迁移学习之快速搭建【卷积神经网络】
前言
卷积神经网络 概念认识:一篇文章“简单”认识《卷积神经网络》(更新版)
卷积神经网络 简单模型搭建:手把手搭建一个【卷积神经网络】
本篇文章带大家熟悉“迁移学习”的开发流程,介绍如何使用预先训练好的神经网络,结合实际的功能需求,来实现一些图像任务;比如:实现对猫和狗的图像进行分类。
预先训练好的神经网络,通常称为“预训练模型”,它在大型数据集上进行训练,取得业界认可的效果,开源给广大开发者使用的模型。本文主要介绍在keras中的关于图像任务的开源模型。
比如:在ImageNet数据集上预训练过的用于图像分类的模型 VGG16、VGG19、ResNetV2、InceptionV3、MobileNetV2、DenseNet、NASNet等等模型。

top-1 accuracy和 top-5 accuracy 是指模型在 ImageNet 验证数据集上的性能;
Depth 是指网络的拓扑深度;这包括激活层、批次规范化层等。
这是官网的链接keras预训练模型,大家可以去探索一下
迁移学习方式
我们可以直接使用预训练模型,毕竟效果挺好的;提供输入信息,经过模型处理,直接输出结果。
也可以使用预训练模型的一部分网络结构,使用其特定的功能(比如:特征提取),然后根据给定任务自定义搭建一部分网络结构(比如:实现分类),最后组合起来就形成一个完整的神经网络啦。本文主要将这种方式。
预训练模型的优点
1)模型在足够大的数据集中训练,通常是业界的通用模型(比如:图像视觉的模型);
2)预训练模型的权重是已知了,往往不用再花时间去训练;只需训练我们自定义的网络结构即可。
思路流程
- 导入数据集
- 探索集数据,并进行数据预处理
- 构建模型(搭建神经网络结构、编译模型)预训练模型 + 自定义模型
- 训练模型(把数据输入模型、评估准确性、作出预测、验证预测)
- 使用训练好的模型
一、导入数据集
使用谷歌开源的数据集,包含几千张猫和狗图像;然后把数据集分为训练集、验证集、测试集。
# 该数据集包含几千张猫和狗图像;
# 下载并提取包含图像的 zip 文件,然后创建一个tf.data.Data.Dataset,
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# 用于使用tf.keras.preprocessing.image_dataset_from_directory 进行拆分训练集和验证集。
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)由于原始数据集不包含测试集,因此将创建一个测试集。在验证集中将其中 20% 移动到测试集。
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
二、探索集数据,并进行数据预处理
将训练集的前 9 张图片和标签打印出来
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
数据集预处理——数据增强
由于该数据集只有几千张猫和狗图像,属于小数据集,在模型训练时容易产生过拟合的;于是使用数据增强,对训练图像进行随机旋转和水平翻转,使得训练样本多样性。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])RandomFlip("horizontal") 对图片进行 随机水平反转
RandomRotation(0.2) 对图片进行 随机旋转
查看一下效果:
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')
数据集预处理——缩放像素值
将图片像素值从[0,255]重新缩放到[-1,1]
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)为什么是除以127.5,再整体偏移-1呢?由于图片的像素范围是0~255,我们把它变成-1~1的范围,于是每张图像(训练集、测试集)都除以127.5,这时得到的范围是0~2,再整体偏移-1,就得到-1~1的范围啦。
三、构建模型
常见卷积神经网络(CNN),主要由几个 卷积层Conv2D 和 池化层MaxPooling2D 层组成。卷积层与池化层的叠加实现对输入数据的特征提取,最后连接全连接层实现分类。
- 特征提取——卷积层与池化层
- 实现分类——全连接层
这里用到“迁移学习”的思想,使用“预训练模型”作为特征提取;实现分类的全连接层有我们自己搭建。
3.1)特征提取——MobileNet V2
特征提取使用谷歌开发的MobileNet V2 模型,它是再ImageNet 数据集上预先训练的,该数据集由 140 万张图像和 1000 个类组成。
我们只使用MobileNet V2 模型的卷积层和池化层,生成base_model;不用它的全连接层,毕竟我们的输出只是识别猫和狗,不用识别1000多个类嘛。
# 使用MobileNet V2 的特征提取的网络结构、权重
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')include_top=False,是指不用MobileNet V2模型的全连接层。
对图像进行特征提取,生成feature_batch
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)冻结base_model,对预先训练好的模型,不再重新进行训练了
base_model.trainable = False查看一下base_model的网络结构 base_model.summary( )

base_model的模型结构实在太大了,这里显示了一小部分。
3.2)实现分类
使用GlobalAveragePooling2D将每张图像转换为单个 1280 元素矢量
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)由于进行猫和狗分类,对每个图像进行单个预测,正数预测类 1,负数预测类 0;于是全连接层用1个神经元就可以了。
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
3.3)搭建整体网络结构
通过使用Keras 功能 API将数据增强、重新缩放、base_model、feature_batch层、分类层prediction_batch 串联在一起来,构建模型。
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
3.4)编译模型
由于有两个类(猫和狗),使用二进制交叉熵损失;
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
查看一下整体的网络结构 tf.keras.utils.plot_model(model)

