一、DRBD 简介及主要功能
简单的说,DRBD (Distributed Replicated Block Device,分布式复制块设备)是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。可以把它看作是一种网络RAID1。
DRBD的主要功能是负责接收数据,把数据写到本地磁盘,然后通过网络将同样的数据发送给另一个主机,另一个主机再将数据存到自己的磁盘中

二、DRBD 工作原理
每个设备(drbd 提供了不止一个设备)都有一个状态,可能是‘主’状态或‘从’状态。在主节点上,应用程序应能运行和访问drbd设备(/dev/drbd*)。每次写入都会发往本地磁盘设备和从节点设备中。从节点只能简单地把数据写入它的磁盘设备上。 读取数据通常在本地进行。 如果主节点发生故障,心跳(heartbeat或corosync)将会把从节点转换到主状态,并启动其上的应用程序。(如果您将它和无日志FS 一起使用,则需要运行fsck)。如果发生故障的节点恢复工作,它就会成为新的从节点,而且必须使自己的内容与主节点的内容保持同步。当然,这些操作不会干扰到后台的服务。
三、DRBD 与 HA 集群
大部分现行高可用性集群使用的是共享存储器,因此存储器连接多个节点(用共享的SCSI 总线或光纤通道就可以做到)。DRBD 也可以作为一个共享的设备,但是它并不需要任何不常见的硬件。它在IP 网络中运行,而且在价格上IP 网络要比专用的存储网络经济的多。目前,DRBD 每次只允许对一个节点进行读写访问,这对于通常的故障切换高可用性集群来讲已经足够用了。现在的版本将支持两个节点同时进行读写存取。这很有用,比如对GFS 来讲就是如此。兼容性DRBD可以在IDE、SCSI 分区和整个驱动器之上运行,但不能在回路模块设备上运行。DRBD 也不能在回送网络设备中运行。因为它同样会发生死锁:所有请求都会被发送设备占用,发送流程也会阻塞在sock_sendmsg()中。有时,接收线程正从网络中提取数据块,并试图把它放在高速缓存器中;但系统却要把一些数据块从高速缓存器中取到磁盘中。这种情况往往会在接收器的环境下发生,因为所有的请求都已经被接收器块占用了。
四、DRBD 复制模式
- 协议A:异步复制协议。本地写成功后立即返回,数据放在发送buffer中,可能丢失。
- 协议B:内存同步(半同步)复制协议。本地写成功并将数据发送到对方后立即返回,如果双机掉电,数据可能丢失。
- 协议C:同步复制协议。本地和对方写成功确认后返回。如果双机掉电或磁盘同时损坏,则数据可能丢失。
- 一般用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境中还是用C协议。
五、DRBD 的安装与配置
- 实验环境:
注:不做特别说明的话就是主从节点都要进行操作,时间同步提前做好(hostname一定要修改)
操作系统:CentOS 6.9
软件版本:drbd84
master节点:192.168.1.14(node1.cloud.com)
slaver 节点:192.168.1.15(node2.cloud.com)
1.添加drbd的yum源(163,阿里,epel源中没有drdb的rpm包)
#在 /etc/yum.repos.d/CentOS-Base.repo 文件中添加以下内容
[elrepo]
name=CentOS-$releasever elrepe
failovermethod=priority
baseurl=http://elrepo.org/linux/elrepo/el6/x86_64/
gpgcheck=0
- 安装
yum makecache
yum install drbd84-utils kmod-drbd84
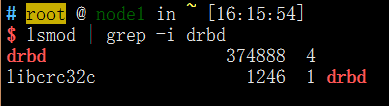
检验是否安装成功
lsmod | grep -i drbd
- 配置文件
# /etc/drbd.d/global_common.conf
global {
usage-count yes; # 是否参加DRBD使用者统计。默认是yes
}
common {
protocol C;# 传输协议采用C
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
disk {
on-io-error detach;#发生I/O错误的节点将放弃底层设备,以 diskless mode继续工作
}
}
# /etc/drbd.d/test1.res
resource test1 {
# 每个主机的说明以“on”开头,后面是主机名
on node1.cloud.com {
device /dev/drbd1; # 定义drdb的设备名
disk /dev/sdb; # /dev/drbd0使用的磁盘分区是/dev/sdb1
address 192.168.1.14:7789; # 设置DRBD的监听端口,用于与另一台主机通信
meta-disk internal;# 定义metadata的存储方式,有2种
}
on node2.cloud.com {
device /dev/drbd1;
disk /dev/sdb;
address 192.168.1.15:7789;
meta-disk internal;
}
}
转载:DRBD 配置文件详解
- 测试
- 分别在两台主机上创建供DRBD记录信息的数据块:
drbdadm create-md test1
# 报错的话试着用以下方式解决
# dd if=/dev/zero of=/dev/sdb bs=1M count=1
- 启动程序,并且设置主节点
/etc/init.d/drbd start
drbdadm -- --overwrite-data-of-peer primary test1#设置主节点
- 格式化磁盘病进行挂载(在主节点进行,)
mkfs.ext4 /dev/drbd1
mount /dev/drbd1 /drbd
- 同步测试
主节点执行:cp -a /var/cache/yum /drbd/
命令执行完成后关闭从节点的drbd服务,挂载从节点/dev/sdb到随意目录下,查看结果

