下面来看一下stage1_rpn_train.pt这个网络的内部结构。
“ZF”网络结构
一、数据输入层:
从roi_data_layer.layer文件中得到数据, 进入到roi_data_layer.layer文件中,查看forward函数,这个函数的top变量就是输出结果。下面进入forward函数:
blobs =self._get_next_minibatch() :首先根据self._get_next_minibatch() 函数得到符合caffe格式的blobs。
看一下self._get_next_minibatch() 函数:
由于__C.TRAIN.USE_PREFETCH =False,所以执行else语句。
首先,根据_get_next_minibatch_inds函数得到db_inds,进入_get_next_minibatch_inds函数:

注意,虽然在config文件中cfg.TRAIN.IMS_PER_BATCH的值为2,但是在train_rpn函数中,将其修改为了1,因此:cfg.TRAIN.IMS_PER_BATCH = 1

关于self._perm:
所以,最后得到的db_inds是从np.random.permutation(np.arange(len(self._roidb)))得到的一个元素,也即是:从self._roidb中随机选取一个数值,那么self._roidb又是什么呢?回想set_roidb函数,在这个函数中,将我们得到的准备数据roidb进行随机打乱,得到了:self._roidb。(从这里可以看出,得到的db_inds实际上是把roidb打乱了2次)。
好了,回到_get_next_minibatch函数:
minibatch_db = [self._roidb[i] for i in db_inds]:根据得到的db_inds中,从self._roidb中取出这张图片对应的数据,我们知道是一个字典,然后把这些字典数据组成一个列表minibatch_db (虽然这个列表只有一个元素)。
最后,使用get_minibatch(minibatch_db,self._num_classes)函数,将minibatch_db 转换为blobs。
get_minibatch是一个比较复杂的函数,进入get_minibatch函数:

在这里,利用_get_image_blob函数得到两个输出值im_blob(是一个列表,虽然这里的列表长度为1) 和 im_scales(是一个列表,虽然这里的列表长度为1)。进入_get_image_blob函数看一下:
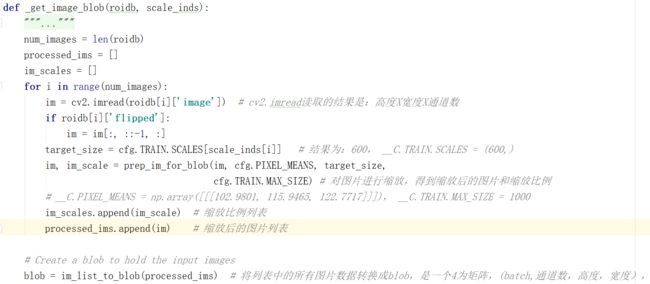
首先,利用prep_im_for_blob函数来得到每张图片的 im 和 im_scale,然后将它们添加到图片列表processed_ims和缩放比例列表:im_scales。接下来,使用im_list_to_blob函数将图片列表processed_ims转换成blob。然后,将blob 和 im_scales返回。
好了,回到get_minibatch函数,我们得到了im_blob(一个batch的blob),以及在这个batch中每张图片的缩放比例列表im_scales。(注意,这里的batch=1,即:blob的第一个维度为1。im_scales的长度也为1)

这里可以看出,blobs是一个字典,首先,将上面得到的im_blob传入blobs字典。
然后判断cfg.TRAIN.HAS_RPN,注意,在train_rpn函数中:cfg.TRAIN.HAS_RPN =True,所以,这里要执行if语句:判断assert len(im_scales) ==1和assert len(roidb) ==1,经过我们的分析,可以看出,这两个条件是成立的。
gt_inds = np.where(roidb[0]['gt_classes'] !=0)[0]:因为gt_classes = np.zeros((num_objs),dtype=np.int32),所以,gt_inds 得到的是gt_classes 的行索引,因为gt_classes 对应的是图片中的真实物体矩阵,没有非0值,所以gt_inds 得到的是gt_classes 中所有的行索引。
gt_boxes是一个num_objs行5列的矩阵,其中前面四列是:每个gt_box对应的坐标,第5列是:物体号。
好了,get_minibatch函数结束,回到_get_next_minibatch函数,最后的返回值是一个blobs字典,
blobs = { 'data': im_blob, 'gt_boxes':gt_boxes, 'im_info':np.array([高度,宽度, 缩放比例]) }
接下来,返回forward函数,遍历blobs 字典,得到:
top[0] = blobs['data']、 top[1] = blobs['im_info'] 、 top[2] = blobs['gt_boxes'] 。
这样,forward函数结束,得到了top变量。回到‘ZF’网络中:

