Redis系列(十六)、Redis6新特性之IO多线程
终于,Redis的多线程版本横空出世,大大提高了并发,本篇就带大家来看看什么是IO多线程,和我们理解的多线程有什么区别,与Memcached的多线程又有什么区别。
目录
介绍
为什么Redis6.0之前是单线程模型
什么是IO多线程
开启IO多线程
性能对比
源码解析
对比Memcached
尾巴
Redis6系列文章:
Redis系列(一)、CentOS7下安装Redis6.0.3稳定版
Redis系列(二)、数据类型之字符串String
Redis系列(三)、数据类型之哈希Hash
Redis系列(四)、数据类型之列表List
Redis系列(五)、数据类型之无序集合Set
Redis系列(六)、数据类型之有序集合ZSet(sorted_set)
Redis系列(七)、常用key命令
Redis系列(八)、常用服务器命令
Redis系列(九)、Redis的“事务”及Lua脚本操作
Redis系列(十)、详解Redis持久化方式AOF、RDB以及混合持久化
Redis系列(十一)、Redis6新特性之ACL安全策略(用户权限管理)
Redis系列(十二)、Redis6集群搭建及原理(主从、哨兵、集群)
Redis系列(十三)、pub/sub发布与订阅(对比List和Kafka)
Redis系列(十四)、Redis6新特性之RESP3与客户端缓存(Client side caching)
Redis系列(十五)、Redis6新特性之集群代理(Cluster Proxy)
介绍
作为Redis6版本中的其中一大新特性,IO多线程大大提升了Redis的并发性能。该功能也是在社区内被反复提起,而之前Antirez在自己的博客中也曾经做过简单的介绍:
http://antirez.com/news/126
【## Multi threading】
为什么Redis6.0之前是单线程模型
首先我们要明确一个共识,我们通常所说的Redis单线程是指获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这个主线程就是我们平时说的"单线程",而其他的清理脏数据、无用连接的释放、LRU淘汰策略等等也是有其他线程在处理的,因此其实在Redis6之前的Redis本质上也是多线程的。
为什么这些操作要放在同一个主线程中,官方给出的解释:传送门
- 通常瓶颈不在 CPU,而是在内存和网络IO;
- 多线程会带来线程不安全的情况;
- 多线程可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗;
- 单线程降低了Redis内部实现复杂度;
- hash的惰性rehash,lpush等线程不安全的命令可以无锁执行;
什么是IO多线程
既然上面说单线程那么好,为什么Redis6.0又要引入多线性呢?
Redis 抽象了一套 AE 事件模型,将 IO 事件和时间事件融入一起,同时借助多路复用机制(linux上用epoll) 的回调特性,使得 IO 读写都是非阻塞的,实现高性能的网络处理能力。加上 Redis 基于内存的数据处理,这就是 “单线程,但却高性能” 的核心原因。
但 IO 数据的读写依然是阻塞的,这也是 Redis 目前的主要性能瓶颈之一,特别是在数据吞吐量特别大的时候,具体情况如下:
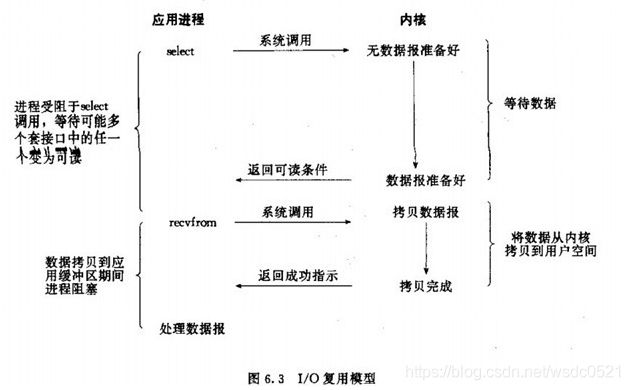
上图的下半部分,当 socket 中有数据时,Redis 会通过系统调用将数据从内核态拷贝到用户态,供 Redis 解析用。这个拷贝过程是阻塞的,术语称作 “同步 IO”,数据量越大拷贝的延迟越高,时间消耗也越大,糟糕的是这些操作都是单线程处理的。(写 reponse 时也是一样)
这是 Redis 目前的瓶颈之一,Redis6.0 引入的 “多线程” 机制就是对于该瓶颈的优化。核心思路是,将主线程的 IO 读写任务拆分出来给一组独立的线程执行,使得多个 socket 的读写可以并行化。
与 Memcached 从 IO 处理到数据访问多线程的实现模式有些差异。Redis 的IO多线程只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想 Redis 因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。
开启IO多线程
默认情况下,Redis多线程是禁用的,我们可以在配置文件选择开启:
vim redis.conf
#开启IO多线程
io-threads-do-reads yes
#配置线程数量,如果设为1就是主线程模式。
io-threads 4
官方建议:至少4核的机器才开启IO多线程,并且除非真的遇到了性能瓶颈,否则不建议开启此配置 ,且配置的线程数少于机器总线程数,如果有4核建议开启2,3个线程,如果有8核建议开6线程。 线程并不是越多越好,多于8个线程意义不大。
性能对比
因资源有限,我手边的机器渣渣配置如下,开启3个线程对比单线程:
配置:
[root@BD-T-uatredis9 ~]# free -h
total used free shared buff/cache available
Mem: 15G 1.0G 13G 64M 1.2G 14G
Swap: 4.0G 0B 4.0G
[root@BD-T-uatredis9 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 4
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E7-4809 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2094.952
BogoMIPS: 4189.90
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-3测试命令:
使用redis-benchmark进行压测,这里模拟在4核4线程的机器上分别测试3线程和单线程在100W请求,数据大小在128b,512b,1024b,200个客户端,执行SET和GET的QPS性能对比
#三线程
./redis-benchmark -h localhost -p 6380 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 --threads 3 -d 128 -c 200 -q
./redis-benchmark -h localhost -p 6380 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 --threads 3 -d 512 -c 200 -q
./redis-benchmark -h localhost -p 6380 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 --threads 3 -d 1024 -c 200 -q
#单线程
./redis-benchmark -h localhost -p 6381 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 -d 128 -c 200 -q
./redis-benchmark -h localhost -p 6381 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 -d 512 -c 200 -q
./redis-benchmark -h localhost -p 6381 --user default -a wyk123456 -t set,get -n 1000000 -r 1000000 -d 1024 -c 200 -q结果:
可能是我机器太渣了,3线程比单线程的QPS提升有120%~140%,网友测试的在4线程下QPS提升了100%。。

网友的测试结果:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge
Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge 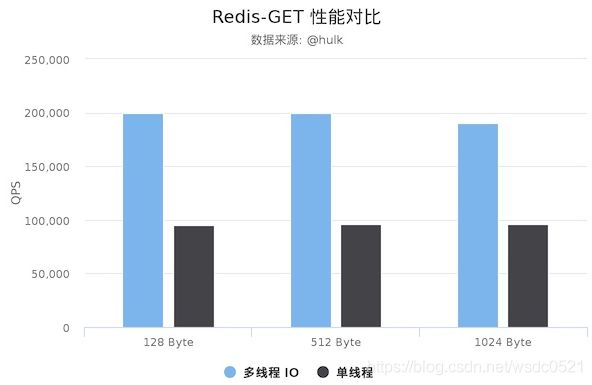
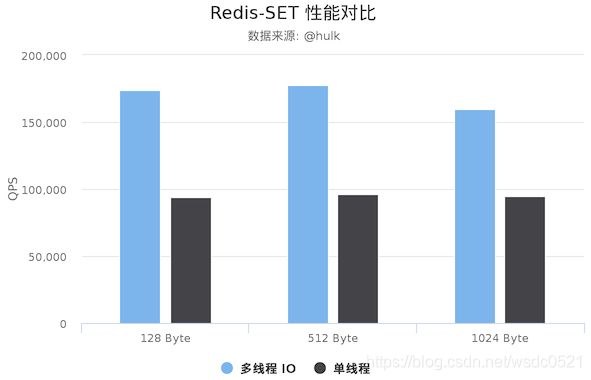
注意,数据仅供验证参考,不能作为线上指标:
- 本测试只是使用早期的
unstble分支的性能,不排除稳定版的性能会更好。- 本测试并没有针对严谨的延时控制和不同并发的场景进行压测。
源码解析
刚才提到IO多线程只是在网络数据的读写上是多线程了,具体流程如下:
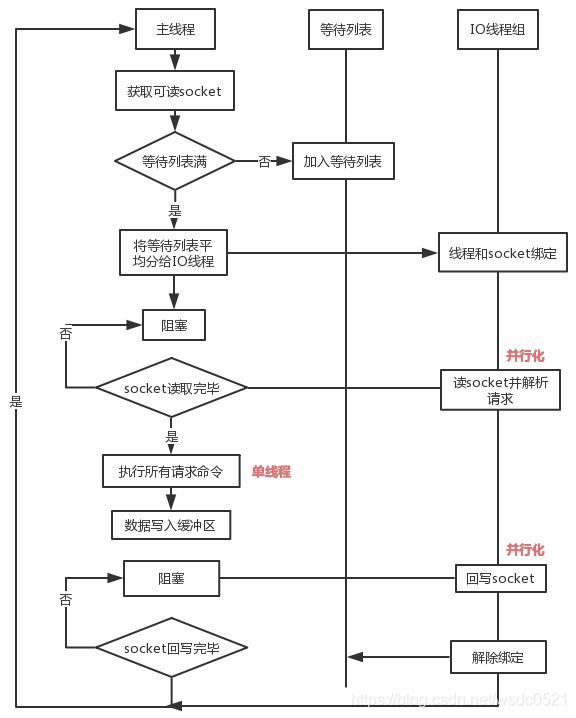
流程:
- 主线程获取 socket 放入等待列表
- 将 socket 分配给各个 IO 线程(并不会等列表满)
- 主线程阻塞等待 IO 线程读取 socket 完毕
- 主线程以单线程执行命令 (如果命令没有接收完毕,会等 IO 下次继续)
- 主线程阻塞等待 IO 线程将数据回写 socket 完毕(一次没写完,会等下次再写)
- 解除绑定,清空等待队列
- IO 线程要么同时在读 socket,要么同时在写,不会同时读或写;
- IO 线程只负责读写 socket 解析命令,不负责执行命令,由主线程串行执行命令;
- IO 线程数可配置,默认为 1;
- 上面的过程是完全无锁的,因为在 IO 线程处理的时主线程会等待全部的 IO 线程完成,所以不会出现 data race 的场景。
源码:
https://github.com/redis-io/redis/blob/6.0/src/networking.c
redis-server 逻辑首先执行 initThreadedIO()函数对 线程进行初始化,当然,也包括 根据配置 server.io_threads_num 控制线程个数,其中主线程的处理逻辑为 IOThreadMain() 函数
