R中的简单线性回归
简单线性回归被用于预测一个量化结果y基于一个单一预测变量的x。目标是建立将y定义为x变量的函数的数学模型(或公式)。
建立了具有统计意义的模型,就可以根据新的x值将其用于预测未来结果。
考虑到这一点,我们想评估三种媒体(youtube,facebook和newspaper)的广告预算对未来销售的影响。这个问题的例子可以用线性回归建模。
公式和基础
线性回归的数学公式可以写成y = b0 + b1*x + e,其中:
-
b0并b1称为回归beta系数或参数:-
b0是回归线的截距;是时的预测值x = 0。 -
b1是回归线的斜率。
-
-
e是误差项(也称为残差),y的一部分可以由回归模型解释
下图说明了线性回归模型,其中:
- 最佳拟合回归线为蓝色
- 截距(b0)和斜率(b1)以绿色显示
- 误差项(e)用垂直红线表示

从上面的散点图可以看出,并不是所有的数据点都精确地落在拟合的回归线上。有些点在蓝色曲线的上方,而有些点在蓝色曲线的下方。总体而言,残余误差(e)的平均值约为零。
残留误差的平方和称为残差平方和或Residual Sum of Squares RSS。
拟合回归线周围的点的平均变化称为残差标准误差(Residual Standard Error, RSE)。这是用于评估拟合回归模型整体质量的指标之一。RSE越低越好。
由于平均误差项为零,因此可以近似估算出结果变量y,如下所示:
y ~ b0 + b1*x
在数学上,确定beta系数(b0和b1),以使RSS尽可能小。确定β系数的这种方法在技术上称为最小二乘回归或普通最小二乘(OLS)回归。
一旦计算出β系数,就进行t检验以检查这些系数是否显着不同于零。Beta系数非零表示在预测变量(x)与结果变量(y)之间存在显着关系。
加载所需的R包
加载所需的软件包:
-
tidyverse用于数据处理和可视化 -
ggpubr:轻松创建发表级图片
library(tidyverse)
library(ggpubr)
theme_set(theme_pubr())
示例数据和问题
我们将使用marketing数据集[datarium包]。它包含三种广告媒体(youtube,facebook和报纸)对销售的影响。数据是连同销售一起的数千美元的广告预算。广告实验已用不同的预算重复了200次,并记录了观察到的销售额。
首先datarium使用来安装软件包devtools::install_github("kassmbara/datarium"),然后marketing按照以下步骤加载和检查数据:
这里可以直接运行
install.packages("datarium")安装
检查数据:
# Load the package
data("marketing", package = "datarium")
head(marketing, 4)
## youtube facebook newspaper sales
## 1 276.1 45.4 83.0 26.5
## 2 53.4 47.2 54.1 12.5
## 3 20.6 55.1 83.2 11.2
## 4 181.8 49.6 70.2 22.2
我们希望根据在YouTube上花费的广告预算来预测未来的销售量。
可视化
- 创建散点图,分别显示在三种媒体的广告投资与销售量的关系
- 添加平滑线
library("gridExtra")
p1 <- ggplot(marketing, aes(x = youtube, y = sales)) +
geom_point() +
stat_smooth()
p2 <- ggplot(marketing, aes(x = facebook, y = sales)) +
geom_point() +
stat_smooth()
p3 <- ggplot(marketing, aes(x = newspaper, y = sales)) +
geom_point() +
stat_smooth()
grid.arrange(p1, p2, p3, ncol= 3, nrow = 1)
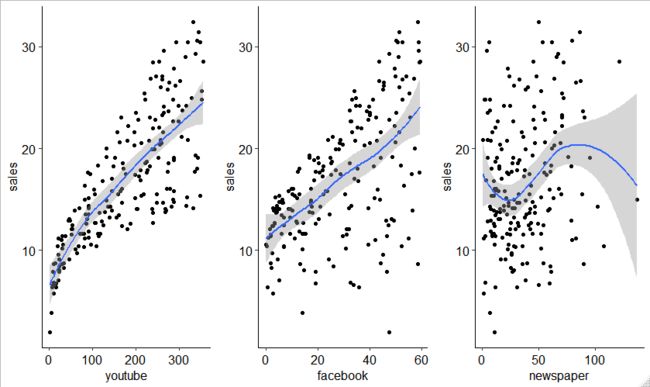
上图显示了youtube和facebook与sales之间成明显的线性关系,而newspaper 与sales之间不成的线性关系而。这是一件好事,因为线性回归的一个重要假设是结果与预测变量之间的关系是线性和可加的。
也可以使用R函数计算两个变量之间的相关系数cor():
