sharing-sphere的词法解析器。跟着芋艿撸sharding-sphere的源代码。
首先了解一下Token和TokenType,知道所有数据库都有哪些词分类。
TokenType的继承关系如下:
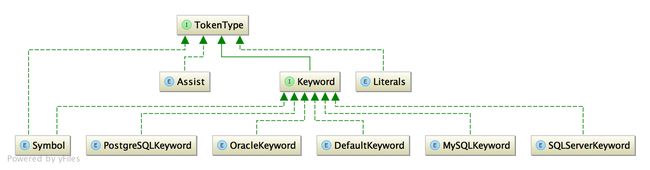
为了补充具体类型下面的一些变量,我用脑图完善了一下上图,看起来更直观一些。

可以看到, TokenType(分词类型),分为四种,分别如下:
- assist 词法分析辅助结束符
词法分析结束,有两种结果,要么成功,要么解析失败。- END,解析成功。
- ERROR 词法解析失败。
- Literals 词法字面量
- IDENTIFIER :词法关键词
- VARIABLE :变量
- CHARS :字符串
- HEX :十六进制
- INT :整数
- FLOAT :浮点数
- Symbol 词法符号标记
- 具体看上图,声明了很多运算符(+-*/),括号信息({}),符号标志(.,)。
- keyword 关键字
- PostgreSqlKeyword postgreSql数据库的关键字
- OracleKeyword oracle数据库的关键字
- MysqlKeyword mysql的关键字
- DefaultKeyword 默认的关键字
知道了词大概分为四类,一个sql语句会被分成多个词,每个词该如何表示?在sharding-sphere中,词的定义是这样的。
public final class Token {
//词的类型
private final TokenType type;
//词的名称
private final String literals;
//词结束的位置
private final int endPosition;
}
举个例子:
select * from table_a
这条语句就会被分为四个词,词的literals分别为select,*, from, table_a。
了解了词,再来看看分词器Tokenizer如何做分词。
public final class Tokenizer {
//输入
private final String input;
//字典
private final Dictionary dictionary;
//偏移量
private final int offset;
}
在Tokenizer分词器中,有三个属性,第一个输入的sql(input),第二个字典(dictionary),里面保存了所有的关键字,第三个偏移量(offset),用于获取分词的长度。分词器具体的api如下:
| 方法名 | 说明 |
|---|---|
| int skipWhitespace() | 跳过所有的空格 返回最后的偏移量 |
| int skipComment() | 跳过注释,并返回最终的偏移量 |
| Token scanVariable() | 获取变量,返回分词Token |
| Token scanIdentifier() | 返回关键词分词 |
| Token scanHexDecimal() | 扫描16进制返回分词 |
| Token scanNumber() | 返回数字分词 |
| Token scanChars() | 返回字符串分词 |
| Token scanSymbol() | 返回词法符号标记分词 |
能看到,所有的分词都是按照TokenType返回不同的分词,不同的分词类型,由不同的分词方法去处理并返回。
再看一下字典,字典是什么,哪里来的?
public final class Dictionary {
private final Map tokens = new HashMap<>(1024);
public Dictionary(final Keyword... dialectKeywords) {
fill(dialectKeywords);
}
private void fill(final Keyword... dialectKeywords) {
for (DefaultKeyword each : DefaultKeyword.values()) {
tokens.put(each.name(), each);
}
for (Keyword each : dialectKeywords) {
tokens.put(each.toString(), each);
}
}
}
能够看到,字典实质是维护了一个map,里面保存了所有的关键字,所有的关键字都是获取Keyword的关键字。也就是说,所有Keyword的值都会保存在字典(Dictionary)里。
到这里,最基本的分词概念就应该很清楚了,一条sql,会被分为多个分词(Token),具体如何分词,是由分词器(Tokenizer)做分词的。
分词器什么时候被使用来做分词?
