论文笔记(五) C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection
文章目录
- 论文笔记(五) C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection
-
- introduction
-
- 问题定义
- 局部极小问题
- 平滑和延续方法
- Contribution
-
- C-MIL方法
- 子集划分策略
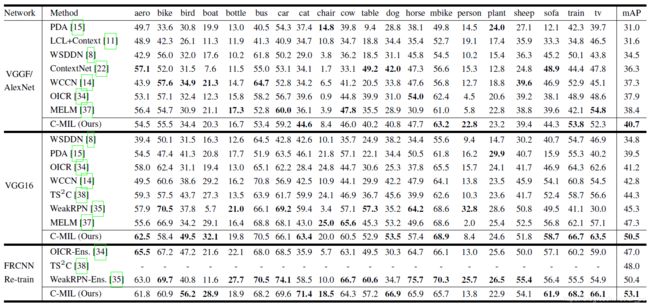
- 实验结果
论文笔记(五) C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection
这是cvpr2019的oral,还是一篇基于弱监督的目标检测论文。
关于弱监督目标检测的定义在上一篇笔记中已经讲过了 传送门 。与上一篇论文中要缓解的问题一样,即弱监督的损失局部极小问题,但是这篇论文的处理方法更为理论化,而不是对模型架构进行调整。
introduction
问题定义
B B B表示图片的集合, B i B_i Bi表示第 i i i张图片。 y = 1 , − 1 y={1, -1} y=1,−1, y i ∈ y y_i\in y yi∈y表示 B i B_i Bi中是否包含样本。 j ∈ 1 , 2 , . . . , N j\in {1,2,...,N} j∈1,2,...,N,N表示目标的数量 B i , j B_{i,j} Bi,j和 y i , j y_{i,j} yi,j表示图片 B i B_i Bi中的目标和目标的标签, w w w表示网络所需要训练的参数。
局部极小问题
在上一篇论文中是从模型架构的角度来缓解这个问题,所以一笔带过了。而在这篇论文中,作者是从优化的角度来缓解此问题。
在MIL网络中,一般分为两部分,即一个选择器和一个检测器,选择器负责将所有候选框分为正样本和负样本,是一个二分类问题,损失函数采用的是hinge loss:
F f ( B , w ) = max ( 0 , 1 − y i max i f ( B i , j , w f ) ) F_f(B,w)=\max(0, 1-y_i\max_if(B_{i,j},w_f)) Ff(B,w)=max(0,1−yimaxif(Bi,j,wf))
检测器负责对所有正样本的类别进行分类,其损失函数为交叉熵损失:
F g ( B i , B i , j ∗ , w g ) = − ∑ z ∑ j δ z , y i , j l o g g z ( B i , j , w g ) F_g(B_i,B_{i,j^*},w_g)=-\sum_z \sum_j \delta_{z,y_{i,j}}log g_z(B_{i,j},w_g) Fg(Bi,Bi,j∗,wg)=−∑z∑jδz,yi,jloggz(Bi,j,wg)
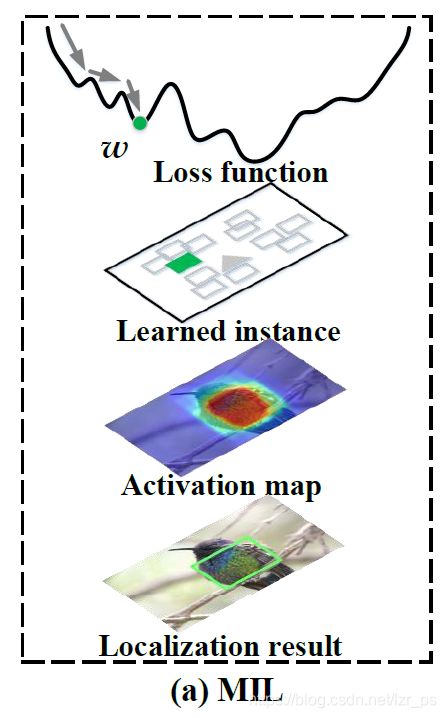
可以看到,当 y i = − 1 y_i=-1 yi=−1时,选择器的损失函数为凸函数,而当 y i = 1 y_i=1 yi=1时是非凸的,所以就导致了在训练正样本时会陷入一个局部的极小值。笼统的来说,选择器会选择物体的一部分(比如猫的头)就作为该目标的location,而不是整个物体(如下图所示)。
平滑和延续方法
平滑(smoothing)是一种常见的优化方法,其目的时让优化目标的变化不那么陡峭。
延续方法(continuation)是一种思想,就是面对复杂而难以优化的问题时,把其分为若干个易于优化的子问题进行求解
Contribution
通过前面的铺垫,后面就轻松很多了
本文的主要贡献有三个:
1.提出了一个新奇的C-MIL方法,用一系列的平滑损失函数来近似原始损失函数,缓解多实例学习中的非凸性问题
2.为目标子集的分割提出了一种参数策略,并于深度神经网络结合来激活目标的全部范围。
3.sota
C-MIL方法
由上可知,局部极小的根源在于选择器损失函数的非凸性,那么怎么优化此损失函数来缓解该问题呢?
