Redis缓存异常
Redis缓存异常
缓存和数据库不一致情况
一致性的含义
- 缓存中有数据,缓存的数据值需要和数据库中的值相同
- 缓存中没有数据,数据库中的值必须是最新值
根据是否接受写请求,可以将缓存分成写缓存和只读缓存
对于读写缓存,修改数据时,对缓存和数据库都需要修改,因此需要指定写回策略
- 同步直写策略:写缓存时,也同步写数据库,缓存和数据库中的数据一致;
- 异步写回策略:写缓存时不同步写数据库,等到数据从缓存中淘汰时,再写回数据库。使用这种策略时,如果数据还没有写回数据库,缓存就发生了故障,那么,此时,数据库就没有最新的数据了。
对于数据一致性要求较高时,应该采取同步直写策略,并且采用事务机制,保证缓存和数据库的更新具有原子性,即要不一起更新,要不都不更新,返回错误信息。
对数据一致性要求不是那么高时,例如缓存中存放电商商品的非关键属性或短视频的创建或修改时间等,使用异步写回策略
对于只读缓存来说,如果有数据新增,会直接写入数据库;而有数据删改时,就需要把只读缓存中的数据标记为无效。这样一来,应用后续再访问这些增删改的数据时,因为缓存中没有相应的数据,就会发生缓存缺失。此时,应用再从数据库中把数据读入缓存,这样后续再访问数据时,就能够直接从缓存中读取了。
新增数据
新增数据,数据会直接写到数据库中,不对缓存进行操作。缓存中没有新增数据,数据库中是最新值,符合一致性的第二种情况
删改数据
发生删改操作时,既需要更新数据库,也需要删除缓存中数据,如果这两个操作无法保证原子性,就会出现数据不一致的问题
先删除缓存,再更新数据库

删除缓存成功,更新数据库失败,此时有其他并发请求访问数据,则Redis中缓存缺失,访问数据库后读到旧值
先更新数据库,再删除缓存
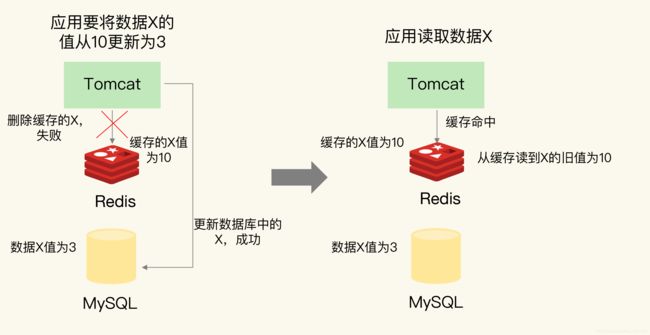
更新数据库成功,删除Redis缓存失败,其他并发请求访问数据,Redis直接返回缓存旧值

解决数据不一致问题
消息队列
将需要删改的缓存值暂存到消息队列中,如果应用没有成功删改缓存值或更新数据库时,从消息队列中重新读取值,重新进行对应的删改操作
若删改操作成功,应将这些值从消息队列中去除,避免重复操作,否则重试至消息一致为止。重试次数到达阈值后,需要向业务层发送报错信息。
消息队列只能处理小量并发情况,大量并发请求时,应用还是有可能读到不一致的数据。

先删除缓存,再更新数据库
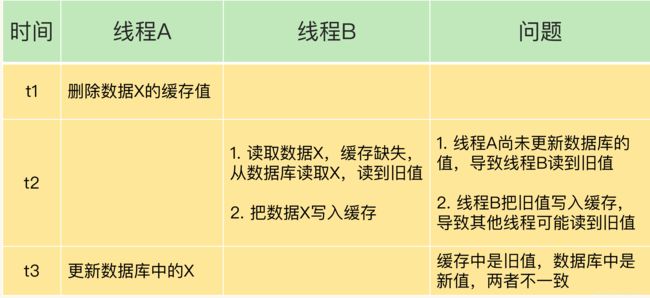
以上问题采用延迟双删(缓存值)方法解决
线程A更新完数据库值以后,先让线程Asleep一小段时间,再进行一次缓存删除操作
sleep一段时间的目的是让线程B先从数据库读取数据,并将缺失的数据写入缓存中,线程A再删除缓存。
因此sleep时间应该以线程读取数据和写缓存的平均时间为基准进行估算
其他线程再读取数据时,会发现缓存缺失,从数据库中读取最新值
// 伪代码
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
先更新数据库值,再删除缓存值
先更新数据库值,再删除缓存值的方式对业务影响较小。

