本文翻译自Introduction to Database Concurrency Control

引言
假设进程A和进程B从Customer表中读取了同一行,在改变了数据后,同时把新的版本写回数据库,这时哪个改动会生效呢?进程A?进程B?还是同时生效?类似的,如果同时对一个名为Customer的共享对象做出改变,会发生什么呢?
在多人同时访问共享实体(无论是对象数据记录还是其他形式)时,会涉及到并发控制的问题。本文将会从实践的角度来概述并发访问控制的方式。
要了解如何在系统中实现并发控制,首先就必须要了解冲突,我们可以避免冲突,或者检测冲突然后解决它。然后是了解事务,它们是可能修改两个或多个实体的操作集合。在现代软件的开发项目中,并发控制和事务不仅仅在数据库的领域存在,而是在所有的架构层都存在相关的问题。
冲突
在Implementing Referential Integrity and Shared Business Logic中,我讨论了由于存在映射到数据模式的对象模式,从而导致的引用完整性问题,可以简单叫做跨模式引用的完整性问题。具体到冲突,只需要关心记录系统中数据实体的一致性问题。记录系统是实体的官方版本所在的位置。记录通常是存储在关系数据库中的数据,可以用XML格式,对象或者其他形式来表示。
当两个活动(可能是不完全成熟的事务)尝试更改记录系统中的实体时,会发生冲突。在三种情况下两个活动会互相干扰。
- 脏读。活动1(A1)从记录系统中读取实体,然后更新记录系统,但是不提交更改(例如,更改尚未完成)。这时活动2(A2)读取实体,不知不觉制作了未提交版本的副本。A1回滚了更改,将实体恢复到原始状态。此时A2读到的实体版本因为从未提交,因此不被认为实际存在。
- 不可重复读。A1从记录系统中读取一个实体并创建它的副本。此时A2从记录系统中删除改实体。那么A1现在有一个没有正式存在的实体的副本。
- 幻影读。A1从记录系统中检索实体集合,然后根据某种搜索条件(例如“所有名为Bill的客户”)来记录它们的副本。然后A2创建新的实体,新的实体正好满足搜索条件(例如,将“Bill Klassen”插入数据库),并保存到记录系统。如果A1重新应用搜索条件,将会获得不同的结果集。
如果允许缓存中的过时数据存在,并发的用户/线程越多,发生冲突的可能性越大。
锁策略
那么,我们能做什么呢?首先,我们可以采用一种悲观锁定方法来避免冲突,但是这样会以降低系统性能作为代价。其次,我们可以使用乐观锁定策略,这种策略可以检测冲突,然后解决冲突。第三,可以采取一种过于乐观的锁策略,完全忽视冲突。
悲观锁
悲观锁指的是实体在应用中存储(通常是以对象的形式)的整个生命周期内,在数据库中被锁定。锁定限制或者阻止其他用户使用数据库中的这个实体。写锁表示锁的持有者打算更新实体,在此期间禁止任何人读取,更新或者删除实体。读锁表示锁的持有者不希望实体在锁定期间被改变,它允许其他人读取实体,但是不能更新或删除该实体。锁的范围可能是整个数据库,表,多行或者单行。这些锁分别被称为数据库锁,表锁,页锁和行锁。
悲观锁定的优点是易于实现,并且保证对数据库的更改是一致和安全的。主要的缺点是此方法不可扩展。当系统有许多用户时,或者当事务涉及更多数量的实体时,或者当事务长时间存在时,不得不等待锁释放的情况会大大增加,因此会限制系统实际可以同时支持的用户数量。
乐观锁
