2021-02-26~27~28 大数据课程笔记 day37day38day39

@R星校长
音乐数据中心平台
1.1 数据库与ER建模
1.1.1 数据库(DataBase)
数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜,存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作,数据组织主要是面向事务处理任务。
1.1.2 数据库三范式
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性和保证数据的一致性,这些规范就可以称为范式NF(Normal Form),大多数情况下,关系型数据库的设计符合三范式即可。
第一范式(1NF):原子性,字段不可分
即表的列的具有原子性,不可再分解,即列的信息,不能分解。数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。如果实体中的某个属性有多个值时,必须拆分为不同的属性 。通俗理解即一个字段只存储一项信息。
举例如下,有如下订单表,购买商品一列,可以拆分为商品和数量两列。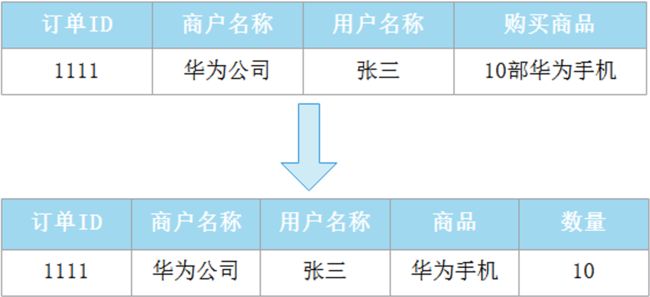
第二范式(2NF):唯一性,一个表只能说明一个事物,有主键,非主键字段依赖主键
第二范式是在第一范式的基础上建立起来的,第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分,为实现区分通常需要我们设计一个主键来实现。当存在多个主键的时候,不能存在这样的属性,它只依赖于其中一个主键,这就是不符合第二范式。通俗理解是任意一个字段都只依赖表中的同一个字段。举例如下: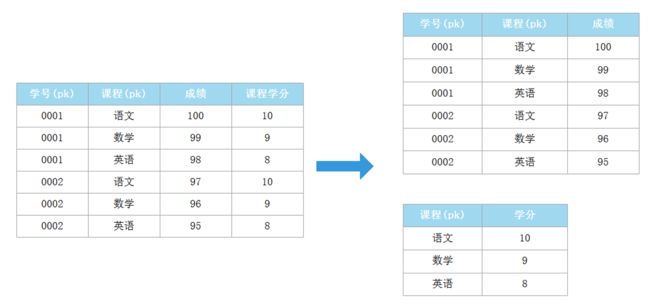
学生信息表中的成绩依赖于学号和课程两个主键,但是课程学分只是依赖课程的。可以拆分成右侧的两张表。
第三范式(3NF):非主键字段不能相互依赖,不存在传递依赖
满足第三范式必须先满足第二范式,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段(某张表的某字段信息,如果能够被推导出来,就不应该单独的设计一个字段来存放)。
如果某一属性依赖于其他非主键属性,而其他非主键属性又依赖于主键,那么这个属性就是间接依赖于主键,这被称作传递依赖于主属性。第三范式中要求任何非主属性不依赖于其它非主属性,即不存在传递依赖。很多时候,我们为了满足第三范式往往会把一张表分成多张表。
举例如下: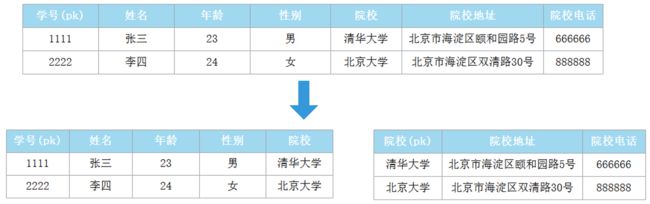
第一张表中“院校地址”是依赖于“院校”的,“院校”依赖于主键“学号”,存在传递依赖,不符合第三范式,那么需要拆解成对应的学生表和院校表两张表。
注意:三大范式只是一般设计数据库的基本理念,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,提高读性能,就必须降低范式标准,降低范式就是增加字段,减少了查询时的关联,提高查询效率,适当保留冗余数据。这就是反范式,反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
1.1.3 ER实体关系模型
ER实体关系模型(Entity-Relationship)是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建模的方式,这种建模方式基于三范式。在信息系统中,将事物抽象为“实体”、“属性”、“关系”来表示数据关联和事物描述。
实体(Entity):实体是一个数据对象,指应用中可以区别的客观存在的事物。例如:商品、用户、学生、课程等。它具有自己的属性,一类有意义的实体构成实体集。在ER实体关系模型中实体使用方框表示。
属性:对实体的描述、修饰就是属性,即:实体的某一特性称为属性。例如:商品的重量、颜色、尺寸。用户的性别、身高、爱好等。在ER实体关系模型中属性使用椭圆来表示。
关系(Relationship):表示一个或多个实体之间的关联关系。实体不是孤立的,实体之间是有联系的,这就是关系。例如:用户是实体,商品是实体,用户选购商品这个过程就会产生“选购商品数量”,“金额”这些属性,这就是关系。再如:学生是实体,课程是实体,学生选择课程这个过程就产生了“课程数量”、“分数”这些属性,这就是关系。在ER实体关系模型中关系使用菱形框表示,并用线段将其与相关的实体链接起来。
ER实体关系模型又叫E-R关系图,实体与实体之间的关系存在一对一的关系、一对多的关系、多对多的关系。
一对一关系:例如:“学生”是实体,“身份证”是实体,一个学生只能有一个身份证,一个身份证也只能对应一个学生。
一对多关系:一对多关系反过来也就成了多对一的关系。例如:“学生”是实体,“账号”是实体,一个学生有多个账号,反过来就是多个账号对应一个学生。
多对多关系:例如:“学生”是实体,“课程”是实体,一个学生可以学习多个课程,一个课程可以被多个学生学习,整体来看,学生学习课程就成了多对多的关系。
1.1.4 ER实体关系模型案例
假设在电商购物系统中,对商品、用户设计ER实体关系模型图来表示商品信息、用户购买商品之间的业务联系,完成数据库逻辑模型设计。
设计ER实体关系模型图,步骤如下:
- 抽象出实体
- 找出实体之间的关系
- 找出实体的属性
- 画出E-R关系图

以上是ER实体关系图,为了方便,我们一般可以将ER实体关系图转换成如下数据库表格式,IDEF1X格式: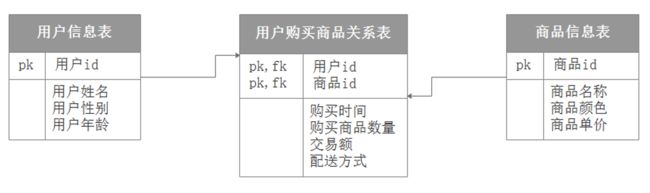
1.2 数据仓库与维度建模
1.2.1 数据仓库(Data Warehouse)
在日益激烈的商业竞争中,企业迫切需要更加准确的战略决策信息。在以往的关系型数据库系统中,企业拥有海量的数据,这些数据对于企业的运作是非常有用的,但是对于商业战略决策和目标制定的作用甚微,不是战略决策要使用的信息。
关系型数据库很难将这些数据转换成企业真正需要的决策信息,原因如下:
- 一个企业中可能有很多管理系统平台,企业数据分散在多种互不兼容的系统中。例如:一个银行中的系统分为:核心系统,信贷系统,企业贷款系统,客户关系系统,助学贷款系统,理财系统、反洗钱系统等,这些系统数据有可能存储在不同类型的关系型数据库中。
- 关系型数据库中存储的数据一般是最基本的、日常事务处理的、面向业务操作的数据,数据一般可以更新状态,删除数据条目等。不能直接反应趋势的变化。例如:用户登录网站购买商品,在关系型数据库中最终存储的数据是某个用户下了一个订单,订单状态为付款待发货。一般用户在网站浏览了什么商品,搜索了什么样的关键字,这些数据不会存储在关系型数据库中,往往这些数据更具价值。
- 对于战略决策来说,决策者必须从不同的商业角度观察数据,比如说产品、地区、客户群等不同方面观察数据,关系型数据库中数据不适合从不同的角度进行分析,只是面向基本的业务操作。
所以我们需要对企业中各类数据进行汇集,清洗,管理,找出战略决策信息,这就需要建立数据仓库。
数据仓库,Data Warehouse,可简写为DW或DWH。数据仓库是面向主题的、集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
面向主题:主题是指使用数据仓库进行决策时所关心的重点方面,每个主题都对应一个相应的分析领域,一个主题通常与多个信息系统相关。
例如:在银行数据中心平台中,用户可以定义为一个主题,用户相关的数据可以来自信贷系统、银行资金业务系统、风险评估系统等,以用户为主题就是将以上各个系统的数据通过用户切入点,将各种信息关联起来。如下图所示:
数据集成:数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息,这个过程中会有ETL操作,以保证数据的一致性、完整性、有效性、精确性。
例如某公司中有人力资源系统、生产系统、财务系统、仓储系统等,现需要将各个系统的数据统一采集到数据仓库中进行分析。在人力系统中,张三的性别为“男”,可能在财务系统中张三的性别为“M”,在人力资源系统中张三的职称为“生产部员工”,在生产系统中张三的职称为“技术经理”,那么当我们将数据抽取到数据仓库中时,需要经过数据清洗将数据进行统一、精确、一致性存储。
相对稳定:数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,基本没有修改和删除操作,通常只需要定期的加载、刷新。
例如:某用户在一天中多次登录某系统,关系型数据库中只是记录当前用户最终在系统上的状态是“在线”还是“离线”,只需要记录一条数据进行状态更新即可。但是在数据仓库中,当用户多次登录系统时,会产生多条记录,不会存在更新状态操作,每次用户登录系统和下线系统都会在数据仓库中记录一条信息,这样方便后期分析用户行为。
反映历史变化:数据仓库中的数据通常包含历史信息,系统地记录企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
例如:电商网站中,用户从浏览各个商品,到将商品加入购物车,直到付款完成,最终的结果在关系型数据库中只需要记录用户的订单信息。往往用户在网站中的浏览商品的信息行为更具有价值,数据仓库中就可以全程记录某个用户登录系统之后浏览商品的浏览行为,加入购物车的行为,及付款行为。以上这些数据都会被记录在数据仓库中,这样就为企业分析用户行为数据提供了数据基础。
1.2.2 数据仓库技术的发展历程
1. 萌芽阶段(1978~1988年)。
数据仓库概念最早可追溯到20世纪70年代,MIT(麻省理工)的研究员致力于研究一种优化的技术架构,该架构试图将业务处理系统和分析系统分开,即将业务处理和分析处理分为不同层次,针对各自的特点采取不同的架构设计原则,MIT的研究员认为这两种信息处理的方式具有显著差别,以至于必须采取完全不同的架构和设计方法。但受限于当时的信息处理能力,这个研究仅仅停留在理论层面。
2. 探索阶段。
20世纪80年代中后期,DEC公司(美国数字设备公司)结合MIT的研究结论,建立了TA2(Technical Architecture2)规范,该规范定义了分析系统的四个组成部分:数据获取、数据访问、目录和用户服务。其中的数据获取和数据访问目前大家都很清楚,而目录服务是用于帮助用户在网络中找到他们想要的信息,类似于业务元数据管理;用户服务用以支持对数据的直接交互,包含了其他服务的所有人机交互界面,这是系统架构的一次重大转变,第一次明确提出分析系统架构并将其运用于实践。
3. 雏形阶段(1988年)
1988年,为解决全企业集成问题,IBM公司第一次提出了信息仓库(InformationWarehouse)的概念:“一个结构化的环境,能支持最终用户管理其全部的业务,并支持信息技术部门保证数据质量”,并称之为VITAL规范(VirtuallyIntegrated Technical Architecture Lifecycle)。并定义了85种信息仓库的组件,包括数据抽取、转换、有效性验证、加载、Cube开发和图形化查询工具等。至此,数据仓库的基本原理、技术架构以及分析系统的主要原则都已确定,数据仓库初具雏形。
4. 确立阶段(1991年)
1991年,比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立。该书定义了数据仓库非常具体的原则,包括:
- 数据仓库是面向主题的(Subject-Oriented)、
- 集成的(Integrated)、
- 包含历史的(Time-variant)、
- 不可更新的(Nonvolatile)、
- 面向决策支持的(Decision Support)
- 面向全企业的(Enterprise Scope)
- 最明细的数据存储(Atomic Detail)
- 数据快照式的数据获取(Snap Shot Capture)
这些原则到现在仍然是指导数据仓库建设的最基本原则。凭借着这本书,Bill Inmon被称为“数据仓库之父”。
Bill Inmon主张自上而下的建设企业级数据仓库EDW (Enterprise Data Warehouse),认为数据仓库是一个整体的商业智能系统的一部分, 一家企业只有一个数据仓库,数据集市(数据集市中存储为特定用户需求而预先计算好的数据,从而满足用户对性能的需求)的信息来源出自数据仓库,在数据仓库中,信息存储符合第三范式,大致结构如下: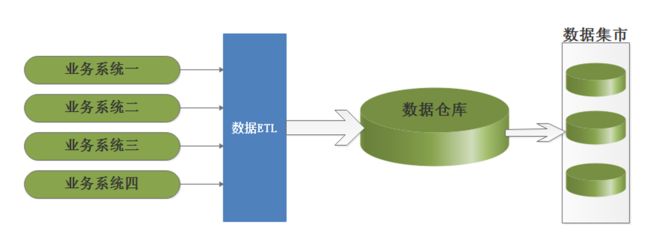
由于企业级数据仓库的设计、实施很困难,使得最早吃数据仓库螃蟹的公司遭到大面积的失败,除了常见的业务需求定义不清、项目执行不力之外,很重要的原因是因为其数据模型设计,在企业级数据仓库中,Inmon推荐采用3范式进行数据建模,但是不排除其他的方法,但是Inmon的追随者固守OLTP系统的3范式设计,从而无法支持决策支持(DSS -Decision Suport System )系统的性能和数据易访问性的要求。
1994年前后,实施数据仓库的公司大都以失败告终,这时,拉尔夫·金博尔(Ralph Kimball)出现了,他的第一本书《The DataWarehouse Toolkit》掀起了数据集市的狂潮,这本书提供了如何为分析进行数据模型优化详细指导意见。
Ralph Kimball主张自下而上的建立数据仓库,极力推崇建立数据集市,认为数据仓库是企业内所有数据集市的集合,信息总是被存储在多维模型当中,为传统的关系型数据模型和多维OLAP之间建立了很好的桥梁,其思路如下: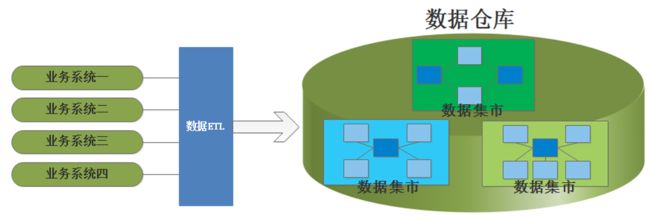
5. 争吵与混乱(1996-1997年)
Bill Inmon(比尔·恩门)的《Building the Data Warehouse》主张建立数据仓库时采用自上而下 方式,以第3范式进行数据仓库模型设计,而Ralph Kimball(拉尔夫·金博尔)在《The DataWarehouse Toolkit》则是主张自下而上的方式,力推数据集市建设。企业级数据仓库还是部门级数据集市?关系型还是多维?Bill Inmon 和Ralph Kimball一开始就争论不休,其各自的追随者也唇舌相向,形成相对立的两派:Inmon派和Kimball派。
在初期,数据集市的快速实施和较高的成功率让Kimball派占了上风,由于数据集市仅仅是数据仓库的某一部分,实施难度大大降低,并且能够满足公司内部部分业务部门的迫切需求,在初期获得了较大成功。但是很快,他们也发现自己陷入了某种困境:随着数据集市的不断增多,这种架构的缺陷也逐步显现,公司内部独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致。解决问题的方法只能是回归到数据仓库最初的基本建设原则上来。
6. 合并(1998-2001年)
两种思路和观点在实际的操作中都很难成功的完成项目交付,1998年,Bill Inmon提出了新的BI架构CIF(Corporation information factory),把Kimball的数据集市也包容进来。CIF的核心是将数仓架构划分为不同的层次以满足不同场景的需求,比如常见的ODS、DW、DM等,每层根据实际场景采用不同的建设方案,现在CIF已经成为建设数据仓库的框架指南,但自上而下还是自下而上的进行数据仓库建设,并未统一。
以上就是到目前为止,整体数仓建设来源的过程。
1.2.3 维度建模
维度建模主要源自数据集市,主要面向分析场景。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。它与实体-关系(ER)建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
Ralph Kimball(拉尔夫·金博尔)推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表划分为事实表、维度表两种类型。
- 事实表
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。例如,一个按照地区、产品、月份划分的销售量和销售额的事实表如下: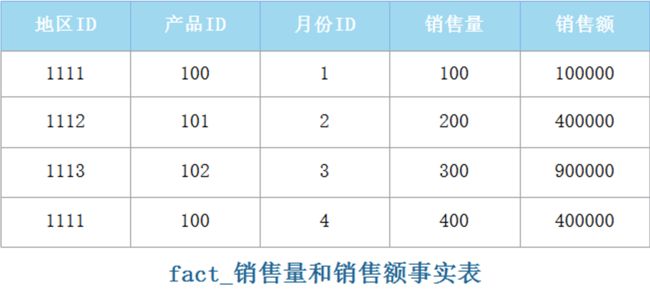
- 在以上事实表的示例中,“地区ID”、“产品ID”、“月份ID”为键值列,“销售量”、“销售额”为度量列,所谓度量列就是列的数据可度量,度量列一般为可统计的数值列。事实表中每个列通常要么是键值列,要么是度量列。
- 事实表中一般会使用一个代号或者整数来代表维度成员,而不使用描述性的名称,例如:ID代号。上表中的“地区ID”、“产品ID”、“月份ID”就是维度列,就是观察数据的角度。使用代号或整数来代表维度成员的原因是事实表往往包含很多数据行,使用代号或整数这种键值方式可以有效减少事实表的大小。
- 在事实表中使用代号或者整数键值时,维度成员的名称需要放在另一种表中,也就是维度表。通常事实表中的每个维度都对应一个维度表。
- 在数据仓库中,事实表的前缀为“fact”
- 维度表
维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute),假设“产品ID”维度表中有3种产品,例如: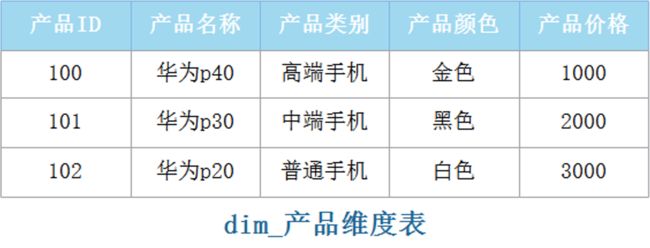
- 如上图,“产品名称”是产品维度表中的一个属性,维度表中可以包含很多属性列。
- 产品维度表中的“产品ID”与事实表中的“产品ID”相匹配,称为“键属性”,在当前产品维度表中一个“产品ID”只有一个“产品名称”,显示时使用“产品名称”来代替,所以“产品名称”也被认为是“键属性”的一部分。
在数据仓库中,维度表中的键属性必须为维度的每个成员包含一个对应的唯一值,用关 系型数据库术语描述就是,键属性是主键列,也就是说维度表中一般为单一主键。 - 每个维度表中的键值属性都与事实表中对应的维度相匹配,在维度表中“产品ID”类似关系型数据库中的主键,在事实表中“产品ID”类似关系型数据库中的外键,维度表和事实表就是按照键值属性“产品ID”进行关联的。在维度表中出现一次的每个键值都会在事实表中出现多次。例如上图中,产品ID 中 1111在事实表中对应多行。
- 在数据仓库中,维度表的前缀为"dim"
总结:
在数据仓库中事实表就是我们需要关注的内容,维度表就是我们从哪些角度观察这些内容。例如,某地区商品的销量,是从地区这个角度观察商品销量的。事实表就是销量表,维度表就是地区表。
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。
星型模型:
当所有的维度表都由连接键连接到事实表时,结构图如星星一样,这种分析模型就是星型模型。如下图,星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在下图中,时间维中存在A年1季度1月,A年1季度2月两条记录,那么A年1季度被存储了2次,存在冗余。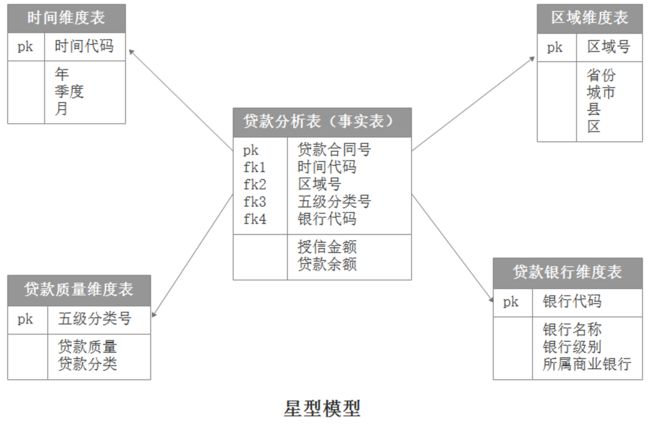
雪花模型:
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其结构图就像雪花连接在一起,这种分析模型就是雪花模型。如下图,雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。如下图中,将地域维表又分解为国家,省份,城市等维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,雪花型结构去除了数据冗余。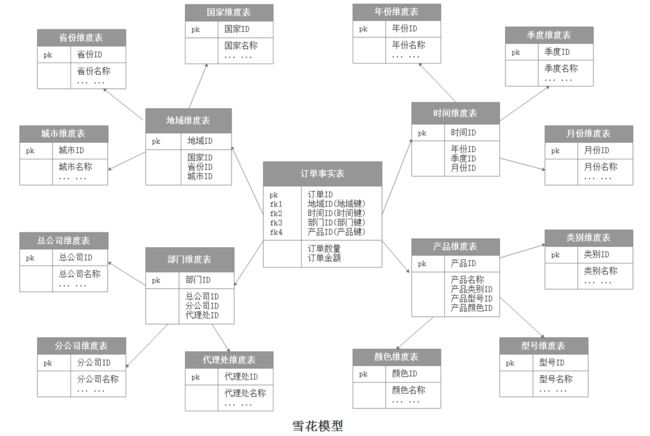
