利用碎片时间阅读了一下Flink的源码,选择Flink主要出发点还是了解一个稳定的分布式计算系统的实现,另外也是由于Flink相对更加成熟的Spark有其独到的优势,相信其在下一代分布式计算中也会占有重要的地位。Flink的主要概念可以在官网了解
Flink系统作业的提交和调度都是利用AKKA的Actor通信,因此也是由此作为切入点,首先理清整个系统的启动以及作业提交的流程和数据流。
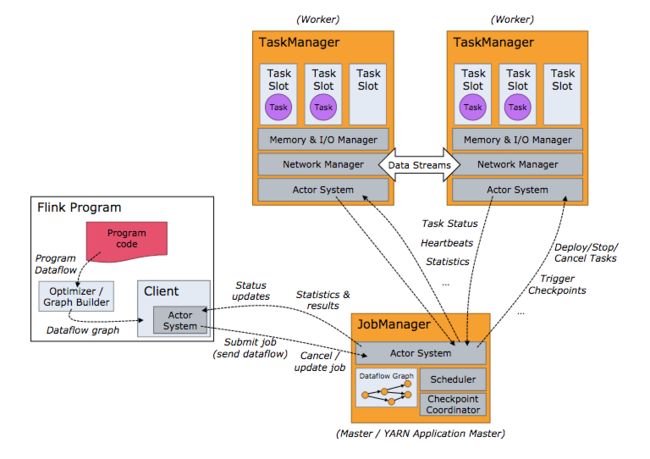
图中可以看到,一个完整的Flink系统由三个Actor System构成,包括Client、JobManager(JM)以及TaskManager(TM)。下面对三个Actor系统的创建进行分析。
JM ActorSystem
JM是Flink系统的调度中心,这部分除了会看到JM ActorSystem的创建,还会了解到整个Flink系统的各个模块的初始化与运行。
先找程序入口,从启动脚本可以追溯到,每一个启动脚本最终都会运行flink_deamon.sh 脚本,查看该脚本:
...
...
case $DAEMON in
(jobmanager)
CLASS_TO_RUN=org.apache.flink.runtime.jobmanager.JobManager
;;
(taskmanager)
CLASS_TO_RUN=org.apache.flink.runtime.taskmanager.TaskManager
;;
(zookeeper)
CLASS_TO_RUN=org.apache.flink.runtime.zookeeper.FlinkZooKeeperQuorumPeer
;;
(*)
echo "Unknown daemon '${DAEMON}'. $USAGE."
exit 1
;;
esac
$JAVA_RUN $JVM_ARGS ${FLINK_ENV_JAVA_OPTS} "${log_setting[@]}" -classpath "`manglePathList "$FLINK_TM_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" ${CLASS_TO_RUN} "${ARGS[@]}" > "$out" 2>&1 < /dev/null &
...
...
由此找到JM的程序入口:org.apache.flink.runtime.jobmanager.JobManager.scala,代码中可以找到main函数,调用runJobManager方法:
def runJobManager(
configuration: Configuration,
executionMode: JobManagerMode,
listeningAddress: String,
listeningPort: Int)
: Unit = {
//startActorSystemAndJobManagerActors返回jobManagerSystem
val (jobManagerSystem, _, _, webMonitorOption, _) = startActorSystemAndJobManagerActors(
configuration,
executionMode,
listeningAddress,
listeningPort,
classOf[JobManager],
classOf[MemoryArchivist],
Option(classOf[StandaloneResourceManager])
)
// 阻塞,直到系统退出
jobManagerSystem.awaitTermination()
webMonitorOption.foreach{
webMonitor =>
try {
webMonitor.stop()
} catch {
case t: Throwable =>
LOG.warn("Could not properly stop the web monitor.", t)
}
}
}
runJobManager方法逻辑比较简单,调用startActorSystemAndJobManagerActors方法中创建ActorSystem和JMActor,然后阻塞等待系统退出,看具体的JM创建过程:
def startActorSystemAndJobManagerActors(
configuration: Configuration,
executionMode: JobManagerMode,
listeningAddress: String,
listeningPort: Int,
jobManagerClass: Class[_ <: JobManager],
archiveClass: Class[_ <: MemoryArchivist],
resourceManagerClass: Option[Class[_ <: FlinkResourceManager[_]]])
: (ActorSystem, ActorRef, ActorRef, Option[WebMonitor], Option[ActorRef]) = {
LOG.info("Starting JobManager")
// Bring up the job manager actor system first, bind it to the given address.
val hostPortUrl = NetUtils.hostAndPortToUrlString(listeningAddress, listeningPort)
LOG.info(s"Starting JobManager actor system at $hostPortUrl")
val jobManagerSystem = try {
val akkaConfig = AkkaUtils.getAkkaConfig(
configuration,
Some((listeningAddress, listeningPort))
)
if (LOG.isDebugEnabled) {
LOG.debug("Using akka configuration\n " + akkaConfig)
}
AkkaUtils.createActorSystem(akkaConfig)//创建ActorSystem全局仅有一个
}
catch {
...
...
}
...
