手摸手带你 App 爬虫入门
你好,我是悦创。
我将选取一个一款展示数据的 App 进行讲解,将会使用 Fiddler 抓包来分析数据请求的接口,以及使用 Python 编写爬虫逻辑,最后,把数据保存到 MongDB 里面去。
公众号原文:https://mp.weixin.qq.com/s/06eKx-X87DEm5sylA7_–g
1. 准备工作
在跟随本教程开始之前,请确保你已经做完如下配置,以下是我本文的操作环境:
- 安装好 Python 3.6+,我这里使用的是 Python 3.7,并确保可以正常运行;
- Python 编译器 Sublime(如果有安装或者已经有 Pycharm 可以跳过准备工作;
- Python 爬虫常用库安装;
- 安装好抓包工具:Fiddler;
- 夜神模拟器安装;
- 安装 豆果美食 App,通过手机应用商店安装时,需要把代理关掉,等到需要在开启代理;
- 课程资料(包含 APP)
1.1 Python 环境的安装
对于 Python 环境的安装,这里可以我简单的编写一些:
- 下载方法
进入官网:https://www.python.org

如图:
- 选择上方 Downloads 选项
- 在弹出的选项框中选择自己对应的系统(注:若直接点击右边的灰色按钮,将下载的是 32 位)

进入下载页面,如图:
- 为 64 位文件下载
- 为 32 位文件下载
选择您对应的文件下载。
安装注意事项

(图片来源于网络)
自定义选项,可以选择文件存放位置等,使得 Python 更符合我们的操作习惯。
默认安装:一路 Next 到底,安装更方便、更快速。
但是,不管是默认安装还是自定义安装,都需要你记得勾选上 Add Python 3.6 to Path
特别注意:图中箭头指向处一定要记得勾选上。否则得手动配置环境变量了哦。
Q:如何配置环境变量呢?
R:控制面板—系统与安全—系统—高级系统设置—环境变量—系统变量—双击 path—进入编辑环境变量窗口后在空白处填入 Python 所在路径—一路确定。
检查
安装完 Python 后,Win+R 打开运行窗口输入 cmd,进入命令行模式,输入 python。若如下图显示 Python 版本号及其他指令则表示 Python 安装成功。

1.2 Python 编译器 Sublime
官网:http://www.sublimetext.com/
选择该编辑器的原因:
- 不需要过多的编程基础,快速上手
- 启动运行速度快
- 最关键的原因——免费
常见问题
使用快捷键 Ctrl+B 无法运行结果,可以尝试 Ctrl+Shift+P,在弹出的窗口中选择 Bulid With: Python。

或选择上方的 Tool 选项中的 Build With 选项,在弹出的窗口中选择 Python。
1.3 爬虫常用库安装
Python 通过 pip install xxx,来使得 Python 自动安装库。
这里就直接运行如下命令即可:
pip3 install -r https://www.aiyc.top/usr/uploads/2020/05/4258804948.txt
1.4 安装抓包工具:Fiddler
1.4.1 Fiddler 抓包软件介绍
1.4.1.1 前言
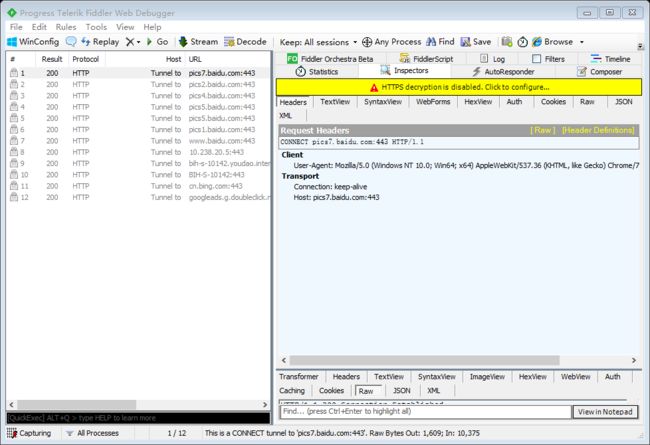
Fiddler是一个很好用的用 c# 编写的 HTTP 网络抓包工具,使用它的话,我们就不必再浏览器的开发者工具里分析页面了,可以在更加专业和智能化的 Fiddler 里面对页面参数进行请求调试。
我们的 Fiddler 是一款 Web 调试代理平台,可以监控和修改 Web 数据流,本身是一款免费开源的不管是开发人员还是测试人员都可以帮助用户查看数据流。

我们可以看一下上图(图一)我们的 Fiddler 在我们的用户(客户端)和 Web 服务器的中间,作为一个代理中间件存在,它可以捕获客户端发起的请求并进行转发,服务器收到 Fiddler 转发的请求之后进行一个相应(response)Fiddler 再一次的捕获到返回的数据,再一次的转发给客户端。通过如上的描述,我们可以知道 Fiddler 在中间也就是个中间人那么我们可以通过这个中间人来进行捕获所有的数据,并且进行修改,我们抓取 APP 包的方法也是基于此原理的。
1.4.1.2 功能强大
- Fiddler 的功能非常强大,它支持 IE、Chrome、Safari、Firefox 和 Opera 等浏览器,针对这些浏览器,它可以更加具体的展现出表示层的数据是如何传递的,展示出数据的格式,语言类型,传送方式缓存机制以及连接方式等等。
- 可以在 iPhone、iPad 等移动设备上进行连接抓取。
对于 Fiddler 的优缺点我们要进行一些了解:
1. 优点
- 它的优点是可以查看所有浏览器、客户端应用或服务器之间的 Web 数据流;
- 可以手动或自动修改任意的请求和响应;
- 可以解密 HTTPS 数据流以便查看和修改;
- 修改请求的数据,甚至可以实现请求自动重定向,从而修改服务器返回的数据。
2. 缺点
- Fiddler 只支持 Http、Https、ftp、Websocket 数据流等相关的协议;
- 无法监测或修改其他数据(也就是它不支持的数据类型),如:SMTP、POP3 等;
- Fiddler 无法处理请求和响应超过 2GB 的数据。
1.4.2 Fiddler 软件下载
接下来,我们来看一下 Fiddler 软件的下载和安装。我们可以直接通过该地址:https://www.telerik.com/fiddler 来访问它的下载界面,界面如下所示(图二):
点之后,就会出现如下界面(图三)需要我们填写信息,如果不知道 填什么,可以按我的图片填写即可,邮箱填你自己的:

点击之后他就会自动开始下载了。
1.4.3 Fiddler 安装
下载完成之后,我就要进行安装了。安装起来也是非常的简单,基本上就一直点击下一步就可以了。这里要注意的是 Fiddler 安装之后是不创建快捷方式的,所以可以自定义安装路径方便你之后的查找和运行。当然在开始 当中也是可以看见的。
为了方便同学们安装,我将 Fiddler 安装录成了视频,同学们可以点击下面连接进行观看:
视频链接:https://www.aiyc.top/archives/448.html
第一次启动有可能会出现如下信息(图四),点击否即可。

正常运行的界面如下(图五):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LWzHZTrS-1600652136238)(豆果 APP 抓取.assets/8c6bb0f0-8b94-11ea-9776-f5261045ba7d)]
至此,这里就成功安装完成了 Fiddler,
1.5 夜神模拟器安装
这里夜神模拟器安装较为简单,为了控制文章长度,如果不会安装的可以参考该链接:https://www.aiyc.top/archives/494.html
1.6 安装 豆果美食 App
具体安装可以参考如下链接:https://www.aiyc.top/archives/508.html,这里支持拖拽安装。
1.7 课程资料(包含 APP)
点击该链接获取:https://gitee.com/aiycgit/Study_Learning_DataBase/tree/master/douguo_App
2. 启动 Fiddler 与配置模拟器代理
开启 Fiddler 并设置模拟器里面手机代理,这一步的具体操作可以点击观看如下视频:
配置完成之后,我们的手机就要通过 Fiddler 来进行抓包了,这也就是我们平时所说的中间人。
2.1 Fiddler 补充(Fiddler 配置与基础操作)
2.1.1 基础介绍
Fiddler一旦启动就会自动开始工作,我们此时打开浏览器随便点击几个页面就可看到 Fiddler 抓取了许多网络包。(图六-1)

2.1.2 软件基本界面
接下来我们来进一步解析一些 Fiddler。

Fiddler 每个部分的名称已经在上图(图六),最上面是我们的工具栏,左边是我们的会话列表,左下是命令行工具,右边 HTTP request(图上我 request 多打了一个 s 抱歉),右下也就是 HTTP response。
- 左下角的 Captuing 是 Fiddler 控制抓取的开关。
- 会话列表:也就是我们抓到的数据都会在会话列表显示;
- 命令行工具:我们可以进行一些过滤等操作,我们可以直接在命令里面输入
help就会自动弹出一个页面,更多信息或者命令行命令可以从跳出的这个页面了解。 - HTTP request:也就是我们 http 的请求信息,里面包含请求方法、http 协议、请求头(user-agent)等等;
- HTTP response:也就服务器给我们返回的信息;
我们继续往下看这张图(图六-3):

- [#] Request 顺序
- [result] HTTP 状态码
- [protocol] 请求使用协议
- [Host] 请求地址域名
- [URL] 统一资源定位符,请求的地址
- [Body] 请求大小 byte
- [Caching] 缓存控制
- [Context-Type] 请求响应类型
- [Process] 发出请求的进程名称
- [Comments] 用户添加的备注
- [Custom]用户设置的自定义值
2.1.3 Fiddler 模拟场景

在 Ruels 里面可以模拟各种场景:
- 请求之前进行登陆验证;
- 对网页进行压缩,测试性能;
- 模拟不同客户端的请求;
- 模拟不同网速不同情况,测试页面容错性;
- 禁用缓存,方便调试服务器静态资源;
- Hide Image Request :隐藏图像请求(我一般开启);
- Hide CONNECTs:把我们的 TCP/IP 握手过滤掉,因为我们不需要看它三次握手三次挥手(我一般开启);
- Apply GZIP Encoding:开启页面压缩,也就是说服务器不用一次性传输很多数据,就类似在电脑上压缩文件来节约空间一样,目的是把页面压缩以达到更好的性能;
2.1.4 查看请求内容
随意双击左侧的一个网络包,右侧的 inspectors 里就可以查看请求内容,与浏览器开发者选项卡中的内容相同。(图七)

2.1.5 对于HTTPS网站的信息我们是无法查看的
我可以看到下面图的黄色提示(图八),别急接下来会讲到的。
2.2 设置
那上面所说的一些基本界面中的信息它不难,那难在哪里呢?
答:难在如何进行一个设置
那接下来我们来一起设置一下我们的 Fiddler 让它可以抓取我们的浏览器数据的数据包,后面会给同学们讲解 App 的数据包。
2.2.1 设置抓取浏览器的数据包——HTTPS 选项卡
接下来,我继续往下设置,也还是在 Tools 里面的 Options ,我们可以看到有很多的选项卡如下图(图八-2):

我们不仅要抓取 HTTP 的数据包,也还要抓取 HTTPS 的数据,相同手机 APP 上也是有 HTTP 和 HTTPS。所以这里我们需要它解密 HTTPS 数据流量,这里也顺便解决上面提到无法抓取 HTTPS 的问题。
所以,我们可以通过伪造 CA 证书来欺骗浏览器和服务器,从而实现 HTTPS 解密,就是把 Fiddler 伪装成为一个 HTTPS 服务器,在真正的 HTTPS 服务器面前 Fiddler 又伪装成浏览器(其实也就是在中间,不清楚的可以看上面的图一)。
我们先点击工具栏中的 Tools,然后点击 Options,如下图(图九):

接下来点开 HTTPS 选项卡,勾选 Decrypt HTTPS 如下图所示(图十):

全部选是,之后再次访问HTTPS网站就可以抓包查看了。上图(图十)的图十的提示就是我们要安装一个 CA 证书,不过这个证书是 Fiddler 自己的证书,我们选是即可,在这里 Fiddler 其实扮演的就是中间人攻击。
虽然上面提到了,那为了让大家更清晰,我这里再提一下:大家可以看上图(图十一) 理解一下,也就是我们客户端发出去的请求会由我们的 Fiddler (中间人)来捕获,由 Fiddler 的证书来进行解密,解密完成之后再由 Fiddler 的证书进行加密然后转发到服务器上面。服务器再将所请求的数据返回(加密过的),Fiddler 接收到数据之后再进行解密,解密完成之后再发数据返回给客户端(明文数据)。这也就是我们 Fiddler 在中间做的一个中间人操作。
我接下来可以看见,在 Decrypt HTTPS 下面还有一个选项,如下图(图十二):