或者用这种方式看看 model.summary( )

四、训练模型
这里我们输入准备好的训练集数据(包括图像、对应的标签),测试集的数据(包括图像、对应的标签),模型一共训练10次。
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)下图是训练过程的截图:

通常loss越小越好,对了解释下什么是loss;简单来说是 模型预测值 和 真实值 的相差的值,反映模型预测的结果和真实值的相差程度;
通常准确度accuracy 越高,模型效果越好。从上图可以看到验证集的准确性高达95%。
评估模型
使用预训练模型MobileNet V2 作为图像特征提取器时,结合我们自定义分类层,看看训练集和验证集的准确性/损失的学习曲线。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()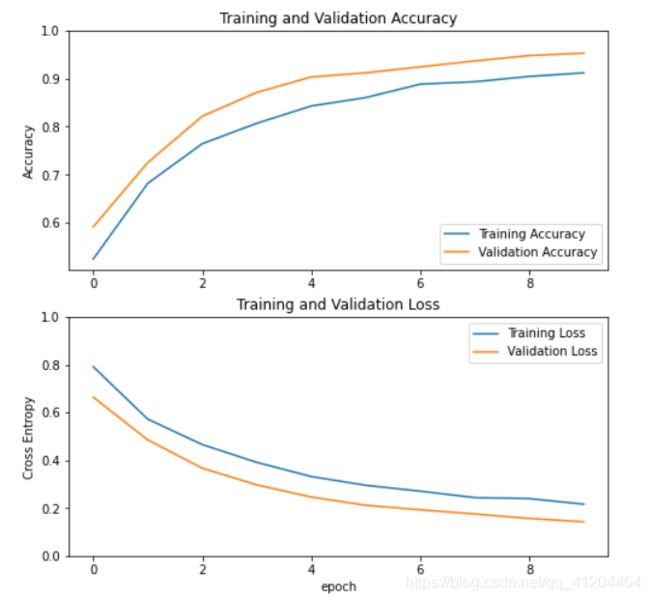
五、使用模型
通常使用 model.predict( ) 函数进行预测。
完整代码
'''
Tensorflow2.x Python3
'''
# 导入库
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# 该数据集包含几千张猫和狗图像;
# 下载并提取包含图像的 zip 文件,然后创建一个tf.data.Data.Dataset,
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# 用于使用tf.keras.preprocessing.image_dataset_from_directory 进行拆分训练集和验证集。
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
# 由于原始数据集不包含测试集,因此将创建一个测试集。在验证集中将其中 20% 移动到测试集。
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
# 将训练集的前 9 张图片和标签打印出来
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
# 数据集预处理——数据增强,对训练图像进行随机旋转和水平翻转,使得训练样本多样性。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
# 数据集预处理——缩放像素值,将图片像素值从[0,255]重新缩放到[-1,1].
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)
# 使用MobileNet V2 模型的卷积层和池化层,生成base_model;不用它的全连接层
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
# 对图像进行特征提取,生成feature_batch
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
# 冻结base_model,对预先训练好的模型,不再重新进行训练了
base_model.trainable = False
# 查看一下base_model的网络结构
base_model.summary()
# 实现分类
# 使用GlobalAveragePooling2D将每张图像转换为单个 1280 元素矢量
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
# 对每个图像进行单个预测,正数预测类 1,负数预测类 0;
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
# 搭建整体网络结构
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
# 编译模型
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 查看一下整体的网络结构
tf.keras.utils.plot_model(model)
model.summary()
# 训练模型
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
# 评估模型
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
参考
Tensorflow官网案例
卷积神经网络 概念认识:一篇文章“简单”认识《卷积神经网络》(更新版)
卷积神经网络 简单模型搭建:手把手搭建一个【卷积神经网络】
卷积神经网络 训练模型遇到过拟合问题,如何解决:“花朵分类“ 手把手搭建【卷积神经网络】