星型模型与雪花模型对比:
星型模型和雪花模型主要区别就是对维度表的拆分,对于雪花模型,维度表的设计更加规范,一般符合三范式设计;而星型模型,一般采用降维的操作,维度表设计不符合三范式设计,反规范化,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,数仓构建实际运用中星型模型使用更多,也更有效率。
此外,在数据仓库中星座模型也使用比较多,当多个事实表共用多张维度表时,就构成了星座模型。
1.2.4 维度建模案例
淘宝电商平台,经常需要对用户订单进行分析,以用户订单为例,使用维度建模的方式来设计模型。
以上涉及到的事实表有:订单明细表。
订单明细表中的维度有用户维度,区域维度,时间维度,商品维度,商户维度。度量有商品件数,商品金额。
用户维度表:用户ID,用户姓名,用户性别,用户年龄,用户职业,用户区域。
区域维度表:区域ID,区域名称。
时间维度表:时间ID,年份,季度,月份,天。
商品维度表:商品ID,商品名称,商品单价,商品类别,商品产地。
商户维度表:商户ID,商户名称,开店年限。
建模设计如下: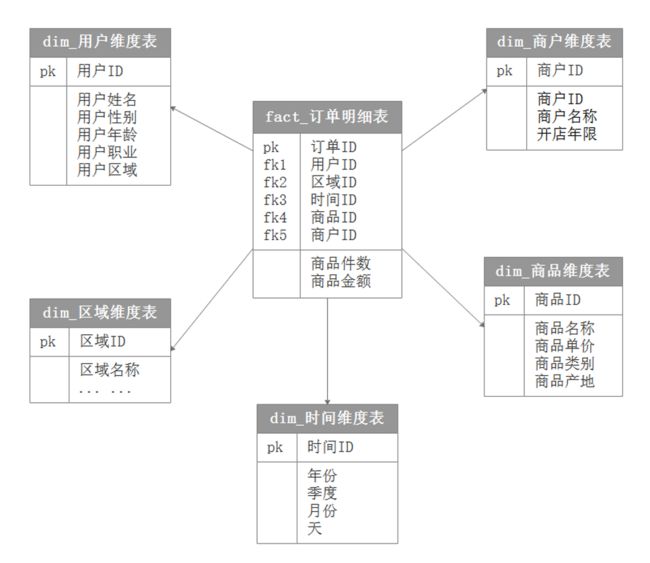
1.3 数据仓库的分层
1.3.1 数据仓库分层设计
在大数据分析中,我们希望我们分析的数据在整个分析流程中有秩序的流转,数据的整个流程能够清晰明确的被我们掌握使用。
 上图中的数据流转我们更希望得到A图中的数据流转过程。所以我们希望有一套行之有效的数据组织和管理方法来让我们的数据更有序,这就需要在数据处理中进行数据分层的原因。基于大数据的数据仓库建设要求快速响应需求,同时需求灵活多变,对实时性有不同的要求,除了面向DSS、BI等应用外,还要响应用户画像、个性化推荐、机器学习、数据分析等各种复杂的应用场景,实际上在大数据开发中,涉及到数仓设计都会进行分层设计。
上图中的数据流转我们更希望得到A图中的数据流转过程。所以我们希望有一套行之有效的数据组织和管理方法来让我们的数据更有序,这就需要在数据处理中进行数据分层的原因。基于大数据的数据仓库建设要求快速响应需求,同时需求灵活多变,对实时性有不同的要求,除了面向DSS、BI等应用外,还要响应用户画像、个性化推荐、机器学习、数据分析等各种复杂的应用场景,实际上在大数据开发中,涉及到数仓设计都会进行分层设计。
数据分层好处如下:
- 清晰的数据结构:每层数据都有各自的作用域和职责,在使用表的时候更方便定位和理解。
- 减少重复开发:规范数据分层,开发一层公用的中间层数据,减少重复计算流转数据。
- 统一数据出口:通过数据分层,提供统一的数据出口,保证对外输出数据口径一致。
- 简化问题:通过数据分层,将复杂的业务简单化,将复杂的业务拆解为多层数据,每层数据负责解决特定的问题。

- ODS(Operational Data Store)层 - 操作数据层
ODS层,操作数据层,也叫贴源层,本层直接存放从业务系统抽取过来的数据,这些数据从结构上和数据上与业务系统保持一致,降低了数据抽取的复杂性,本层数据大多是按照源头业务系统的分类方式而分类的。一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可。
- DW(Data Warehouse)层 - 数据仓库层
数据仓库层是我们在做数据仓库时要核心设计的一层,本层将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data Warehouse Middle)层和DWS(Data Warehouse Service)层。
数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证,在ODS的基础上对数据进行加工处理,提供更干净的数据。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,当一个维度没有数据仓库需要的任何数据时,就可以退化维度,将维度退化至事实表中,减少事实表和维表的关联。例如:订单id,这种量级很大的维度,没必要用一张维度表来进行存储,而我们一般在进行数据分析时订单id又非常重要,所以我们将订单id冗余在事实表中,这种维度就是退化维度。
数据中间层:DWM(Data Warehouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工处理数据。简单来说,就是对通用的维度进行聚合操作,算出相应的统计指标,方便复用。
数据服务层:DWS(Data Warehouse Service)
该层数据表会相对比较少,大多都是宽表(一张表会涵盖比较多的业务内容,表中的字段较多)。按照主题划分,如订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
在实际业务处理中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS也没有问题。
- DM(Data Mart)层 - 数据集市层
数据集市层,也可以称为数据应用层,基于DW上的基础数据,整合汇总成分析某一个主题域的报表数据。主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
1.3.2 数据仓库分层案例
现在以购物网站电商日志为例,来说明数据仓库分层的使用,这里我们只是关注用户产生的日志这一部分数据。
某购物网站用户可以在pc端、ipad、手机app端、微信小程序登录购物网站进行购物,用户购物会产生一些订单、浏览商品、地域登录登出等日志数据。为方便后期分析用户日志数据和订单数据更好的辅助决策,设计数据仓库分层如下: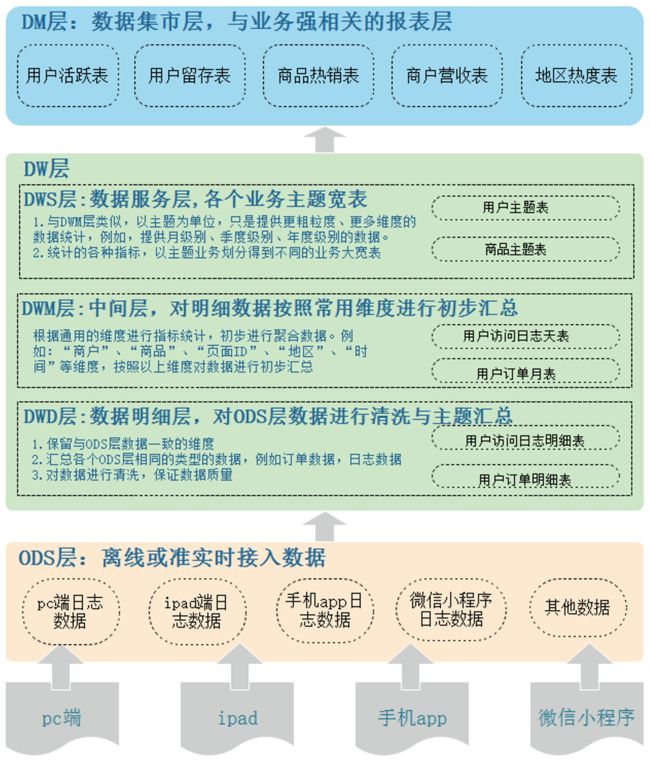
1.4 数据库与数据仓库区别
数据库:传统关系型数据库的主要应用是OLTP(On-Line Transaction Processing),主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。
数据仓库:数仓系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。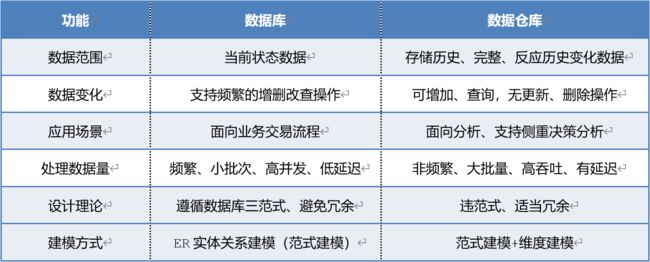
1.5 项目介绍
音乐数据中心数仓综合项目主要是针对公司过去收集到的用户点播、购买音乐等数据(包括业务数据与用户行为数据),为公司业务更健康的发展提供决策服务支持(BI商业决策)。
数据中心项目中包含业务系统数据和用户行为日志数据。
- 业务数据即业务系统产生的业务数据,例如:系统中产生的订单、登录、点歌、广告展示等数据。
- 用户行为数据例如:用户在实体机器上操作的行为都是用户行为数据,点击、收藏、扫码等事件。
公司针对以上数据进行分析的结果主要有两个应用:
- 一是针对BI系统,商业智能中主要展示更多的报表给公司的运营人员参照。例如:每日歌曲点唱量,每日营收,机器分布,实时pv,uv,用户留存率、漏斗模型等。
- 另一个应用是数据服务,数据服务主要是针对分析后结果数据以接口的形式提供给业务系统来访问,例如:推荐系统,根据歌曲来推荐歌曲,根据歌手来推荐歌曲或者根据用户来推荐歌曲。
1.6 项目架构
数据中心项目是Spark综合的数仓项目。分为离线处理和实时处理,其中用到的技术有MySQL、Sqoop、HDFS、Yarn、Hive、数据仓库模型设计、SparkCore、SparkSQL、SparkStreaming、Azkaban、Flume、Kafka、Redis、superSet、Redis、微信指数、高德API等。
离线处理:以Spark为主,其中很少使用了SparkCore的代码,主要使用SparkSQL构建数据仓库。项目使用airflow/Azkaban进行调度,可以每日进行调度,也可以每月进行调度,每天定时触发调度。
实时处理:使用SparkStreaming实现实时处理。离线N+1的方式不能得到实时数据,运营活动中心有时需要实时的用户上线数据,针对客户端进行数据埋点,用户在客户端所有的行为都是事件,对事件进行埋点,当用户触发了一些事件时,判断用户是否满足了目标用户情况。
实时处理流程如下:
http请求 -->数据采集接口–>数据目录–> flume监控目录[监控的目录下的文件是按照日期分的] -->Kafka [也会放在HDFS中,就是上面做的] -->SparkStreaming分析数据 --> Kafka[给运营中心使用] 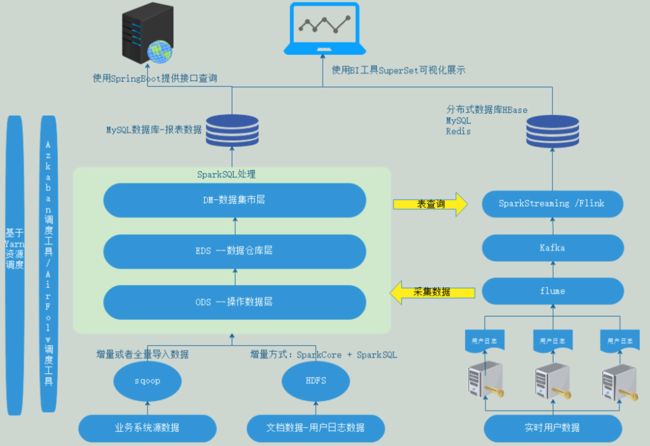
1.7 集群配置&项目人数、周期
- 集群配置:
生产环境:集群有50台服务器,16核32线程+128G+40T。
20核40线程机器。32核64线程。56核112线程。
测试环境:5台测试机器,2核双线程+32G+1T磁盘 - 项目人数:
1个web人员+大数据开发4人(2人负责离线,1人负责实时,一人负责规划)+运维部门人员2人。 - 项目周期:
业务一直改变,目前2年。
1.8 数据来源及采集
数据中心项目中的数据来源主要是商场中的KTV歌厅产生的数据和商场中跳舞机产生的数据。
以上两种设备产生的数据可以分为两类数据,一类是产生的订单数据,会记录到业务数据库。后期直接通过sqoop直接抽取MySQL中的数据到HDFS。另外一类是通过http请求,上传到专门采集数据的日志服务器上,每天由运维人员将数据打包上传到数据中心平台某个目录下,然后由定时任务定时来执行Spark任务拉取数据,上传至HDFS中。这里读取压缩数据使用SparkCore进行处理,处理之后将数据以parquet格式或者json格式存储在HDFS中即可。
1.9 数据仓库模型
数据仓库按照主题分为三个主题:用户、机器、内容(歌曲相关、歌手相关)。每个主题下面都有对应的表。数据仓库的设计分为三层,如下:
- ODS层:
ODS文件中是从业务数据库中抽取出来数据表的原数据, 数据从关系型数据库MySQL中导入,转换成Parquet格式的文件存在HDFS中,后期方便使用SparkSQL处理。
ODS层数据来源如下:
外部数据源:网易云爬取歌曲热度数据、歌手热度数据,爬取数据是json格式的数据。
内部数据源:主要有MySQL和客户端上传json数据。MySQL使用Sqoop抽取数据到HDFS中,导入ODS层。客户端产生日志到客户端服务器,客户端服务器由运维人员每天将数据压缩成包导入到HDFS路径中,也就是ODS层。 - EDS层:
EDS层负责信息集成、轻度汇总类数据。简单理解就是将事务性的数据组织成便于分析的仓库维度建模类型的数据,做一些轻度聚合,类似Hive中的宽表。例如:将ODS层数据进行清洗,如果主题是用户主题,那么就按照用户id为粒度将数据组织在一起。如果主题是机器,那么就按照机器id为粒度将数据组织在一起。
以上ODS层和EDS层使用Spark代码处理数据,然后利用SparkSQL读取ODS层数据,保存到Hive的EDS层。 - DM层:
DM层的数据有一部分是存储在Hive表中,或者保存分析结果到MySQL、HBase等。EDS层数据是parquet格式的数据,放在Hive的主要原因是后期使用Kylin 查询一些业务,数据放MySQL的都是结果数据,放在HBase的原因是设涉及到大表的明细查询。
以上数据仓库模型的设计表对应关系都在“数据仓库模型.xlsx”文件中。
1.10 数据仓库命名规范
参照“数据仓库模型.xlsx”文件。
1.11 Sqoop安装
由于项目中使用到了Sqoop将mysql中的数据导入到Hive中,所以这里,首先安装Sqoop。
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop的导入导出数据原理非常简单,就是将导入或导出命令翻译成 mapreduce 程序来实现。
Sqoop安装:
1. 下载Sqoop
登录sqoop官网:http://sqoop.apache.org/ ,下载Sqoop,这里选择版本1.4.7版本进行下载。
2. 上传解压
将下载好的Sqoop,上传到集群中的某个节点上,这里选择mynode3,进行解压。节点必须有Hadoop环境,并且配置好hadoop环境变量。
3. 在mynode3节点上配置sqoop的环境变量
在/etc/profile追加Sqoop的环境变量,保存后,执行source /etc/profile使环境变量生效。
1. export SQOOP_HOME=/software/sqoop-1.4.7.bin__hadoop-2.6.0/
2. export PATH=$PATH:$SQOOP_HOME/bin
4. 拷贝mysql的驱动包到Sqoop lib下
将“mysql-connector-java-5.1.47.jar”包上传到“$SQOOP_HOME/lib”下。当导入MySQL数据到HDFS时,需要使用MySQL驱动包。
5. 拷贝hive相应的jar包到Sqoop lib下
当将数据导入到Hive时,需要使用到Hive对应的jar包,需要将“$HIVE_HOME/lib”目录下的“hive-exec-1.2.1.jar”与“hive-common-1.2.1.jar”两个jar包复制到“$SQOOP_HOME/lib”下。
6. 执行命令:sqoop help ,查看是否配置好Sqoop
1.12 搭建Flume
首先我们去Flume的官网下载Flume,网址如下:http://flume.apache.org/download.html。
关于Flume的版本这里没有特别的要求,我们这里可以选择”apache-flume-1.9.0-bin.tar.gz”进行下载,点击”apache-flume-1.9.0-bin.tar.gz”将开始下载,下载的速度与个人网络好坏有关,如果遇到网络连接慢的情况,可以更改其他时段进行下载。最后将下载好的Flume保存到本地目录。
Flume的搭建配置步骤如下:
- 首先将Flume上传到Mynode5节点/software/路径下,并解压,命令如下:
1. [root@mynode5 software]# tar -zxvf ./apache-flume-1.9.0-bin.tar.gz
- 其次配置Flume的环境变量,配置命令如下:
1. 修改 /etc/profile文件,在最后追加写入如下内容,配置环境变量:
2. [root@mynode5 software]# vim /etc/profile
3. export FLUME_HOME=/software/apache-flume-1.9.0-bin
4. export PATH=$FLUME_HOME/bin:$PATH
5.
6. #保存以上配置文件并使用source命令使配置文件生效
7. [root@mynode5 software]# source /etc/profile
经过以上两个步骤,Flume的搭建已经完成,至此,Flume的搭建完成,我们可以使用Flume进行数据采集。
1.13 安装部署Azkaban
大数据业务处理场景中,经常有这样的分析场景:
A任务:将收集的数据通过一系列的规则进行清洗,然后存入Hive 表a中。
B任务:将Hive中已存在的表b和表c进行关联得到表d。
C任务:将A任务中得到的表a与B任务中得到的表d进行关联得到分析的结果表e。
D任务:最后将Hive中得到的表e 通过sqoop导入到关系型数据库MySQL中供web端查询使用。
显然,以上任务C依赖于任务A与任务B的结果,任务D依赖于任务C的结果。我们一般的做法可以打开两个终端分别执行任务A与任务B,当任务A与任务B执行完成之后再执行任务C,当任务C执行完成之后再执行任务D。整个任务流程中必须保证任务A、任务B执行完成之后执行任务C,然后再执行任务D。这样某一个环节都离不开人工的参与,需要时刻盯着各任务的执行进度,非常费力。
以上业务场景就是一个大的任务,任务中分为四个子任务A、B、C、D,如果能有一个任务调度器给我们自动实现执行任务A,执行任务B,然后再执行任务C,最后执行任务D,那么就不需要人工时刻盯着任务是否执行完成,是否该开启下一个任务。Azkaban就是这样一个工作流的调度器,可以解决以上场景问题。
1.13.1 Azkaban的安装
Azkaban是一个批量工作流调度器,底层是使用java语言开发,用于在一个工作流内以一定的顺序运行一组任务和流程,并且提供了非常方便的webui界面来监控任务调度的情况,方便我们来管理流调度任务。
Azkaban由三个关键组件组成:
- AzkabanWebServer:
主要负责项目管理、用户登录权限认证、定时执行工作任务、跟踪提交任务执行的流程、访问历史执行任务、保存执行计划的状态。 - AzkabanExecutorServer:
主要负责工作流程的提交、执行、检索和更新当前正在执行计划的数据,处理执行计划的日志。 - 关系型数据库(仅支持mysql):
主要是保存工作流中的原数据信息。
下面,让我们从零开始搭建一个Azkaban任务流调度系统。
1.13.1.1 下载Azkaban
登陆Azkaban的官网:https://azkaban.github.io/,点击Downloads,如图示:
点击之后,在跳转的页面中选择Releases,进入页面选择相应的版本下载,这里选择的版本是3.70.0版本,点击“Source code(tar.gz)”下载。
1.13.1.2 环境准备
在Linux中安装Azkaban,系统中需要安装好jdk,MySQL,这里选择的是jdk8和MySQL5.1版本。除此之外,还需要安装git,git是一个开源的分布式版本控制系统,一般在项目版本控制中会使用git控制,这里安装Azkaban需要git是因为需要通过git构建依赖的包。
jdk和mysql的安装比较容易,下面介绍git的安装:
- 下载git,执行如下命令:
wget https://github.com/git/git/archive/v2.21.0.tar.gz
1. [root@mynode5 git]# wget https://github.com/git/git/archive/v2.21.0.tar.gz
2. --2019-04-08 15:08:22-- https://github.com/git/git/archive/v2.21.0.tar.gz
3. 正在解析主机 github.com... 13.250.177.223, 52.74.223.119, 13.229.188.59
4. 正在连接 github.com|13.250.177.223|:443... 已连接。
5. 已发出 HTTP 请求,正在等待回应... 302 Found
6. 位置:https://codeload.github.com/git/git/tar.gz/v2.21.0 [跟随至新的 URL]
7. --2019-04-08 15:08:23-- https://codeload.github.com/git/git/tar.gz/v2.21.0
8. 正在解析主机 codeload.github.com... 54.251.140.56, 13.229.189.0, 13.250.162.133
9. 正在连接 codeload.github.com|54.251.140.56|:443... 已连接。
10. 已发出 HTTP 请求,正在等待回应... 200 OK
11. 长度:未指定 [application/x-gzip]
12. 正在保存至: “v2.21.0.tar.gz”
13.
14. [ <=> ] 8,293,180 1.16M/s in 7.2s
15.