这是让你选择抓取的对象:
- …from all processes:抓取所有的进程;
- …from browsers only:仅抓取浏览器;(这里为了方便小白入门以免抓取到其请求的信息,我们先选择“仅抓取浏览器进程”)
- …from non-browsers noly:抓取除浏览器进程之外的数据;
- …from remote clients only:仅抓取远程客户端;(当我们抓取 App 数据端的时候,就可以选择该选项)
最终我们在 HTTPS 选项卡中设置的最终版如下图所示(图十三):

2.2.2 Connections 选项卡
接下来,我们来设置一下 Connections 选项卡,点击 Connections 选项卡之后,界面如下(图十四):

这里需要设置 Fiddler 设置端口号(Fiddler listens on port)一般这里的端口号都可以设置只要不是系统的端口号冲突即可。这里,我一般设置成 8889,当然默认也是可以的。并且你也要勾选允许远程电脑进行连接(Allow remote computers to connect)如果你不勾选你的手机是连不到 Fiddler 的,也就是说你的抓包工具是抓不到你手机上的数据包的。
当你点击(Allow remote computers to connect)的时候,会弹出如下提示框(图十五):

点击确定即可,然后点击“ok”即可,操作如下动图(图十六):

截止这里,就已经设置好了,我们就可以抓取浏览器的数据了。
2.2.3 Fiddler抓包手机APP
首先需要点击Tools->options->Connections->Allow remote computers to connect

设置好之后,需要打开你的手机,在手机设置里把手机的代理设置为电脑端的IP和端口,因为不同手机的设置环境不同,这里需要你自行百度,假设我们电脑地址为192.168.1.1,在手机配置好代理之后,打开手机浏览器,输入192.168.1.1:8888,会出现如下界面

点击最下边的 FiddlerRoot centificate,下载并且安装证书。
最后浏览手机 APP百度外卖,就可以在电脑端抓包了。

2.3 简单操作 Fiddler
2.3.1 清空会话列表中的信息
方法有两种,第一种是下图的操作方法,先全选(Control + A)然后鼠标右键,选择“remove”>>> “All Sessions”即可。具体操作看下图(图十七):

第二种方法,直接上动图(图十八):

2.3.2 设置浏览器代理
上面我们简单的配置了一下 Fiddler 接下来需要配置一下我们的浏览器,使我们的浏览器通过代理来访问互联网,那我们应该如何设置呢?
这里我们需要用到 Chrome 上的一个插件,名称叫做:Proxy SwitchyOmega 这里需要到谷歌应用商店,链接:https://chrome.google.com/webstore/category/extensions?hl=zh-CN,然后输入:Proxy SwitchyOmega 即可添加该扩展程序,但考虑到大部分人不支持“科学上网”这里提供三个链接下载:
操作视频:https://www.aiyc.top/archives/450.html
推荐下载地址:https://www.aiyc.top/archives/450.html
下载地址1:https://github.com/FelisCatus/SwitchyOmega/releases
下载地址2:https://proxy-switchyomega.com/download/
s随便选择一个下载地址下载即可,安装也很简单可以直接拖拽到浏览器即可安装。一般安装成功后,都会出现在下图位置(图十九):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DlFHJ4F7-1600652136255)(豆果 APP 抓取.assets/43869360-8c65-11ea-baea-1d374979c00e)]
点击上图的红色方框里面的插件,就会出现下图所示(图二十):

点击”选项“之后就会出现如下页面(图二十一):

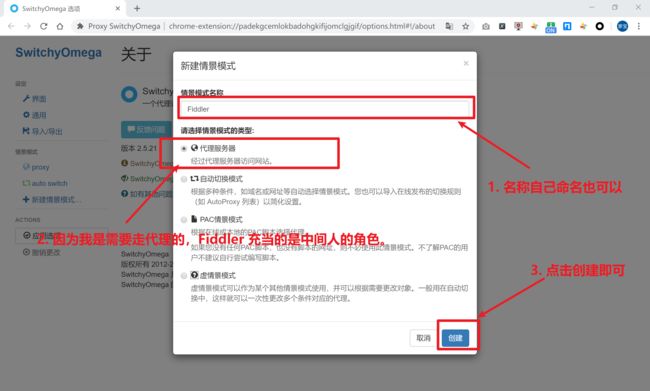
点击“新建情景模式”之后你会看见如下界面(图二十二):

配置信息可参考如下图片填写,然后点击创建即可(图二十三):
点击创建之后,你会看到如下界面(图二十四):

接下来,我们来进一步设置,代理协议选择 HTTP 代理服务器填写 127.0.0.1 代理端口就是上面设置 Fiddler 时设置的端口,这里我设置的是 8889,所以填的也就是 8889,下图已经给出(图二十五):

记得修改完成之后点击“应用选项”否则你这个情景模式是无法保存的。接下来我们就可以把浏览器改成 Fiddler 的情景模式,也就是说我们可以通过 Fiddler 来抓取数据了。操作如下动图(图二十六):

以上就是配置好了,不过这里要注意的是,我们配置完成之后要重新启动一下 Fiddler 不然会显示未连接到互联网如下图(图二十七):

重启应用之后,我们可以把 Fiddler 会话列表清空,然后访问:https://www.aiyc.top/ 操作如下图(图二十八):
从上面的操作可以看到,我们成功抓取到了数据,那如何看里面的信息呢?
我们直接点击相应的数据即可,操作如下动图(图二十九):

上面我们选择 Inspectors 然后点击 Headers 我们一般使用 Raw 查看,我们还可以查看一下我网站返回的数据,操作如下动图(图三十):

之后会给大家讲解如何设置抓取 App 的手机的数据包,那这里还有一个要设置的,不过在讲如何设置之前,我们来看看为什么要设置,这里我们也是 先清空会话列表,请求百度网址,并查看返回的数据,操作如下动图(图三十一):
我们可以看见,给我返回的数据是乱码,如下图(图三十二):

那该如何解决呢?
方法一点击如下图位置的提示即可解决(图三十三):

不过,方法一的话,每次遇见乱码都得再点以次,这样显然不是我们想要的,我们可以再进行一步设置,如下图设置(图三十四):

