o t i n g ) voting) voting)
H ( x ) = { c j , ∑ i = 1 T h i j ( x ) > 0.5 ∑ k = 1 N ∑ i = 1 T h i k ( x ) r e j e c t , 其 他 H(\bm x)=\begin{cases} c_j, & \sum_{i=1}^Th_i^j(\bm x)>0.5 \sum_{k=1}^N\sum_{i=1}^Th_i^k(\bm x)\\ \\ reject, & 其他 \end{cases} H(x)=⎩⎪⎨⎪⎧cj,reject,∑i=1Thij(x)>0.5∑k=1N∑i=1Thik(x)其他 即若某个标记得票过半数,则预测为该类别,否则拒绝预测。
∙ \bullet ∙ 相对多数投票法 ( p l u r a l i t y (plurality (plurality v o t i n g ) voting) voting)
即预测为得票最多的类别,若同时有多个类别获得最高票,则从中随机选取一个。
∙ \bullet ∙ 加权投票法 ( w e i g h t e d (weighted (weighted v o t i n g ) voting) voting)
与加权平均法类似
2.2 平均法
对数值型输出 h i ( x ) ∈ R h_i(\bm x)\in \mathbb {R} hi(x)∈R,最常见的结合策略是平均法 ( a v e r a g i n g ) (averaging) (averaging)。
∙ \bullet ∙ 简单平均法 ( s i m p l e (simple (simple a v e r a g i n g ) averaging) averaging)
H ( x ) = 1 T ∑ i = 1 T h i ( x ) H(\bm x)=\frac {1} {T}\sum_{i=1}^Th_i(\bm x) H(x)=T1i=1∑Thi(x) ∙ \bullet ∙ 加权平均法 ( w e i g h t e d (weighted (weighted a v e r a g i n g ) averaging) averaging)
H ( x ) = 1 T ∑ i = 1 T w i h i ( x ) H(\bm x)=\frac {1} {T}\sum_{i=1}^Tw_ih_i(\bm x) H(x)=T1i=1∑Twihi(x) 其中 w i w_i wi是个体学习器 h i h_i hi的权重,通常要求 w i ≥ 0 , ∑ i = 1 T w i = 1 w_i\geq 0,\sum_{i=1}^Tw_i=1 wi≥0,∑i=1Twi=1。
很显然,简单平均法是加权平均法令 w i = 1 T w_i=\frac {1} {T} wi=T1的特例。加权平均法的权重一般是从训练数据中学习得到的,现实任务中的训练样本通常不充分或存在噪声,这将使得学习得到的权重不完全可靠。一般而言,在个体学习器性能相差较大时宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
3. 模型实现
这里使用sklearn.ensemble里的RandomForestClassifier进行决策树建模来解决分类问题,数据集为sklearn自带的酒数据集winedata,数据集详情可参考决策树这篇博客,这里不再叙述。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split, cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
winedata = load_wine()
x_train, x_test, y_train, y_test = train_test_split(winedata.data, winedata.target, test_size=0.3, random_state=1024)
# n_estimators 森林中树木的数量, 即评估器的数量 往往越大越好[1, 200]
# bootstrap 有放回随机抽样 默认为True, 一般保持默认
# oob_score True 使用袋外数据来测试模型, 即可以不用划分数据集了
# random_state 控制随机森林的生成模式
model = RandomForestClassifier(n_estimators=100, criterion='gini', random_state=1024)
model.fit(x_train, y_train)
score = model.score(x_test, y_test)
# score: 0.9815
print('score:', score)
我们构建了一个含有100棵决策树的随机森林,在没有调参的情况下,在winedata数据集上的进度就达到了0.98,明显高于单棵决策树的0.9074。下面来看一下参数n_estimators对随机森林的影响:
score_list = []
for i in range(200):
model = RandomForestClassifier(n_estimators=i+1, criterion='gini', random_state=1024)
score = cross_val_score(model, winedata.data, winedata.target, cv=10).mean()
score_list.append(score)
plt.figure(figsize=(20, 5))
plt.plot(range(1, 201), score_list)
# plt.xticks(range(1, 201))
plt.show()
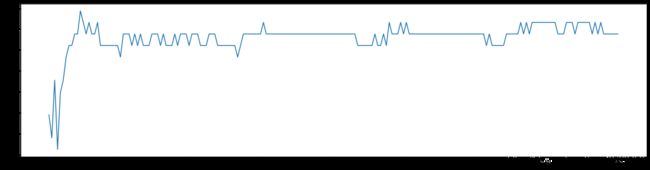
下面不用手动划分数据集了,我们根据上述的介绍,使用oob来训练模型:
# 使用oob
model = RandomForestClassifier(n_estimators=100, criterion='gini', random_state=1024, oob_score=True)
model.fit(winedata.data, winedata.target)
# # 查看各个基评估器
# model.estimators_
# # 看看精度0.9831
# model.oob_score_

随机森林是基于决策树的,所以其参数选择有些多,有关
RandomForestClassifier的详细参数说明可参考官方手册。
结束语
持续充电中,博客内容也在不断更新补充中,如有错误,欢迎来私戳小编哦!共同进步,感谢Thanks♪(・ω・)ノ