六、模拟DRBD主节点出问题,从节点转为主节点后,主节点又正常
- 关闭主节点IP(node1 为主节点)


- 把从节点升级为主节点,并查看状态
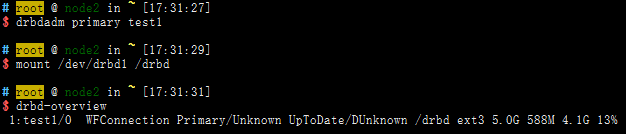
- 恢复主节点IP地址,查看drbd状态


- 恢复同步断掉前的状态(node1为主,node2为从)



七、keepalived + DRBD + NFS 构建存储节点HA

- node1 节点进行的操作(三台服务器先进行时间同步,用到的脚本具体看文末)
①、配置keepalived(keepalived.conf)
! Configuration File for keepalived
global_defs {
router_id node1
}
vrrp_script chk_nfs {
script "/etc/keepalived/check_nfs.sh" # 监测 NFS 状态的脚本
interval 5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_nfs
}
notify_stop /etc/keepalived/notify_stop.sh # keepalived 停掉时执行的脚本
notify_master /etc/keepalived/notify_master.sh # keepalived 角色转变为 master 时执行的脚本
virtual_ipaddress {
192.168.1.200
}
}
②、配置 DRBD 和 NFS
#DRBD 配置
# cat /etc/drbd.d/global_common.conf
global {
usage-count yes;
}
common {
protocol C;
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
}
options {
}
disk {
on-io-error detach;
}
net {
}
}
########################################################################################
# cat /etc/drbd.d/test1.res
resource test1 {
on node1.cloud.com {
device /dev/drbd1;
disk /dev/sdb;
address 192.168.1.14:7789;
meta-disk internal;
}
on node2.cloud.com {
device /dev/drbd1;
disk /dev/sdb;
address 192.168.1.15:7789;
meta-disk internal;
}
}
########################################################################################
# NFS 配置
# cat /etc/exports
/drbd 192.168.1.0/24(rw,insecure,sync,all_squash,anonuid=65534,anongid=65534)
- node2 节点进行的操作
①、配置keepalived(keepalived.conf)
! Configuration File for keepalived
global_defs {
router_id node2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
notify_master /etc/keepalived/notify_master.sh # 切换为 Master 时执行的脚本
notify_backup /etc/keepalived/notify_backup.sh # 切换为 BackUp 时执行的脚本
virtual_ipaddress {
192.168.1.200
}
}
DRBD 和 NFS 配置基本一致,不再贴配置文件
- 开启服务 client 端进行写入测试

现在关闭 node1 的 keepalived 服务,看写入是否正常


大约2分钟之后,写入继续在node2上进行

附录: keepalived + NFS + DRBD 配置文件