16. 2019-04-08 15:08:31 (1.10 MB/s) - “v2.21.0.tar.gz” 已保存 [8293180]
- 解压下载好的压缩包
1. [root@mynode5 git]# tar -zxvf ./v2.21.0.tar.gz
- 安装编译源码所需依赖,以上安装依赖时,出现提示按‘y’即可
1. [root@mynode5 git]# yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker
- 进入解压的文件夹,编译git,这一步骤时间稍微过长,耐心等待即可
1. [root@mynode5 git]# cd git-2.21.0/
2. [root@mynode5 git-2.21.0]# make prefix=/usr/local/git all
- 安装git到/usr/local/git路径
1. [root@mynode5 git-2.21.0]# make prefix=/usr/local/git install
- 配置环境变量
打开/etc/profile文件,追加如下内容:PATH=$PATH:/usr/local/git/bin
1. [root@mynode5 git-2.21.0]# vim /etc/profile
2. 追加如下内容之后,再保存。
3. export PATH=$PATH:/usr/local/git/bin
4. [root@mynode5 git-2.21.0]# source /etc/profile #使新加入的环境变量生效
- 检查git版本,验证是否安装成功
1. [root@mynode5 git-2.21.0]# git --version
2. git version 2.21.0
1.13.1.3 安装Azkaban
- 上传下载好的azkaban,解压到
/software/azkaban-temp文件夹
1. [root@mynode5 software]# tar -zxvf ./azkaban-3.70.0.tar.gz
2. [root@mynode5 software]# mv ./azkaban-3.70.0 azkaban-temp
- 进入azkaban-temp目录,进行编译
1. [root@mynode5 azkaban]# ./gradlew distTar
2. Downloading https://services.gradle.org/distributions/gradle-4.6-all.zip
3. .....................................................................................................
4. Unzipping /root/.gradle/wrapper/dists/gradle-4.6-all/bcst21l2brirad8k2ben1letg/gradle-4.6-all.zip to /root/.gradle/wrapper/dists/gradle-4.6-all/bcst21l2brirad8k2ben1letg
5. Set executable permissions for: /root/.gradle/wrapper/dists/gradle-4.6-all/bcst21l2brirad8k2ben1letg/gradle-4.6/bin/gradle
6. Starting a Gradle Daemon (subsequent builds will be faster)
7. Parallel execution with configuration on demand is an incubating feature.
8. Download https://plugins.gradle.org/m2/com/gradle/build-scan/com.gradle.build-scan.gradle.plugin/1.9/com.gradle.build-scan.gradle.plugin-1.9.pom
9. ... ...
10. Download https://repo.maven.apache.org/maven2/org/codehaus/jackson/jackson-core-asl/1.8.8/jackson-core-asl-1.8.8.pom
11. Download https://repo.maven.apache.org/maven2/org/codehaus/jackson/jackson-mapper-asl/1.8.8/jackson-mapper-asl-1.8.8.pom
12. Download https://repo.maven.apache.org/maven2/commons-codec/commons-codec/1.7/commons-codec-1.7.jar8.8.pom
13. Download https://repo.maven.apache.org/maven2/com/twitter/parquet-hadoop-bundle/1.3.2/parquet-hadoop-bundle-1.3.2.jar
14. Download https://repo.maven.apache.org/maven2/org/codehaus/jackson/jackson-core-asl/1.8.8/jackson-core-asl-1.8.8.jar
15. Download https://repo.maven.apache.org/maven2/org/codehaus/jackson/jackson-mapper-asl/1.8.8/jackson-mapper-asl-1.8.8.jar
16.
17. BUILD SUCCESSFUL in 4m 6s
18. 54 actionable tasks: 40 executed, 14 from cache
注意:编译过程中有可能由于网络延时造成编译时失败,可以多重试几次解决此问题。
- 新建azkaban目录,将编译好的文件复制到此目录下
1. [root@mynode5 software]# mkdir ./azkaban
2. [root@mynode5 software]# cd azkaban
3. [root@mynode5 azkaban]# cp /software/azkaban-temp/azkaban-db/build/distributions/azkaban-db-0.1.0-SNAPSHOT.tar.gz /software/azkaban
4. [root@mynode5 azkaban]# cp /software/azkaban-temp/azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz /software/azkaban
5. [root@mynode5 azkaban]# cp /software/azkaban-temp/azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz /software/azkaban
- 在azkaban目录下解压各个编译好的压缩包,重新命名
1. [root@mynode5 azkaban]# tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz
2. [root@mynode5 azkaban]# tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz
3. [root@mynode5 azkaban]# tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
4. [root@mynode5 azkaban]# mv azkaban-db-0.1.0-SNAPSHOT azkaban-db
5. [root@mynode5 azkaban]# mv azkaban-web-server-0.1.0-SNAPSHOT azkaban-web
6. [root@mynode5 azkaban]# mv azkaban-exec-server-0.1.0-SNAPSHOT azkaban-exec
至此,经历了Azkaban的下载、编译,Azkaban安装基本准备工作已经完成,下一步就是配置Azkaban,将Azkaban运行起来。
1.13.2 导入数据库
运行Azkaban基本的原数据信息库,在编译好的azkaban-db中就有基本的库信息,需要将这些数据导入到关系型数据库中,这里就是导入MySQL数据库中,导入的MySQL数据库可以和当前Azkaban安装在同一节点上,也可以安装在不同的节点上,笔者的Azkaban安装在mynode5节点上,MySQL数据库安装在mynode2节点上。
- 登录mysql数据库,创建azkaban数据库
1. [root@mynode2 ~]# mysql -u root -p
2. Enter password:
3. Welcome to the MySQL monitor. Commands end with ; or \g.
4. Your MySQL connection id is 3
5. Server version: 5.1.73 Source distribution
6.
7. Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
8.
9. Oracle is a registered trademark of Oracle Corporation and/or its
10. affiliates. Other names may be trademarks of their respective
11. owners.
12.
13. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
14.
15. mysql> create database azkaban default character set latin1;
16. Query OK, 1 row affected (0.00 sec)
注意:这里创建azkaban时建议使用 latin1编码,因为索引太长,utf8编码格式不支持,最高支持1000。
- 准备sql文件
将mynode5节点上/software/azkaban/azkaban-db目录下的create-all-sql-0.1.0-SNAPSHOT.sql 复制到mynode2节点/software/test目录下。
1. [root@mynode5 azkaban-db]# scp /software/azkaban/azkaban-db/create-all-sql-0.1.0-SNAPSHOT.sql root@mynode2:/software/test create-all-sql-0.1.0-SNAPSHOT.sql 100% 12KB 11.8KB/s 00:00
- 向MySQL中导入数据库
1. mysql> use azkaban;
2. Database changed
3. mysql> source /software/test/create-all-sql-0.1.0-SNAPSHOT.sql
4. Query OK, 0 rows affected (0.03 sec)
5.
6. Query OK, 0 rows affected (0.00 sec)
7.
8. Query OK, 0 rows affected (0.00 sec)
9.
10. Query OK, 0 rows affected (0.01 sec)
11. Records: 0 Duplicates: 0 Warnings: 0
12.
13. Query OK, 0 rows affected (0.00 sec)
14.
15. Query OK, 0 rows affected (0.00 sec)
16. Records: 0 Duplicates: 0 Warnings: 0
17.
18. Query OK, 0 rows affected (0.01 sec)
19. Records: 0 Duplicates: 0 Warnings: 0
20.
21. Query OK, 0 rows affected (0.00 sec)
22. Records: 0 Duplicates: 0 Warnings: 0
23.
24. Query OK, 0 rows affected (0.00 sec)
25. Records: 0 Duplicates: 0 Warnings: 0
26.
27. Query OK, 0 rows affected (0.01 sec)
28. Records: 0 Duplicates: 0 Warnings: 0
29.
30. Query OK, 0 rows affected (0.00 sec)
31. Records: 0 Duplicates: 0 Warnings: 0
32.
33. Query OK, 0 rows affected (0.01 sec)
34.
35. Query OK, 0 rows affected (0.00 sec)
36. Records: 0 Duplicates: 0 Warnings: 0
37.
38. Query OK, 0 rows affected (0.00 sec)
39.
40. Query OK, 0 rows affected (0.01 sec)
41. Records: 0 Duplicates: 0 Warnings: 0
42.
43. Query OK, 0 rows affected (0.00 sec)
44. Records: 0 Duplicates: 0 Warnings: 0
45.
46. Query OK, 0 rows affected (0.01 sec)
47. Records: 0 Duplicates: 0 Warnings: 0
48.
49. Query OK, 0 rows affected (0.01 sec)
50.
51. Query OK, 0 rows affected (0.00 sec)
52. Records: 0 Duplicates: 0 Warnings: 0
53.
54. Query OK, 0 rows affected (0.00 sec)
55.
56. Query OK, 0 rows affected (0.01 sec)
57. Records: 0 Duplicates: 0 Warnings: 0
58.
59. Query OK, 0 rows affected (0.00 sec)
60.
61. Query OK, 0 rows affected (0.01 sec)
62. Records: 0 Duplicates: 0 Warnings: 0
63.
64. Query OK, 0 rows affected (0.00 sec)
65.
66. Query OK, 0 rows affected (0.00 sec)
67. Records: 0 Duplicates: 0 Warnings: 0
68.
69. Query OK, 0 rows affected (0.00 sec)
70.
71. Query OK, 0 rows affected (0.01 sec)
72.
73. Query OK, 0 rows affected (0.00 sec)
74. Records: 0 Duplicates: 0 Warnings: 0
75.
76. Query OK, 0 rows affected (0.00 sec)
77.
78. Query OK, 0 rows affected (0.01 sec)
79. Records: 0 Duplicates: 0 Warnings: 0
80.
81. Query OK, 0 rows affected (0.00 sec)
82.
83. Query OK, 0 rows affected (0.01 sec)
84. Records: 0 Duplicates: 0 Warnings: 0
85.
86. Query OK, 0 rows affected (0.00 sec)
87.
88. Query OK, 0 rows affected (0.00 sec)
89. Records: 0 Duplicates: 0 Warnings: 0
90.
91. Query OK, 0 rows affected (0.01 sec)
92.
93. Query OK, 0 rows affected (0.00 sec)
94. Records: 0 Duplicates: 0 Warnings: 0
95.
96. Query OK, 0 rows affected (0.00 sec)
97.
98. Query OK, 0 rows affected, 1 warning (0.00 sec)
99.
100. Query OK, 0 rows affected, 1 warning (0.00 sec)
101.
102. Query OK, 0 rows affected, 1 warning (0.00 sec)
103.
104. Query OK, 0 rows affected, 1 warning (0.00 sec)
105.
106. Query OK, 0 rows affected, 1 warning (0.00 sec)
107.
108. Query OK, 0 rows affected, 1 warning (0.00 sec)
109.
110. Query OK, 0 rows affected, 1 warning (0.01 sec)
111.
112. Query OK, 0 rows affected, 1 warning (0.00 sec)
113.
114. Query OK, 0 rows affected, 1 warning (0.00 sec)
115.
116. Query OK, 0 rows affected, 1 warning (0.00 sec)
117.
118. Query OK, 0 rows affected, 1 warning (0.00 sec)
119.
120. Query OK, 0 rows affected (0.00 sec)
121.
122. Query OK, 0 rows affected (0.01 sec)
123.
124. Query OK, 0 rows affected (0.00 sec)
125.
126. Query OK, 0 rows affected (0.00 sec)
127.
128. Query OK, 0 rows affected (0.00 sec)
129.
130. Query OK, 0 rows affected (0.01 sec)
131.
132. Query OK, 0 rows affected (0.00 sec)
133.
134. Query OK, 0 rows affected (0.00 sec)
135.
136. Query OK, 0 rows affected (0.01 sec)
137.
138. Query OK, 0 rows affected (0.00 sec)
139.
140. Query OK, 0 rows affected (0.01 sec)
141.
142. Query OK, 0 rows affected (0.00 sec)
143.
144. Query OK, 0 rows affected (0.00 sec)
- 检查导入的数据库表
1. mysql> show tables;
2. +--------------------------+
3. | Tables_in_azkaban |
4. +--------------------------+
5. | QRTZ_BLOB_TRIGGERS |
6. | QRTZ_CALENDARS |
7. | QRTZ_CRON_TRIGGERS |
8. | QRTZ_FIRED_TRIGGERS |
9. | QRTZ_JOB_DETAILS |
10. | QRTZ_LOCKS |
11. | QRTZ_PAUSED_TRIGGER_GRPS |
12. | QRTZ_SCHEDULER_STATE |
13. | QRTZ_SIMPLE_TRIGGERS |
14. | QRTZ_SIMPROP_TRIGGERS |
15. | QRTZ_TRIGGERS |
16. | active_executing_flows |
17. | active_sla |
18. | execution_dependencies |
19. | execution_flows |
20. | execution_jobs |
21. | execution_logs |
22. | executor_events |
23. | executors |
24. | project_events |
25. | project_files |
26. | project_flow_files |
27. | project_flows |
28. | project_permissions |
29. | project_properties |
30. | project_versions |
31. | projects |
32. | properties |
33. | triggers |
34. +--------------------------+
1.13.3 配置运行Azkaban
1.13.3.1 创建ssl配置
HTTP的全称是Hypertext Transfer Protocol Vertion (超文本传输协议),HTTPS的全称是Secure Hypertext Transfer Protocol(安全超文本传输协议),HTTPS基于HTTP开发,使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的安全版。Azkaban支持安全的https访问,但是需要创建ssl配置。
在/software/azkaban目录下执行命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA创建ssl配置。
1. [root@mynode5 azkaban]# keytool -keystore keystore -alias jetty -genkey -keyalg RSA
2. 输入密钥库口令:
3. 再次输入新口令:
4. 您的名字与姓氏是什么?
5. [Unknown]: azkaban
6. 您的组织单位名称是什么?
7. [Unknown]: azkaban
8. 您的组织名称是什么?
9. [Unknown]: azkaban
10. 您所在的城市或区域名称是什么?
11. [Unknown]: beijing
12. 您所在的省/市/自治区名称是什么?
13. [Unknown]: beijing
14. 该单位的双字母国家/地区代码是什么?
15. [Unknown]: CN
16. CN=azkaban, OU=azkaban, O=azkaban, L=beijing, ST=beijing, C=CN是否正确?
17. [否]: Y
18.
19. 输入 <jetty> 的密钥口令
20. (如果和密钥库口令相同, 按回车):
输入完信息,执行完以上命令之后,在当前目录下生成一个keystore文件,将此文件复制到azkaban web服务器根目录下。
1. [root@mynode5 azkaban]# mv /software/azkaban/keystore /software/azkaban/azkaban-web
1.13.3.2 Azkaban web 服务器配置
进入/software/azkaban/azkaban-web/conf目录下,编辑azkaban.properties文件:
1. [root@mynode5 conf]# cd /software/azkaban/azkaban-web/conf/
2. [root@mynode5 conf]# vim azkaban.properties
编辑内容如下:
1. # Azkaban Personalization Settings
2. azkaban.name=My Azkaban #服务器UI上显示的名字
3. azkaban.label=My Local Azkaban #描述
4. azkaban.color=#FF3601 #web ui 颜色
5. azkaban.default.servlet.path=/index
6. web.resource.dir=/software/azkaban/azkaban-web/web/ #web目录
7. default.timezone.id=Asia/Shanghai #设置时区,用于任务调度定时
8. # Azkaban UserManager class
9. user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
10. user.manager.xml.file=/software/azkaban/azkaban-web/conf/azkaban-users.xml #用户配置文件
11. # Loader for projects
12. executor.global.properties=/software/azkaban/azkaban-web/conf/global.properties #全局配置文件
13. azkaban.project.dir=projects
14. # Velocity dev mode
15. velocity.dev.mode=false
16. # Azkaban Jetty server properties.
17. jetty.use.ssl=false #Jetty 服务器属性,开启配置成true
18. jetty.maxThreads=25 #最大线程数
19. jetty.port=8081 #Jetty 端口
20. jetty.keystore=/software/azkaban/azkaban-web/keystore #SSL 文件名
21. jetty.password=azkaban #SSL 文件密码
22. jetty.keypassword=azkaban #Jetty 主密码 与 keystore 文件相同
23. jetty.truststore=/software/azkaban/azkaban-web/keystore #SSL 文件名
24. jetty.trustpassword=azkaban # SSL 文件密码
25. jetty.ssl.port=8443 #配置ssl之后访问端口
26. # Azkaban Executor settings
27. # mail settings
28. mail.sender=
29. mail.host=
30. # User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
31. # enduser -> myazkabanhost:443 -> proxy -> localhost:8081
32. # when this parameters set then these parameters are used to generate email links.
33. # if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
34. # azkaban.webserver.external_hostname=myazkabanhost.com
35. # azkaban.webserver.external_ssl_port=443
36. # azkaban.webserver.external_port=8081
37. job.failure.email=
38. job.success.email=
39. lockdown.create.projects=false
40. cache.directory=cache
41. # JMX stats
42. jetty.connector.stats=true
43. executor.connector.stats=true
44. executor.port=12312 #executor 服务器端口
45. # Azkaban mysql settings by default. Users should configure their own username and password.
46. database.type=mysql #数据库类型
47. mysql.port=3306 #端口号
48. mysql.host=mynode2 #数据库连接Ip
49. mysql.database=azkaban #数据库实例
50. mysql.user=root #数据库用户名
51. mysql.password=123456 #数据库密码
52. mysql.numconnections=100 #最大连接数
53. #Multiple Executor
54. azkaban.use.multiple.executors=true
55. azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus # MinimumFreeMemory 去掉,因为检查每台节点是否有6G内存
56. azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
57. azkaban.executorselector.comparator.Memory=1
58. azkaban.executorselector.comparator.LastDispatched=1
59. azkaban.executorselector.comparator.CpuUsage=1
1.13.3.3 Azkaban executor服务器配置
进入/software/azkaban/azkaban-exec/conf目录下,编辑azkaban.properties文件:
1. # Azkaban Personalization Settings
2. azkaban.name=My Azkaban
3. azkaban.label=My Local Azkaban
4. azkaban.color=#FF3601
5. azkaban.default.servlet.path=/index
6. web.resource.dir=/software/azkaban/azkaban-web/web/
7. default.timezone.id=Asia/Shanghai
8. # Azkaban UserManager class
9. user.manager.class=azkaban.user.XmlUserManager
10. user.manager.xml.file=/software/azkaban/azkaban-web/conf/azkaban-users.xml
11. # Loader for projects
12. executor.global.properties=/software/azkaban/azkaban-web/conf/global.properties
13. azkaban.project.dir=projects
14. # Velocity dev mode
15. velocity.dev.mode=false
16. # Azkaban Jetty server properties.
17. jetty.use.ssl=false #不需要在executor中配置
18. jetty.maxThreads=25 #不需要在executor中配置
19. jetty.port=8081 #不需要在executor中配置
20. # Where the Azkaban web server is located
21. azkaban.webserver.url=http://localhost:8081
22. # mail settings
23. mail.sender=
24. mail.host=
25. # User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
26. # enduser -> myazkabanhost:443 -> proxy -> localhost:8081
27. # when this parameters set then these parameters are used to generate email links.
28. # if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
29. # azkaban.webserver.external_hostname=myazkabanhost.com
30. # azkaban.webserver.external_ssl_port=443
31. # azkaban.webserver.external_port=8081
32. job.failure.email=
33. job.success.email=
34. lockdown.create.projects=false
35. cache.directory=cache
36. # JMX stats
37. jetty.connector.stats=true
38. executor.connector.stats=true
39. # Azkaban plugin settings
40. azkaban.jobtype.plugin.dir=/software/azkaban/azkaban-exec/plugins/jobtypes
41. # Azkaban mysql settings by default. Users should configure their own username and password.