> cor(marketing$sales, marketing$youtube)
[1] 0.7822244
> cor(marketing$sales, marketing$facebook)
[1] 0.5762226
> cor(marketing$sales, marketing$newspaper)
[1] 0.228299
相关系数测量两个变量x和y之间的关联水平。它的值介于-1(完全负相关:x增加时,y减小)和+1(完全正相关:x增加时,y增大)之间。
接近0的值表示变量之间的关系较弱。较低的相关性(-0.2 在我们的示例中,相关系数足够大,因此我们可以继续构建y作为x的函数的线性模型。 简单的线性回归试图根据youtube广告预算找到最佳的线来预测销售量。 线性模型方程可写为: R函数 结果显示了youtube变量的截距和beta系数。 从上面的输出中: 估计的回归线方程可写为: 截距( 变量youtube( 要将回归线添加到散点图上,可以使用函数 在上一节中,我们建立了一个线性销售模型,作为youtube广告预算的函数: 使用此公式预测将来的销售之前,应确保该模型具有统计意义,即: 在本节中,我们将描述如何检查线性回归模型的质量。 对于 我们首先使用R函数显示模型的统计摘要 摘要输出显示6个组件,包括: 模型统计摘要中的系数表显示: t统计量和p值: 对于给定的预测变量,t统计量(及其关联的p值)测试给定的预测变量和结果变量之间是否存在统计上显着的关系,即预测变量的beta系数是否显着不同从零开始。 统计假设如下: 在数学上,对于给定的beta系数(b),t检验计算为 t统计量越高(p值越低),则预测变量越重要。右侧的符号在视觉上指定了重要性级别。表格下方的行显示了这些符号的定义。一星表示0.01
具有统计学意义的系数表明,预测变量(x)与结果变量(y)之间存在关联。 在我们的示例中,截距的p值和预测变量都非常重要,因此我们可以拒绝原假设并接受替代假设,这意味着预测变量与结果变量之间存在显着关联。 对于是否在模型中包含预测变量,t统计量是非常有用的指南。高t统计量(p值接近0的低值)表示应将预测变量保留在模型中,而非常低的t统计量则表示可以删除预测变量(P. Bruce and Bruce 2017)。 标准误差和置信区间: 标准误差测量β系数的变异性/准确性。它可用于计算系数的置信区间。 例如,系数b1的95%置信区间定义为 即,间隔[0.042,0.052]包含b1的真实值的可能性大约为95%。同样,可以将b0的95%置信区间计算为 要获取这些信息,只需键入: 一旦确定至少一个预测变量与结果显着相关,就应该通过检查模型拟合数据的程度来继续进行诊断。此过程也称为拟合优度 可以使用以下三个数量来评估线性回归拟合的整体质量,这些数量显示在模型摘要中: RSE(也称为模型sigma)是残差,表示拟合回归线周围观测点的平均变化。这是残留误差的标准偏差。 RSE提供了模型无法解释的数据模式的绝对度量。比较两个模型时,具有较小RSE的模型很好地表明了该模型最适合数据。 将RSE除以结果变量的平均值将为您提供预测误差率,该误差率应尽可能小。 在我们的示例中,RSE = 3.91,这意味着观察到的销售价值平均偏离真实回归线约3.9个单位。 3.9单位的RSE是否可接受的预测误差是主观的,并且取决于问题的背景。但是,我们可以计算百分比误差。在我们的数据集中,销售平均值为16.827,因此百分比误差为3.9 / 16.827 = 23%。 R平方(R2)的范围是0到1,并且代表模型中可以解释的数据中信息的比例(即变化)。调整后的R平方可调整自由度。 R2衡量模型拟合数据的程度。对于简单的线性回归,R2是皮尔森相关系数的平方。 R2的高值是一个很好的指示。但是,当在模型中添加更多的预测变量时(例如在多元线性回归模型中),R2的值趋于增加,因此您应主要考虑调整后的R平方,对于更多数量的预测变量而言,这是惩罚性的R2。 F统计量提供了模型的整体重要性。它评估至少一个预测变量是否具有非零系数。 在简单的线性回归中,此检验并不是真正有趣的事情,因为它只是复制了系数表中可用的t检验给出的信息。实际上,F检验与t检验的平方相同:312.1 =(17.67)^ 2。在任何具有1个自由度的模型中都是如此。 一旦我们开始在多元线性回归中使用多个预测变量,F统计量就变得更加重要。 大的F统计量将对应于统计上显着的p值(p <0.05)。在我们的示例中,F统计量等于312.14,产生的p值为1.46e-42,这是非常重要的。 在计算回归模型之后,第一步是检查至少一个预测变量是否与结果变量显着相关。 如果一个或多个预测变量很重要,则第二步是通过检查残差标准误差(RSE),R2值和F统计量来评估模型对数据的拟合程度。这些指标提供了模型的整体质量。 下节内容:R中的多元线性回归计算方式