/* networking.c: line 2666 */
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is used by the thread to just manipulate a single sub-array of clients. */
// 线程 ID,跟普通线程池的操作方式一样,都是通过 线程ID 进行操作
long id = (unsigned long)myid;
while(1) {
/* Wait for start */
// 这里的等待操作比较特殊,没有使用简单的 sleep,避免了 sleep 时间设置不当可能导致糟糕的性能,但是也有个问题就是频繁 loop 可能一定程度上造成 cpu 占用较长
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
/* Give the main thread a chance to stop this thread. */
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
// debug 模式
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
/* Process: note that the main thread will never touch our list
* before we drop the pending count to 0. */
// 根据线程 id 以及待分配列表进行 任务分配
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 判断读写类型
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
// 这里需要注意重复调用了 readQueryFromClient,不过不用担心,有 CLIENT_PENDING_READ 标识可以进行识别
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}handleClientsWithPendingReadsUsingThreads() 待处理任务分配
/* networking.c: line 2871 */
/* When threaded I/O is also enabled for the reading + parsing side, the readable handler will just put normal clients into a queue of clients to process (instead of serving them synchronously). This function runs the queue using the I/O threads, and process them in order to accumulate the reads in the buffers, and also parse the first command available rendering it in the client structures. */
int handleClientsWithPendingReadsUsingThreads(void) {
// 是否开启 线程读
if (!io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
/* Distribute the clients across N different lists. */
// 将待处理任务进行分配,分配方式为 RR (round robin) 即基于任务到达时间片进行分配
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
/* Give the start condition to the waiting threads, by setting the start condition atomic var. */
// 设定任务个数参数
io_threads_op = IO_THREADS_OP_READ;
for (int j = 0; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
/* Wait for all threads to end their work. */
// 等待所有线程任务都处理完毕
while(1) {
unsigned long pending = 0;
for (int j = 0; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