在sharing-sphere中是用词法分析器(Lexer)去做分词。
public class Lexer {
//输入的sql
@Getter
private final String input;
//字典
private final Dictionary dictionary;
//偏移量
private int offset;
//当前分词
@Getter
private Token currentToken;
}
在输入sql,具体需要分词的时候,实质是调用Lexer的nextToken做分词的。
public final void nextToken() {
//跳过忽略的分词
skipIgnoredToken();
//如果是变量
if (isVariableBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanVariable();
//N\
} else if (isNCharBegin()) {
currentToken = new Tokenizer(input, dictionary, ++offset).scanChars();
//如果是字母或`或者-或者$
} else if (isIdentifierBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier();
//ox开头的
} else if (isHexDecimalBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal();
//数字0~9开头
//.开头第二位是数字且前一位不是字母,`, $,或者_。
//-开头,第二位是.或者0~9
} else if (isNumberBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanNumber();
//+-*/{}[]等其他词法符号标记
} else if (isSymbolBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanSymbol();
//以",或者'开头,如果是字符串的话
} else if (isCharsBegin()) {
currentToken = new Tokenizer(input, dictionary, offset).scanChars();
//如果是最后
} else if (isEnd()) {
currentToken = new Token(Assist.END, "", offset);
} else {
//出错
throw new SQLParsingException(this, Assist.ERROR);
}
//重置偏移量,便宜量为上一个分词的结束位置。
offset = currentToken.getEndPosition();
}
我们还是以上面的sql为例,看一下分词器分词之后会有几个词,都是什么信息。
select * from table_a
@Test
public void lexerTest() {
String sql="select * from table1";
Lexer lexer = new Lexer(sql, dictionary);
lexer.nextToken();
Token currentToken=lexer.getCurrentToken();
while(currentToken.getType()!=Assist.END&¤tToken.getType()!=Assist.ERROR){
System.out.println(currentToken);
lexer.nextToken();
currentToken=lexer.getCurrentToken();
}
}
运行结果:
Token(type=SELECT, literals=select, endPosition=6)
Token(type=STAR, literals=*, endPosition=8)
Token(type=FROM, literals=from, endPosition=13)
Token(type=IDENTIFIER, literals=table1, endPosition=20)
我们能看到,这条sql被分词分为四个,entPosition为在sql中的结束坐标位置。
换条复杂的sql试试。
@Test
public void lexerTest() {
String sql="select a='张三', b=\"李四\", t.name,t.age from table1 t left join table2 t2 on t1.name=t2.name where t2.age>5 --左外关联";
Lexer lexer = new Lexer(sql, dictionary);
lexer.nextToken();
Token currentToken=lexer.getCurrentToken();
while(currentToken.getType()!=Assist.END&¤tToken.getType()!=Assist.ERROR){
System.out.println(currentToken);
lexer.nextToken();
currentToken=lexer.getCurrentToken();
}
}
分词结果如下:
Token(type=SELECT, literals=select, endPosition=6)
Token(type=IDENTIFIER, literals=a, endPosition=8)
Token(type=EQ, literals==, endPosition=9)
Token(type=CHARS, literals=张三, endPosition=13)
Token(type=COMMA, literals=,, endPosition=14)
Token(type=IDENTIFIER, literals=b, endPosition=16)
Token(type=EQ, literals==, endPosition=17)
Token(type=CHARS, literals=李四, endPosition=21)
Token(type=COMMA, literals=,, endPosition=22)
Token(type=IDENTIFIER, literals=t, endPosition=24)
Token(type=DOT, literals=., endPosition=25)
Token(type=IDENTIFIER, literals=name, endPosition=29)
Token(type=COMMA, literals=,, endPosition=30)
Token(type=IDENTIFIER, literals=t, endPosition=31)
Token(type=DOT, literals=., endPosition=32)
Token(type=IDENTIFIER, literals=age, endPosition=35)
Token(type=FROM, literals=from, endPosition=40)
Token(type=IDENTIFIER, literals=table1, endPosition=47)
Token(type=IDENTIFIER, literals=t, endPosition=49)
Token(type=LEFT, literals=left, endPosition=54)
Token(type=JOIN, literals=join, endPosition=59)
