1.导入数据
2.可视化数据
3.清洗、转换数据
4.对数据编码
5.拆分训练集和测试集
6.进行学习
7.验证
8.预测
1.导入数据

Paste_Image.png

Paste_Image.png
2.可视化

Paste_Image.png
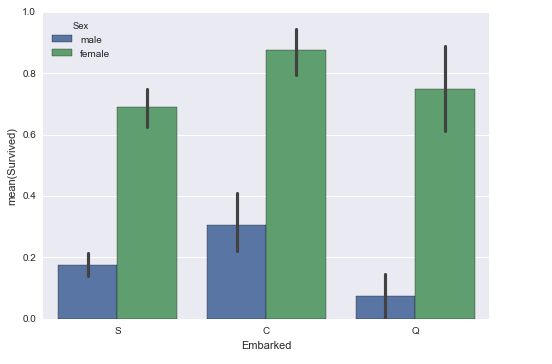
Paste_Image.png
可见在c处登船的成活率最高,女性普遍比男性高。

Paste_Image.png
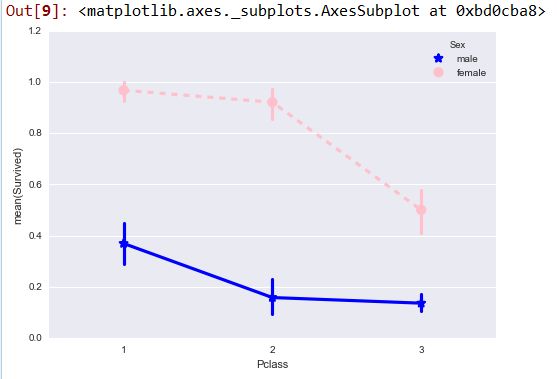
Paste_Image.png
发现社会地位高,存活率高。
3.数据清洗
#转化数据
#分组
def simplify_ages(df):
df.Age=df.Age.fillna(-0.5)
bins=(-1,0,5,12,18,25,35,60,120)
group_names=['Unknown','baby','child','teenager','student','young adult','adult','senior']
categories=pd.cut(df.Age,bins,labels=group_names)
df.Age=categories
return df
#取第一个字母
def simplify_cabins(df):
df.Cabin=df.Cabin.fillna('N')
df.Cabin=df.Cabin.apply(lambda x:x[0])
return df
#分组
def simplify_fares(df):
df.Fare=df.Fare.fillna(-0.5)
bins=(-1,0,8,15,31,1000)
group_names=['Unknown','0.25','05','0.75','1']
categories=pd.cut(df.Fare,bins,labels=group_names)
df.Fare=categories
return df
#对名字改变
def format_name(df):
df['Lname'] = df.Name.apply(lambda x: x.split(' ')[0])
df['NamePrefix'] = df.Name.apply(lambda x: x.split(' ')[1])
return df
#删除无用字段
def drop_features(df):
return df.drop(['Ticket','Name','Embarked'],axis=1)
def transform_features(df):
df = simplify_ages(df)
df = simplify_cabins(df)
df = simplify_fares(df)
df = format_name(df)
df = drop_features(df)
return df
data_train = transform_features(data_train)
data_test = transform_features(data_test)
data_train.head()
Paste_Image.png
继续进行处理后数据的可视化

Paste_Image.png

Paste_Image.png

Paste_Image.png
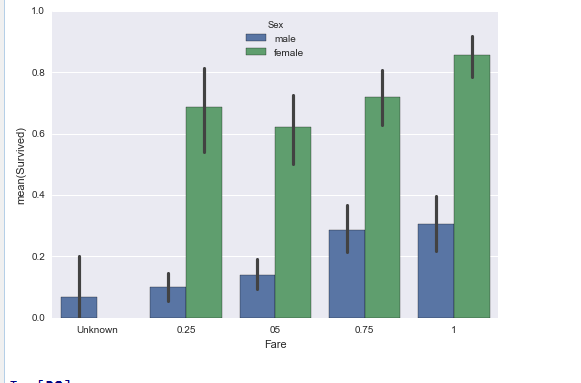
Paste_Image.png
男性低年龄段存活率高,女性高年龄段存活率高。票价越高存活率越高。
4 对数据编码
from sklearn import preprocessing
def encode_features(df_train, df_test):
features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
df_combined = pd.concat([df_train[features], df_test[features]])
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df_combined[feature])
df_train[feature] = le.transform(df_train[feature])
df_test[feature] = le.transform(df_test[feature])
return df_train, df_test
data_train, data_test = encode_features(data_train, data_test)
data_train.head()

Paste_Image.png
5.选取测试集与训练集
from sklearn.model_selection import train_test_split
x_all=data_train.drop(['Survived', 'PassengerId'], axis=1)
y_all=data_train['Survived']
num_test=0.2
x_train,x_test,y_train,y_test=train_test_split(x_all,y_all,test_size=num_test,random_state=23)
6.拟合、演算
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, accuracy_score
from sklearn.grid_search import GridSearchCV
# 选择分类器.
clf = RandomForestClassifier()
# 尝试的参数
parameters = {'n_estimators': [4, 6, 9],
'max_features': ['log2', 'sqrt','auto'],
'criterion': ['entropy', 'gini'],
'max_depth': [2, 3, 5, 10],
'min_samples_split': [2, 3, 5],
'min_samples_leaf': [1,5,8]
}
# 设置scoring参数
acc_scorer = make_scorer(accuracy_score)
# 运行格网搜索
grid_obj = GridSearchCV(clf, parameters, scoring=acc_scorer)
grid_obj = grid_obj.fit(x_train, y_train)
# 将分类器设置为估计效果最好
clf = grid_obj.best_estimator_
# 最好效果的拟合
clf.fit(x_train, y_train)
#预测结果
predictions = clf.predict(x_test)
print(accuracy_score(y_test, predictions))

Paste_Image.png
7.进行交叉检验
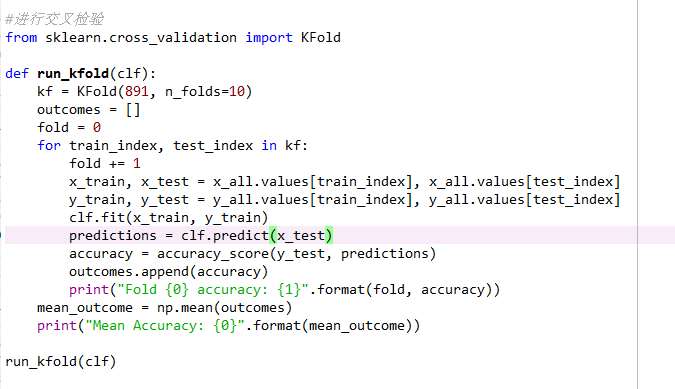
Paste_Image.png
8.预测

Paste_Image.png