42. database.type=mysql
43. mysql.port=3306
44. mysql.host=mynode2
45. mysql.database=azkaban
46. mysql.user=root
47. mysql.password=123456
48. mysql.numconnections=100
49. # Azkaban Executor settings
50. executor.maxThreads=50
51. executor.port=12321
52. executor.flow.threads=30
1.13.3.4 启动Azkaban
- 启动AzkabanExecutorServer
进入/software/azkaban/azkaban-exec/bin目录,启动AzkabanExecutorServer,jps 检查进程,出现AzkabanExecutorServer进程表示启动成功。
1. [root@mynode5 bin]# cd /software/azkaban/azkaban-exec/bin
2. [root@mynode5 bin]# ./start-exec.sh
3. [root@mynode5 bin]# jps
4. 8745 AzkabanExecutorServer
5. 8763 Jps
- 激活AzkabanExecutor
启动AzkabanExecutor需要激活,在浏览器中执行如下命令,激活AzkabanExecutor:
1. http://mynode5:12321/executor?action=activate
- 启动AzkabanWebServer
进入/software/azkaban/azkaban-web/bin目录,启动AzkabanWebServer,jps检查进程,出现AzkabanWebServer进程表示启动成功。
1. [root@mynode5 bin]# cd /software/azkaban/azkaban-web/bin
2. [root@mynode5 bin]# ./start-web.sh
3. [root@mynode5 bin]# jps
4. 8805 Jps
5. 8792 AzkabanWebServer
6. 8745 AzkabanExecutorServer
至此,Azkaban的搭建已经完成,下面检查Azkaban运行情况。
1.13.4 验证Azkaban运行情况
验证Azkaban是否启动成功,可以访问Azkaban的WebUI界面,检查是否启动成功。在浏览器输入http://mynode5:8081,检查是否安装成功: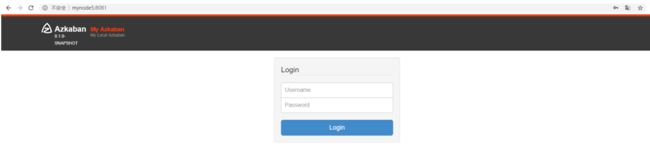
输入地址之后,出现以上页面表示配置Azkaban没有问题,Azkaban启动成功,默认的用户名和密码都是Azkaban,可以输入用户名和密码登录Azkaban的界面提交任务流,进行任务管理和调度。
至此,Azkaban搭建成功,下面我们模拟一个任务流来尝试利用Azkaban来进行任务调度。
1.13.5 构建工作流
以上小节介绍了安装部署Azkaban,本节中我们将设计一个模拟的任务流程flow,通过这个任务流程来学习如何编写Azkaban的任务、如何在WebUI中查看任务流调度及状态。
首先介绍下Azkaban中project、flows、job之间的关系:一个project中可以包含一个或者多个flows,一个flows包含多个job。这里的job是在Azkaban中运行的一个进程,可以是简单的linux命令、shell脚本、sql脚本等。一个job可以依赖于另一个job,这种多个job之间的依赖关系组成flow,也就是任务流。
1.13.5.1 设计工作流程
假设现在有5个job,分别是job1、job2、job3、job4、job5。每个job都执行一个shell 脚本。job3依赖与job1和job2执行的结果,job4依赖于job3执行的结果,job5依赖于job4执行的结果。
针对以上这个任务需求,我们可以设计一个任务流(flow),这个任务流中有5个job,按照上述job依赖的关系,可以编写一个简单的任务流程提交到Azkaban中进行调度执行。
1.13.5.2 编写各阶段Job
编写job非常容易,需要创建一个以".job"结尾的文本文件,文件中书写格式如下:
1. type=command
2. command= 需要执行的脚本或命令
type=command 是告诉Azkaban使用unix原生命令去运行命令或者脚本,command=“xxx”就是指定当前job需要执行的命令或者脚本,如果当前job依赖于其他的job,只需要在这个文本文件后面加上“dependencies=依赖的job名称”即可,依赖的job只需要写名称,不需要写出后缀“job”。
为了方便演示以上工作流程,这里设计的每个job都调起linux上的一个脚本,脚本中就使用简单的echo打印一些信息供参看,5个job及对应的脚本设置内容如下:
- 编写job任务
job1.job:
1. type=command
2. command= sh job1.sh
job2.job:
1. type=command
2. command= sh job2.sh
job3.job:
1. type=command
2. command= sh job3.sh
3. dependencies=job1,job2
job4.job:
1. type=command
2. command= sh job4.sh
3. dependencies=job3
job5.job:
1. type=command
2. command= sh job5.sh
3. dependencies=job4
以上job任务的编写可以在本地window环境中编写,编写完成后需要将5个job压缩到一个压缩文件中,后期提交到Azkaban中执行。
- 编写脚本内容
job1.sh:
1. echo "开始执行job1... ... "
2. echo "正在执行job1... ... "
3. echo "执行完成job1... ... "
job2.sh:
1. echo "开始执行job2... ... "
2. echo "正在执行job2... ... "
3. echo "执行完成job2... ... "
job3.sh:
1. echo "开始执行job3... ... "
2. echo "正在执行job3... ... "
3. echo "执行完成job3... ... "
job4.sh:
1. echo "开始执行job4... ... "
2. echo "正在执行job4... ... "
3. echo "执行完成job4... ... "
job5.sh:
1. echo "开始执行job5... ... "
2. echo "正在执行job5... ... "
3. echo "执行完成job5... ... "
以上脚本是在linux中编写,job1.sh、job2.sh、job3.sh、job4.sh、job5.sh几个脚本都需要赋予执行权限。
1.13.5.3 配置工作流并执行
Azkaban中任务提交时,必须将所有job文件压缩到一个zip文件中再提交到Azkaban中执行。首先将以上5个job压缩到一个zip文件中,然后登陆Azkaban,点击右上角的Create Project 创建一个项目:
在弹出的框中填写项目名称及项目描述: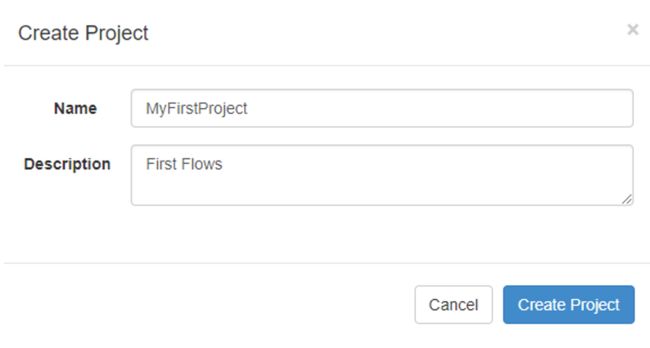
点击Create Project,点击upload,上传压缩好的任务: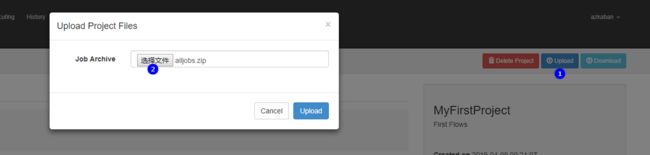
上传完成之后,查看任务流,Azkaban默认Flow名称是以最后一个没有依赖的job定义的: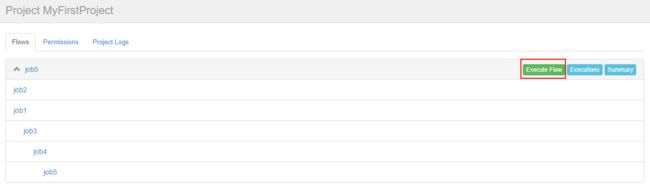
点击Execute Flow 可以看到任务流的详细依赖关系:
点击Execute执行任务。
如果想要每隔一段时间执行一次任务,可以点击Schedule,配置定时任务,配置好时间之后,点击Schedule调度即可。如图示: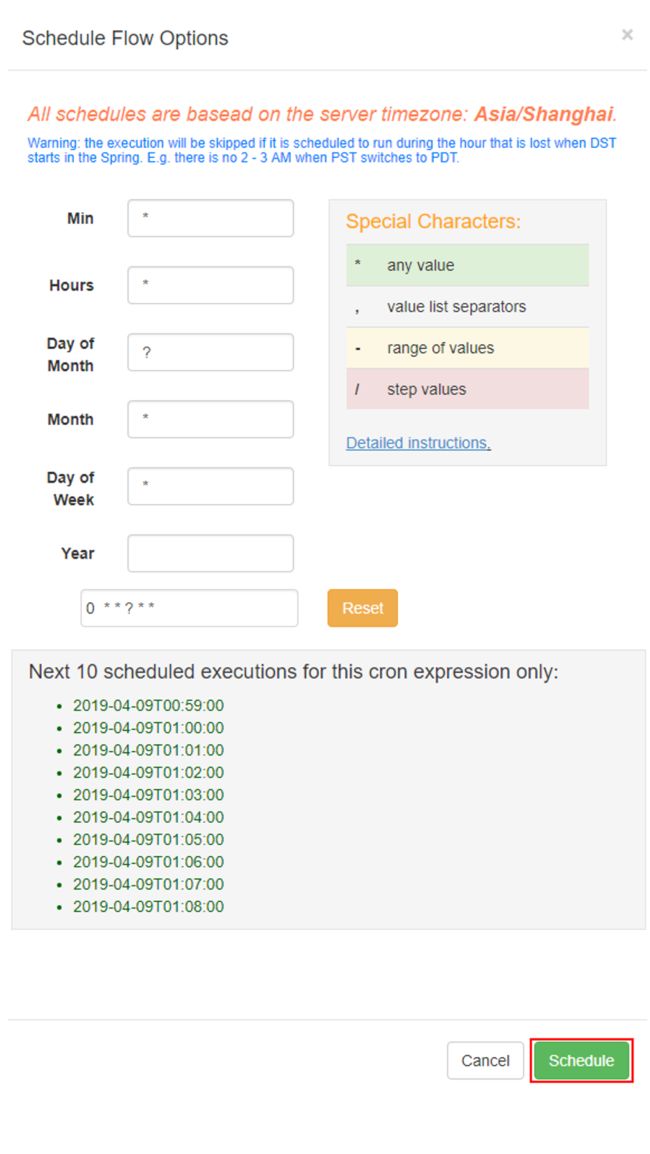
1.13.5.4 工作流执行监控
执行任务完成之后,会自动跳转到执行成功界面:
可以点击Job List 来查看详细job的执行先后顺序:
还可以通过点击每个job的详细信息查看任务执行过程中产生的日志信息:
例如:点击job2的Details信息,可以看到:
1. 09-04-2019 00:46:42 CST job2 INFO - Starting job job2 at 1554742002885
2. 09-04-2019 00:46:42 CST job2 INFO - job JVM args: -Dazkaban.flowid=job5 -Dazkaban.execid=5 -Dazkaban.jobid=job2
3. 09-04-2019 00:46:42 CST job2 INFO - user.to.proxy property was not set, defaulting to submit user azkaban
4. 09-04-2019 00:46:42 CST job2 INFO - Building command job executor.
5. 09-04-2019 00:46:42 CST job2 INFO - Memory granted for job job2
6. 09-04-2019 00:46:42 CST job2 INFO - 1 commands to execute.
7. 09-04-2019 00:46:42 CST job2 INFO - cwd=/software/azkaban/azkaban-exec/bin/executions/5
8. 09-04-2019 00:46:42 CST job2 INFO - effective user is: azkaban
9. 09-04-2019 00:46:42 CST job2 INFO - Command: sh /software/test/job2.sh
10. 09-04-2019 00:46:42 CST job2 INFO - Environment variables: {
JOB_OUTPUT_PROP_FILE=/software/azkaban/azkaban-exec/bin/executions/5/job2_output_6774298763557644376_tmp, JOB_PROP_FILE=/software/azkaban/azkaban-exec/bin/executions/5/job2_props_595600383798337016_tmp, KRB5CCNAME=/tmp/krb5cc__MyFirstProject__job5__job2__5__azkaban, JOB_NAME=job2}
11. 09-04-2019 00:46:42 CST job2 INFO - Working directory: /software/azkaban/azkaban-exec/bin/executions/5
12. 09-04-2019 00:46:42 CST job2 INFO - 开始执行job2... ...
13. 09-04-2019 00:46:42 CST job2 INFO - 正在执行job2... ...
14. 09-04-2019 00:46:42 CST job2 INFO - 执行完成job2... ...
15. 09-04-2019 00:46:42 CST job2 INFO - Process completed successfully in 0 seconds.
16. 09-04-2019 00:46:42 CST job2 INFO - output properties file=/software/azkaban/azkaban-exec/bin/executions/5/job2_output_6774298763557644376_tmp
17. 09-04-2019 00:46:42 CST job2 INFO - Finishing job job2 at 1554742002940 with status SUCCEEDED
1.13.6 Azkaban 问题
如果在提交Azkaban时出现任务一直运行状态,但是执行不完成,查看azkaban webui日志发现“Cannot request memory (Xms 0 kb, Xmx 0 kb) from system for job job1, sleep for 60 secs and retry, at.. ...”问题,原因是执行主机内存不足引起,azkaban要求执行主机可用内存必须大于3G才能满足执行任务的条,可以在../azkaban-exec/plugins/jobtype目录下,配置commonprivate.properties文件,在文件中加入“memCheck.enabled=false”,不检查内存即可,重启azkaban。
1.14 Superset 安装
Superset 是一款由 Airbnb 开源的“现代化的企业级 BI(商业智能) Web 应用程序”,其通过创建和分享 dashboard,为数据分析提供了轻量级的数据查询和可视化方案。
Superset 的前端主要用到了 React 和 NVD3/D3,而后端则基于 Python 的 Flask 框架和 Pandas、SQLAlchemy 等依赖库,主要提供了这几方面的功能:
- 集成数据查询功能,支持多种数据库,包括 MySQL、PostgresSQL、Oracle、SQL Server、SQLite、SparkSQL 等,并深度支持 Druid。
- 通过 NVD3/D3 预定义了多种可视化图表,满足大部分的数据展示功能。如果还有其他需求,也可以自开发更多的图表类型,或者嵌入其他的 JavaScript 图表库(如 HighCharts、ECharts)。
- 提供细粒度安全模型,可以在功能层面和数据层面进行访问控制。支持多种鉴权方式(如数据库、OpenID、LDAP、OAuth、REMOTE_USER 等)。
1.14.1 Superset基于window安装
- 创建虚拟环境
Superset依赖的包比较多,为了避免冲突,先创建个python的虚拟环境,Superset需要python3.6的环境。这里基于Anaconda中创建python3.6虚拟环境。使用Anaconda自带的conda工具创建虚拟环境,直接进入cmd,输入如下命令:
1. conda create -n superset python=3.6
2.
- 创建环境后激活环境
在cmd中输入如下命令激活python3.6环境,这里就是使用这个刚刚创建的python环境:
1. activate superset
2.
3. 安装Superset
1. (superset) C:\Users\wubai>pip install superset
2.
安装过程中报错如下:

这里的错误时python-geohash这个依赖没有安装成功,这里手动下载这个whl依赖进行手动安装。下载whl的网站如下:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#python-geohash
搜索对应的whl按照对应的虚拟环境中的python版本进行下载即可,这里下载的是python36的64位的geohash whl安装包。
whl附件:
下载后保存到D盘下,然后在虚拟python环境中手动安装geohash包:
1. (superset) C:\Users\wubai>pip install d:python_geohash-0.8.5-cp36-cp36m-win_amd64.whl
2.
如图:
这样,缺失的依赖就安装成功,重新在python虚拟环境中执行pip install superset,报错如下(大概在报错的倒数10行内):
1. error: could not create 'build\lib\superset\static\assets\.terser-plugin-cache\content-v2\sha512\00\0f\4e8df4f5ee7921b2270d4e4b41484d51b0f9179c662a55d62128f18abf1686780a3620666b8d0f53752f414c3c1bdf8cafd5de04e357c01b4ec561ab7581': No such file or directory
2.
以上报错原因为:Windows本身不允许创建非常长的路径,那么有一些软件的安装(编译安装)等在创建长路径的时候会失败,就会报以上错误。
解决方式如下:
打开注册表编辑器:regedit
找到以下路径:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSytem
找到如下键值:LongPathsEnabled
将值修改为1:默认是0,不启用。
经过以步骤设置,继续使用pip install superset即可成功。
4. 初始化superset
官方初始化步骤如下:
1. # 创建管理员账号
2. fabmanager create-admin --app superset
3.
4. # 初始化数据库
5. superset db upgrade
6.
7. # 载入案例数据
8. superset load_examples
9.
10. # 初始化角色和权限
11. superset init
12.
13. # 启动服务,端口号 8088,使用 -p 更改端口号
14. superset run
15.
注意:
- 创建管理员账号时,Superset 会使用 sqlite 数据库,sqlite 数据库默认在当前用户下
~/.superset/superset.db,如果是重复安装Superset需要将superset.db删除。
- 在虚拟的python环境中初始化数据库时,报错如下:

在命令行中直接运行 superset, 会提示“不是内部或外部命令”。要解决这个问题,可以直接通过 cd 命令进入 Superset 安装目录:
…\Anaconda3\envs\superset\Lib\site-packages\superset\bin )。然后运行如下命令:
1. python superset db upgrade
2. python superset load_examples
3. python superset init
4. python superset run
5.
![]()
- 执行
python superset load_examples根据网络速度不同,等待时间稍微长一些,也有可能报错:“urllib.error.URLError:多重试几次即可。”
- 运行superset,启动服务。
启动服务,在superset旧版本中使用superset runserver 启动服务,在0.30.0版本中使用superset run启动。可以使用python superset run -h 0.0.0.0 -p 8088来指定端口启动服务,-h 0.0.0.0是避免只能本地访问superset服务。默认使用superset run启动的访问路径和端口为:http://127.0.0.1:5000
1.14.2 SuperSet基于Linux安装
1.安装superSet之前安装基础依赖
yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
2.官网下载Anconda ,选在linux版本,并安装
下载官网地址:https://www.anaconda.com/products/individual#macos
3.将下载好的anconda安装包上传至mynode5节点,进行安装
sh Anaconda3-2020.02-Linux-x86_64.sh 【一路回车即可】
Do you accept the license terms? [yes|no]
Yes【继续回车】
... ...
Anaconda3 will now be installed into this location:
/root/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda3] >>> 【回车即可,安装到/root/anaconda3路径下】
... ...
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>>yes【输入yes,回车即可】
... ...
