* HBase框架基础(二)
上一节我们了解了HBase的架构原理和模块组成,这一节我们先来聊一聊HBase的读写数据的过程。
* HBase的读写流程及3个机制
HBase的读数据流程:
1、HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。
2、接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。
3、Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
4、最后HRegionServer把查询到的数据响应给Client。
HBase写数据流程:
1、Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。
2、确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
3、Client向该HRegionServer服务器发起写入数据请求,然后HRegionServer收到请求并响应。
4、CLient先把数据写入到HLog,以防止数据丢失。
5、然后将数据写入到Memstore
6、如果HLog和Memstore均写入成功,则这条数据写入成功
7、如果Memstore达到阈(yu)值(注意,不存在“阀值”这么一说,属于长期的误用,在此提醒),会把Memstore中的数据flush到Storefile中。
8、当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。
9、当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
重申强调上述涉及到的3个机制:
** Flush机制:
当MemStore达到阈值,将Memstore中的数据Flush进Storefile
涉及属性:
hbase.hregion.memstore.flush.size:134217728
即:128M就是Memstore的默认阈值
hbase.regionserver.global.memstore.upperLimit:0.4
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于hbase.regionserver.global.memstore.lowerLimit。
** Compact机制:
把小的Memstore文件合并成大的Storefile文件。
** Split机制
当Region达到阈值,会把过大的Region一分为二。

* HBaseAPI的使用
接下来我们来尝试一下使用Java来操作一下HBase,首先我们需要配置一下开发环境。
** 下载maven离线依赖包
maven本次用到的Hbase+Hadoop的Maven离线依赖包传送门:
链接:http://pan.baidu.com/s/1bpthCcf 密码:wjq
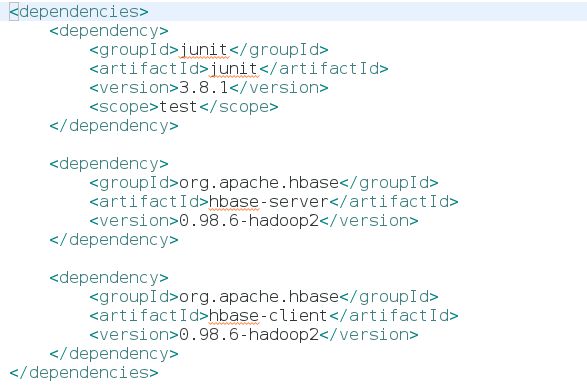
** 新建Eclipse的Maven Project,配置pom.xml的dependency如图:
** 接下来我们来表演一下HBase的相关操作
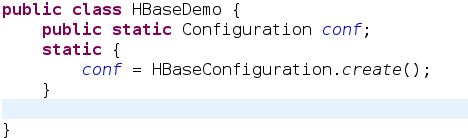
首先,声明静态配置,用以初始化整个Hadoop以及HBase的配置,如图:
检查表是否存在:
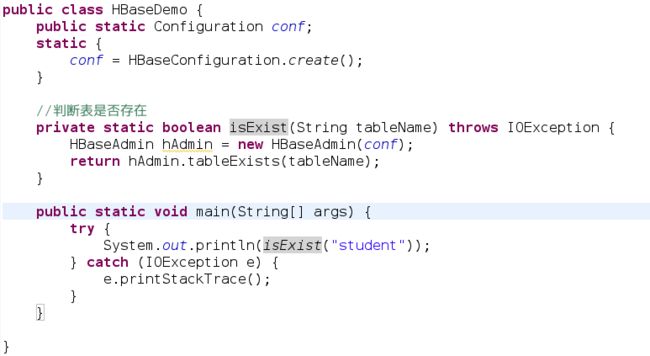
注:这就是一个最简单的示例,接下来的代码展示,只展示最核心的函数块,不再全部截图,文后结束给大家Demo源码传送门
创建数据库表:
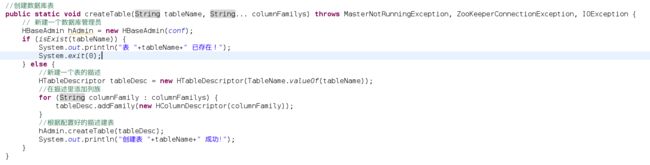
此处我在Java的主函数中执行了该创建表的方法,表明为staff,并有两个列族,分别为info和other_info,成功后,来到CRT验证一下,如图:

删除数据库表:
完成后请自行测试,如何测试已经在上一步告诉你了

增:
向我们之前创建好的student表中插入一条数据
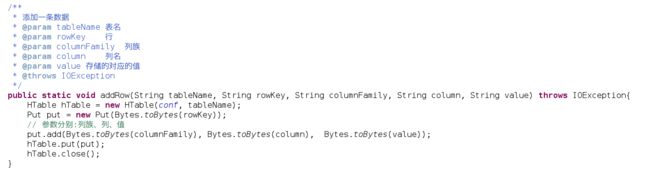
然后执行:
结果:

删:
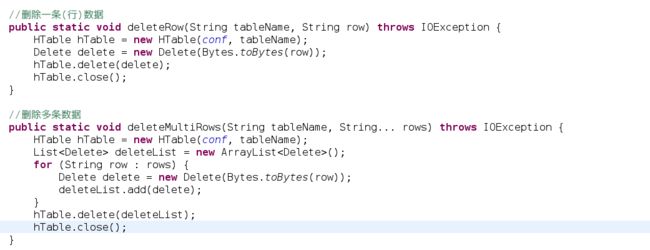
改:
与增的案例意思是一样的,只需要按照指定的rowKey和列族:列覆盖原来的值就可以了
查:
查询表中的所有数据和信息,所有的都会查了,单行信息就很简单了~
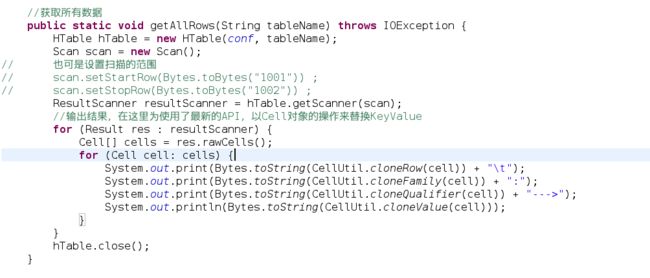
测试结果:
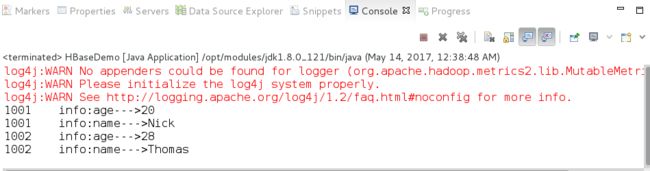
源码传送门:
链接:http://pan.baidu.com/s/1o8x5q8i 密码:2kf1
* HBase的MapReduce调用
1、首先需要查看配置HBase的Mapreduce所依赖的Jar包,使用命令:
$ bin/hbase mapredcp,然后出现如下依赖,这些依赖我们一会需要export 到classpath中:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-common-0.98.6-cdh5.3.6.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/protobuf-java-2.5.0.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-client-0.98.6-cdh5.3.6.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-hadoop-compat-0.98.6-cdh5.3.6.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hbase-protocol-0.98.6-cdh5.3.6.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/high-scale-lib-1.1.1.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/zookeeper-3.4.5-cdh5.3.6.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/guava-12.0.1.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/htrace-core-2.04.jar:
/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/netty-3.6.6.Final.jar
2、执行环境变量的临时导入
$ export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
$ export HADOOP_HOME=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
注意:两边有反引号,表示将mapredcp命令的执行结果赋值给classpath。
3、运行官方自带的MapReduce相关的jar
案例一:统计student表有多少行数据
直接执行代码:
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar rowcounter student
案例二:使用MapReduce任务将数据导入到HBase
Step1、创建测试文件
$ vi fruit.txt,文件如图:

完事之后,我们要上传这个fruit.txt到HDFS系统中
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put ./fruit.txt /input/
Step2、创建HBase表
$ bin/hbase shell
hbase(main):001:0> create 'fruit','info'
Step3、执行MapReduce到HBase的fruit表中
在这一步开始之前,我们先拓展一点知识:
* tsv格式的文件:字段之间以制表符\t分割
* csv格式的文件:字段之间以逗号,分割(后面的数据分析我们会经常涉及到这样的格式)
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar \
lib/hbase-server-0.98.6-hadoop2.jar importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color \
fruit hdfs://mycluster/input
成功之后,我们来检查一下HBase中的数据,如图:

惊不惊喜?意不意外?
* 总结
本节主要是了解一些HBase的一些基本Java API,以及如何使用官方的jar来执行一些常用的MapReduce操作,比如向HBase中导入数据。注意:一定要仔细观察每一条语句执行的参数和意义,不要直接复制。(截图展示代码的目的也正是如此)
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:HBase框架基础(三)