Token(type=IDENTIFIER, literals=table2, endPosition=66)
Token(type=IDENTIFIER, literals=t2, endPosition=69)
Token(type=ON, literals=on, endPosition=72)
Token(type=IDENTIFIER, literals=t1, endPosition=75)
Token(type=DOT, literals=., endPosition=76)
Token(type=IDENTIFIER, literals=name, endPosition=80)
Token(type=EQ, literals==, endPosition=81)
Token(type=IDENTIFIER, literals=t2, endPosition=83)
Token(type=DOT, literals=., endPosition=84)
Token(type=IDENTIFIER, literals=name, endPosition=88)
Token(type=WHERE, literals=where, endPosition=94)
Token(type=IDENTIFIER, literals=t2, endPosition=97)
Token(type=DOT, literals=., endPosition=98)
Token(type=IDENTIFIER, literals=age, endPosition=101)
Token(type=GT, literals=>, endPosition=102)
Token(type=INT, literals=5, endPosition=103)
可以看到,注释部分内容已经被过滤掉,整条sql被分成多个词。
词法解析器分析完了,但程序在执行过程中,不同的特性,每中数据库都应该有自己的引擎,而在sharding-sphere中,也是如此,目前实现了MySQL,postgreSQL,Oracle,SQLServer,每种数据库的关键字也不大一样,所以每种数据库也应该有自己的关键字字典,如下:
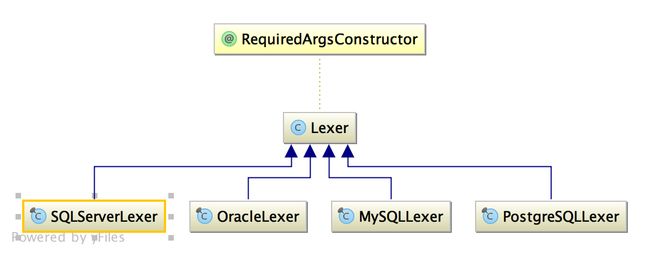
具体如下:
public final class MySQLLexer extends Lexer {
private static Dictionary dictionary = new Dictionary(MySQLKeyword.values());
public MySQLLexer(final String input) {
super(input, dictionary);
}
@Override
protected boolean isHintBegin() {
return '/' == getCurrentChar(0) && '*' == getCurrentChar(1) && '!' == getCurrentChar(2);
}
@Override
protected boolean isCommentBegin() {
return '#' == getCurrentChar(0) || super.isCommentBegin();
}
@Override
protected boolean isVariableBegin() {
return '@' == getCurrentChar(0);
}
}
public final class OracleLexer extends Lexer {
private static Dictionary dictionary = new Dictionary(OracleKeyword.values());
public OracleLexer(final String input) {
super(input, dictionary);
}
@Override
protected boolean isHintBegin() {
return '/' == getCurrentChar(0) && '*' == getCurrentChar(1) && '+' == getCurrentChar(2);
}
}
分词器要使用,肯定需要有一个对象去使用,这里是使用分词器引擎LexerEngine,持有分词器lexer去做词法分析。
@RequiredArgsConstructor
public final class LexerEngine {
private final Lexer lexer;
}
LexeEngine的api如下
| 方法名 | 说明 |
|---|---|
| String getInput() | 获取输入的sql |
| nextToken() | 调用分词器的nextToken |
| Token getCurrentToken() | 返回分词器的当前分词 |
| String skipParentheses(final SQLStatement sqlStatement) | 跳过所有括号及括号里的所有信息并返回。 |
| accept(final TokenType tokenType) | 是否接受该分词类型 |
| equalAny(final TokenType... tokenTypes) | 当前分词是不是参数中的一种 |
| boolean skipIfEqual(final TokenType... tokenTypes) | 如果分词类型相同,则跳过这次的分词,获取下一个分词 |
| skipAll(final TokenType... tokenTypes) | 跳过所有参数中的分词类型,获取下一个分词。 |
| skipUntil(final TokenType... tokenTypes) | 跳过其他分词,直到碰到参数中的分词。 |
| unsupportedIfEqual(final TokenType... tokenTypes) | 不支持参数中的分词类型 |
| unsupportedIfNotSkip(final TokenType... tokenTypes) | 如果没有跳过一下参数中的分词,则报错 |
| DatabaseType getDatabaseType() | 获取当前的数据库类型 |
由于分词器(Lexer)已经区分数据库类型了,所以分词引擎(LexerEngine)就没有区分类型。当需要使用分词器引擎的时候,只需要调用工厂new一个出来,具体如下:
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class LexerEngineFactory {
public static LexerEngine newInstance(final DatabaseType dbType, final String sql) {
switch (dbType) {
case H2:
case MySQL:
return new LexerEngine(new MySQLLexer(sql));
case Oracle:
return new LexerEngine(new OracleLexer(sql));
case SQLServer:
return new LexerEngine(new SQLServerLexer(sql));
case PostgreSQL:
return new LexerEngine(new PostgreSQLLexer(sql));
default:
throw new UnsupportedOperationException(String.format("Cannot support database [%s].", dbType));
}
}
}
分词器到这里就分析完了。后面再看别的。
感谢芋艿,芋艿的博客给了很大帮助。