【安装完成】
4.配置Anconda的环境变量
在 /etc/profile中加入以下语句:
export PATH=$PATH:/root/anaconda3/bin
source /etc/profile
5.安装python3.6 python环境
conda create -n python36 python=3.6
6.激活使用python36 python环境
conda activate python36【激活使用python36环境,需要先执行下】
相关命令如下:
source activate 【初始化conda,必须执行,执行之后可以使用conda命令激活环境】
conda deactivate 【退出当前base环境】
conda activate python36【激活使用python36环境】
conda deactivate 【退出当前使用python36环境】
conda remove -n python36 --all 【删除python36环境】
7.安装superset
(superset) [root@mynode5 ~]# pip install apache-superset==0.36.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:-i https://pypi.tuna.tsinghua.edu.cn/simple 使用清华路径安装。
https://pypi.doubanio.com/simple 豆瓣源。
8.初始化superset
(python36) [root@mynode5 ~]# superset db upgrade 【初始化数据库】
(python36) [root@mynode5 ~]# superset fab create-admin 【创建用户名和密码】
(python36) [root@mynode5 ~]# superset load_examples 【加载样例,目前版本有问题,也可以不加载】
(python36) [root@mynode5 ~]# superset init 【初始化】
9.启动superset
(python36) [root@mynode5 ~]# superset run -h 0.0.0.0 -p 8088
注意:-p 8088来指定端口启动服务,-h 0.0.0.0是避免只能本地访问superset服务。
10.关闭superset
ctrl+c 可以关闭当前进程,也可以以下方式:
(python36) [root@mynode5 ~]# netstat -nlp 【找到端口占用情况】
(python36) [root@mynode5 ~]# kill -9 xxx 【kill 端口对应的进程】
1.15 Superset使用
1.15.1 配置MySQL数据源
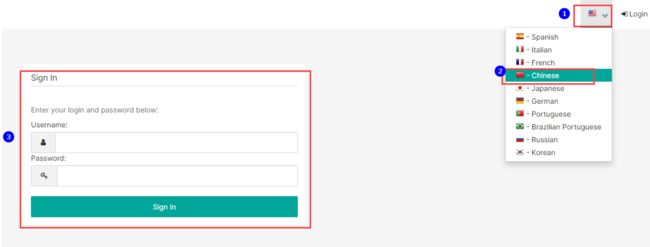
1.登录SuperSet
浏览器输入:http://mynode5:8088/登录SuperSet。
2.在Anconda中切换python36 环境,安装PyMySQL
MySQLdb模块目前在python2中支持,在python3中不支持,可以使用PyMySQL代替。
(python36) [root@mynode5 ~]# pip install PyMySQL
3.点击数据源,选择数据库,增加mysql数据源
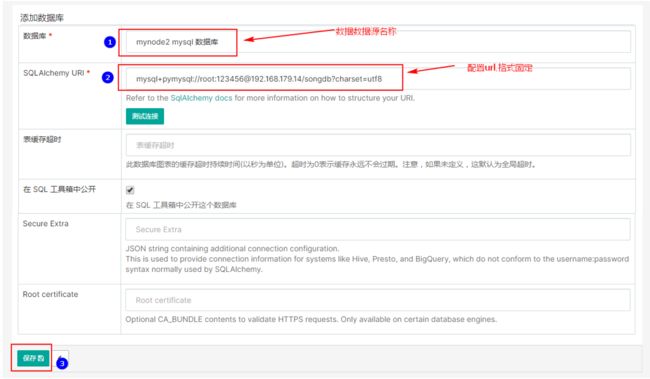
配置mysql数据源格式如下:
mysql+pymysql://root:123456@192.168.179.14/songdb?charset=utf8
1.15.2 添加MySQL数据库表并编辑
1.添加数据库表
点击数据源->数据表,选择右上角加号,增加数据表。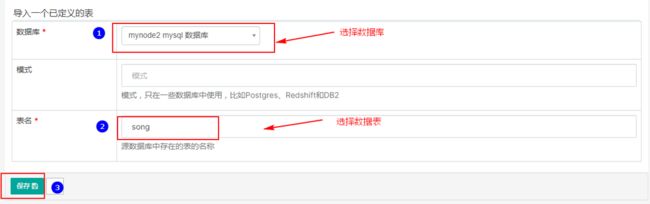
2.编辑表
点击创建好的song表,点击编辑,可以对列进行修改。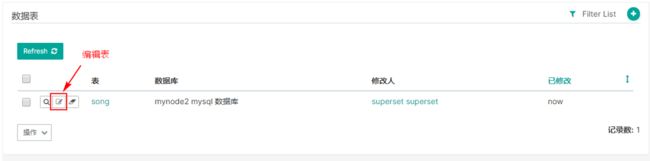
在编辑中,选择“列”标签下的编辑,可以对列进行修改名称: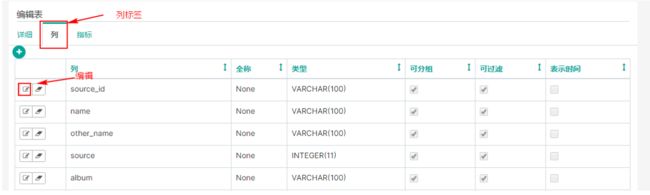
点击编辑可以给列添加全称命名/修改类型/执行是否分组、过滤:

选择“指标”标签下的编辑,可以对统计的“指标”进行命名: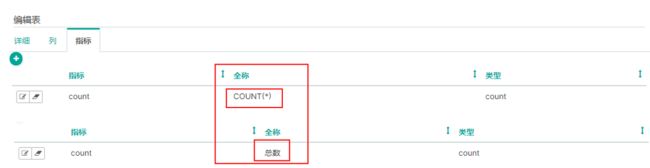
1.15.3 绘制图表
绘制图表可以在“数据源”->“数据表”,选择需要制图的表,双击表即可进入编辑图表面板。或者在“图表”标签右上角点击加号,创建新的图表: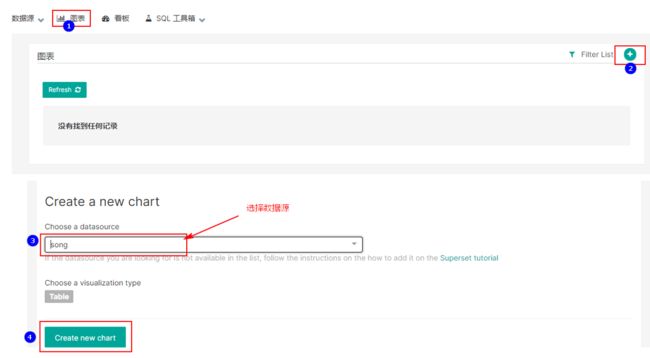
在弹出的页面中,选在图表类型,选择“表”格式: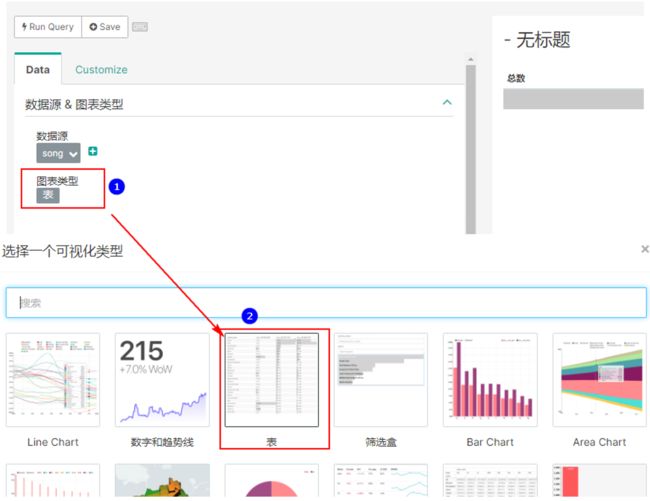
在弹出的页面中准备表显示的指标: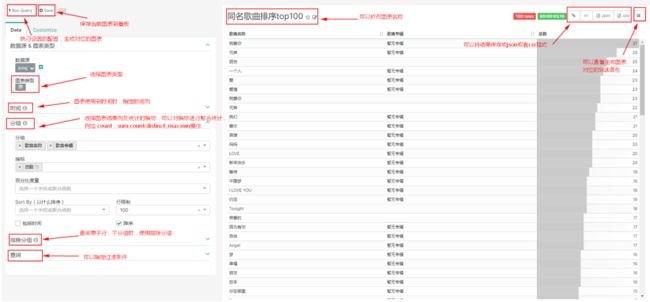
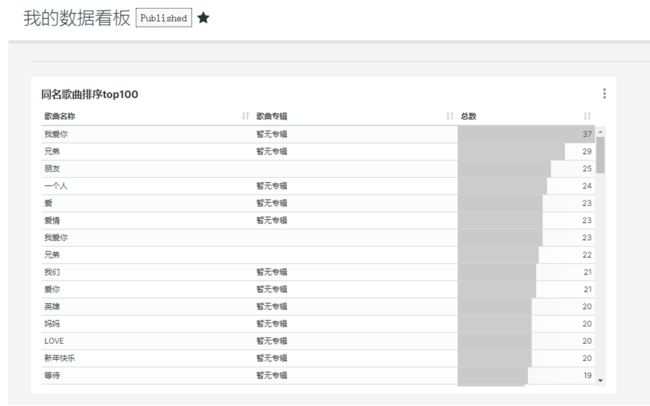
将图表结果保存到面板中,方便之后查询,点击右上角“save”: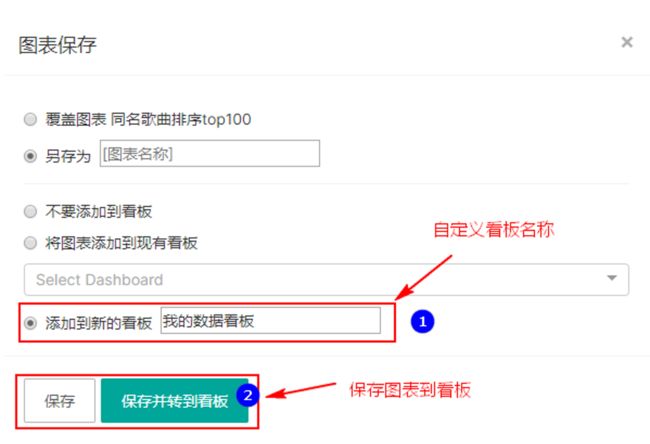
1.15.4 绘制柱状图
点击“数据源”->“数据表”,双击需要做图的表,在面板“图表类型”中,选择柱状图:
对弹出的面板进行如下编辑: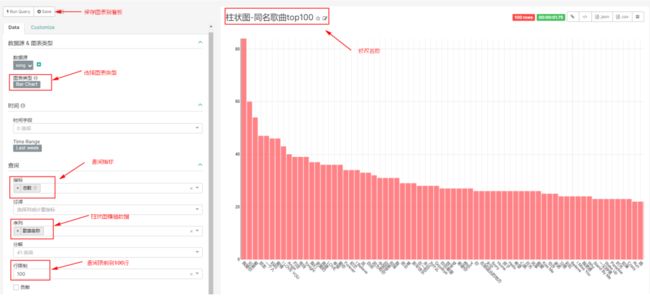
点击“Save”保存图表到已有看板: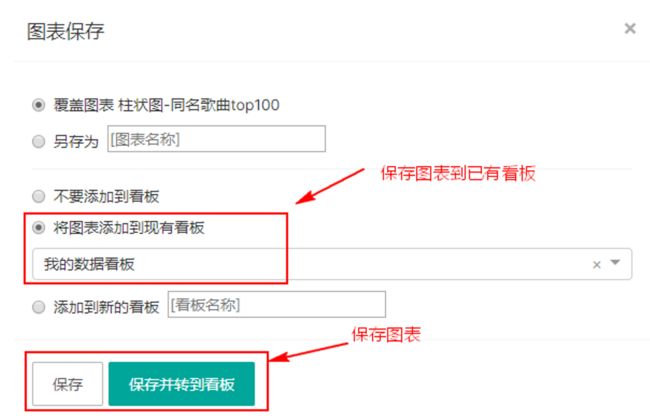
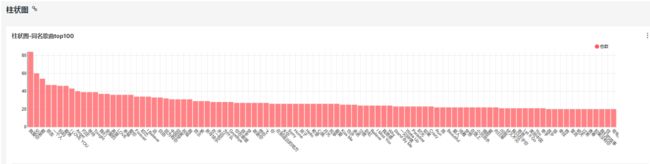
1.15.5 绘制折线图
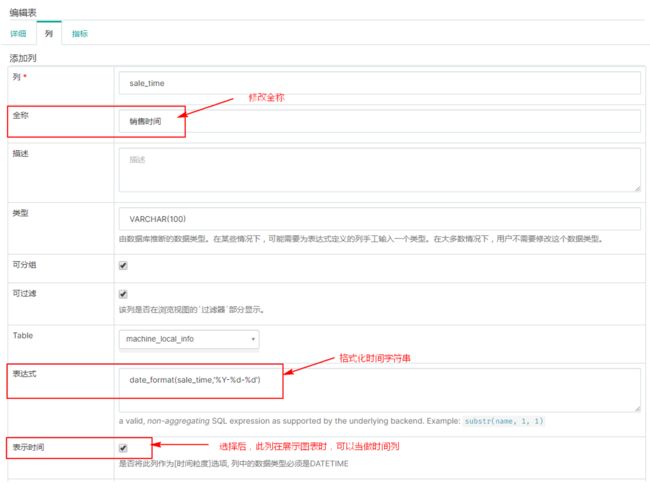
在“数据源”->“数据表”中添加含有时间列的表,表中的时间列可以是字符串,superset允许对字符串的时间列进行处理后当做时间列。例如:表“machine_local_info”中“sale_time”销售时间格式为“20201231”格式,可以通过编辑列,对数据进行表达式转换,当做时间列,后期在superset中方便展示与时间相关的图表。
点击“编辑”,对“machine_local_time”数据“sale_time”列进行编辑:
最后点击保存修改。双击表“machine_local_info”进行制作折线图: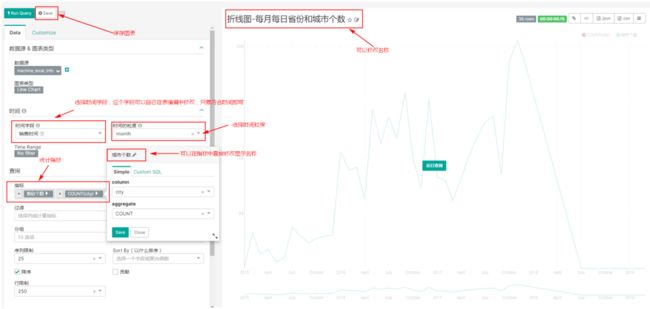
点击“save”保存图表到已有看板: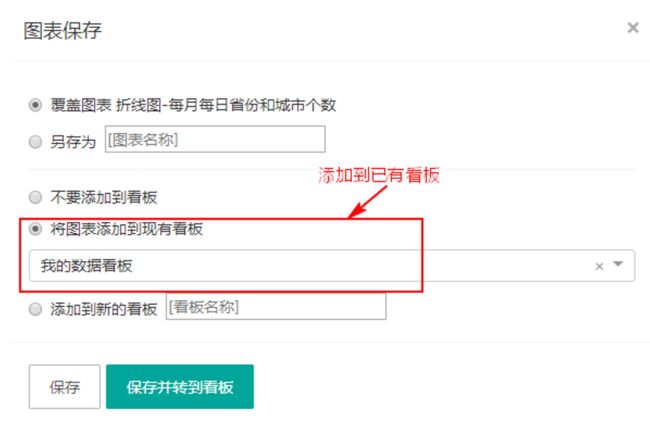
1.16 第一个业务:歌曲热度与歌手热度排行
1.16.1 需求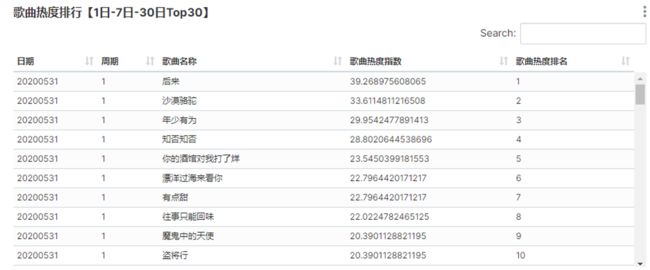
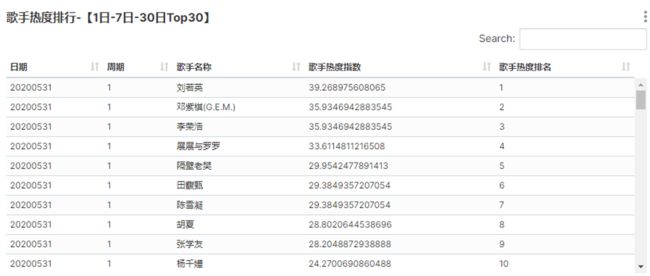
需求是根据用户在各个歌曲点唱机上的点歌行为,来统计最近昨日,近7日,近30日的歌曲点唱量、歌曲点赞量、点唱用户数、点唱订单数、7日和30日最高点唱量、7日和30日最高点赞量及各个周期的歌曲热度和歌手热度。
1.16.2 模型设计
要完成昨日的歌曲热度与歌手热度分析,需要以下两类数据:
1. 歌曲歌手的基本信息
这些信息放在业务系统的关系型数据库MySql song表中。通过sqoop每天定时全量覆盖抽取到数据仓库Hive中的ODS层中。关于song表的结构信息参看“数据仓库模型.xls”文件及mysql 数据song 表数据。
2. 用户在机器上的点歌行为数据
这部分数据是用户在各个机器上当天的点歌播放行为数据,这些数据是运维每天零点打包以gz压缩文件的方式上传到HDFS平台,这里我们假定将数据“currentday_clientlog.tar.gz”每天凌晨定时上传到HDFS路径“hdfs://mycluster/logdata”中,这里在企业中应当上传到某个以天名称的结构目录下,通过Spark数据清洗将数据存放到Hive数仓ODS层中。关于用户在机器上的点歌行为数据参照“事件上报协议.docx”文档。
这里根据需求将表分成如下三层: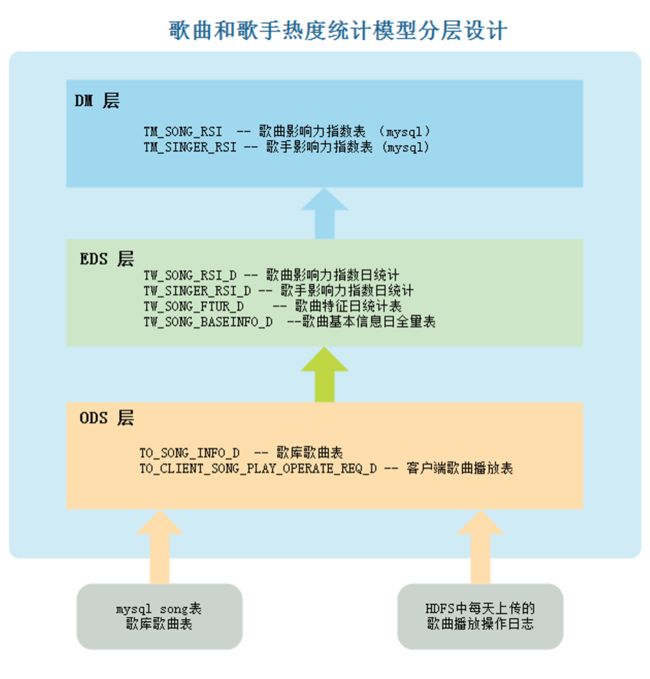
基于以上逻辑表建立物理模型如下:
1. TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 客户端歌曲播放表
CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D`(
`SONGID` string,
`MID` string,
`OPTRATE_TYPE` string,
`UID` string,
`CONSUME_TYPE` string,
`DUR_TIME` string,
`SESSION_ID` string,
`SONGNAME` string,
`PKG_ID` string,
`ORDER_ID` string
)
partitioned by (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D';
2. TO_SONG_INFO_D 歌库歌曲表
CREATE EXTERNAL TABLE `TO_SONG_INFO_D`(
`NBR` string,
`NAME` string,
`OTHER_NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER_INFO` string,
`POST_TIME` string,
`PINYIN_FST` string,
`PINYIN` string,
`SING_TYPE` int,
`ORI_SINGER` string,
`LYRICIST` string,
`COMPOSER` string,
`BPM_VAL` int,
`STAR_LEVEL` int,
`VIDEO_QLTY` int,
`VIDEO_MK` int,
`VIDEO_FTUR` int,
`LYRIC_FTUR` int,
`IMG_QLTY` int,
`SUBTITLES_TYPE` int,
`AUDIO_FMT` int,
`ORI_SOUND_QLTY` int,
`ORI_TRK` int,
`ORI_TRK_VOL` int,
`ACC_VER` int,
`ACC_QLTY` int,
`ACC_TRK_VOL` int,
`ACC_TRK` int,
`WIDTH` int,
`HEIGHT` int,
`VIDEO_RSVL` int,
`SONG_VER` int,
`AUTH_CO` string,
`STATE` int,
`PRDCT_TYPE` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TO_SONG_INFO_D';
3. TW_SONG_BASEINFO_D 歌曲基本信息日全量表
CREATE EXTERNAL TABLE `TW_SONG_BASEINFO_D`(
`NBR` string,
`NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER1` string,
`SINGER2` string,
`SINGER1ID` string,
`SINGER2ID` string,
`MAC_TIME` int,
`POST_TIME` string,
`PINYIN_FST` string,
`PINYIN` string,
`SING_TYPE` int,
`ORI_SINGER` string,
`LYRICIST` string,
`COMPOSER` string,
`BPM_VAL` int,
`STAR_LEVEL` int,
`VIDEO_QLTY` int,
`VIDEO_MK` int,
`VIDEO_FTUR` int,
`LYRIC_FTUR` int,
`IMG_QLTY` int,
`SUBTITLES_TYPE` int,
`AUDIO_FMT` int,
`ORI_SOUND_QLTY` int,
`ORI_TRK` int,
`ORI_TRK_VOL` int,
`ACC_VER` int,
`ACC_QLTY` int,
`ACC_TRK_VOL` int,
`ACC_TRK` int,
`WIDTH` int,
`HEIGHT` int,
`VIDEO_RSVL` int,
`SONG_VER` int,
`AUTH_CO` string,
`STATE` int,
`PRDCT_TYPE` array<string> )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_BASEINFO_D';
4. TW_SONG_FTUR_D 歌曲特征日统计表
CREATE EXTERNAL TABLE `TW_SONG_FTUR_D`(
`NBR` string,
`NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER1` string,
`SINGER2` string,
`SINGER1ID` string,
`SINGER2ID` string,
`MAC_TIME` int,
`SING_CNT` int,
`SUPP_CNT` int,
`USR_CNT` int,
`ORDR_CNT` int,
`RCT_7_SING_CNT` int,
`RCT_7_SUPP_CNT` int,
`RCT_7_TOP_SING_CNT` int,
`RCT_7_TOP_SUPP_CNT` int,
`RCT_7_USR_CNT` int,
`RCT_7_ORDR_CNT` int,
`RCT_30_SING_CNT` int,
`RCT_30_SUPP_CNT` int,
`RCT_30_TOP_SING_CNT` int,
`RCT_30_TOP_SUPP_CNT` int,
`RCT_30_USR_CNT` int,
`RCT_30_ORDR_CNT` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_FTUR_D';
5. TW_SINGER_RSI_D 歌手影响力日统计表
CREATE EXTERNAL TABLE `TW_SINGER_RSI_D`(
`PERIOD` string,
`SINGER_ID` string,
`SINGER_NAME` string,
`RSI` string,
`RSI_RANK` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SINGER_RSI_D';
6. TW_SONG_RSI_D 歌曲影响力日统计表
CREATE EXTERNAL TABLE `TW_SONG_RSI_D`(
`PERIOD` string,
`NBR` string,
`NAME` string,
`RSI` string,
`RSI_RANK` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/song/TW_SONG_RSI_D';
DM层两张表会在后期处理过程中,以SparkSQL方式每天覆盖更新到mysql表中,这里不单独建立对应的物理模型。
以上各个物理表之间的流转关系如下: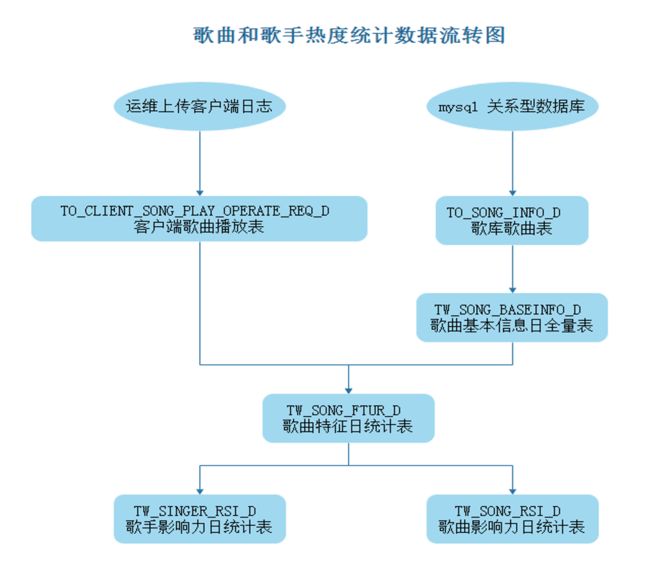
1.16.3 数据处理流程
1. 准备客户端日志,上传至HDFS中。
将客户端日志“currentday_clientlog.tar.gz”上传至HDFS目录“hdfs://mycluster/logdata”下,如果HDFS没有此目录需要先创建这个目录。这里模拟运维人员每天凌晨将数据上传至HDFS中。如果程序在本地运行,上传至当前项目下的data目录下,可以在项目application.conf进行配置。
2. 清洗客户端日志数据,保存到数仓ODS层
这里使用的是Spark读取上传到HDFS目录下的压缩数据,压缩数据中有很多张表,本业务中我们只需要获取客户端歌曲播放日志信息即可,这些数据在日志数据中的标识为“MINIK_CLIENT_SONG_PLAY_OPERATE_REQ”,这里读取这些数据进行ETL,保存到HDFS目录“hdfs://mycluster/logdata/all_client_tables”下,后期使用SparkSQL加载到对应的Hive 仓库 ODS层的“TO_CLIENT_SONG_PLAY_OPERATE_REQ_D”客户端歌曲播放表中。
对应的处理数据的代码文件:”ProduceClientLog.scala”
3. 抽取MySQL中song数据到Hive ODS
将MySQL中的“songdb”库中的“song”表通过sqoop抽取到对应的ODS层表“TO_SONG_INFO_D”中,这里需要安装sqoop工具,每天定时全量覆盖更新到Hive中。
首先在安装mysql的mynode2节点登录mysql,使用navicat工具连接mysql,创建 songdb库,在“songdb”库中导入“songdb.sql”文件,将“song”数导入到MySQL中。
创建“songdb”库:
create database songdb default character set utf8;
其次,在mynode3上执行sqoop导入数据脚本“ods_mysqltohive_to_song_info_d.sh”,将mysql中的song表数据导入到Hive 数仓“TO_SONG_INFO_D”表中,脚本内容如下:
1. sqoop import \
2. --connect jdbc:mysql://mynode2:3306/songdb?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
3. --username root \
4. --password 123456 \
5. --table song \
6. --target-dir /user/hive/warehouse/data/song/TO_SONG_INFO_D/ \
7. --delete-target-dir \
8. --num-mappers 1 \
9. --fields-terminated-by '\t'
sqoop后可以指定的参数,解释如下:
--connect :连接jdbc url
dontTrackOpenResources=true:你关闭所有的statement和resultset,但是如果你没有关闭connection的话,connection就会引用到statement和resultset上,从而导致GC不能释放这些资源(statement和resultset),当设置参数dontTrackOpenResources=true时,在statement关闭后,resultset也会被关闭,达到节省内存目的。
defaultFetchSize:设置每次拉取数据量。
useCursorFetch=true :设置连接属性 useCursorFetch=true (5.0版驱动开始支持),表示采用服务器端游标,每次从服务器取fetch_size条数据。
useUnicode=yes&characterEncoding=utf8 : 设置编码格式UTF8
--username : 数据库用户名
--password : 数据库密码
--table : import出的数据库表
--target-dir : 指定数据导入到HDFS中的路径。
--delete-target-dir :如果数据输出目录已存在则先删除
--num-mappers :当数据导入HDFS中时生成的MR任务使用几个map任务。
--hive-import :将数据从关系数据库中导入到 hive 表中,自动将数据导入到hive中,生成对应–hive-table 指定的表,表中的字段是直接从MySql中映射过来的字段。
--hive-database : 数据导入Hive中使用的Hive 库。
--hive-overwrite :覆盖掉在 Hive 表中已经存在的数据,与append只能使用一个。
--fields-terminated-by : 指定字段列分隔符,默认分隔符是’\001’,建议指定分隔符。
--hive-table : 导入的Hive表。
4. 清洗“歌库歌曲表”生成“歌曲基本信息日全量表”
由ODS层的歌库歌曲表 “TO_SONG_INFO_D”ETL得到歌曲基本信息日全量表“TW_SONG_BASEINFO_D”,主要是对原来数据字段切分,脏数据过滤,时间格式整理,字段提取等操作。
对应的ETL scala 文件为:”GenerateTwSongBaseinfoD.scala”。
5. EDS层生成“歌曲特征日统计表”
基于客户端歌曲播放表:“TO_CLIENT_SONG_PLAY_OPERATE_REQ_D”和歌曲基本信息日全量表:“TW_SONG_BASEINFO_D”生成歌曲特征日统计表:“TW_SONG_FTUR_D”,主要是按照两张表的歌曲ID进行关联,主要统计出歌曲在当天、7天、30天内的点唱信息和点赞信息。
对应的数据处理文件:“GenerateTwSongFturD.scala”
6. 统计歌手和歌曲热度
这里统计歌手和歌曲热度都是根据歌曲特征日统计表:“TW_SONG_FTUR_D”计算得到,主要借助了微信指数来统计对应的歌曲和歌手的热度,统计了当天、近7天、近30天每个歌手和歌曲的热度信息存放在对应的EDS层的歌手影响力指数日统计表“TW_SINGER_RSI_D”和歌曲影响力指数日统计表“TW_SONG_RSI_D”。
对应的数据处理文件:“GenerateTmSingerRsiD.scala”、“GenerateTmSongRsiD.scala”
注意问题1:
微信传播指数WCI可以显示出微信公众号的热度排名,公式由“清博指数”提供,其计算公式如下: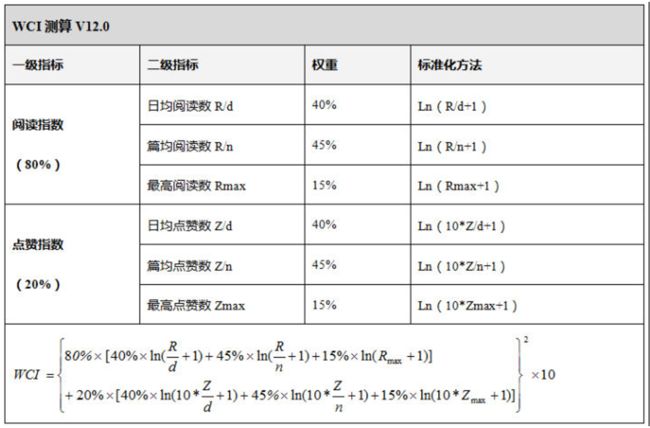
R为评估时间段内所有文章(n)的阅读总数。这里可以看成某个歌曲在一段时间内的总点唱数。
Z为评估时间段内所有文章(n)的点赞总数。这里可以看成某个歌曲在一段时间内的总点赞数。
d为评估时间段内所含天数,一般为周取7天,月取30天,年度取365天,其他自定义时间以真实的天数计算。
n为评估时间段内某公众号所发文章数。这里和歌曲无对应。
Rmax和Zmax为评估时间段内公众号所发文章的最高阅读数和点赞数。这里可以看成某个歌曲在一段时间内的总点唱数和总点赞数。
以上指数计算方式对应到歌曲指数计算方式如下: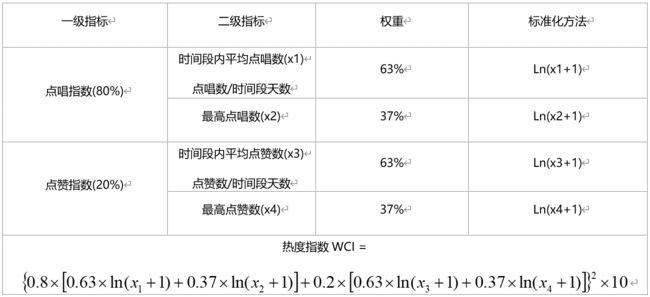
注意问题2:
在对歌曲特征日统计表:“TW_SONG_FTUR_D”进行统计得到歌手影响力指数日统计表“TW_SINGER_RSI_D”和歌曲影响力指数日统计表“TW_SONG_RSI_D”时,分别还将对应的结果使用SparkSQL保存到了MySQL中,对应的mysql库为“songresult”库。创建数据库时需要使用utf-8编码:
create database songresult default character set utf8;
对应的表分别为:“tm_singer_rsi”、“tm_song_rsi”。方便后期从mysql总查看数据结果。
另外,还需要在安装mysql的节点上配置“/etc/my.cnf”,在对应的标签下加入如下配置,更改mysql数据库编码格式为utf-8。
[mysqld]
default-character-set= utf8
[client]
default-character-set = utf8
配置完成之后,执行“service mysqld restart”重启mysql生效。
1.16.4 使用Azkaban配置任务流
这里使用Azkaban来配置任务流进行任务调度。集群中提交任务,需要修改项目中的application.conf文件配置项:local.run=“false”,并打包。