数据一致性小结
- 删除缓存值或更新数据库失败导致数据库不一致,使用重试机制确保删除或更新操作成功
- 在删除缓存值、更新数据库的两部操作中,有其他线程读取到旧值,采用延迟双删方案
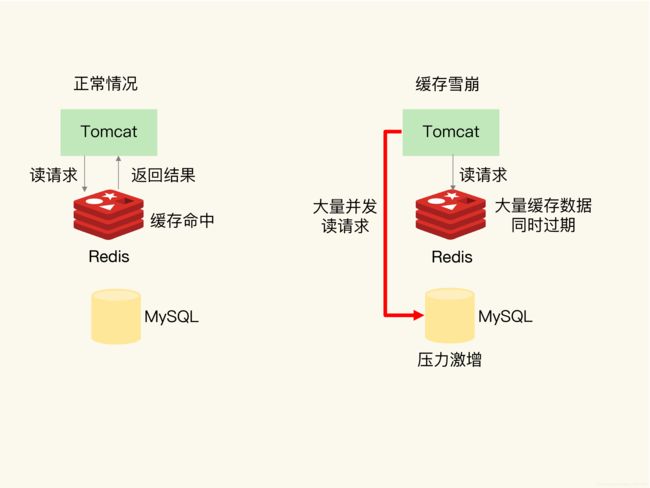
缓存雪崩
缓存雪崩是指大量的应用请求无法在Redis缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增
- 缓存中有大量数据同时过期,导致大量请求无法得到处理。
- Redis缓存实例故障宕机,大量请求积压到数据库层
数据过期
- 微调过期时间
如果业务层的确要求有些数据同时失效,用EXPIRE命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加1~3分钟)
使不同数据的过期时间有所差别,但差别又不会太大
既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。 - 服务降级
- 当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
- 当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。

服务器宕机
- 在业务系统中实现服务熔断或请求限流机制
缓存客户端不把请求发给Redis实例,而是直接返回 - 事前预防,通过主从节点的方式构建Redis缓存高可靠集群
如果Redis缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务
缓存击穿
缓存击穿是指,针对某个访问频繁的热点数据,无法在缓存中进行处理,对该热点数据的大量请求,都发送到后端数据库,导致数据库压力激增,影响数据库处理其他请求
缓存击穿通常发生在热点数据过期失效时

缓存击穿解决方法
对于访问特别频繁的热点数据,不设置过期时间,对热点数据的访问请求,都在缓存中进行处理
缓存穿透
缓存穿透是指要访问的数据既不在Redis缓存中,也不在数据库中,请求数据时,访问缓存-缓存缺失-访问数据库-数据库无数据的流程,如果有大量这样的请求,会同时对缓存和数据库带来巨大压力
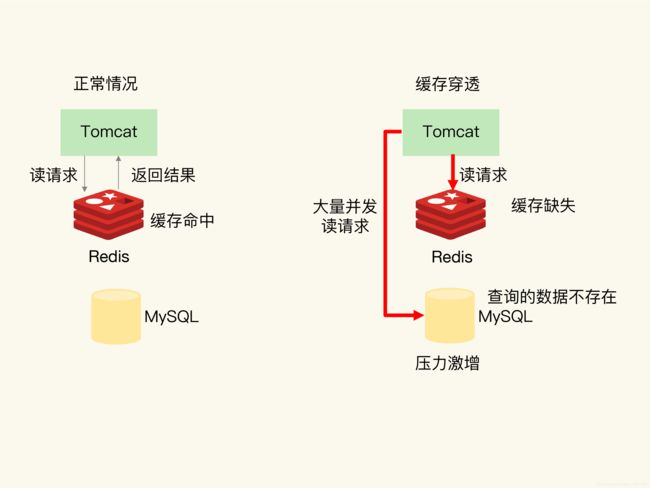
缓存穿透发生的可能原因
- 业务层误操作:缓存中数据和数据库中数据误删除
- 恶意攻击:专门发送请求访问数据库中不存在的数据
缓存穿透解决方法
- 缓存空值和缺省值
Redis中缓存一个和业务层决定的缺省值或空值 - 使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在
- 请求入口的前端进行请求检测
前端过滤非法请求(请求字段不存在,参数不合理)
缓存穿透、雪崩、击穿情况小结

尽量少采用服务熔断、服务降级、请求限流等有损方案
尽量使用预防式方案
- 针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群;
- 针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;
- 针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。
缓存穿透这个问题的本质是查询了Redis和数据库中没有的数据,而服务熔断、服务降级和请求限流的方法,本质上是为了解决Redis实例没有起到缓存层作用的问题,缓存雪崩和缓存击穿都属于这类问题。