...//此处省略webMonitor的创建
try {
// bring up the job manager actor
LOG.info("Starting JobManager actor")
val (jobManager, archive) = startJobManagerActors(
configuration,
jobManagerSystem,
jobManagerClass,
archiveClass)
// start a process reaper that watches the JobManager. If the JobManager actor dies,
// the process reaper will kill the JVM process (to ensure easy failure detection)
LOG.debug("Starting JobManager process reaper")
jobManagerSystem.actorOf(
Props(
classOf[ProcessReaper],
jobManager,
LOG.logger,
RUNTIME_FAILURE_RETURN_CODE),
"JobManager_Process_Reaper")
// bring up a local task manager, if needed
if (executionMode == JobManagerMode.LOCAL) {
LOG.info("Starting embedded TaskManager for JobManager's LOCAL execution mode")
val taskManagerActor = TaskManager.startTaskManagerComponentsAndActor(
configuration,
ResourceID.generate(),
jobManagerSystem,
listeningAddress,
Some(TaskManager.TASK_MANAGER_NAME),
None,
localTaskManagerCommunication = true,
classOf[TaskManager])
LOG.debug("Starting TaskManager process reaper")
jobManagerSystem.actorOf(
Props(
classOf[ProcessReaper],
taskManagerActor,
LOG.logger,
RUNTIME_FAILURE_RETURN_CODE),
"TaskManager_Process_Reaper")
}
...
...
(jobManagerSystem, jobManager, archive, webMonitor, resourceManager)
}
...
...
}
这里可以看到startActorSystemAndJobManagerActors方法中利用AkkaUtils和flinkConfig创建了全局的ActorSystem,AkkaUtils也是对Actor创建的简单封装,这里不再赘述。紧接着利用刚创建的jobManagerSystem和jobManager的类名:jobManagerClass创建jobManager。除了jobManager以外,该方法中还创建了Flink的其他重要模块,从返回值中可以清楚看到。另外本地模式启动方式下,还会创建本地的启动本地的taskManagerActor。继续深入到startJobManagerActors,该方法接收jobManagerSystem等参数,创建jobManager和archive并返回:
def startJobManagerActors(
configuration: Configuration,
actorSystem: ActorSystem,
jobManagerActorName: Option[String],
archiveActorName: Option[String],
jobManagerClass: Class[_ <: JobManager],
archiveClass: Class[_ <: MemoryArchivist])
: (ActorRef, ActorRef) = {
val (executorService: ExecutorService,
instanceManager,
scheduler,
libraryCacheManager,
restartStrategy,
timeout,
archiveCount,
leaderElectionService,
submittedJobGraphs,
checkpointRecoveryFactory,
savepointStore,
jobRecoveryTimeout,
metricsRegistry) = createJobManagerComponents(
configuration,
None)
val archiveProps = Props(archiveClass, archiveCount)
// start the archiver with the given name, or without (avoid name conflicts)
val archive: ActorRef = archiveActorName match {
case Some(actorName) => actorSystem.actorOf(archiveProps, actorName)
case None => actorSystem.actorOf(archiveProps)
}
val jobManagerProps = Props(
jobManagerClass,
configuration,
executorService,
instanceManager,
scheduler,
libraryCacheManager,
archive,
restartStrategy,
timeout,
leaderElectionService,
submittedJobGraphs,
checkpointRecoveryFactory,
savepointStore,
jobRecoveryTimeout,
metricsRegistry)
val jobManager: ActorRef = jobManagerActorName match {
case Some(actorName) => actorSystem.actorOf(jobManagerProps, actorName)
case None => actorSystem.actorOf(jobManagerProps)
}
(jobManager, archive)
}
这里首先createJobManagerComponents方法创建了jobManager的重要组成模块,包括了存储、备份等策略的组件实现,还包括以后会遇到的scheduler、submittedJobGraphs,分别负责job的调度和作业的提交,这里暂不深入。
jobManagerActor已经成功创建,但是Scala中一个Actor会继承Actor类,并重写receive方法接受信息并处理,由此可以发现.JobManager类继承FlinkActor,再看FlinkActor:
trait FlinkActor extends Actor {
val log: Logger
override def receive: Receive = handleMessage
/** Handle incoming messages
* @return
*/
def handleMessage: Receive
def decorateMessage(message: Any): Any = {
message
}
}
可以看到receive方法被重写,并赋值为handleMessage,所以处理消息的操作被放在FlinkActor子类Jobmanager的handleMessage方法中:
override def handleMessage: Receive = {
...
...
case SubmitJob(jobGraph, listeningBehaviour) =>
val client = sender()
val jobInfo = new JobInfo(client, listeningBehaviour, System.currentTimeMillis(),
jobGraph.getSessionTimeout)
submitJob(jobGraph, jobInfo)
...
...
handleMessage方法中处理的消息很多,包括了诸如作业恢复,leader决策,TM注册,作业的提交、恢复与取消,这里暂时只关注消息SubmitJob(jobGraph, listeningBehaviour),消息的定义很简单,不再追溯。而SubmitJob消息的主要获取Client传来的jobGraph以及listeningBehaviour。Flink的作业最后都会抽象为jobGraph交给JM处理。关于jobGraph的生成,会在后面的Job生成的过程中进行分析。
JM对job的处理函数submitJob(jobGraph, jobInfo),参数jobInfo中包括了Client端的ActorRef,用以Job处理结果的返回,该函数中实现了JM对作业的提交与处理的细节,为突出重点,放在作业处理部分分析。但从该方法的注释来看:
/**
* Submits a job to the job manager. The job is registered at the libraryCacheManager which
* creates the job's class loader. The job graph is appended to the corresponding execution
* graph and the execution vertices are queued for scheduling.
*
* @param jobGraph representing the Flink job
* @param jobInfo the job info
* @param isRecovery Flag indicating whether this is a recovery or initial submission
*/
在该方法中将Job注册到libraryCacheManager,并将Job执行饿的DAG加入到调度队列。
小结
这里仅仅就JM Actor的创建过程对flink的源码进行了分析,主要了解到flink系统JM部分ActorSystem的组织方式,main函数最终创建JM 监听客户端的消息,并对作业进行调度和Job容错处理,最终交由TaskManager进行处理。对于具体的调度和处理策略,JM和TM的通信会在以后进行分析。接下来首先看Client端的逻辑。
原创文章,原文到我的博客