作者通过将每张图片中的实例划分为子集来处理其非凸性和平滑性。具体做法:
由前面的定义可得,我们要优化的目标为权重 w w w
w = arg min w F ( B , w ) w=\arg \min_w F(B,w) w=argminwF(B,w)
其中 F ( B , w ) F(B,w) F(B,w)为模型总损失,定义一系列 λ , 0 = λ 0 < λ 1 < . . . < λ T = 1 \lambda, 0=\lambda_0<\lambda_1<...<\lambda_T=1 λ,0=λ0<λ1<...<λT=1,在C-MIL中将该损失函数从 ( w 0 , 0 ) (w^0,0) (w0,0)到 ( w ∗ , 1 ) (w^*,1) (w∗,1)不断更新,刚开始当 λ = 0 时 \lambda=0时 λ=0时优化目标为 w 0 w^0 w0,其最终的优化目标就为:
w ∗ = arg min w F ( B , w , λ ) = arg min w f , w g ∑ i F f ( B i , B i . J ( λ ) , w f ) + F g ( B i , B i , J ( λ ) , w g ) w^*=\arg \min_w F(B,w,\lambda)=\arg \min_{w_f,w_g}\sum_i F_f(B_i,B_{i.J(\lambda)},w_f)+F_g(B_i,B_{i,J(\lambda)},w_g) w∗=argminwF(B,w,λ)=argminwf,wg∑iFf(Bi,Bi.J(λ),wf)+Fg(Bi,Bi,J(λ),wg)
其中 B i , J ( λ ) B_{i,J(\lambda)} Bi,J(λ)取决于 λ \lambda λ,代表了目标的子集。
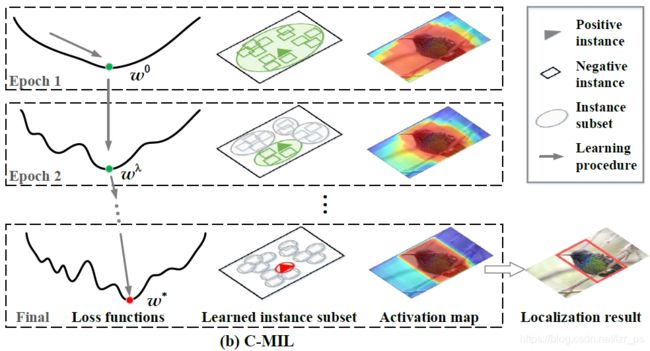
那么怎么根据 λ \lambda λ来分割子集呢?
子集划分策略
本文中的子集有如下特征:
1.空间相关,即彼此重叠且交并比够大
2.类别相关,即拥有相似的类别分数
所以有如下子集划分策略:
1.选择得分最高但是还未属于任何一个实例子集的实例建立一个新的实例子集;
2.将哪些与上述得分最高的实例交并比大于等于 λ \lambda λ的实例归入该实例子集
重复以上两个步骤以获得每一次迭代的实例子集。
由此可知,当 λ = 0 \lambda=0 λ=0时,只有一个实例子集且该子集包含所有实例;当 λ = 1 \lambda=1 λ=1时,每个实例都是一个子集,该损失函数即为不进行延续处理的损失函数。
并且每个实例子集的分数定义为:
f ( B i , J ( λ ) ) = 1 ∣ B i , J ( λ ) ∣ ∑ j f ( B i , j , w f ) f(B_{i,J(\lambda)})=\dfrac{1}{|B_{i,J(\lambda)}|}\sum_j f(B_{i,j},w_f) f(Bi,J(λ))=∣Bi,J(λ)∣1∑jf(Bi,j,wf)
∣ B i , J ( λ ) ∣ |B_{i,J(\lambda)}| ∣Bi,J(λ)∣表示该子集中实例的个数。
模型框架图:
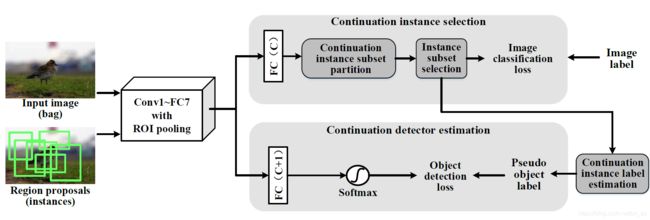 该论文在框架上没有创新,主要是对损失函数上对其进行了平滑处理,缓解了其非凸性。
该论文在框架上没有创新,主要是对损失函数上对其进行了平滑处理,缓解了其非凸性。
实验结果