使用locust同时压测http和websocket
因连接websocket业务逻辑是需要先登录,拿到token作为参数去请求,所以测试websocket协议也必须先使用登录接口,但是我又不想先全部登录一下拿到token保存起来,所以想http和websocket的压测一起处理。
这里是基于ws4py库连接websocket
先写基础的链接类:
from locust import TaskSet, task, between, Locust, events, HttpLocust
from ws4py.client.threadedclient import WebSocketClient
from ws4py.websocket import Heartbeat
from ws4py.client import ssl, HandshakeError
class Ws(WebSocketClient):
def __init__(self, url, token, start_time):
super(Ws, self).__init__(url)
self.token = token
self.start_time = start_time
def opened(self):
ms_9904 = json.dumps({
"c": 9904,
"data": {
"token": self.token
}
})
self.send(ms_9904)
def received_message(self, message):
if str(message) != "6":
ms = json.loads(str(message))
print(ms)
locust是通过events.request_failure.fire和request_success.fire获取请求成功和失败,
所以在websocket的connect方法里加入这两个方法,
在上面的Ws类中添加修改connect方法,connect方法是直接从源码里复制出来,然后在try except中加入events.request_failure.fire,最后正确的时候添加request_success.fire
def connect(self):
if self.scheme == "wss":
self.sock = ssl.wrap_socket(self.sock, **self.ssl_options)
self._is_secure = True
try:
self.sock.connect(self.bind_addr)
except TimeoutError as err:
events.request_failure.fire(request_type="web_socket", name='ws',
response_time=(time.time() - self.start_time) * 1000,
response_length=0, exception=err)
self._write(self.handshake_request)
response = b''
doubleCLRF = b'\r\n\r\n'
while True:
bytes = self.sock.recv(128)
if not bytes:
break
response += bytes
if doubleCLRF in response:
break
if not response:
self.close_connection()
err = HandshakeError("Invalid response")
# 这里如果没有response,那么就报错握手异常
events.request_failure.fire(request_type="ws", name="web_sk",
response_time=(time.time() - self.start_time) * 1000,
response_length=0, exception="2,%s" % err)
raise err
headers, _, body = response.partition(doubleCLRF)
response_line, _, headers = headers.partition(b'\r\n')
try:
self.process_response_line(response_line)
self.protocols, self.extensions = self.process_handshake_header(headers)
except HandshakeError as err:
self.close_connection()
events.request_failure.fire(request_type="ws", name='web_sk',