可以看到,得到的top就是这个网络层中的输出结果。
二、基础的网络层(总共包含5个卷积过程)
接着看下面的网络结构,一开始是:
#========= conv1-conv5 ============
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 96
kernel_size: 7
pad: 3
stride: 2
}
}
输入是上面得到的‘data',输出96个通道,卷积核的大小7,补零(补3圈),卷积的stride=2
接下来,一直到conv5 结束,都是一样分析,具体的内容可以参考:https://blog.csdn.net/Seven_year_Promise/article/details/60954553
而且conv5 的输出结果为:batch*256*14*14 。(根据设置,我们知道,这里的batch=1)
三、RPN层
首先看一下RPN层的网络结构:

我们得到的batch*256*14*14 就是图中的feature map,首先进行了一个3*3的卷积,输出的结果还是batch*256*14*14 ,然后分两个方向:
第一个方向,进行1*1*18的卷积,得到的结果为:batch*18*14*14 。根据结果可以看出,这里相当于在特征图的每个格子中取了9个anchor,每个anchor有foreground和background(检测目标是foreground),所以刚好是18个通道。然后进行softmax分类获得foreground anchors,也就相当于初步提取了检测目标候选区域box(一般认为目标在foreground anchors中)。
那么为何要在softmax前后都接一个reshape layer?其实只是为了便于softmax分类,至于具体原因这就要从caffe的实现形式说起了。在caffe基本数据结构blob中以如下形式保存数据:
blob=[batch_size, channel,height,width]
对应至上面的保存bg/fg anchors的矩阵,其在caffe blob中的存储形式为[1, 2*9, 14, 14]。而在softmax分类时需要进行fg/bg二分类,所以reshape layer会将其变为[1, 2, 9*14, 14]大小,即单独“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。
第二个方向,进行1*1*36的卷积,得到的结果为:batch*36*14*14 (实际上是:[1, 4*9, 14, 14])。也就是每个anchor会得到4个偏移量。
下面看具体的代码:
#========= RPN ============
layer {
name: "rpn_conv1"
type: "Convolution"
bottom: "conv5"
top: "rpn_conv1"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 256
kernel_size: 3 pad: 1 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_relu1"
type: "ReLU"
bottom: "rpn_conv1"
top: "rpn_conv1"
}
这里是进行了3*3的卷积,然后又接了一个relu的激活函数。
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn_conv1"
top: "rpn_cls_score"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn_conv1"
top: "rpn_bbox_pred"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
这两层分别是两个方向,用1*1*18的卷积,得到:rpn_cls_score([1, 2*9, 14, 14]);
1*1*36的卷积,得到:rpn_bbox_pred([1, 4*9, 14, 14])。
下面将rpn_cls_score改变维度:

通过reshape层,将rpn_cls_score进行reshape,得到:rpn_cls_score_reshape([1, 2, 9*14, 14])。
(关于caffe的reshape层:
#dim:0 表示维度不变,即输入和输出是相同的维度。
#dim:2 表示将原来的维度变成2。
#dim:-1 表示由系统自动计算维度,数据的总量不变。)
我们知道,rpn_cls_score(或者说:rpn_cls_score_reshape)和rpn_bbox_pred是网络预测的rpn_box,而且,我们下一步需要对这两个结果计算loss,那么计算loss所需要的target在哪里呢,下面我们需要计算target:

