数据湖解决方案关键一环,IceBerg会不会脱颖而出?
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


小编在之前的详细讲解过关于数据湖的发展历程和现状,《我看好数据湖的未来,但不看好数据湖的现在》 ,在最后一部分中提到了当前数据湖的解决方案中,目前跳的最凶的三巨头包括:Delta、Apache Iceberg 和 Apache Hudi。
本文中将详细的介绍一下其中的IceBerg,看一下IceBerg会不会最终脱颖而出。
发展历程
首先,大家要明白为什么出现了类似Iceberg这样的数据技术。
大数据领域发展至今已经经历了相当长时间的发展和探索,虽然大数据技术的出现和迭代降低了用户处理海量数据的门槛,但是有一个问题不能忽视,数据格式对不同引擎适配的对接。
这句话是什么意思呢?
我们在使用不同的引擎进行计算时,需要将数据根据引擎进行适配。这是相当棘手的问题,为此出现了一种新的解决方案:介于上层计算引擎和底层存储格式之间的一个中间层。这个中间层不是数据存储的方式,只是定义了数据的元数据组织方式,并且向引擎层面提供统一的类似传统数据库中"表"的语义。它的底层仍然是Parquet、ORC等存储格式。
基于此,Netflix开发了Iceberg,目前已经是Apache的顶级项目。
IceBerg的特性
我么直接引用官网的介绍:
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Trino and Spark that use a high-performance format that works just like a SQL table.
Iceberg是一个为大规模数据集设计的通用的表格形式。并且适配Trino(原PrestoSQL)和Spark适,提供SQL化解决方案。
IceBerg有一系列特性如下:
模式演化,支持添加,删除,更新或重命名,并且没有副作用
隐藏分区,可以防止导致错误提示或非常慢查询的用户错误
分区布局演变,可以随着数据量或查询模式的变化而更新表的布局
快照控制,可实现使用完全相同的表快照的可重复查询,或者使用户轻松检查更改
版本回滚,使用户可以通过将表重置为良好状态来快速纠正问题
快速扫描数据,无需使用分布式SQL引擎即可读取表或查找文件
数据修剪优化,使用表元数据使用分区和列级统计信息修剪数据文件
兼容性好 ,可以存储在任意的云存储系统和HDFS中
支持事务,序列化隔离 表更改是原子性的,读者永远不会看到部分更改或未提交的更改
高并发,高并发写入器使用乐观并发,即使写入冲突,也会重试以确保兼容更新成功
其中的几个特性精准的命中了用户的痛点,包括:
ACID和多版本支持
支持批/流读写
多种分析引擎的支持
其中更为重要的一点,IceBerg积极拥抱以Flink为核心的实时计算体系,提供了非常友好的与Flink结合的能力。
IceBerg初体验
目前IceBerg在Github上的分支已经更新到了0.11.0版本,小编本地搭建了单机版本的Spark和Flink环境,我们先来看Spark+IceBerg的入门案例:
我们可以用简单的像下面这样创建表:
import org.apache.iceberg.catalog.TableIdentifier
import org.apache.iceberg.spark.SparkSchemaUtil
val catalog = new HiveCatalog(spark.sparkContext.hadoopConfiguration)
val data = Seq((1, "a"), (2, "b"), (3, "c")).toDF("id", "data")
val schema = SparkSchemaUtil.convert(data.schema)
val name = TableIdentifier.of("default", "test_table")
val table = catalog.createTable(name, schema)
读写操作:
// write the dataset to the table
data.write.format("iceberg").mode("append").save("default.test_table")
// read the table
spark.read.format("iceberg").load("default.test_table")
当然也可以通过Sql来读写:
spark.read.format("iceberg").load("default.test_table").createOrReplaceTempView("test_table")
spark.sql("""SELECT count(1) FROM test_table""")
另外,特别值得一提的是,IceBerg社区上 https://github.com/apache/incubator-iceberg/pull/856 提供了可以试用的Flink Iceberg sink原型代码。下载该patch放入master分支,编译并构建即可。我们来试用一下:
// Configurate catalog
org.apache.hadoop.conf.Configuration hadoopConf =
new org.apache.hadoop.conf.Configuration();
hadoopConf.set(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREURIS.varname,
META_STORE_URIS);
hadoopConf.set(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREWAREHOUSE.varname,
META_STORE_WAREHOUSE);
Catalog icebergCatalog = new HiveCatalog(hadoopConf);
// Create Iceberg table
Schema schema = new Schema(
...
);
PartitionSpec partitionSpec = builderFor(schema)...