首先保证在Hive中对应的表都已经创建好。然后在安装azkaban的mynode5节点”/software/musicproject/”路径下准备如下脚本:
- 清洗客户端日志脚本 1produce_clientlog.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.ods.ProduceClientLog /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- mysql 数据抽取数据到 Hive ODS 脚本 2extract_mysqldata_to_ods.sh :
#!/bin/bash
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_song_info_d.sh
exit
aabbcc
echo "all done!"
- 清洗歌库歌曲表脚本 3produce_tw_song_baseinfo_d.sh:
#!/bin/bash
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.tw.GenerateTwSongBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar-
with-dependencies.jarexit
aabbcc
echo "all done!"
- 生成歌曲特征日统计表脚本 4produce_tw_song_ftur_d.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.song.GenerateTwSongFturD /root/test/MusicProject-1.0-SNAPSHOT-jar-with
-dependencies.jar $currentDateexit
aabbcc
echo "all done!"
- 生成歌曲热度表脚本 5produce_tw_song_rsi_d.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.content.GenerateTwSongRsiD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-
dependencies.jar $currentDateexit
aabbcc
echo "all done!"
- 生成歌手热度表脚本 6produce_tw_singer_rsi_d.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.content.GenerateTwSingerRsiD /root/test/MusicProject-1.0-SNAPSHOT-jar-wit
h-dependencies.jar $currentDateexit
aabbcc
echo "all done!"
编写azkaban 各个job组成任务流:
1. job1.job
type=command
command=sh /software/musicproject/1produce_clientlog.sh ${mydate}
2. job2.job
type=command
command=sh /software/musicproject/2extract_mysqldata_to_ods.sh
3. job3.job
type=command
command=sh /software/musicproject/3produce_tw_song_baseinfo_d.sh
dependencies=job2
4. job4.job
type=command
command=sh /software/musicproject/4produce_tw_song_ftur_d.sh ${mydate}
dependencies=job1,job3
5. job5.job
type=command
command=sh /software/musicproject/5produce_tw_song_rsi_d.sh ${mydate}
dependencies=job4
6. job6.job
type=command
command=sh /software/musicproject/6produce_tw_singer_rsi_d.sh ${mydate}
dependencies=job5
将以上6个job打包到压缩包中,在azkaban中提交执行即可。
注意:${mydate}是获取azkaban执行任务时指定的参数,这里是如果azkaban指定了参数就按照指定的参数处理数据,如果azkaban没有指定参数那么就由脚本获取当前系统天的时间来执行脚本。在执行azkaban任务流时可以指定参数: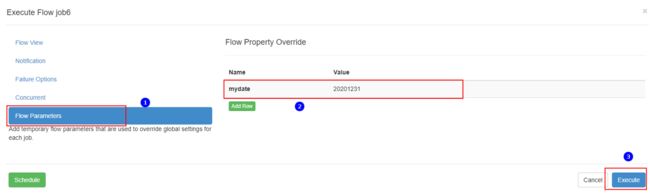
1.16.5 使用SuperSet数据可视化
1. 切换python环境,启动SuperSet
在mynode5节点上,执行命令“conda activate python36”切换python环境,并执行命令“superset run -h 0.0.0.0 -p 8088”启动Superset
2. 在superset中设计表可视化
1) 登录superset
浏览器输入:http://mynode5:8088,输入SuperSet的账号密码,登录,并切换中文。
2) 加载数据源
点击“数据源”->“数据库”,添加数据库: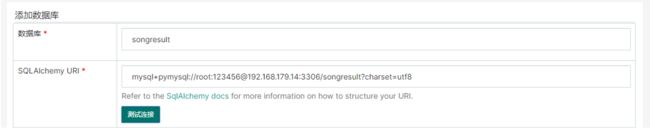
3) 加载数据表
点击“数据源”->“数据表”,添加“songresult”库下的表“tm_singer_rsi”和“tm_song_rsi”。
4) 修改表中对应字段显示名称
编辑表记录,找到列标签,编辑各个列的全称: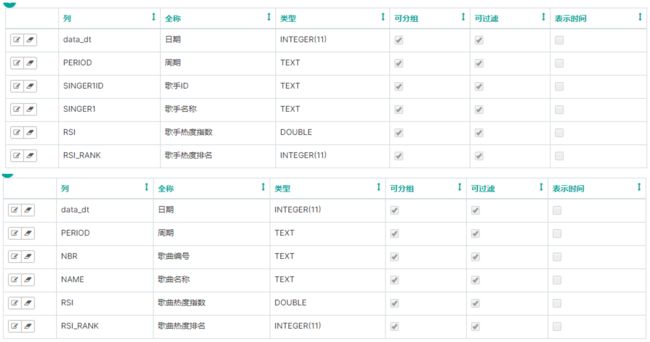
5) 编辑图表
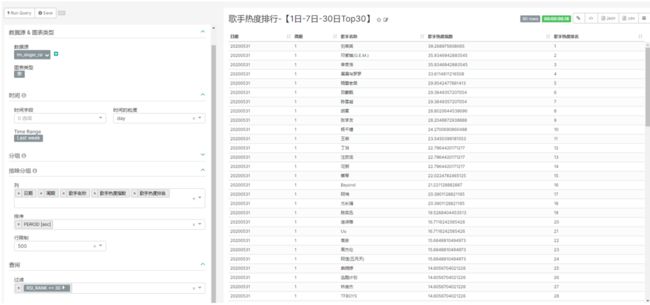
6) 面板可视化展示

1.17 第二个业务:机器详细信息统计
1.17.1 需求
目前要根据两个业务系统中的数据统计机器基础详细信息。这两个业务系统对应的关系型数据库分别是“ycak”“ycbk”。
“ycak”库中存在两张机器相关的数据库表如下:
“machine_baseinfo”机器基本信息表,机器的系统版本,歌库版本,UI版本,最近登录时间相关。
“machine_local_info”机器位置信息日全量表,机器所在的省市县及详细地址,运行时间和销售时间相关。
“ycbk”库中存在6张表,分别如下:
“machine_admin_map”机器客户映射资料表
“machine_store_map”机器门店映射关系表
“machine_store_info”门店信息全量表
“province_info”机器省份日全量表
“city_info”机器城市日全量表
“area_info”机器区县日全量表
注意:所有的机器信息来自于“machine_baseinfo”机器基本信息表与“machine_admin_map”机器客户映射资料表。
1.17.2 模型设计
完成以上机器详细信息统计,数据是分别存在两个业务系统库中,需要通过ODS将数据从关系型数据库抽取到Hive ODS层。
根据需求,针对机器进行分析,在数仓中我们构建“机器”主题,具体数据分层如下: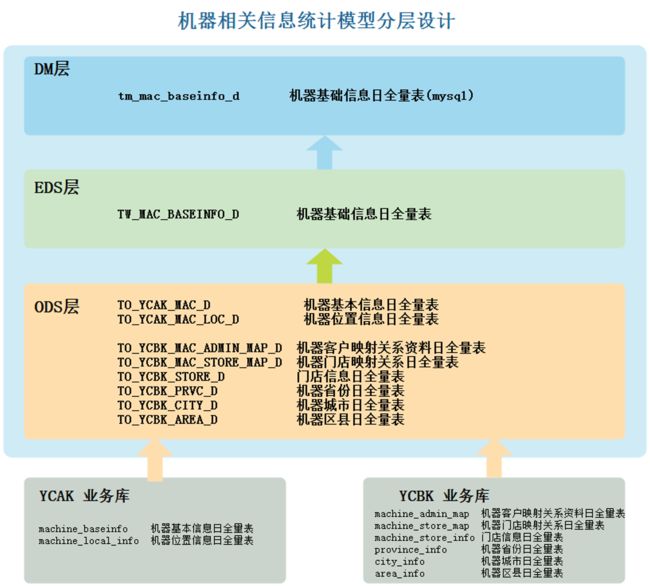
在Hive中建立ODS层对应的表:
1. TO_YCAK_MAC_D 机器基本信息表
CREATE EXTERNAL TABLE `TO_YCAK_MAC_D`(
`MID` int,
`SRL_ID` string,
`HARD_ID` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`IS_ONLINE` string,
`STS` int,
`CUR_LOGIN_TM` string,
`PAY_SW` string,
`LANG` int,
`SONG_WHSE_TYPE` int,
`SCR_TYPE` int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCAK_MAC_D';
2. TO_YCAK_MAC_LOC_D 机器位置信息表
CREATE EXTERNAL TABLE `TO_YCAK_MAC_LOC_D`(
`MID` int,
`PRVC_ID` int,
`CTY_ID` int,
`PRVC` string,
`CTY` string,
`MAP_CLSS` string,
`LON` string,
`LAT` string,
`ADDR` string,
`ADDR_FMT` string,
`REV_TM` string,
`SALE_TM` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCAK_MAC_LOC_D';
3. TO_YCBK_MAC_ADMIN_MAP_D 机器客户映射资料表
CREATE EXTERNAL TABLE `TO_YCBK_MAC_ADMIN_MAP_D`(
`MID` int,
`MAC_NM` string,
`PKG_NUM` int,
`PKG_NM` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`DEPOSIT` double,
`SCENE_PRVC_ID` string,
`SCENE_CTY_ID` string,
`SCENE_AREA_ID` string,
`SCENE_ADDR` string,
`PRDCT_TYPE` string,
`SERIAL_NUM` string,
`HAD_MPAY_FUNC` int,
`IS_ACTV` int,
`ACTV_TM` string,
`ORDER_TM` string,
`GROUND_NM` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_MAC_ADMIN_MAP_D';
4. TO_YCBK_MAC_STORE_MAP_D 机器门店映射关系表
CREATE EXTERNAL TABLE `TO_YCBK_MAC_STORE_MAP_D`(
`STORE_ID` int,
`MID` int,
`PRDCT_TYPE` int,
`ADMINID` int,
`CREAT_TM` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_MAC_STORE_MAP_D';
5. TO_YCBK_STORE_D 门店信息表
CREATE EXTERNAL TABLE `TO_YCBK_STORE_D`(
`ID` int,
`STORE_NM` string,
`TAG_ID` string,
`TAG_NM` string,
`SUB_TAG_ID` string,
`SUB_TAG_NM` string,
`PRVC_ID` string,
`CTY_ID` string,
`AREA_ID` string,
`ADDR` string,
`GROUND_NM` string,
`BUS_TM` string,
`CLOS_TM` string,
`SUB_SCENE_CATGY_ID` string,
`SUB_SCENE_CATGY_NM` string,
`SUB_SCENE_ID` string,
`SUB_SCENE_NM` string,
`BRND_ID` string,
`BRND_NM` string,
`SUB_BRND_ID` string,
`SUB_BRND_NM` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_STORE_D';
6. TO_YCBK_PRVC_D 机器省份日全量表
CREATE EXTERNAL TABLE `TO_YCBK_PRVC_D`(
`PRVC_ID` int,
`PRVC` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_PRVC_D';
7. TO_YCBK_CITY_D 机器城市日全量表
CREATE EXTERNAL TABLE `TO_YCBK_CITY_D`(
`PRVC_ID` int,
`CTY_ID` int,
`CTY` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_CITY_D';
8. TO_YCBK_AREA_D 机器区县日全量表
CREATE EXTERNAL TABLE `TO_YCBK_AREA_D`(
`CTY_ID` int,
`AREA_ID` int,
`AREA` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_AREA_D';
9. TW_MAC_BASEINFO_D 机器基础信息日全量表
CREATE EXTERNAL TABLE `TW_MAC_BASEINFO_D`(
`MID` int,
`MAC_NM` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`HARD_ID` string,
`SALE_TM` string,
`REV_TM` string,
`OPER_NM` string,
`PRVC` string,
`CTY` string,
`AREA` string,
`ADDR` string,
`STORE_NM` string,
`SCENCE_CATGY` string,
`SUB_SCENCE_CATGY` string,
`SCENE` string,
`SUB_SCENE` string,
`BRND` string,
`SUB_BRND` string,
`PRDCT_NM` string,
`PRDCT_TYP` int,
`BUS_MODE` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`IS_ACTV` int,
`ACTV_TM` string,
`PAY_SW` int,
`PRTN_NM` string,
`CUR_LOGIN_TM` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_BASEINFO_D';
以上建模中,处理ODS层的各个表结构之外,EDS层TW_MAC_BASEINFO_D 表在对应的DM层也要一张表对应,这里DM层在mysql中有对应的tm_mac_baseinfo_d 表,以上各个表之间的数据流转过程如下: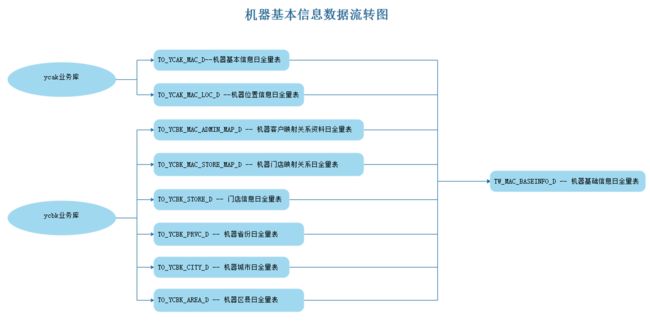
1.17.3 数据处理流程
3. 将数据导入到对应的MySQL业务库中
在MySQL中分别创建“ycak”、“ycbk”数据库,将“ycak.sql”“ycbk.sql”分别运行在对应的库下,将数据导入到业务库中。
create database ycak default character set utf8;
create database ycbk default character set utf8;
4. 使用Sqoop抽取数据到Hive ODS层
将“ycak”库下的“machine_baseinfo”表通过Sqoop每天全量覆盖导入到ODS层 TO_YCAK_MAC_D表中,导入脚本“ods_mysqltohive_to_ycak_mac_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_baseinfo \
--target-dir /user/hive/warehouse/data/machine/TO_YCAK_MAC_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycak”库下的“machine_local_info”表通过Sqoop每天全量覆盖导入到ODS层TO_YCAK_MAC_LOC_D表中,导入脚本“ods_mysqltohive_to_ycak_mac_loc_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_local_info \
--target-dir /user/hive/warehouse/data/machine/TO_YCAK_MAC_LOC_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“YCBK”库下的“machine_admin_map”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_MAC_ADMIN_MAP_D表中,导入脚本“ods_mysqltohive_to_ycbk_mac_admin_map_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_admin_map \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_MAC_ADMIN_MAP_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycbk”库下的“machine_store_map”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_MAC_STORE_MAP_D表中,导入脚本“ods_mysqltohive_to_ycbk_mac_store_map_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_store_map \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_MAC_STORE_MAP_D/ \
--delete-target-dir \
--num-mappers 1
--fields-terminated-by '\t'
将“ycbk”库下的“machine_store_info”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_STORE_D表中,导入脚本“ods_mysqltohive_to_ycbk_store_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_store_info \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_STORE_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycbk”库下的“province_info”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_PRVC_D表中,导入脚本“ods_mysqltohive_to_ycbk_prvc_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table province_info \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_PRVC_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycbk”库下的“city_info”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_CITY_D表中,导入脚本“ods_mysqltohive_to_ycbk_city_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table city_info \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_CITY_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycbk”库下的“area_info”表通过Sqoop每天全量覆盖导入到ODS层TO_YCBK_AREA_D表中,导入脚本“ods_mysqltohive_to_ycbk_area_d.sh”如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table area_info \
--target-dir /user/hive/warehouse/data/machine/TO_YCBK_AREA_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
5. 代码对ODS层数据进行ETL清洗
对以上8张表之间的关联及数据清洗对应的ETL scala 代码为:GenerateTwMacBaseinfoD.scala
1.17.4 使用Azkaban配置任务流
这里使用Azkaban来配置任务流进行任务调度。集群中提交任务,需要修改项目中的application.conf文件配置项:local.run=“false”。并将项目打包。
1. 首先在Hive中创建对应的ODS,EDS层的表。
结合模型设计,在Hive中创建对应的数据仓库表,执行以下对应的创建SQL文件。
TO_YCAK_MAC_D.sql
TO_YCAK_MAC_LOC_D.sql
TO_YCBK_MAC_ADMIN_MAP_D.sql
TO_YCBK_MAC_STORE_MAP_D.sql
TO_YCBK_STORE_D.sql
TO_YCBK_PRVC_D.sql
TO_YCBK_CITY_D.sql
TO_YCBK_AREA_D.sql
TW_MAC_BASEINFO_D.sql
2. 准备好抽取MySql数据表的脚本。
在安装Sqoop的客户端mynode3 /root/test路径下准备好如下抽取数据脚本。
ods_mysqltohive_to_ycak_mac_d.sh
ods_mysqltohive_to_ycak_mac_loc_d.sh
ods_mysqltohive_to_ycbk_mac_admin_map_d.sh
ods_mysqltohive_to_ycbk_mac_store_map_d.sh
ods_mysqltohive_to_ycbk_store_d.sh
ods_mysqltohive_to_ycbk_prvc_d.sh
ods_mysqltohive_to_ycbk_city_d.sh
ods_mysqltohive_to_ycbk_area_d.sh
同时,在安装azkaban的mynode5节点路径/software/musicproject/下准备如下脚本 extract_data.sh,同时赋予执行权限:
#!/bin/bash
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_ycak_mac_d.sh
sh ods_mysqltohive_to_ycak_mac_loc_d.sh
sh ods_mysqltohive_to_ycbk_mac_admin_map_d.sh
sh ods_mysqltohive_to_ycbk_mac_store_map_d.sh
sh ods_mysqltohive_to_ycbk_store_d.sh
sh ods_mysqltohive_to_ycbk_prvc_d.sh
sh ods_mysqltohive_to_ycbk_city_d.sh
sh ods_mysqltohive_to_ycbk_area_d.sh
exit
aabbcc
echo "all done!"