response_time=(time.time() - self.start_time) * 1000,
response_length=0, exception="3,%s" % err)
raise
self.handshake_ok()
if body:
self.process(body)
events.request_success.fire(request_type="ws", name='web_sk',
response_time=(time.time() - self.start_time) * 1000,
response_length=0)
编写websocket的蝗虫类
class WebsocketLocust(Locust):
"""修改client"""
def __init__(self):
super(WebsocketLocust, self).__init__()
self.client_ws = Ws
原有的HttpLocust类中有self.client方法,所以我这里在locust源码上添加了几行代码
在locust.core的TaskSet类中添加方法:
class TaskSet(object, metaclass=TaskSetMeta):
# 在最后添加了该方法
@property
def client_ws(self):
return self.locust.client_ws
在locust.core的Locust类中添加属性:
class Locust(object):
# 添加属性
client_ws = NoClientWarningRaiser()
编写TaskSet任务类
目前任务就简单的写了登录方法和websocket的连接方法,TaskSet类中on_start方法是每个蝗虫开始任务时,都会先调用一次该方法,应该就像初始化一样。
class WebsocketTasks(TaskSet):
def on_start(self):
user_id = self.locust.user_list.get() # 从队列中获取user_id
par = {
"userId": user_id,
}
re = self.client.post("/cgi_bin/login2", par).json()
self.token = re['data']['token']
@task
def start_game(self):
start_time = time.time()
ws = self.client_ws("ws://localhost/web_sk", self.token, start_time)
ws.connect()
Heartbeat(ws).run()
ws.run_forever()
编写蝗虫类
继承WebsocketLocust和HttpLocust
class WebsocketUser(WebsocketLocust, HttpLocust):
host = "http://x.x.x.x"
user_list = queue.Queue() # 使用队列
for i in range(500):
user_id = "N%s" % (10000 + i)
user_list.put_nowait(user_id)
task_set = WebsocketTasks # 指定任务
wait_time = between(1.0, 3.0) # 每个任务类中的任务间隔时间1~3秒
启动
输入命令locust -f locustfile.py
(也有–no-web模式)
看到终端输出:

在浏览器输入:localhost:8089,就能进到首页
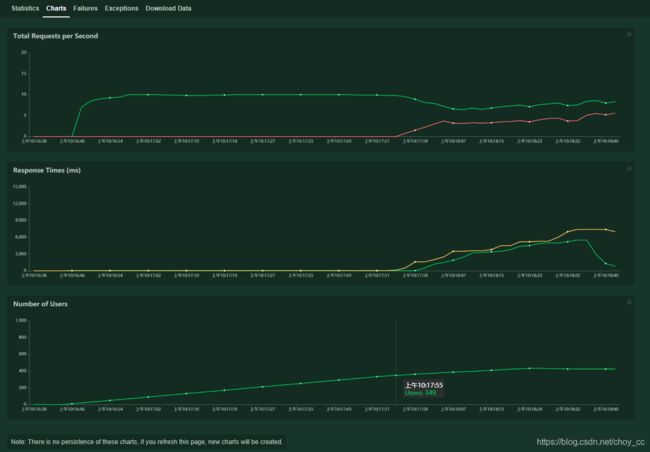
这里我输入总计500个用户,每秒5个
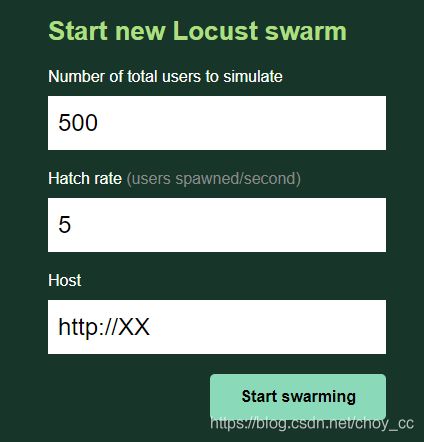
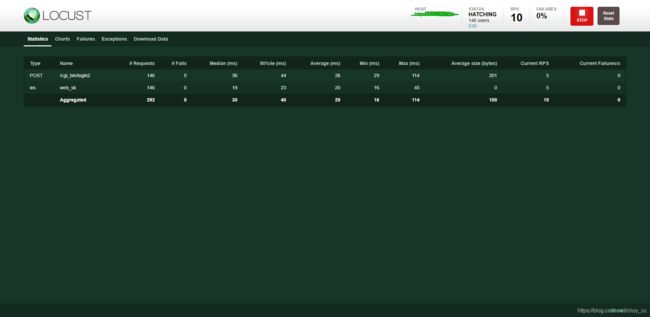
开始运行的时候还是很健康的
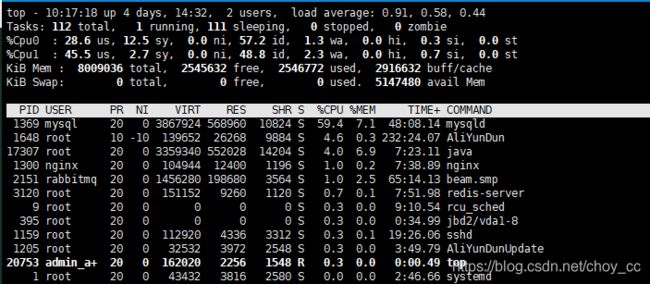
linux查看load average的平均负载也是正常范围,但是mysql的CPU占用率有点高,应该是登录接口要查询user表,查看user表并没有添加索引,添加索引应该会降低cpu消耗
拐点出现在350个用户左右,响应时间增长的很快
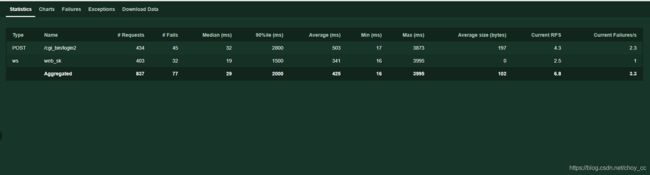
我们可以看到每秒处理的请求数,响应时间,并发用户数
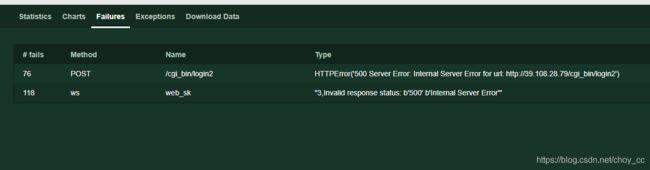
查看错误信息,都是握手不成功的
登录阿里云查看监控信息,发现是网络资源被占满,无法建立更多的连接。