redis雪崩_Redis缓存雪崩、穿透、击穿应对及常见精选面试题
随着互联网技术的持续发展,各种类型的应用层出不穷,使得当今成为云计算、大数据盛行的时代,因此也对应用的性能要求更高,高并发低延迟、海量数据流量、大规模集群管理已成基础要求。为了克服这些问题,NoSQL技术应运而生,它同时具备了高性能、可扩展性强、高可用等优点,受到开发者的青睐。Redis已成为如今最受欢迎的技术之一,也成了分布式项目中的缓存标配。

1,Redis是什么?
Redis 是开源免费的,基于内存的一款高性能 key-value 数据库。也是目前最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、可实现持久化键值对存储数据,其具备如下特性:
基于内存运行,性能高效
支持多种数据类型,可持久化
支持分布式,理论上可以无限扩展
key-value存储系统
单线程运行,操作具有原子性
开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
Redis的应用场景包括:缓存系统(热点数据:高频读、低频写)、计数器、发布订阅、消息队列、排行榜、分布式锁和实时系统等。

3,Redis的数据类型及主要特性?
Redis提供的数据类型主要分为5种自有类型和一种自定义类型,这5种自有类型包括:String类型、哈希类型、列表类型、集合类型和顺序集合类型。String类型:
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。 哈希类型: 该类型是field和关联的value组成的map。其中,field和value都是字符串类型。 列表类型: 该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。 集合类型: Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。 Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。顺序集合类型:
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。4,Redis 持久化机制及各自的优缺点?
Redis提供两种持久化机制 RDB 和 AOF 机制:
1)RDB (Redis DataBase)持久化方式;
是用数据快照的方式持久化记录 redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件存在磁盘上,在Redis故障重启后自动获取这个文件恢复数据。
优点:
只有一个文件 dump.rdb,方便持久化。
容灾性好,一个文件可以保存到安全的磁盘。
性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis的高性能)
相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
2)AOF (Append-only file)持久化方式;
采用AOF持久方式时,Redis会把每一个写请求都记录在一个日志文件里。在Redis重启时,会把AOF文件中记录的所有写操作顺序执行一遍,确保数据恢复到最新。AOF默认是关闭的,如要开启,进行如下配置:
appendonly yes
AOF提供了三种fsync配置,always/everysec/no,通过[appendfsync]指定:appendfsync no:不进行fsync,将flush文件的时机交给OS决定,速度最快;
appendfsync always:每写入一条日志就进行一次fsync操作,数据安全性最高,但速度最慢;
appendfsync everysec:折中的做法,交由后台线程每秒fsync一次;
优点:
数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录到 aof 文件中一次。
通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof工具解决数据一致性问题。
AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令。
缺点:
AOF 文件比 RDB 文件大,且恢复速度慢。
数据集大的时候,比 rdb 启动效率低。
5,Redis 常见性能问题和解决方案:
1)Master 上最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务。
2)如果数据比较重要,某Slave 开启 AOF 备份数据,策略设置每秒同步一次。
3)为了主从复制速度和连接的稳定性,Master 和 Slave 最好在同一个局域网。
4)尽量避免在压力很大的主库上增加从库。
5)主从复制不要用图状结构,用单向链表结构更为稳定,即:Master
6,Redis 集群实现及集群的原理是什么?
Redis集群实现有两种方式,如下:
1)Redis Sentinal,是着眼于高可用,在 master 宕机时会自动将 slave 提升为master,继续提供服务。
2)Redis Cluster,着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。
7,redis 过期键的删除策略?
1)定时删除:在设置键的过期时间的同时,创建一个定时器 timer,让定时器在键的过期时间来临时,立即执行对键的删除操作。 2)惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。 3)定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。8,使用Redis 做异步队列,你是怎么用的?
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。关于可不可以不用 sleep?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。如果被追问能不能生产一次消费多次呢?那使用 pub/sub 主题订阅者模式,可以实现1:N 的消息队列。
1)pub/sub 有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 RabbitMQ等。
2)redis 如何实现延时队列?
使用 sortedset,拿时间戳作为score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
Redis缓存安全防范分布式项目使用Redis缓存,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。另外的一些典型问题,就是缓存穿透、缓存雪崩和缓存击穿。
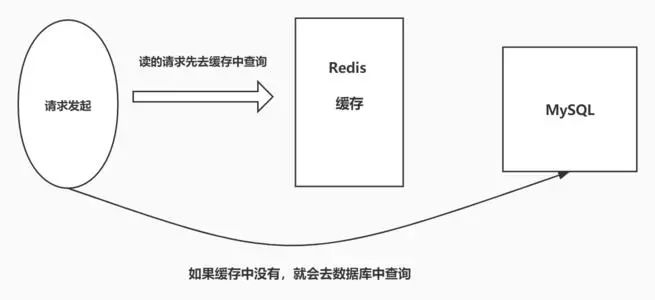
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。如果用户发起id为“-1”或id特别大不存在的数据。这时很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
1,接口层增加校验。对id做基础校验,id<=0的直接拦截;
2,从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value键值对写为key-null,缓存有效时间可以设置短点,如60秒(设置太长会导致正常情况也没法使用),这样可以防止攻击用户反复用同一个id暴力攻击。
2,缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。产生雪崩的原因之一,比如马上就到618了,很快就会迎来一波抢购,这些要抢购的商品在同一时间点(17号23点放入)比较集中的放入了缓存,假设缓存两个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而此时对这批商品的访问查询,都落到了数据库身上,这时对于数据库而言,就会带来极大的压力。
解决方案:
1,在设置数据缓存有效期时,在时间后加上一个随机因子。
2,分散缓存过期时间,将热门类数据缓存时间长一点,冷门类的短一点。
3,设置热点数据永不过期。
3,缓存击穿缓存击穿,是指一个key非常热点,高并发集中对这个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像春运期间火车站售票大厅,本来那些设在门口和广场的自助机可以办理售票,结果自助机瞬间全部瘫痪,造成大量买票的人涌进售票大厅人工窗口。
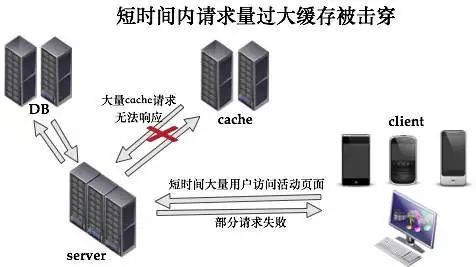
解决方案:
1,设置热点数据永远不过期;
2,加互斥锁,互斥锁参考代码如下:
推荐阅读:SpringCloud微服务项目实战 - 缓存详解及高效缓存接入
SpringCloud微服务项目实战 - 限流、熔断、降级处理 SpringCloud微服务项目实战 - API网关Gateway详解实现SpringCloud微服务项目实战 - 网关zuul详解及搭建

扫码关注公众号,发送关键词获取相关资料:
发“Springboot”领取电商项目实战源码;
发“SpringCloud”领取学习实战资料;