7 三种方式爬取斗鱼主播照片
gitbook链接:用python带你进入AI中的深度学习技术领域https://www.gitbook.com/book/scrappyzhang/python_to_deeplearn/details
github链接:https://github.com/ScrappyZhang/python_web_Crawler_DA_ML_DL
在第4章到第6章,我们分别学习了解了单线程、多线程、多进程和协程,本章将通过一个抓取斗鱼美女主播照片的案例来实际感受不同模式的实际区别。本章结合第7章的HTTP协议,以python3的urllib.request(访问网页模块) 和 re(正则表达式)两个模块为辅助来进行不同版本的抓取程序编写。
7.1 单线程抓取
首先,我们可以先通过浏览器查看到斗鱼美女主播首页的相关信息:[https://www.douyu.com/directory/game/yz]。
通过查看网页源代码,我们会发现每一张主播图片都对应着一个url。因此我们可以想到,通过打开首页网页源代码中所有的该url就可以将首页的所有美女主播的图片获取到。(https://www.douyu.com/directory/game/yz。通过查看网页源代码,我们会发现每一张主播图片都对应着一个url。因此我们可以想到,通过打开首页网页源代码中所有的该url就可以将首页的所有美女主播的图片获取到。)

如何实现全部下载呢?单线程就是一个下载完再下载另一个,直至所有的都下载。本节通过将首页网页源代码中所有的url存入一个列表,然后再通过for循环一个个去下载美女主播图片。主要的代码思路如下。

时间大约统计
import time
start = time.time() # 程序大约的开始时间
end = time.time() # 程序大约的结束时间
print('耗时:', end - start)
打开并获取首页网页内容
home = """https://www.douyu.com/directory/game/yz?page=1&isAjax=1""" # 首页地址
# 请求的时候需要带上头部 可以防止初步的反爬措施
headers = {
"Host":"www.douyu.com",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/62.0.3202.94 Safari/537.36"
}
# 构造好请求对象 将请求提交到服务器 获取的响应就是到首页的html代码
request = urllib.request.Request(url=home, headers=headers)
# urlopen函数可以直接传入url网址 也可以指定好一个请求对象
response = urllib.request.urlopen(request)
# 将收到的响应对象中数据的bytes数据读出出来 并且解码
html_data = response.read().decode()
正则解析美女主播首页的内容
img_list = re.findall(r"https://.*?\.(?:jpg)", html_data)
单线程下载照片
for img_url in img_list:
down_img(img_url)
下载照片函数
max_retry_count = 3
def down_img(url):
"""
下载图片
https://rpic.douyucdn.cn/live-cover/appCovers/2017/10/24/12017.jpg
"""
for i in range(max_retry_count):
try:
response = urllib.request.urlopen(url)
# bytes
data = response.read()
# 从url中得到文件名
file_name = url[url.rfind('/')+1:]
# 打开文件用以写入
with open("img/"+ file_name, "wb") as file:
file.write(data)
except Exception as e:
print("出错 %s 正在重试" % e)
else:
break
完整代码
import urllib.request
import re
import time
max_retry_count = 3
def down_img(url):
for i in range(max_retry_count):
try:
response = urllib.request.urlopen(url)
data = response.read()
file_name = url[url.rfind('/')+1:]
with open("img/"+ file_name, "wb") as file:
file.write(data)
except Exception as e:
print("出错 %s 正在重试" % e)
else:
break
if __name__ == '__main__':
start = time.time() # 程序大约的开始时间
home = """https://www.douyu.com/directory/game/yz?page=1&isAjax=1""" # 首页地址
# 请求的时候需要带上头部 可以防止初步的反爬措施
headers = {
"Host":"www.douyu.com",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/62.0.3202.94 Safari/537.36"
}
request = urllib.request.Request(url=home, headers=headers)
response = urllib.request.urlopen(request)
html_data = response.read().decode()
img_list = re.findall(r"https://.*?\.(?:jpg)", html_data)
# 下载美女主播图片
for img_url in img_list:
down_img(img_url)
end = time.time()
print('耗时:', end - start)
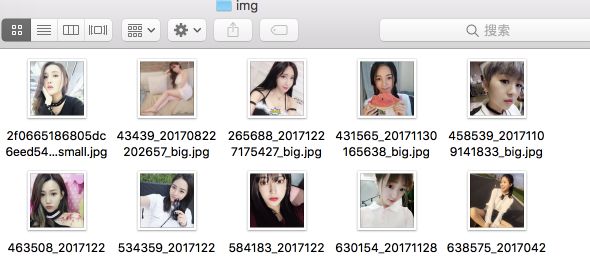
实现结果
我们成功下载到114张照片(不同场景可能略有差异),并将所有的照片存入./img/文件夹,耗时56.19秒。
小结

7.2 多线程抓取
根据之前我们第4章所学习的知识,我们只需将for循环抓取替代为多线程创建抓取即可。替换代码(完整代码见net07_douyu_threading.py)如下:
# 下载美女主播图片
for img_url in img_list:
td = threading.Thread(target=down_img, args=(img_url,))
td.start()
# 阻塞程序直到所有线程运行完毕
while True:
length = len(threading.enumerate())
if length == 1:
break
我们共花费了22.84秒。
7.3 多进程抓取
根据之前我们第5章所学习的进程知识,我们只需将for循环抓取替代为多进程创建抓取即可。替换代码(完整代码见net07_douyu_multiprocessing.py)如下:
# 下载美女主播图片
for img_url in img_list:
p = multiprocessing.Process(target=down_img, args=(img_url,))
p.start()
# 阻塞程序直到所有进程运行完毕
while True:
length = len(multiprocessing.active_children()) # 存活的子进程的数量
if length == 0:
break
我们共花费了7.23秒。
7.4 协程抓取
根据之前我们第6章所学习的进程知识,我们只需将for循环抓取替代为协程创建抓取即可。替换代码(完整代码见net07_douyu_gevent.py)如下:
# 下载美女主播图片
gevent_list = []
for img_url in img_list:
g1 = gevent.spawn(down_img, img_url)
gevent_list.append(g1)
gevent.joinall(gevent_list) # 待所有协程执行完毕再向下执行
同样是单线程的协程,我们共花费了5.46秒。