先来看一下参数:param_str: "'feat_stride': 16",这个实际上表示:图片经过一系列卷积,到现在的feature map缩小了多少倍,也就是说,我们的经过缩放之后的图片经过了最初的五层卷积,高度和宽度都变为了原来的1/16(后面的3*3卷积和1*1卷积之后,feature map大小不变,所以没有计算在内)
再来看一下这一层的输入和输出:
输入:
bottom: 'rpn_cls_score' (1*1*18卷积的结果)
bottom: 'gt_boxes' (roi_data_layer.layer的输出结果,num_obj行5列的矩阵,前4列是坐标,第5列是物体号)
bottom: 'im_info' (roi_data_layer.layer的输出结果, [高度,宽度, 缩放比例],这里的高度和宽度是缩放之后的)
bottom: 'data' (roi_data_layer.layer的输出结果, 4维矩阵,(batch, 3,高度,宽度),batch=1)
输出:
top: 'rpn_labels' :
先看一个中间变量labels:height * width *9 个元素的一维向量(height、width 是feature map的高度和宽度),也就是说labels刚好和总的anchor的数量是对应的。然后将labels进行两次reshape:
labels = labels.reshape((1, height, width, A)).transpose(0,3,1,2),
labels = labels.reshape((1,1, A * height, width))
得到rpn_labels,我们对比一下 rpn_labels的维度:(1,1, 9* 14, 14) 和 rpn_cls_score_reshape的维度(1, 2, 9*14, 14)。发现不太一样,由于对caffe不太熟悉,不知道在计算rpn_loss_cls的时候,是否对rpn_labels进行了后续处理。(当然,这里如果要把rpn_labels和rpn_cls_score_reshape的维度变成一样也很容易处理,进行one_hot处理就可以了)。
top: 'rpn_bbox_targets':
同样的,先看就中间变量bbox_targets,这是一个:height * width *9行4列的矩阵(列元素:tx,ty,tw,th)。然后进行reshape和转置,bbox_targets = bbox_targets .reshape((1, height, width, A *4)).transpose(0,3,1,2)。
那么,最后得到的维度是(1,A *4,height, width)。和rpn_bbox_pred的维度是一致的。
top: 'rpn_bbox_inside_weights':和 'rpn_bbox_targets'是一样的操作,先是得到 height * width *9行4列的矩阵(计算rpn_loss_bbox用到,没找到具体的rpn_loss_bbox文件),然后进行reshape和转置,最终得到的结果维度是:(1,A *4*,height, width)。
top: 'rpn_bbox_outside_weights':和 'rpn_bbox_targets'是一样的操作,先是得到 height * width *9行4列的矩阵(计算rpn_loss_bbox用到,没找到具体的rpn_loss_bbox文件),然后进行reshape和转置,最终得到的结果维度是:(1,A *4*,height, width)。
好了,下面进入rpn.anchor_target_layer文件,具体来看一下上述的结果是怎么实现的,直接看forward函数:
首先,判断batch是否为1,否则报错。然后根据输入得到基本信息:


可以得到:每个格子生成9个anchor,总共有K个格子(K=14*14=196),那么anchor的总数为:K*A个。
所有的anchor具体的坐标为:all_anchors,这是一个K*A行4列的矩阵。
注意:这个生成的all_anchors不是feature map的anchor,而是缩放后的图片的anchor,因为在生成这些anchor的过程中,乘以了系数self._feat_stride(值为:16)。
然后,过滤all_anchors,只保留没有超出图片的anchor:


过滤anchor之后,设置label的值,labels分为三类:1(代表正样本)、0(负样本)、-1(直接丢弃)。
然后,判断anchor和gt_box的overlap(即:IOU):
(1)先求overlaps矩阵:
overlaps = bbox_overlaps ( np.ascontiguousarray(anchors,dtype=np.float) \
,np.ascontiguousarray(gt_boxes,dtype=np.float) ),结果是一个inds_inside行num_obj列的矩阵
(2)对于每一个gt_box来说,和它的重叠区域最大的那个anchor的labels设为:1(即为:正样本),也就是在overlaps 矩阵中,按照列求最大值,那么每列最大值对应的行索引号对对应的anchor为正样本
(3)overlaps按照行取最大值,如果最大值大于0.7,那么这行对应的anchor为正样本(labels设为:1)
(4)overlaps按照行取最大值,如果最大值小于0.3,那么这行对应的anchor为负样本(labels设为:0)
(5)正样本的个数num_fg取128个,如果大于128,那么多出的部分直接丢弃(labels设为-1);如果num_fg不够128个,那么用负样本来补;
负样本的个数num_bg取:256-num_fg,同样的,如果num_bg大于256-num_fg,多出的直接丢弃
下面看bbox_targets,bbox_targets和过滤后的anchors ( anchors = all_anchors[inds_inside, :] )是对应的:

注意:这里的bbox_targets中4列的元素值:是坐标的偏移量,而不是坐标。
到这里还没有结束,注意我们这里得到的labels、bbox_targets都是通过过滤之后的anchors得到的,数量只有inds_inside个。但是,我们预测得到的结果是:rpn_cls_score([1, 2*9, 14, 14])(表示:anchor的个数是:9*14*14),这个数量和我们过滤之前的all_anchors的数量是一样的。所以,下面要经过一个简单的处理,利用_unmap函数将labels和bbox_targets的行的数量重新扩展到total_anchors个。