在多用户系统中,冲突不频繁的情况是很常见的。虽然我们两个人都在使用Customer对象,但是当我使用John Berg对象时,你正在使用Wayne Miller对象,因此不会发生冲突。在这样的情况下,乐观锁定会成为可行的并发控制策略。解决的思路是,程序员在知道发生冲突的概率很低的情况下,不选择试图阻止它们,而是选择检测冲突,并且在冲突发生的时候解决它。
图一描述了在使用乐观锁定时更新对象的逻辑。应用程序将对象读入内存的过程中,对数据添加读锁并在读完后释放。在该时间点,可以对该行进行标记以便检测冲突(后面会更详细地说明)。然后应用程序操作对象,在要更新数据的时候,先获得对数据的写锁定,并读取数据源,以便确定是否有冲突。在确定没有冲突的情况下,程序更新数据并释放写锁。如果检测到冲突,比如数据在最初被读入内存后被另一个进程更新,那么冲突将需要被解决。
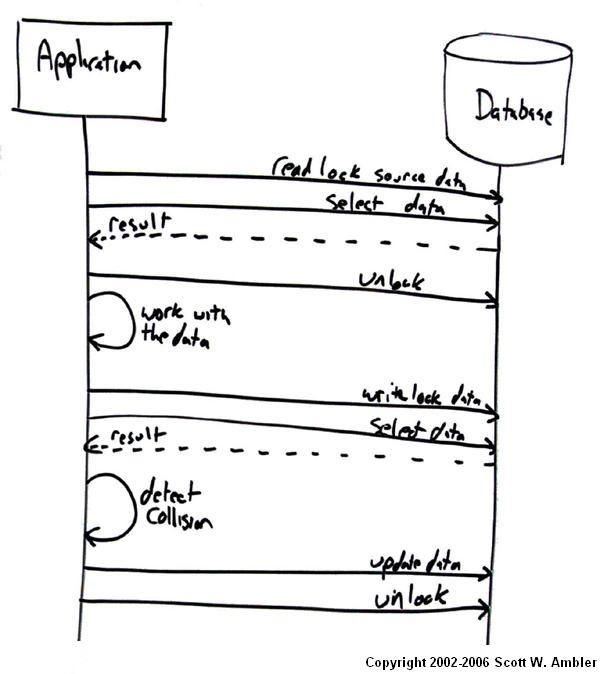
确定是否发生冲突有两种基本策略。
- 使用唯一标志符标记源。源数据在每次更新时都会被唯一标识。在更新的时候检查标识,如果和最初的值不同,那么说明数据源被改了。以下是不同类型的并发标识。
- 日期时间戳(这个值应该由数据库服务器来分配,因为不能指望所有计算机的时钟都同步)
- 增量计数器
- 用户ID(只有每个人都有唯一的ID,并且只登陆一台机器,并且应用程序确定在内存中只存在一个对象的副本时,这种方法才有效)。
- 由全局唯一代理键生成器生成的值。
- 保留源数据的副本。在更新操作时检索源数据,并与最初检索的值进行比较。如果值不一样,那就说明发生了冲突。如果无法向数据库schema添加足够的列来维护并发标记,这个策略将是唯一的选择。
图一描述了一种朴素的方法,事实上有一些方法可以用来减少数据库交互的次数。对数据库的前三个请求--初始锁定,标记源数据,解锁--可以作为单个事务执行。接下来的两个交互,锁定和获取源数据的副本,也可以合并成一次数据库请求。此外,更新和解锁可以类似地组合。另外一种改进的方式是将最后四个交互组合成单个事务,在数据库服务器而不是应用服务器上执行冲突检测。
过度乐观锁定
这种策略假设冲突永远不会发生,既不会试图避免也不会检测冲突。此策略适用于单用户系统,和系统一次只能由一个用户或者进程访问的系统。这样的情况确实是会发生的。重要的是要认识到,这个策略完全不适合多用户系统。
冲突解决策略
在解决冲突的时候有五种基本策略:
- 放弃
- 展示问题让用户决定
- 合并改动
- 记录冲突让后来的人决定
- 无视冲突,直接覆盖。
要知道冲突的粒度也很重要。假设两个人操作同一Customer实体的副本。一个人更新了客户的姓名,另一个人更新了他们的购物偏好设置,那么可以从这次的冲突中恢复。实际上,更新相同的用户时,冲突发生在实体级别,但是不是在属性级别。在实体级别检测到潜在冲突,然后在属性级别解决是很常见的。
策略的选择
为了简单起见,许多项目团队选择单一的锁定策略并将其应用到所有表。当应用程序中所有表或至少大多数表具有相同的访问特性时,此方法是很有效的。然而,对于更复杂的应用程序,可能需要基于各个表的访问特性实现几个锁定策略。Willem Bogaerts建议的一种方法是按类型对每个表进行分类,来为其提供锁定策略的指导。如下表
| 表类型 | 例子 | 推荐的策略 |
|---|---|---|
| 实时高并发 |
|
|
| 实时低并发 |
|
|
| 日志(通常是附加日志) |
|
|
| 查找/引用(通常只读) |
|
|