3. 编写提交Spark任务处理数据的脚本
在安装azkaban的mynode5节点路径/software/musicproject/下准备Spark处理数据的脚本:produce_tw_mac_baseinfo_d.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
4. 编写azkaban任务流,并提交执行。
1. job1.job
type=command
command=sh /software/musicproject/extract_data.sh ${mydate}
2. job2.job
type=command
command=sh /software/musicproject/produce_tw_mac_baseinfo_d.sh
dependencies=job1
1.17.5 使用SuperSet数据可视化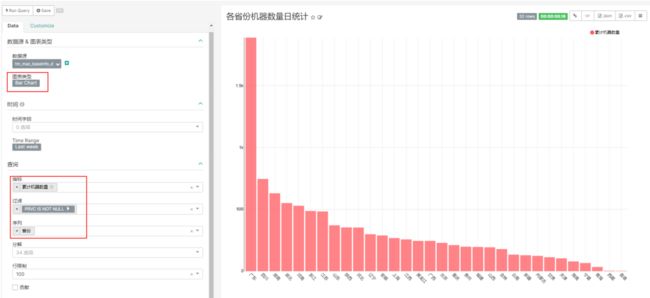
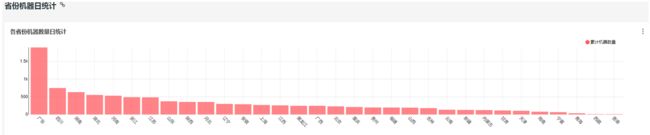

1.18 第三个业务:日活跃用户统计
1.18.1 需求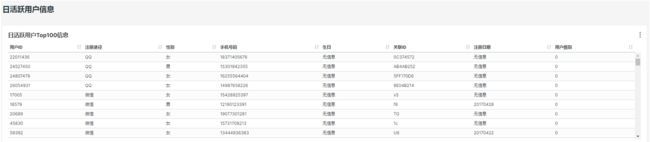
每天统计最近7日活跃用户的详细信息,如上图示例。
如果计算用户日活情况,需要获取对应的每天用户登录信息,用户登录信息被记录在“ycak”业务库下的“user_login_info”表中,这张表将用户每天登录系统,登出系统的信息记录下来,我们可以将这张表的信息每天增量的抽取到ODS层中,然后把用户的基本信息每天全量抽取到ODS层,然后获取每天活跃的用户信息,进而计算统计出7日用户活跃情况。这里用户的基本信息包含了四类注册用户的数据,存储在“ycak”业务库中,分别是:“user_wechat_baseinfo”、“user_alipay_baseinfo”、“user_qq_baseinfo”、“user_app_baseinfo”。
1.18.2 模型设计
将业务需要到的数据表通过Sqoop抽取到ODS层数据。根据业务我们在数仓中构建“用户主题”,具体数据分层如下: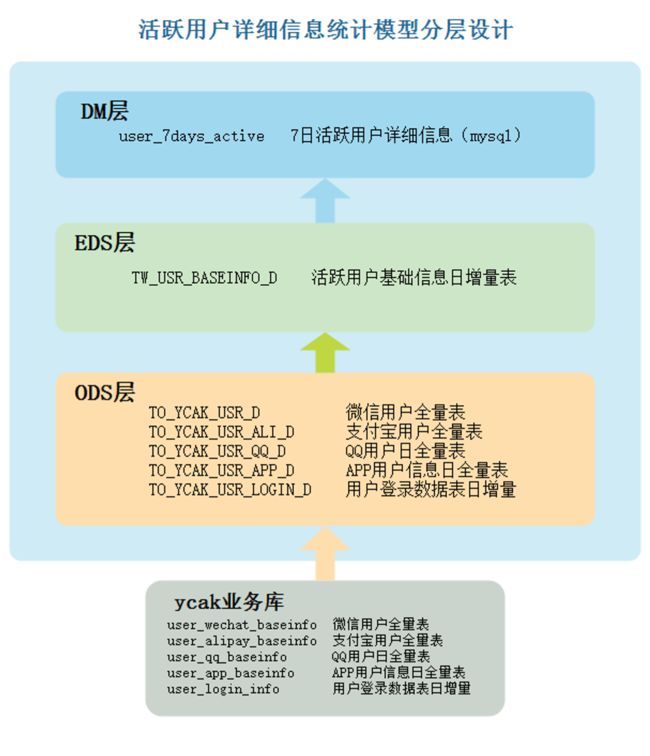
在Hive中构建ODS层对应的表:
TO_YCAK_USR_D :微信用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`WX_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_D';
TO_YCAK_USR_ALI_D :支付宝用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_ALI_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string,
`ALY_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_ALI_D';
TO_YCAK_USR_QQ_D : QQ用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_QQ_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`QQID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_QQ_D';
TO_YCAK_USR_APP_D :APP用户信息日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_APP_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`REG_TM` string,
`USR_EXP` string,
`LEVEL` int,
`APP_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_APP_D';
TO_YCAK_USR_LOGIN_D : 用户登录数据日增量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_LOGIN_D`(
`ID` int,
`UID` int,
`MID` int,
`LOGIN_TM` string,
`LOGOUT_TM` string,
`MODE_TYPE` int
)
PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_LOGIN_D';
TW_USR_BASEINFO_D :活跃用户基础信息日增量表
CREATE EXTERNAL TABLE `TW_USR_BASEINFO_D`(
`UID` int,
`REG_MID` int,
`REG_CHNL` string,
`REF_UID` string,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` string,
`REG_DT` string,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string
)
PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TW_USR_BASEINFO_D';
以上表模型中,最终获取7日用户活跃信息从EDS层“TW_USR_BASEINFO_D”表统计得到,这里将统计到的7日活跃用户情况存放在DM层,这里通过SparkSQL直接将结果存放在“user_7days_active”表中,提供查询展示。
以上各个表之间的数据流转关系如下: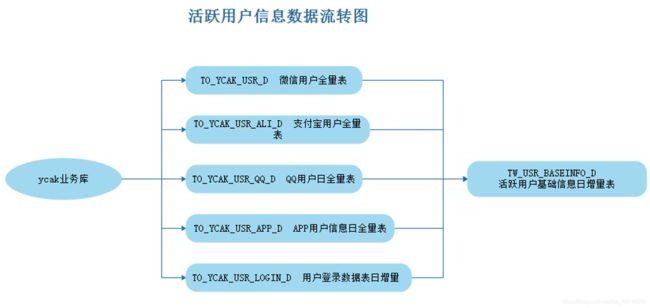
1.18.3 数据处理流程
1. 将数据导入mysql数据库中
在mysql中创建“ycak”数据库,将“ycak.sql”导入到ycak数据库中
create database ycak default character set utf8;
2. 使用Sqoop抽取mysql数据到ODS层
将“ycak”数据库下的“user_wechat_baseinfo”数据导入到ODS层“TO_YCAK_USR_D”表中,对应的sqoop脚本 ods_mysqltohive_to_ycak_usr_d.sh 内容如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_wechat_baseinfo \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycak”数据库下的“user_alipay_baseinfo”数据导入到ODS层“TO_YCAK_USR_ALI_D”表中,对应的sqoop脚本 ods_mysqltohive_to_ycak_usr_ali_d.sh 内容如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_alipay_baseinfo \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_ALI_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycak”数据库下的“user_qq_baseinfo”数据导入到ODS层“TO_YCAK_USR_QQ_D”表中,对应的sqoop脚本 ods_mysqltohive_to_ycak_usr_qq_d.sh 内容如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_qq_baseinfo \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_QQ_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycak”数据库下的“user_app_baseinfo”数据导入到ODS层“TO_YCAK_USR_APP_D”表中,对应的sqoop脚本 ods_mysqltohive_to_ycak_usr_app_d.sh 内容如下:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_app_baseinfo \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_APP_D/ \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
将“ycak”数据库下的“user_login_info”数据导入到ODS层“TO_YCAK_USR_LOGIN_D”表中,这里是每天增量导入,对应的sqoop脚本 ods_mysqltohive_to_ycak_usr_login_d.sh 内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====没有导入数据的日期,输入日期===="
exit
else
echo "====使用导入数据的日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
#查询hive ODS层表 TO_YCAK_USR_LOGIN_D 中目前存在的最大的ID
maxid=`hive -e "select max(id) from TO_YCAK_USR_LOGIN_D"`
echo "Hive ODS层表 TO_YCAK_USR_LOGIN_D 最大的ID是$maxid"
if [ x"$maxid" = xNULL ]; then
echo "maxid is NULL 重置为0"
maxid=0
fi
#sqoop 导入数据:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_login_info \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_LOGIN_D/data_dt=${currentDate} \
--num-mappers 1 \
--fields-terminated-by '\t' \
--incremental append \
--check-column id \
--last-value $maxid
#更新Hive 分区
hive -e "alter table TO_YCAK_USR_LOGIN_D add partition(data_dt=${currentDate});"
3. 使用SparkSQL对ODS层数据进行清洗
对应的处理数据的scala文件:GenerateTwUsrBaseinfoD.scala,将代码打包上传至mynode4节点/root/test下,提交到集群中运行即可,提交命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.eds.content.GenerateTwUsrBaseinfoD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
1.18.4 使用Azkaban配置任务流
这里使用Azkaban来配置任务流进行任务调度。集群中提交任务,需要修改项目中的application.conf文件配置项:local.run=“false”。并将项目打包。
- 确保在Hive中创建各个ODS层表及EDS层表
- 准备抽取mysql数据的sqoop脚本
在安装Sqoop的mynode3节点 /root/test路径下准备抽取数据的脚本:
ods_mysqltohive_to_ycak_usr_d.sh
ods_mysqltohive_to_ycak_usr_ali_d.sh
ods_mysqltohive_to_ycak_usr_qq_d.sh
ods_mysqltohive_to_ycak_usr_app_d.sh
ods_mysqltohive_to_ycak_usr_login_d.sh
另外,在安装azkaban的mynode5节点 /software/musicproject/下准备脚本 “extract_usr_data.sh”,注意当前脚本需要传入参数,内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_ycak_usr_d.sh
sh ods_mysqltohive_to_ycak_usr_ali_d.sh
sh ods_mysqltohive_to_ycak_usr_qq_d.sh
sh ods_mysqltohive_to_ycak_usr_app_d.sh
sh ods_mysqltohive_to_ycak_usr_login_d.sh $currentDate
exit
aabbcc
echo "all done!"
- 编写提交Spark任务处理数据的脚本
在安装azkaban的mynode5节点路径/software/musicproject/下,编写脚本produce_tw_usr_baseinfo_d.sh,内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.user.GenerateTwUsrBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- 编写azkaban任务进行提交
1. job1.job
type=command
command=sh /software/musicproject/extract_usr_data.sh ${mydate}
2. job2.job
type=command
command=sh /software/musicproject/produce_tw_usr_baseinfo_d.sh.sh ${mydate}
dependencies=job1
1.18.5 使用SuperSet数据可视化
添加数据表,给各个列重新指定全称: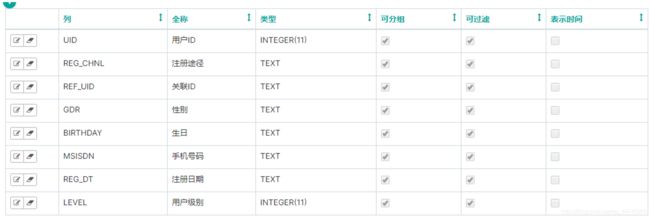
处理结果中的空值,例如处理生日如果为空,则显示无信息,“数据源”->“数据表”,找到列标签中对应的生日列,表达式处理空值,如下:
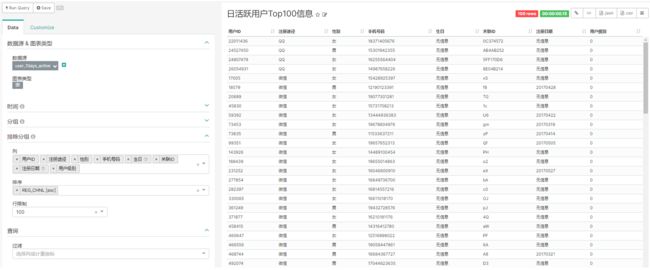
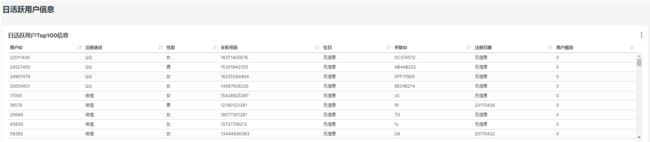
1.19 第四个业务:商户营收统计
1.19.1 需求
公司生产卡拉唱歌机器,这种机器会卖给商户,商户来进行经营收费,但是公司会对商品进行升级和歌曲库升级,这里商户进行经营后的收入是要分给机器生产的公司的,也就是公司和商户进行分成经营,共同盈利。
投资人:一台机器你可以来出资购买,你就是投资人。
代理人:机器给谁代理,谁就是代理人,一般都是一些大型商场和KTV等。
合伙人:合伙人就是与你共同出资进行投资购买机器的人。
这里商户营收统计,指的是统计投资人、代理人、合伙人各部分营收情况。
1.19.2 模型设计
统计商户营收需要分为以下四个方面的数据:
- TW_MAC_BASEINFO_D 机器基础信息日全量表
这个表中的数据是第二个业务统计的机器的详细信息,此表中的数据包含每天统计到的机器的歌库版本、系统版本、所处位置、门店名称、场景情况、投资人分层比例、代理人分层比例、合伙人分层比例、公司分层比例、代理人信息等数据。 - TW_MAC_LOC_D 机器位置信息日统计表
机器位置信息日统计表是由ODS层TO_YCAK_USR_LOC_D 用户位置记录日增量表统计得到,由每天用户上传的经纬度调用高德api获取全量机器对应的最新的位置信息。这里需要TW_MAC_LOC_D 机器位置信息日统计表的数据主要原因是获取每天机器所在的位置。以此表中机器位置信息为主,如果此表中机器的位置为空,则获取对应的TW_MAC_BASEINFO_D 表中的机器位置信息。 - TW_CNSM_BRIEF_D 消费退款订单流水日增量表
根据消费退款订单流水日增量表可以统计得到每天每个机器的订单、收入、退款情况,后期统计商户营收情况时,需要从此表中获取对应每台机器当天的订单、收入、退款情况。TW_CNSM_BRIEF_D 表中的数据由TO_YCAK_CNSM_D 机器消费订单明细增量表清洗得到。 - TW_USR_BASEINFO_D 活跃用户基础信息日增量表
活跃用户基础信息日增量表由业务三统计得到。在商户营收统计中可以由此表进一步聚合统计得到每天每台机器上的新增用户和登录的用户量。
经过以上四个方面的分析,在数仓中设计分层如下: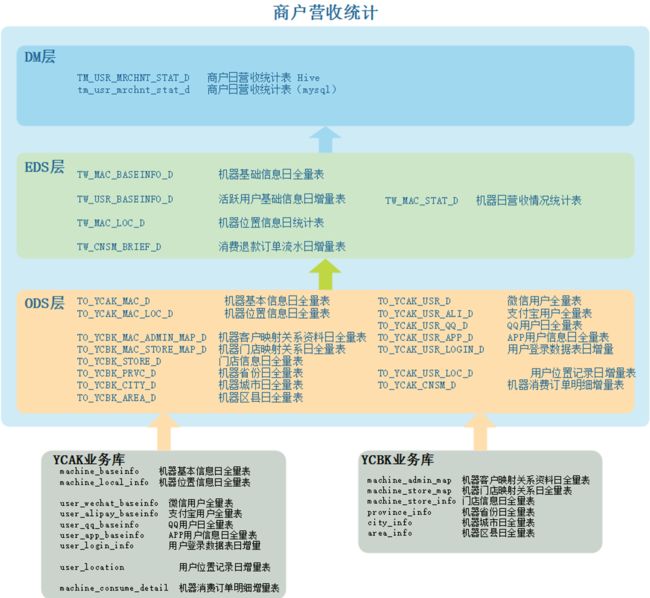
以上四个方面中,第一个和第四个模型设计参照对应的业务二和业务三模型设计即可。下面模型设计只设计第二个第三个方面。在Hive中ODS、EDS层中建表:
TO_YCAK_USR_LOC_D: 用户位置记录日增量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_LOC_D`(
`ID` int,
`UID` int,
`LAT` string,
`LNG` string,
`DATETIME` string,
`MID` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_LOC_D';
TW_MAC_LOC_D :机器位置信息日统计表
CREATE EXTERNAL TABLE `TW_MAC_LOC_D`(
`MID` int,
`X` string,
`Y` string,
`CNT` int,
`ADDER` string,
`PRVC` string,
`CTY` string,
`CTY_CD` string,
`DISTRICT` string,
`AD_CD` string,
`TOWN_SHIP` string,
`TOWN_CD` string,
`NB_NM` string,
`NB_TP` string,
`BD_NM` string,
`BD_TP` string,
`STREET` string,
`STREET_NB` string,
`STREET_LOC` string,
`STREET_DRCTION` string,
`STREET_DSTANCE` string,
`BUS_INFO` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_LOC_D';
TO_YCAK_CNSM_D :机器消费订单明细增量表
CREATE EXTERNAL TABLE `TO_YCAK_CNSM_D`(
`ID` int,
`MID` int,
`PRDCD_TYPE` int,
`PAY_TYPE` int,
`PKG_ID` int,
`PKG_NM` string,
`AMT` int,
`CNSM_ID` string,
`ORDR_ID` string,
`TRD_ID` string,
`ACT_TM` string,
`UID` int,
`NICK_NM` string,
`ACTV_ID` int,
`ACTV_NM` string,
`CPN_TYPE` int,
`CPN_TYPE_NM` string,
`PKG_PRC` int,
`PKG_DSCNT` int,
`ORDR_TYPE` int,
`BILL_DT` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_CNSM_D';
TW_CNSM_BRIEF_D : 消费退款订单流水日增量表
CREATE EXTERNAL TABLE `TW_CNSM_BRIEF_D`(
`ID` int,
`TRD_ID` string,
`UID` string,
`MID` int,
`PRDCD_TYPE` int,
`PAY_TYPE` int,
`ACT_TM` string,
`PKG_ID` int,
`COIN_PRC` int,
`COIN_CNT` int,
`UPDATE_TM` string,
`ORDR_ID` string,
`ACTV_NM` string,
`PKG_PRC` int,
`PKG_DSCNT` int,
`CPN_TYPE` int,
`ABN_TYP` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TW_CNSM_BRIEF_D';
TW_MAC_STAT_D :机器日营收情况统计表
CREATE EXTERNAL TABLE `TW_MAC_STAT_D`(
`MID` int,
`MAC_NM` string,
`PRDCT_TYPE` string,
`STORE_NM` int,
`BUS_MODE` string,
`PAY_SW` string,
`SCENCE_CATGY` string,
`SUB_SCENCE_CATGY` string,
`SCENE` string,
`SUB_SCENE` string,
`BRND` string,
`SUB_BRND` string,
`PRVC` string,
`CTY` string,
`AREA` string,
`AGE_ID` string,
`INV_RATE` string,
`AGE_RATE` string,
`COM_RATE` string,
`PAR_RATE` string,
`PKG_ID` string,
`PAY_TYPE` string,
`CNSM_USR_CNT` string,
`REF_USR_CNT` string,
`NEW_USR_CNT` string,
`REV_ORDR_CNT` string,
`REF_ORDR_CNT` string,
`TOT_REV` string,
`TOT_REF` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_STAT_D';
TM_USR_MRCHNT_STAT_D:商户日营收统计表
CREATE EXTERNAL TABLE `TM_USR_MRCHNT_STAT_D`(
`ADMIN_ID` string,
`PAY_TYPE` int,
`REV_ORDR_CNT` int,
`REF_ORDR_CNT` int,
`TOT_REV` double,
`TOT_REF` double,
`TOT_INV_REV` DECIMAL(10,2),
`TOT_AGE_REV` DECIMAL(10,2),
`TOT_COM_REV` DECIMAL(10,2),
`TOT_PAR_REV` DECIMAL(10,2)
)
PARTITIONED BY (DATA_DT string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TM_USR_MRCHNT_STAT_D';
以上模型设计中,各个ODS层与EDS层表之间的流转关系如下: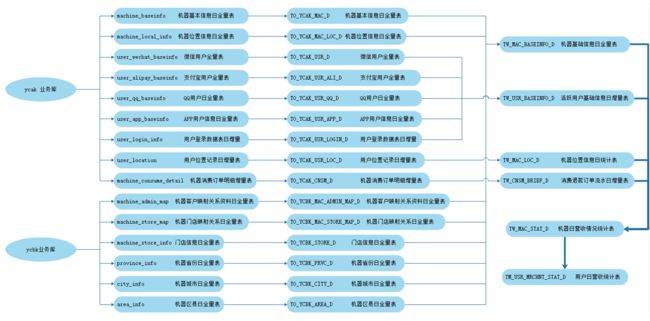
1.19.3 数据处理流程
-
将各个业务库的数据导入到Mysql中
-
在Hive中创建以上模型设计的表。
-
执行第二个业务-机器详细信息统计
执行第二个业务获取 TW_MAC_BASEINFO_D 机器基础信息日全量表信息。
- 执行第三个业务-日活跃用户统计
执行第三个业务获取 TW_USR_BASEINFO_D 活跃用户基础信息日增量表信息。
- 使用sqoop抽取mysql数据到ODS层
使用Sqoop每天增量抽取mysql “ycak”库下的user_location 用户位置记录日增量表数据到ODS层TO_YCAK_USR_LOC_D 表中,脚本“ods_mysqltohive_to_ycak_usr_loc_d.sh”内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====没有导入数据的日期,输入日期===="
exit
else
echo "====使用导入数据的日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
#查询hive ODS层表 TO_YCAK_USR_LOC_D 中目前存在的最大的ID
maxid=`hive -e "select max(id) from TO_YCAK_USR_LOC_D"`
echo "Hive ODS层表 TO_YCAK_USR_LOC_D 最大的ID是$maxid"
if [ x"$maxid" = xNULL ]; then
echo "maxid is NULL 重置为0"
maxid=0
fi
#sqoop 导入数据:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table user_location \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_USR_LOC_D/data_dt=${currentDate} \
--num-mappers 1 \
--fields-terminated-by '\t' \
--incremental append \
--check-column id \
--last-value $maxid
#更新Hive 分区
hive -e "alter table TO_YCAK_USR_LOC_D add partition(data_dt=${currentDate});"
使用Sqoop每天增量抽取MySQL“ycak”库下的“machine_consume_detail”机器消费订单明细表到ODS层的TO_YCAK_CNSM_D 表,脚本“ods_mysqltohive_to_ycak_cnsm_d.sh”内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====没有导入数据的日期,输入日期===="
exit
else
echo "====使用导入数据的日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
#查询hive ODS层表 TO_YCAK_CNSM_D 中目前存在的最大的ID
maxid=`hive -e "select max(id) from TO_YCAK_CNSM_D"`
echo "Hive ODS层表 TO_YCAK_CNSM_D 最大的ID是$maxid"
if [ x"$maxid" = xNULL ]; then
echo "maxid is NULL 重置为0"
maxid=0
fi
#sqoop 导入数据:
sqoop import \
--connect jdbc:mysql://mynode2:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root \
--password 123456 \
--table machine_consume_detail \
--target-dir /user/hive/warehouse/data/user/TO_YCAK_CNSM_D/data_dt=${currentDate} \
--num-mappers 1 \
--fields-terminated-by '\t' \
--incremental append \
--check-column id \
--last-value $maxid
#更新Hive 分区
hive -e "alter table TO_YCAK_CNSM_D add partition(data_dt=${currentDate});"
- 使用SparkSQL处理ODS层数据得到EDS层数据
使用SparkSQL代码清洗TO_YCAK_USR_LOC_D 用户位置记录日增量表数据到TW_MAC_LOC_D机器位置信息日统计表中,这里清洗主要是根据用户上报的经纬度信息通过高德api获取对应的机器位置,对应的清洗数据的Scala文件为“GenerateTwMacLocD.scala”,提交Spark任务的命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacLocD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