TableIdentifier tableIdentifier =
TableIdentifier.of(DATABASE_NAME, TABLE_NAME);
// If needed, check the existence of table by loadTable() and drop it
// before creating it
icebergCatalog.createTable(tableIdentifier, schema, partitionSpec);
// Obtain an execution environment
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// Enable checkpointing
env.enableCheckpointing(...);
// Add Source
DataStream> dataStream =
env.addSource(source, typeInformation);
// Configure Ieberg sink
Configuration conf = new Configuration();
conf.setString(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREWAREHOUSE.varname,
META_STORE_URIS);
conf.setString(IcebergConnectorConstant.DATABASE, DATABASE_NAME);
conf.setString(IcebergConnectorConstant.TABLE, TABLE_NAME);
// Append Iceberg sink to data stream
IcebergSinkAppender> appender =
new IcebergSinkAppender>(conf, "test")
.withSerializer(MapAvroSerializer.getInstance())
.withWriterParallelism(1);
appender.append(dataStream);
// Trigger the execution
env.execute("Sink Test");
你还可以在这里看到这个组件的设计:
https://docs.google.com/document/d/19M-sP6FlTVm7BV7MM4Om1n_MVo1xCy7GyDl_9ZAjVNQ/edit?usp=sharing
目前IceBerg对Flink的特性支持如下:
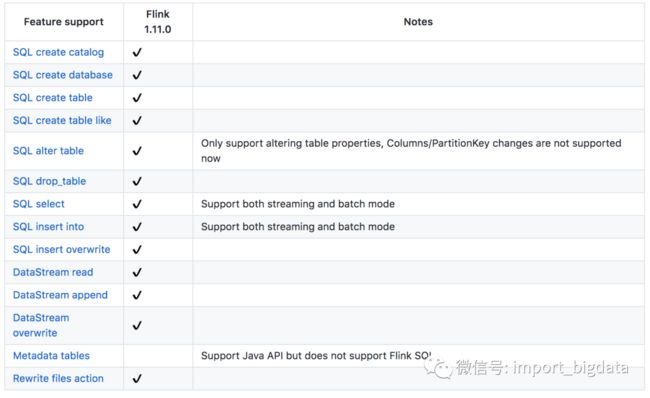
IceBerg还提供非常详细的接入文档:https://github.com/apache/iceberg/blob/master/site/docs/flink.md
在大厂的典型应用
目前一些公开的文章和资料中,我们可以找到一些Flink+IceBerg构建数据湖原型的案例。我们对其中的典型案例进行详细拆解。
阿里在Flink + Iceberg数据湖的探索
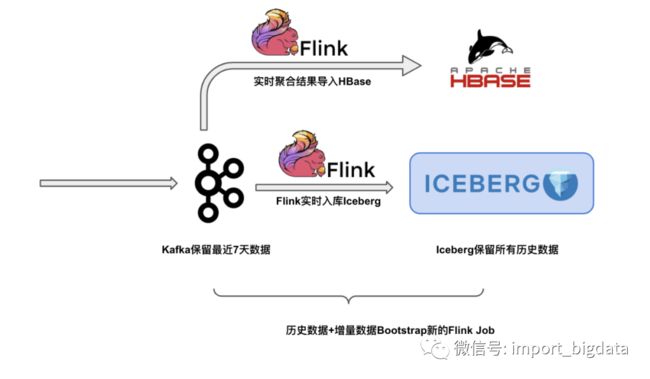
上图和下面的方案是阿里巴巴在业务实践中进行的探索之一,采用Iceberg全量数据和Kafka的增量数据来驱动新的Flink作业。如果需要过去很长时间例如一年的数据,可以采用常见的 lambda 架构,离线链路通过 kafka->flink->iceberg 同步写入到数据湖,由于 Kafka 成本较高,保留最近 7 天数据即可,Iceberg 存储成本较低,可以存储全量的历史数据,启动新 Flink 作业的时候,只需要去拉 Iceberg 的数据,跑完之后平滑地对接到 kafka 数据即可。
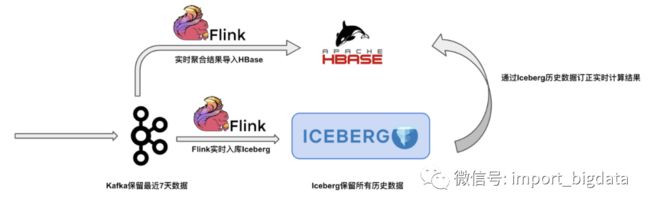
同样是在 lambda 架构下,实时链路由于事件丢失或者到达顺序的问题,可能导致流计算端结果不一定完全准确,这时候一般都需要全量的历史数据来订正实时计算的结果。而我们的 Iceberg 可以很好地充当这个角色,因为它可以高性价比地管理好历史数据。
腾讯数据平台部Flink + Iceberg 全场景实时数仓
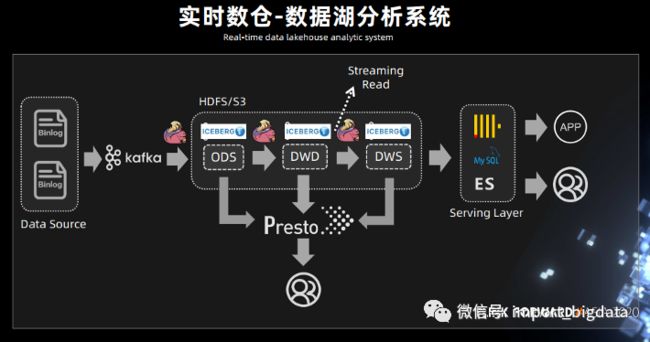
在腾讯数据平台部高级工程师苏舒的分享中,基于 Iceberg snapshot 的 Streaming reader 功能,在传统的Kappa架构基础上,将 Kafka 替换成 Iceberg。
在中间处理层,用 presto 进行一些简单的查询,因为 Iceberg 支持 Streaming read,所以在系统的中间层也可以直接接入 Flink,直接在中间层用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。
这样把离线任务天级别到小时级别的延迟大大的降低,改造成了一个近实时的数据湖分析系统。
未来期待
目前Apache Iceberg坚定不移在向一个通用的 Table Format方向前进,与下游的引擎和存储解耦,未来是有非常可能成为 Table Format 层的事实标准。
另外正如阿里巴巴的胡争前辈所述:
Apache Iceberg 正在朝着流批一体的数据湖存储层发展,manifest 和snapshot 的设计,有效地隔离不同 transaction 的变更,非常方便批处理和增量计算。而我们知道 Apache Flink 已经是一个流批一体的计算引擎,可以说这二者的长远规划完美匹配,未来二者将合力打造流批一体的数据湖架构。

我看好数据湖的未来,但不看好数据湖的现在
数据湖VS数据仓库?湖仓一体了解一下
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