/* Run the list of clients again to process the new buffers. */
// 继续运行,等待新的处理任务
listRewind(server.clients_pending_read,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~ CLIENT_PENDING_COMMAND;
processCommandAndResetClient(c);
}
processInputBufferAndReplicate(c);
}
listEmpty(server.clients_pending_read);
return processed;
}readQueryFromClient() 函数
/* networking.c: line 1791 */
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from the event loop. This is the case if threaded I/O is enabled. */
// 加入多线程模型已经启用
if (postponeClientRead(c)) return;
// 如果没有启用多线程模型,则走下面继续处理读逻辑
// ....还有后续老逻辑
} 函数 postponeClientRead() 将任务放入处理队列,而根据上面 IOThreadMain() 和 handleClientsWithPendingReadsUsingThreads() 的任务处理逻辑进行处理
/* networking.c: line 2852 */
int postponeClientRead(client *c) {
// 如果启用多线程模型,并且判断全局配置中是否支持多线程读
if (io_threads_active &&
server.io_threads_do_reads &&
// 这里有个点需要注意,如果是 master-slave 同步也有可能被认为是普通 读任务,所以需要标识
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
c->flags |= CLIENT_PENDING_READ;
// 将任务放入处理队列
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}对比Memcached
前些年memcached 是各大互联网公司常用的缓存方案,因此redis 和 memcached 的区别基本成了面试官缓存方面必问的面试题,最近几年memcached用的少了,基本都是 redis。不过随着Redis6.0加入了多线程特性,类似的问题可能还会出现,接下来我们只针对多线程模型来简单比较一下它们。
首先看一下Memcached的线程模型:
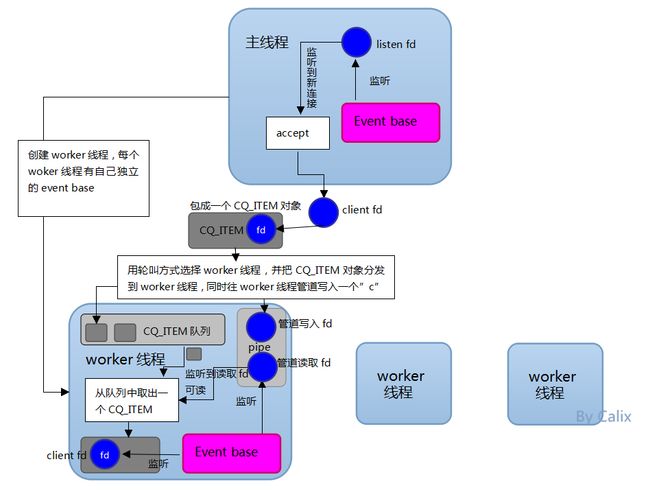
如上图所示:Memcached 服务器采用 master-woker 模式进行工作,服务端采用 socket 与客户端通讯。主线程、工作线程 采用 pipe管道进行通讯。主线程采用 libevent 监听 listen、accept 的读事件,事件响应后将连接信息的数据结构封装起来,根据算法选择合适的工作线程,将连接任务携带连接信息分发出去,相应的线程利用连接描述符建立与客户端的socket连接 并进行后续的存取数据操作。
Redis6.0与Memcached多线程模型对比:
相同点:都采用了 master线程-worker 线程的模型
不同点:Memcached 执行主逻辑也是在 worker 线程里,模型更加简单,实现了真正的线程隔离,符合我们对线程隔离的常规理解。而 Redis 把处理逻辑交还给 master 线程,虽然一定程度上增加了模型复杂度,但也解决了线程并发安全等问题。
尾巴
大家都会拿Redis和memcached对比,但Redis不是memcached,它只是做到like memcached的多线程,而不是跟memcached一样的完全隔离的多线程模型。Redis中因为有lua脚本,事务,Lpush等等复杂性,需要考虑的问题很多,不管怎么样,最新版的Redis6带给我们的IO多线程着实是个惊喜,互联网大厂们应该很快就会纷纷上线此功能了!
参考
https://ruby-china.org/topics/38957
http://www.web-lovers.com/redis-source-6-rc-mult-thread.html
https://zhuanlan.zhihu.com/p/76788470
http://calixwu.com/2014/11/memcached-yuanmafenxi-xianchengmoxing.html
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!