ResNet**迁移学习
2. ResNet
#ResNet网络
ResNet网络是在2015年由微软实验室提出,其网络中的亮点为1. 提出residual结构(残差结构)2.可以搭建超深的网络结构(突破1000层)3.用Batch Normalization加速训练(丢弃dropout)
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
1)梯度消失或梯度爆炸。随着网络的层数不断增加,梯度消失或者梯度爆炸的现象会越来越明显:假设每一层的误差梯度是一个小于1的数,在我们传播过程中每向前传播一层,都要乘以一个小于1的梯度误差,当我们的网络不断增加,梯度会越来越接近于0;反而言之,假设每一层的梯度误差是一个大于1的数,随着网络的层数不断加深,其梯度会越来越大,即出现梯度爆炸。
通过对我们的数据进行标准化处理,权重初始化,BN(Batch Normalization)
2)退化问题(degradation problem)。当我们解决了梯度消失或梯度爆炸问题后,仍然存在了神经网络的层数深没有层数浅的效果好的问题,用残差结构来解决退化问题
迁移学习
优势:1。能够快速的训练出一个理想的结果
2.当数据集较小时也能训练出理想的效果
注意:使用别人预训练模型参数时,要注意别人的预处理方式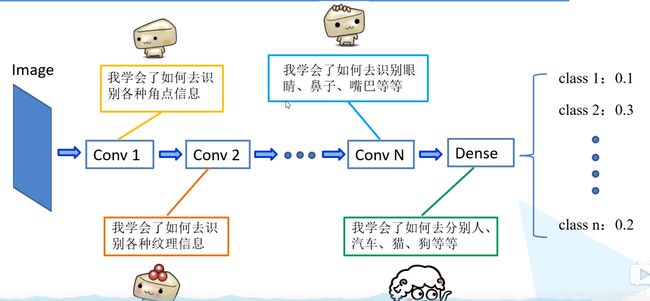
迁移:浅层已经学习好了的角点信息,纹理信息,这些信息是比较通用的,这些信息不仅在本网络中适用在其他网络中也可以用。将已经学习好了的浅层网络的参数迁移到新的网络中去,我们在去训练所需要的高维信息的特征
常见的迁移学习的方式
1.载入权重后训练所有参数(最后一层无法载入预训练模型参数)
2.载入权重后只训练最后几层参数
3.载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层。
用第一种方法是在于你不考虑训练的时间和设备上,其效果好于后面两种
Rsenet的网络
Rsenet的网络
import torch.nn as nn
import torch
#18层或34层的resnet
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)#残差结构
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
#50层101层152层的结构残差结构
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)`
迁移学习代码,先去下载pytorch官方给出的resnet网络的`
预训练模型
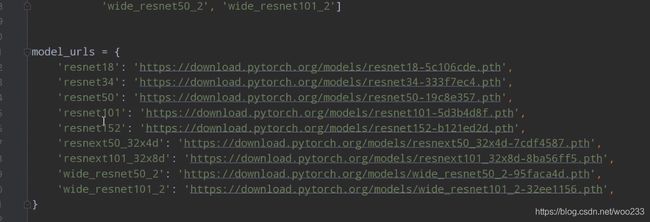
import torchvision.models.resnet #按住Ctrl键鼠标点击resnet,进入官方的脚本中,根据上图所示的链接进行下载
net = resnet34()
# load pretrain weights
model_weight_path = "./resnet34-pre.pth"
missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)#载入模型权重
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
inchannel = net.fc.in_features
net.fc = nn.Linear(inchannel, 5)#这里的5为自己需要分类的个数
net.to(device)
mobilenet的预训练模型的方法:
net = MobileNetV2(num_classes=5)
# load pretrain weights
model_weight_path = "./mobilenet_v2.pth"
pre_weights = torch.load(model_weight_path)#载入预训练模型参数
# delete classifier weights
pre_dict = {
k: v for k, v in pre_weights.items() if "classifier" not in k}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)#最后一层的权重不载入
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False
net.to(device)