使用SparkSQL代码清洗“TO_YCAK_CNSM_D ”机器消费订单明细增量表到EDS层“TW_CNSM_BRIEF_D” 消费退款订单流水日增量表中,这里主要根据用户每天在机器上的消费行为统计每台机器的订单营收情况,对应的Scala代码为“GenerateTwCnsmBriefD.scala”。提交Spark任务的命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.eds.content.GenerateTwCnsmBriefD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
- 针对EDS层数据聚合得到 TW_MAC_STAT_D 机器日统计表数据
根据以下四个EDS层数据表聚合得到TW_MAC_STAT_D表中的数据,基于以下四张表的数据统计出机器位置、机器的营收情况、用户登录情况。
TW_MAC_BASEINFO_D 机器基础信息日全量表信息
TW_USR_BASEINFO_D 活跃用户基础信息日增量表信息
TW_MAC_LOC_D 机器位置信息日统计表
TW_CNSM_BRIEF_D 消费退款订单流水日增量表
以上处理数据对应的SparkSQL代码文件为“GenerateTwMacStatD.scala”,对应的提交 Spark 任务的命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacStatD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
- 针对
TW_MAC_STAT_D机器日统计表数据得到DM层数据
这里根据 TW_MAC_STAT_D 机器日统计表数据得到 TM_USR_MRCHNT_STAT_D 商户日统计表信息。对应的SparkSQL代码“GenerateTmUsrMrchntStatD.scala”,提交 Spark 任务的命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.dm.user.GenerateTmUsrMrchntStatD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
1.19.4 使用Azkaban配置任务流
1. 在Hive中创建使用到的模型表
所有需要创建的表如下:
第二个业务使用到的表:
TO_YCBK_AREA_D.sql
TO_YCBK_CITY_D.sql
TO_YCBK_MAC_ADMIN_MAP_D.sql
TO_YCBK_MAC_STORE_MAP_D.sql
TO_YCBK_PRVC_D.sql
TO_YCBK_STORE_D.sql
TO_YCAK_MAC_D.sql
TO_YCAK_MAC_LOC_D.sql
TW_MAC_BASEINFO_D.sql
第三个业务使用到的表:
TO_YCAK_USR_ALI_D.sql
TO_YCAK_USR_APP_D.sql
TO_YCAK_USR_D.sql
TO_YCAK_USR_LOGIN_D.sql
TO_YCAK_USR_QQ_D.sql
TW_USR_BASEINFO_D.sql
统计机器位置、消费退款订单、机器营收使用到的表:
TO_YCAK_CNSM_D.sql
TO_YCAK_USR_LOC_D.sql
TW_CNSM_BRIEF_D.sql
TW_MAC_LOC_D.sql
TW_MAC_STAT_D.sql
TM_USR_MRCHNT_STAT_D.sql
2. 将各个抽取mysql数据到ODS层的脚本准备到对应的节点上
这里将抽取数据的脚本放在mynode3节点的/root/test下,所有脚本如下:
处理第二个业务使用到的sqoop脚本:
ods_mysqltohive_to_ycak_mac_d.sh
ods_mysqltohive_to_ycak_mac_loc_d.sh
ods_mysqltohive_to_ycbk_mac_admin_map_d.sh
ods_mysqltohive_to_ycbk_mac_store_map_d.sh
ods_mysqltohive_to_ycbk_store_d.sh
ods_mysqltohive_to_ycbk_prvc_d.sh
ods_mysqltohive_to_ycbk_city_d.sh
ods_mysqltohive_to_ycbk_area_d.sh
处理第三个业务使用到的sqoop脚本:
ods_mysqltohive_to_ycak_usr_d.sh
ods_mysqltohive_to_ycak_usr_ali_d.sh
ods_mysqltohive_to_ycak_usr_qq_d.sh
ods_mysqltohive_to_ycak_usr_app_d.sh
ods_mysqltohive_to_ycak_usr_login_d.sh
处理机器位置信息、消费退款订单数据使用到的sqoop脚本:
ods_mysqltohive_to_ycak_usr_loc_d.sh
ods_mysqltohive_to_ycak_cnsm_d.sh
3. 打包代码上传到mynode4中
4. 编写azkaban任务
job1:统计机器详细信息(业务二)
job1.job
type=command
command=sh /software/musicproject/first.sh ${mydate}
first.sh:
#!/bin/bash
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_ycak_mac_d.sh
sh ods_mysqltohive_to_ycak_mac_loc_d.sh
sh ods_mysqltohive_to_ycbk_mac_admin_map_d.sh
sh ods_mysqltohive_to_ycbk_mac_store_map_d.sh
sh ods_mysqltohive_to_ycbk_store_d.sh
sh ods_mysqltohive_to_ycbk_prvc_d.sh
sh ods_mysqltohive_to_ycbk_city_d.sh
sh ods_mysqltohive_to_ycbk_area_d.sh
exit
aabbcc
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用azkaban 传入的时间===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
job2:统计日活跃用户信息(业务三)
job2.job
type=command
command=sh /software/musicproject/second.sh ${mydate}
second.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_ycak_usr_d.sh
sh ods_mysqltohive_to_ycak_usr_ali_d.sh
sh ods_mysqltohive_to_ycak_usr_qq_d.sh
sh ods_mysqltohive_to_ycak_usr_app_d.sh
sh ods_mysqltohive_to_ycak_usr_login_d.sh $currentDate
exit
aabbcc
echo "all done!"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.user.GenerateTwUsrBaseinfoD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
job3:统计机器位置、消费退款订单信息
job3.job
type=command
command=sh /software/musicproject/third.sh ${mydate}
third.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode3 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /root/test
sh ods_mysqltohive_to_ycak_usr_loc_d.sh $currentDate
sh ods_mysqltohive_to_ycak_cnsm_d.sh $currentDate
exit
aabbcc
echo "all done!"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacLocD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.user.GenerateTwCnsmBriefD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
job4:统计机器日营收情况统计表
job4.job
type=command
command=sh /software/musicproject/fourth.sh ${mydate}
dependencies=job1,job2,job3
fourth.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.eds.machine.GenerateTwMacStatD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
job5:统计DM层商户营收信息
job5.sh
type=command
command=sh /software/musicproject/fifth.sh ${mydate}
dependencies=job4
fifth.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.user.GenerateTmUsrMrchntStatD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
5. 将以上个任务打包提交到Azkaban执行
1.20 第五个业务:地区营收日报统计
1.20.1 需求
根据“机器日营收情况统计表”,每天统计省市总营收、总退款、总订单数、总退款订单数、总消费用户数、同退款用户数。
1.20.2 模型设计
统计每日省市的总营收、总退款、总订单、总退款订单、总消费用户及总退款用户可以根据业务四中统计的“TW_MAC_STAT_D”机器日营收情况统计表,按照省市字段聚合得到以上各个指标。
在Hive中建表:TM_MAC_REGION_STAT_D 地区营收日统计表:
CREATE EXTERNAL TABLE `TM_MAC_REGION_STAT_D`(
`PRVC` string,
`CTY` string,
`MAC_CNT` int,
`MAC_REV` DECIMAL(10,2),
`MAC_REF` DECIMAL(10,2),
`MAC_REV_ORDR_CNT` int,
`MAC_REF_ORDR_CNT` int,
`MAC_CNSM_USR_CNT` int,
`MAC_REF_USR_CNT` int
)
PARTITIONED BY (DATA_DT string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TM_MAC_REGION_STAT_D';
1.20.3 数据处理流程
使用SparkSQL对ODS层数据进行清洗,对应的处理数据的scala文件:GenerateTmMacRegionStatD.scala,将代码打包上传至mynode4节点/root/test下,提交到集群中运行即可,提交命令如下:
sh ./spark-submit
--master yarn-client
--class com.bjsxt.scala.musicproject.dm.machine.GenerateTmMacRegionStatD
/root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar 分析数据日期
1.20.4 使用Azkaban配置任务流
地区营收日报统计依赖了“TW_MAC_STAT_D”机器日营收情况统计表,所以此业务的任务流调度与业务四中的任务流调度一致,在生成“TW_MAC_STAT_D”表之后,定时执行如下脚本即可。
- 在Hive中创建对应的表 TM_MAC_REGION_STAT_D
- 基于业务四编写job6,进行Azkaban任务流调度
job6:统计DM层商户营收信息
job5.sh
type=command
command=sh /software/musicproject/sixth.sh ${mydate}
dependencies=job4
sixth.sh:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====azkaban中没有传入日期,使用今天日期===="
else
echo "====使用azkaban中导入的数据日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
ssh root@mynode4 > /software/musicproject/log/produce_clientlog.txt 2>&1 <<aabbcc
cd /software/spark-2.3.1/bin
sh ./spark-submit --master yarn-client --class com.bjsxt.scala.musicproject.dm.machine.GenerateTmMacRegionStatD /root/test/MusicProject-1.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
1.21 第六个业务:实时统计所有用户的pv,uv
1.21.1 需求
全网用户在实时操作机器的同时,可以使用数据采集接口将实时用户登录操作数据进行采集,针对这些数据可以实时统计每台机器实时的pv/uv,以及全网中所有用户的实时pv/uv,并需要实时保存至Redis或者关系型数据库mysql中。
1.21.2 数据采集接口及数据生产
数据采集接口原理是利用SpringBoot提供日志采集服务接口,在web系统中当用户操作某个需要监控的行为时,调用SpringBoot对应的数据服务接口,通过Log4j日志功能将对应的日志实时写入到指定的目录日志文件中,再通过Flume监控对应的日志目录,将日志实时采集到Kafka中,进而使用流式处理框架进行数据分析处理。
对应的数据采集接口项目为:LogCollector项目。
生产数据代码如下:
/**
* 读取 data目录下的用户登录机器日志,将登录数据生产到对应的日志采集接口中。
*/
public class ProdeceUserLoginLog {
public static void main(String[] args) throws InterruptedException {
String logType = "userLoginLog";
String url="http://mynode5:8686/collector/common/"+logType;
String result = null; //调用接口返回结果
HttpClient client = HttpClients.createDefault();
HttpPost post = new HttpPost(url);
//设置请求头
post.setHeader("Content-Type", "application/json");
//循环获取对应的日志数据,生产到对应的数据采集接口中
while(true){
InputStream in = null;
BufferedReader br = null;
try{
/**
* 获取日志文件数据路径:
* ProdeceUserLoginLog.class.getClassLoader().getResource().getPath 获取的是编译后classes文件夹的根路径
*/ in=ProdeceUserLoginLog.class.getClassLoader().getResourceAsStream("userLoginInfos");
br=new BufferedReader(new InputStreamReader(in));
String line=br.readLine();
while (line!=null){
//设置请求体
post.setEntity(new StringEntity("["+line+"]",Charset.forName("UTF-8")));
Thread.sleep(200);
//获取返回信息
HttpResponse response = client.execute(post);
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK){
result = EntityUtils.toString(response.getEntity(), "utf-8");
}
System.out.println("SpringBoot服务端返回结果:"+result);
//将每条数据发送到对应的日志采集接口中,获取下一条数据
line=br.readLine();
}
}catch (IOException e){
e.printStackTrace();
}finally {
try {
br.close();
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
1.21.3 数据处理流程
- 在Kafka中创建对应的日志接收topic
- 将日志采集接口打包部署到mynode5节点上
- 启动Flume日志采集脚本监控目录日志
Flume配置文件配置读取目录下的日志到Kafka中,配置文件内容如下:
#设置source名称
a.sources = r1
#设置channel的名称
a.channels = c1
#设置sink的名称
a.sinks = k1
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a.sources.r1.filegroups = f1 f2
#第一组监控的是test1文件夹中的什么文件:.log文件
a.sources.r1.filegroups.f1 = /software/logs/common/.*log
#第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件
a.sources.r1.filegroups.f2 = /software/logs/system/.*txt
# The channel can be defined as follows.
#设置source的channel名称
a.sources.r1.channels = c1
a.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a.channels.c1.transcationCapacity=100
# Each sink's type must be defined
#设置Kafka接收器
a.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a.sinks.k1.brokerList=mynode1:9092,mynode2:9092,mynode3:9092
#设置Kafka的Topic
a.sinks.k1.topic=mytopic
#设置序列化方式
a.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a.sinks.k1.channel = c1
将以上文件任意命名,例如:命名为a.properties,执行flume命令,监控目录数据:
flume-ng agent --name a -f /software/apache-flume-1.9.0-bin/conf/flume-conf-file-kafka.properties -Dflume.root.logger=INFO,console
以上配置项解释如下:
配置项解释:
--name:启动 agent 的名称,与配置文件中保持一致
-f:指定 agent 配置文件
-Dflume.root.logger=INFO,console 将日志打印到控制台
- 启动 SparkStreaming 读取 Kafka 中数据实时统计 PV , UV
对应的代码为 “RealTimePVUV.scala”。 - 启动生产数据代码 “ProdeceUserLoginLog”,调用日志采集接口生产数据
使用 SparkStreaming 读取 Kafka 中的数据进行统计实时 pv , uv , 对应的代码为:“RealTimePVUV.scala”。 - 在Redis中查看对应的结果
1.22 第七个业务:实时统计歌曲热榜
1.22.1 需求
实时采集用户在机器上点播歌曲的日志数据,统计每分钟歌曲点播热榜。将结果保存到关系型数据库 mysql 中。
1.22.2 数据采集接口及数据生产
数据采集接口原理是利用SpringBoot提供日志采集服务接口,在web系统中当用户操作某个需要监控的行为时,调用SpringBoot对应的数据服务接口,通过Log4j日志功能将对应的日志实时写入到指定的目录日志文件中,再通过Flume监控对应的日志目录,将日志实时采集到Kafka中,进而使用流式处理框架进行数据分析处理。
对应的数据采集接口项目为:LogCollector项目。
生产数据代码如下:
/**
* 读取 data目录下的用户登录机器点播歌曲日志,将点播歌曲数据生产到对应的日志采集接口中。
*/
public class ProdeceUserPlaySongInfoLog {
public static void main(String[] args) throws InterruptedException {
String logType = "userPlaySongLog";
String url="http://mynode5:8686/collector/common/"+logType;
String result = null; //调用接口返回结果
HttpClient client = HttpClients.createDefault();
HttpPost post = new HttpPost(url);
//设置请求头
post.setHeader("Content-Type", "application/json");
//循环获取对应的日志数据,生产到对应的数据采集接口中
while(true){
InputStream in = null;
BufferedReader br = null;
try{
/**
* 获取日志文件数据路径:
* ProdeceUserLoginLog.class.getClassLoader().getResource().getPath 获取的是编译后classes文件夹的根路径
*/ in=ProdeceUserPlaySongInfoLog.class.getClassLoader().getResourceAsStream("client_play_songinfo");
br=new BufferedReader(new InputStreamReader(in));
String line=br.readLine();
while (line!=null){
//设置请求体
post.setEntity(new StringEntity("["+line+"]",Charset.forName("UTF-8")));
Thread.sleep(200);
//获取返回信息
HttpResponse response = client.execute(post);
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK){
result = EntityUtils.toString(response.getEntity(), "utf-8");
}
System.out.println("SpringBoot服务端返回结果:"+result);
//将每条数据发送到对应的日志采集接口中,读取下一条数据
line=br.readLine();
}
}catch (IOException e){
e.printStackTrace();
}finally {
try {
br.close();
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
1.22.3 数据处理流程
- 在Kafka中创建对应的日志接收topic
- 将日志采集接口打包部署到mynode5节点上
- 启动Flume日志采集脚本监控目录日志
Flume配置文件配置读取目录下的日志到Kafka中,配置文件内容如下:
#设置source名称
a.sources = r1
#设置channel的名称
a.channels = c1
#设置sink的名称
a.sinks = k1
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a.sources.r1.filegroups = f1 f2
#第一组监控的是test1文件夹中的什么文件:.log文件
a.sources.r1.filegroups.f1 = /software/logs/common/.*log
#第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件
a.sources.r1.filegroups.f2 = /software/logs/system/.*txt
# The channel can be defined as follows.
#设置source的channel名称
a.sources.r1.channels = c1
a.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a.channels.c1.transcationCapacity=100
# Each sink's type must be defined
#设置Kafka接收器
a.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a.sinks.k1.brokerList=mynode1:9092,mynode2:9092,mynode3:9092
#设置Kafka的Topic
a.sinks.k1.topic=mytopic1
#设置序列化方式
a.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a.sinks.k1.channel = c1
将以上文件任意命名,例如:命名为a.properties,执行flume命令,监控目录数据:
flume-ng agent --name a -f /software/apache-flume-1.9.0-bin/conf/flume-conf-file-kafka.properties -Dflume.root.logger=INFO,console
以上配置项解释如下:
配置项解释:
--name:启动agent的名称,与配置文件中保持一致
-f:指定agent配置文件
-Dflume.root.logger=INFO,console 将日志打印到控制台
- 启动SparkStreaming读取Kafka中数据实时统计PV,UV
对应的代码为“RealTimePVUV.scala”。 - 启动生产数据代码“ProdeceUserLoginLog”,调用日志采集接口生产数据
使用SparkStreaming读取Kafka中的数据进行统计实时pv,uv,对应的代码为:“RealTimePVUV.scala”。 - 在Redis中查看对应的结果