sales = b0 + b1 * youtubelm()可用于确定线性模型的beta系数:model <- lm(sales ~ youtube, data = marketing)
model
##
## Call:
## lm(formula = sales ~ youtube, data = marketing)
##
## Coefficients:
## (Intercept) youtube
## 8.4391 0.0475
解释
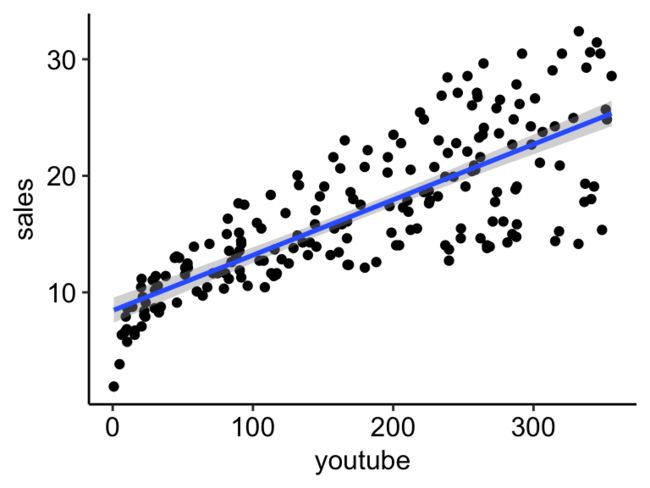
sales = 8.44 + 0.048*youtubeb0)为8.44。可以将其解释为YouTube广告预算为零的预测销售单位。回想一下,我们以千美元为单位运营。这意味着,对于等于零的youtube广告预算,我们可以预期实现8.44 * 1000 = 8440美元的销售额。b1)的回归beta系数(也称为斜率)为0.048。这意味着,对于等于1000美元的youtube广告预算,我们可以预期销售额会增加48个单位(0.048 * 1000)。也就是说,sales = 8.44 + 0.048*1000 = 56.44 units。因为我们以千美元为单位进行操作,所以这表示销售额为56440美元。回归线
stat_smooth()[ggplot2]。默认情况下,拟合线周围带有置信区间。置信带反映了该线的不确定性。如果您不想显示它,请se = FALSE在函数中指定选项stat_smooth()。ggplot(marketing, aes(youtube, sales)) +
geom_point() +
stat_smooth(method = lm)
模型评估
sales = 8.44 + 0.048*youtube。
模型汇总
summary()的解读有一篇不错的文章:R语言:summary()函数解读summary():summary(model)
##
## Call:
## lm(formula = sales ~ youtube, data = marketing)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.06 -2.35 -0.23 2.48 8.65
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.43911 0.54941 15.4 <2e-16 ***
## youtube 0.04754 0.00269 17.7 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.91 on 198 degrees of freedom
## Multiple R-squared: 0.612, Adjusted R-squared: 0.61
## F-statistic: 312 on 1 and 198 DF, p-value: <2e-16
系数意义
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.4391 0.54941 15.4 1.41e-35
## youtube 0.0475 0.00269 17.7 1.47e-42
t = (b - 0)/SE(b),其中SE(b)是系数b的标准误差。t统计量测量b远离0的标准偏差的数量。因此,较大的t统计量将产生较小的p值。b1 +/- 2*SE(b1),其中:
b1 - 2*SE(b1) = 0.047 - 2*0.00269 = 0.042 b1 + 2*SE(b1) = 0.047 + 2*0.00269 = 0.052 b0 +/- 2*SE(b0)。confint(model)
## 2.5 % 97.5 %
## (Intercept) 7.3557 9.5226
## youtube 0.0422 0.0528
模型精度
## rse r.squared f.statistic p.value
## 1 3.91 0.612 312 1.47e-42
sigma(model)*100/mean(marketing$sales)
## [1] 23.2
概要
> 觉得有用老铁们麻烦双击666~