这样就可以解决了。
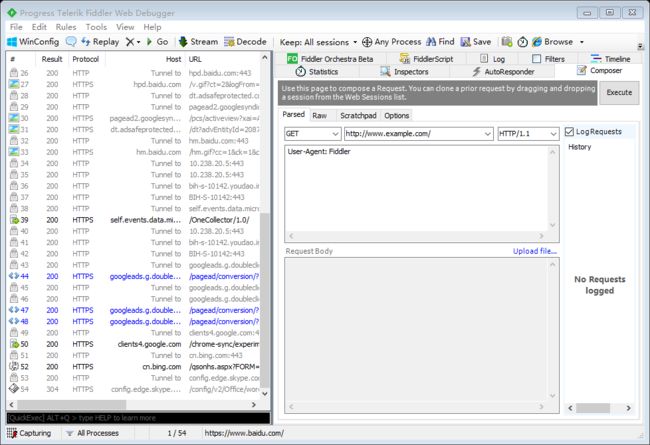
2.3.3 自定义请求发送
在右边的 Composer 选项卡中,我们可以自定义请求,手动写一个,也可以从左边的会话中拖拽一个过去。
我们只需要编写简单的URL,当然还可以定制一些 user-agent

3. 抓取豆果美食 App
3.1 目标
- 分析豆果美食数据包
- 通过 Python 多线程-线程池抓取数据
- 通过使用代理 ip 隐藏爬虫
- 将数据保存到 Mongodb 中
打开 Fiddler、打开豆果美食,我们需要抓取豆果美食的菜谱分类,


我们可以操作时可以看见,你右边滚动(向下滚动/滑动),左边抓包的也在一直抓包,当然你可以自行选择抓取其他的数据。这里演示的只是:菜谱->蔬菜->土豆->学做最多;
接下来就是要分析抓取到的这些数据包,看 有没有我可以请求且所需要的数据接口,以及确认是否服务器会给我们相应的返回数据。
3.2 数据包分析
通过上面的操作我们可以获取的很多的数据包,接下来我们就来分析一下我们锁需要的数据包,找这些数据包其实有一些规律,比方说我们豆果美食,那它的数据肯定是以一个主站或者说主机头(主域名啥的),来进行请求的;
所以,我们可以 Finde 一下,也可以 Control + F,当然也可以在菜单栏:Edit->FindSessions,操作之后,界面如下:


- Find:查找内容
- options:
- Search:设置查找(匹配范围)【Requests and response、Requests only、Response only、Url only】;
- Examine:检查;
- Match case:区分大小写;
- Regular Expression:正则表达式;
- Search binaries:搜索二进制文件;
- Decode compressed content:解码压缩内容;
- Search only selected sessions:只搜索选定的会话;
- Select matches:选择匹配;
- Unmark old results:取消标记旧的结果(比如第二次筛选,把上一次赛选的所标记的颜色取消掉);
- Result Highlight:结果强调(高亮);
我们可以在 api.douguo.net,如何我们就可以看见包含 api.douguo.net 的数据包都变成黄色。
然后,我点击去一个找,找到如下:

但是会发现这个数据包其实是,属于全部里面的数据包,并不是我们要选的学做最多的。
我接下来继续分析,看哪些是符合我们的数据包:
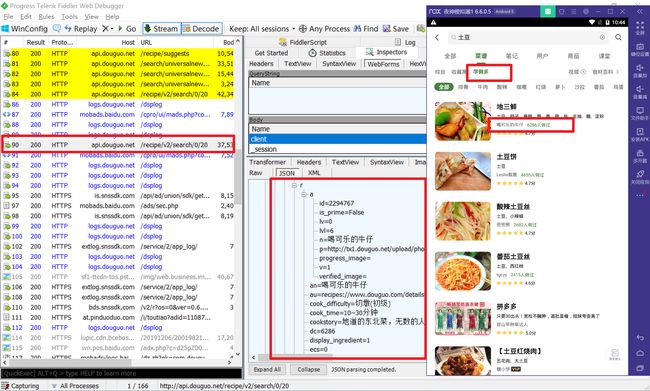
我在看看第二页,因为我们原先滚动(滑动了屏幕):

这样我们就可以知道,该 App 是每页20条菜谱数据。
注意:如果你上面找到对应的 json 数据,却显示貌似不正常,这个时候使用浏览器或者其他工具进行 json 格式化;
在线 Json 格式化网址:https://c.runoob.com/front-end/53
效果如下:
原本:
格式化之后:

最终我们就找到的数据接口。
我把抓取到的数据导了出来,内容同学们可以点击该连接直接阅读:https://gitee.com/aiycgit/Study_Learning_DataBase/blob/master/douguo_App/90_Full.txt
3.3 编写爬虫代码
3.3.1 构造请求头
编写 headers,这里我们把 fiddler 抓取到数据中的 headers 构造成字典,使用正则表达式:
(.*?):(.*)
"$1":"$2",
在 sublime 当中快捷键:Control + H,使用其他编辑器也是可以的,自行选择。

编写完成之后选 Replace All 即可:
"client":"4",
"version":"6962.2",
"device":"MI 5",
"sdk":"22,5.1.1",
"channel":"qqkp",
"resolution":"1920*1080",
"display-resolution":"1920*1080",
"dpi":"2.0",
"android-id":"1f0189836f997940",
"pseudo-id":"9836f9979401f018",
"brand":"Xiaomi",
"scale":"2.0",
"timezone":"28800",
"language":"zh",
"cns":"2",
"carrier":"CMCC",
"imsi":"460071940762499",
"User-Agent":"Mozilla/5.0 (Linux; Android 5.1.1; MI 5 Build/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.136 Mobile Safari/537.36",
"act-code":"1588254561",
"act-timestamp":"1588254561",
"uuid":"0c576456-a996-45c5-b351-f57431558133",
"battery-level":"0.97",
"battery-state":"3",
"mac":"F0:18:98:36:F9:97",
"imei":"355757944762497",
"terms-accepted":"1",
"newbie":"0",
"reach":"10000",
"Content-Type":"application/x-www-form-urlencoded; charset=utf-8",
"Accept-Encoding":"gzip, deflate",
"Connection":"Keep-Alive",
"Cookie":"duid=64268418",
"Host":"api.douguo.net",
"Content-Length":"179",
然后,就是要优化 headers 你要进行优化,那不是我们自己觉得哪些是可以有可无的是需要我们多抓取几次数据包之后得出来的结论。
当然,还有就是不断地测试,注释与取消注释,然后去请求看是否正常返回数据。
经过我地大量测试发现 imei 是不能去掉的,那这个 imei 是个什么东西呢?
可以打开我们夜神模拟器的设置,我们可以找到如下 imei 设置:

这个 imei 是随机生成的,我们需要进行保留的;
我们还可以看到 mac 地址,我们也可以进行注释掉,以及这两个 android-id、pseudo-id 我们也可以注释掉;
imsi 我们也把它注释掉,以及 Cookie 也注释掉,因为你一直带着这个 Cookie 去访问很容易被服务端检查并发现,如果这个 cookie 过时(失效了)这样也是访问不到的,还有就是 Content-Length 可以注释掉;这样一个 headers 就伪造完成了,以上注释是我测试过的,如果还有可以注释掉或者其他可以在下方留言交流。
3.3.2 构造全部栏目的 Data(index_data)

复制出来并构造成字典即可。
3.3.2 分析全部栏目&编写爬虫
然后我们需要编写请求,这里要注意,代理我们要在我们请求之后再加上去,也就是测试成功之后再往上加代理,不然你有可能搞不清楚 是你代理除了问题还是请求数据的时候出现了问题,造成数据没有返回。
为了抓取蔬菜中的全部数据,我要来分析一下主页的数据,那就算要分析主页的数据,所以也是要找到这个 API 接口的,
http://api.douguo.net/recipe/flatcatalogs
为什么是这个呢?
我们把它的 json 拿出来看看:

从上面看,我们可以得出结论,就是我们需要的主页数据。
接下来就是编写代码了,最终我们编写如下代码:
"""
project = 'Code', file_name = 'Spider_douguo.py', author = 'AI悦创'
time = '2020/5/21 11:13', product_name = PyCharm, 公众号:AI悦创
code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
"""
# 导入请求库
import json
import requests
from urllib import parse
from requests.exceptions import RequestException
# 分析请求的类型:post;
# 分析变化的数据:url 变化;
# post 的 data 是不一样的;
# 分析不变的数据:headers 是不变的;
HEADERS = {
"client":"4",
"version":"6962.2",
"device":"MI 5",
"sdk":"22,5.1.1",
"channel":"qqkp",
"resolution":"1920*1080",
"display-resolution":"1920*1080",
"dpi":"2.0",
# "android-id":"1f0189836f997940",
# "pseudo-id":"9836f9979401f018",
"brand":"Xiaomi",
"scale":"2.0",
"timezone":"28800",
"language":"zh",
"cns":"2",
"carrier":"CMCC",
# "imsi":"460071940762499",
"User-Agent":"Mozilla/5.0 (Linux; Android 5.1.1; MI 5 Build/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.136 Mobile Safari/537.36",
"act-code":"1588254561",
"act-timestamp":"1588254561",
"uuid":"0c576456-a996-45c5-b351-f57431558133",
"battery-level":"0.97",
"battery-state":"3",
# "mac":"F0:18:98:36:F9:97",
"imei":"355757944762497",
"terms-accepted":"1",
"newbie":"0",
"reach":"10000",
"Content-Type":"application/x-www-form-urlencoded; charset=utf-8",
"Accept-Encoding":"gzip, deflate",
"Connection":"Keep-Alive",
# "Cookie":"duid=64268418",
"Host":"api.douguo.net",
# "Content-Length":"179",
}
# print(parse.unquote('%E5%9C%9F%E8%B1%86'))
class DouGuo_Crawler:
def __init__(self):
self.headers = HEADERS
# self.url = DETAIL_API_URL
self.index_data = {
"client": "4",
# "_session": "1590028187496355757944762497",
# "v": "1590023768",# 时间戳,也就是你请求数据的时间
"_vs": "2305",
"sign_ran": "94b96c996a4a222540e435ee06ef133a",
"code": "b366f93caa7bac04",
}
def request(self, url, data = None):
try:
response = requests.post(url = url, headers = self.headers, data = data)
if response.status_code == 200:
return response
return None
except RequestException:
return None
def main(self):
url = 'http://api.douguo.net/recipe/flatcatalogs'
html = self.request(url = url, data = self.index_data)
print(html.text)
if __name__ == '__main__':
douguo = DouGuo_Crawler().main()
运行结果:
{
"state":"success","result":{
"nv":"1590045372","cs":[{
"name":"\u70ed\u95e8","id":"1","ju":"recipes:\/\/www.douguo.com\/search?key=\u70ed\u95e8&_vs=400","cs":[{
"name":"\u5bb6\u5e38\u83dc","id":"18","ju":"recipes:\/\/www.douguo.com\/search?key=\u5bb6\u5e38\u83dc&_vs=400","cs":[{
"name":"\u7ea2\u70e7\u8089","id":"5879","ju":"recipes:\/\/www.douguo.com\/search?key=\u7ea2\u70e7\u8089&_vs=400","cs":[],"image_url":""},{
"name":"\u53ef\u4e50\u9e21\u7fc5","id":"5880","ju":"recipes:\/\/www.douguo.com\/search?key=\u53ef\u4e50\u9e21\u7fc5&_vs=400","cs":[],"image_url":""},{
"name":"\u7cd6\u918b\u6392\u9aa8","id":"5881","ju":"recipes:\/\/www.douguo.com\/search?key=\u7cd6\u918b\u6392\u9aa8&_vs=400","cs":[],"image_url":""},{
"name":"\u9c7c\u9999\u8089\u4e1d","id":"5882","ju":"recipes:\/\/www.douguo.com\/search?key=\u9c7c\u9999\u8089\u4e1d&_vs=400","cs":[],"image_url":""},{
"name":"\u5bab\u4fdd\u9e21\u4e01","id":"5883","ju":"recipes:\/\/www.douguo.com\/search?key=\u5bab\u4fdd\u9e21\u4e01&_vs=400","cs":[],"image_url":""},{
"name":"\u7ea2\u70e7\u6392\u9aa8","id":"5884","ju":"recipes:\/\/www.douguo.com\/search?key=\u7ea2\u70e7\u6392\u9aa8&_vs=400","cs":[],"image_url":""},{
"name":"\u54b8","id":"478","ju":"recipes:\/\/www.douguo.com\/search?key=\u54b8&_vs=400","cs":[],"image_url":""},{
"name":"\u81ed\u5473","id":"483","ju":"recipes:\/\/www.douguo.com\/search?key=\u81ed\u5473&_vs=400","cs":[],"image_url":""},{
"name":"\u82e6","id":"479","ju":"recipes:\/\/www.douguo.com\/search?key=\u82e6&_vs=400","cs":[],"image_url":""},{
"name":"\u9c9c","id":"5878","ju":"recipes:\/\/www.douguo.com\/user?id=23162809&tab=1","cs":[],"image_url":""}],"image_url":""}],"image_url":""}],"ads":[{
"dsp":{
"id":"ad5671","pid":"6080244867596723","ch":1,"url":"","i":"","cap":"\u5e7f\u544a","position":"1recipecategory","query":"","client_ip":"","req_min_i":60,"channel":"","media_type":0,"request_count":1,"max_impression_count":0,"name":"\u840c\u840c\u54d2\u63a8\u5e7f\u5458","logo":"http:\/\/i1.douguo.net\/upload\/\/photo\/2\/1\/1\/70_215540a4a78ff0584e3f41d2de1a7191.jpg","user":{
"nick":"\u840c\u840c\u54d2\u63a8\u5e7f\u5458","user_photo":"http:\/\/i1.douguo.net\/upload\/\/photo\/2\/1\/1\/70_215540a4a78ff0584e3f41d2de1a7191.jpg","lvl":7,"user_id":23010754},"show":0,"ximage":"","canclose":0},"cid":"18"}]}}
输出结果过多,省略部分结果,然后把获取到的结果用 json 格式化数据即可观看具体的数据内容。
3.3.3 对全部栏目抓取到的 Json 进行解析
接下来,我就要抓取到的 json 进行数据解析,在解析之前我们需要进行数据的分析:我们可以看见全部的数据结果其实是在 result 里面的 cs 里面,如下图所示:

我们折叠起来的之后,可以知道一共有 14 个栏目,而对应的 Json 也是 14,如下图:

这也就是我们要遍历的数据,接下来我们再来看看里面的结构:

那目前就是:result->cs->cs->cs,所以我们目前的解析代码就可以写成如下:
import json
def parse_flatcatalogs(self, html):
"""
:param html: Parse target text
:return:
"""
json_content = json.loads(html)['result']['cs']
for index_items in json_content:
for index_item in index_items['cs']:
for item in index_item['cs']:
print(item)
运行结果如下:
C:\Users\clela\AppData\Local\Programs\Python\Python37\python.exe "C:/Code/pycharm_daima/实战项目代码/豆果 App/Spider_douguo.py"
{
'name': '红烧肉', 'id': '5915', 'ju': 'recipes://www.douguo.com/search?key=红烧肉&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '可乐鸡翅', 'id': '5916', 'ju': 'recipes://www.douguo.com/search?key=可乐鸡翅&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '糖醋排骨', 'id': '5917', 'ju': 'recipes://www.douguo.com/search?key=糖醋排骨&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '鱼香肉丝', 'id': '5918', 'ju': 'recipes://www.douguo.com/search?key=鱼香肉丝&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '宫保鸡丁', 'id': '5919', 'ju': 'recipes://www.douguo.com/search?key=宫保鸡丁&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '红烧排骨', 'id': '5920', 'ju': 'recipes://www.douguo.com/search?key=红烧排骨&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '怪味', 'id': '482', 'ju': 'recipes://www.douguo.com/search?key=怪味&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '苦', 'id': '479', 'ju': 'recipes://www.douguo.com/search?key=苦&_vs=400', 'cs': [], 'image_url': ''}
{
'name': '鲜', 'id': '5878', 'ju': 'recipes://www.douguo.com/user?id=23162809&tab=1', 'cs': [], 'image_url': ''}
输出结果过多,这里省略部分结果。
3.3.4 编写详情页的 Data
我们接下来要如何操作呢?
我们接下来不就是为了获取每个详情页嘛,不过我们还是以开头的土豆来写,我还是把抓取到的土豆的数据包复制出来分析:
client=4&_session=1590129789130355757944762497&keyword=%E5%9C%9F%E8%B1%86&order=0&_vs=11102&type=0&auto_play_mode=2&sign_ran=c7d28e4120793b7687e6f13b0e0df1d8&code=9a4596275dd6d8c1
这里,为什么只留 client 呢?其他的请求头其实前面已经分析并构造好了,而 url 也没什么好分析的,请求模式一看也就都知道 POST 请求,所以接下来我们来分析 client,我有两种方法对上面的 client 除了一个是 Python 代码的方法,如下:
from urllib import parse
str_txt = 'client=4&_session=1590129789130355757944762497&keyword=%E5%9C%9F%E8%B1%86&order=0&_vs=11102&type=0&auto_play_mode=2&sign_ran=c7d28e4120793b7687e6f13b0e0df1d8&code=9a4596275dd6d8c1'
result = parse.unquote(str_txt)
print(result)
运行结果:
client=4&_session=1590129789130355757944762497&keyword=土豆&order=0&_vs=11102&type=0&auto_play_mode=2&sign_ran=c7d28e4120793b7687e6f13b0e0df1d8&code=9a4596275dd6d8c1
方法二使用 Fiddler 操作如下动图:
3.3.5 为什么不构造 url(api)呢?
这里有同学会问了,为什么只看 client 而不可 url(api)呢?
这是因为,这个 api 是豆果或者其他 App 也类似,你找到这个借口之后,你传入的 data 数据不一样,它给你放回的数据也是不一样的,具体操作同学们可以换一个栏目然后进行抓包,比如我这里选择了:水产海鲜->基围虾:
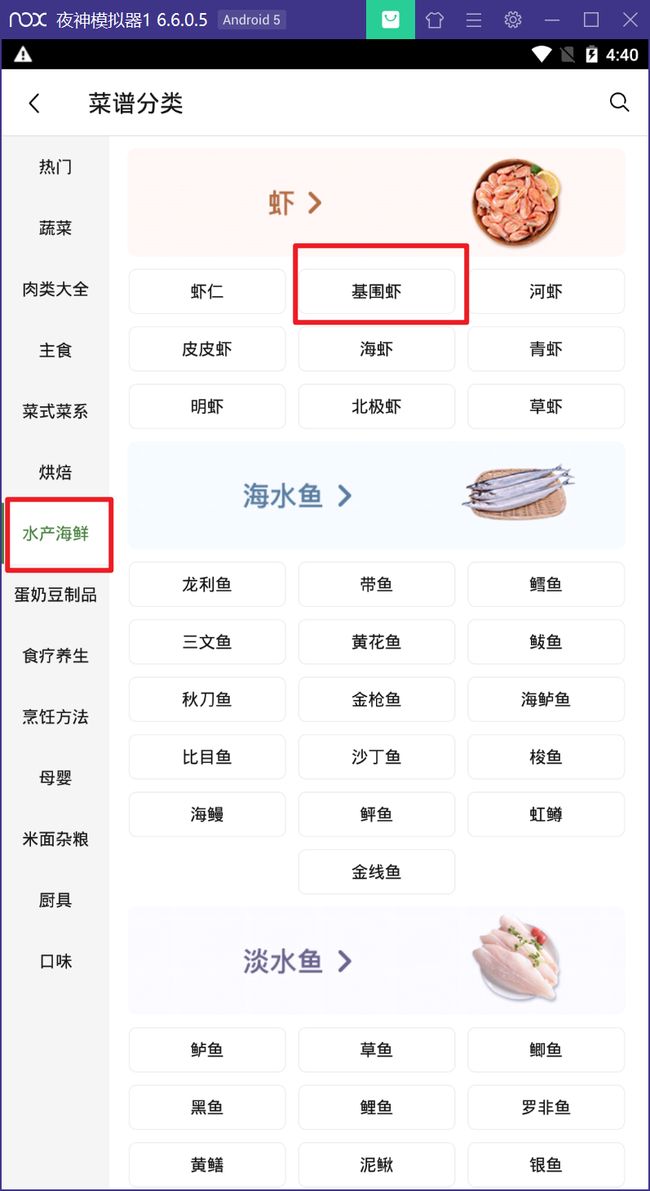
然后选择菜谱->学做多:

最终,我们滑动界面并抓包,抓包结果如下所示:

格式化都得结果:
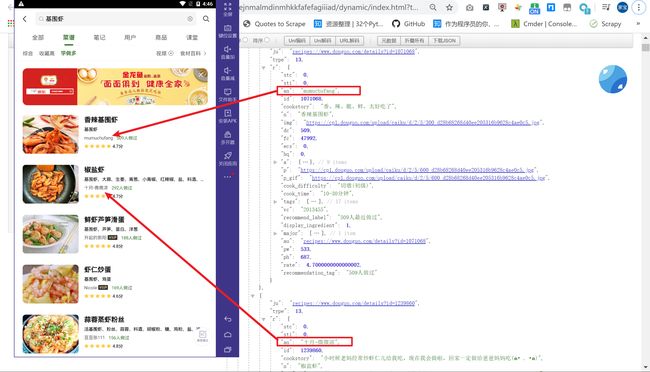
这也就是为什么只看 client 的原因了,接下来我们上面的,我把解析之后的 client 构造成字典,上面已经演示过了,这里就不做过多的演示。
3.3.6 构造 data 成字典
构造结果如下:
"client":"4",
# "_session":"1590129789130355757944762497",
"keyword":"土豆",
"order":"0",
"_vs":"11102",
"type":"0",
"auto_play_mode":"2",
"sign_ran":"c7d28e4120793b7687e6f13b0e0df1d8",
"code":"9a4596275dd6d8c1",
并编写如代码:
def __init__(self):
self.headers = HEADERS
# self.url = DETAIL_API_URL
self.index_data = {
"client": "4",
# "_session": "1590028187496355757944762497",
# "v": "1590023768",# 时间戳,也就是你请求数据的时间
"_vs": "2305",
"sign_ran": "94b96c996a4a222540e435ee06ef133a",
"code": "b366f93caa7bac04",
}
self.detail_data = {
"client":"4",
# "_session":"1590129789130355757944762497",
"keyword":"土豆",
"order":"0",
"_vs":"11102",
"type":"0",
"auto_play_mode":"2",
"sign_ran":"c7d28e4120793b7687e6f13b0e0df1d8",
"code":"9a4596275dd6d8c1",
}
我们需要修改 self.detail_data 修改 keyword,当然上面的 data 如果可以再次进行优化,欢迎你点击阅读原文留言给我鸭,之后会出抖音等 App 爬虫。
所以,修改成如下代码:
self.detail_data = {
"client":"4",
# "_session":"1590129789130355757944762497",
"keyword": None,
"order":"0",
"_vs":"11102",
"type":"0",
"auto_play_mode":"2",
"sign_ran":"c7d28e4120793b7687e6f13b0e0df1d8",
"code":"9a4596275dd6d8c1",
}
接下来也修改一下函数:parse_flatcatalogs
def parse_flatcatalogs(self, html):
"""
:param html: Parse target text
:return:
"""
json_content = json.loads(html)['result']['cs']
for index_items in json_content:
for index_item in index_items['cs']:
for item in index_item['cs']:
self.detail_data['keyword'] = item['name']
print(self.detail_data)
运行结果如下,结果过多,这里省略部分结果:
{
'client': '4', 'keyword': '红烧肉', 'order': '0', '_vs': '11102', 'type': '0', 'auto_play_mode': '2', 'sign_ran': 'c7d28e4120793b7687e6f13b0e0df1d8', 'code': '9a4596275dd6d8c1'}
{
'client': '4', 'keyword': '可乐鸡翅', 'order': '0', '_vs': '11102', 'type': '0', 'auto_play_mode': '2', 'sign_ran': 'c7d28e4120793b7687e6f13b0e0df1d8', 'code': '9a4596275dd6d8c1'}
{
'client': '4', 'keyword': '糖醋排骨', 'order': '0', '_vs': '11102', 'type': '0', 'auto_play_mode': '2', 'sign_ran': 'c7d28e4120793b7687e6f13b0e0df1d8', 'code': '9a4596275dd6d8c1'}
{
'client': '4', 'keyword': '鱼香肉丝', 'order': '0', '_vs': '11102', 'type': '0', 'auto_play_mode': '2', 'sign_ran': 'c7d28e4120793b7687e6f13b0e0df1d8', 'code': '9a4596275dd6d8c1'}
{
'client': '4', 'keyword': '宫保鸡丁', 'order': '0', '_vs': '11102', 'type': '0', 'auto_play_mode': '2', 'sign_ran': 'c7d28e4120793b7687e6f13b0e0df1d8', 'code': '9a4596275dd6d8c1'}
3.3.7 构造队列&提交数据到队列
我们构造 data 成功了,接下来我们需要的是使用多线程,所以,我们就需要一个队列,所以这里就需要引入如下库:
from multiprocessing import Queue
# 创建队列
queue_list = Queue()
这样,我们的队列就创建成功了,那接下来我们就可以把我们的数据提交到我的队列当中去,也就是我们把我们的 self.detail_data 提交到,我们的队列当中,代码如下:queue_list.put(self.detail_data)
def parse_flatcatalogs(self, html):
"""
:param html: Parse target text
:return:
"""
json_content = json.loads(html)['result']['cs']
for index_items in json_content:
for index_item in index_items['cs']:
for item in index_item['cs']:
self.detail_data['keyword'] = item['name']
# print(self.detail_data)
queue_list.put(self.detail_data)
print(queue_list.qsize()) # 查看队列中有多少数据
3.3.8 获取菜谱列表
前面我们获取到了各种食材,接下来就是要获取每一个食材的菜谱(做过最多),选取菜谱的 api,如下图:

recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
编写函数:
def the_recipe(self, data):
"""
抓取菜谱数据
:return:
"""
print(f"当前出处理的食材: {data['keyword']}")
recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
response = self.request(url = recipe_api, data = data).text
# return response
print(response)
修改 main 函数进行修改测试:
def main(self):
# url = 'http://api.douguo.net/recipe/v2/search/0/20'
url = 'http://api.douguo.net/recipe/flatcatalogs'
html = self.request(url = url, data = self.index_data).text
# print(html)
self.parse_flatcatalogs(html)
# print(queue_list.get())
self.the_recipe(data = queue_list.get())
测试运行结果,结果过多,展示部分结果:
当前出处理的食材: 可乐鸡翅
{
"state":"success","result":{
"sts":["\u53ef\u4e50\u9e21\u7fc5"],"hidden_sorting_tags":0,"list":[{
"ju":"recipes:\/\/www.douguo.com\/details?id=206667","type":13,"r":{
"stc":0,"sti":0,"an":"stta\u5c0f\u94ed","id":206667,"cookstory":"","n":"\u53ef\u4e50\u9e21\u7fc5[\u7b80\u5355\u5230\u6ca1\u4e0b\u8fc7\u53a8\u4e5f\u4f1a\u505a]","img":"https:\/\/cp1.douguo.com\/upload\/caiku\/8\/f\/c\/300_8f6d0f8b7195c0397c92fe39643761fc.jpg","dc":16948,"fc":34462,"ecs":1,"hq":0,"a":{
"id":2042182,"n":"stta\u5c0f\u94ed","v":1,"verified_image":"","progress_image":"","p":"http:\/\/tx1.douguo.net\/upload\/photo\/4\/0\/3\/70_u49617908834149171436.jpg","lvl":6,"is_prime":false,"lv":0},"p":"https:\/\/cp1.douguo.com\/upload\/caiku\/8\/f\/c\/600_8f6d0f8b7195c0397c92fe39643761fc.jpg","p_gif":"https:\/\/cp1.douguo.com\/upload\/caiku\/8\/f\/c\/600_8f6d0f8b7195c0397c92fe39643761fc.jpg","cook_difficulty":"\u5207\u58a9(\u521d\u7ea7)","cook_time":"10~30\u5206\u949f","tags":[{
"t":"\u665a\u9910"},{
"t":"\u5348\u9910"},{
"t":"\u7092\u9505"},{
"t":"\u9505\u5177"},{
"t":"\u70ed\u83dc"},{
"t":"\u54b8\u751c"},
当然,我们可以把该数据进行 Json 格式化,如下结果:

我们把对应做的最多的,可乐鸡翅拿来对比一下:

表明数据抓取正常,这里我们可以继续点进去看详情介绍,因为第一条没有详情介绍,这里我点击第二天:

我们再打开第三个进行验证,不过我这里第三个又是没有介绍的:

所以只能点击第四个看有没有有了,结果第四个也没有,到第五个有了,对比如下:

所以,可以知道我们的请求是没有问题的,我们接下来继续操作,也就是进行所获取到的数据进行解析,所需的数据如同所示:

def the_recipe(self, data):
"""
抓取菜谱数据
:return:
"""
print(f"当前出处理的食材: {data['keyword']}")
recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
response = self.request(url = recipe_api, data = data).text
# print(response)
recipe_list = json.loads(response)['result']['list']
# print(type(recipe_list))
for item in recipe_list:
print(item)
运行结果,数据较多,也是省略部分数据:
当前出处理的食材: 地三鲜
'https://cp1.douguo.com/upload/caiku/5/0/4/600_50d4ffc003fd4b43449cb0d8ed902174.jpg', 'p_gif': 'https://cp1.douguo.com/upload/caiku/5/0/4/600_50d4ffc003fd4b43449cb0d8ed902174.jpg', 'cook_difficulty': '切墩(初级)', 'cook_time': '10-30分钟', 'tags': [{
't': '东北菜'}, {
't': '炸'}, {
't': '炒'}, {
't': '咸'}, {
't': '下饭菜'}, {
't': '快手菜'}, {
't': '热菜'}, {
't': '素菜'}, {
't': '锅具'}, {
't': '炒锅'}, {
't': '午餐'}, {
't': '晚餐'}, {
't': '中国菜'}], 'vc': '15733890', 'recommend_label': '1495人最近做过', 'display_ingredient': 1, 'major': [{
'note': '适量', 'title': '茄子'}, {
'note': '一个', 'title': '土豆'}, {
'note': '各一根', 'title': '青红椒'}, {
'note': '适量', 'title': '葱姜蒜'}], 'au': 'recipes://www.douguo.com/details?id=975713', 'pw': 799, 'ph': 450, 'rate': 4.7, 'recommendation_tag': '1495人做过'}}
{
'ju': 'recipes://www.douguo.com/details?id=1396536', 'type': 13, 'r': {
'stc': 0, 'sti': 0, 'an': '咫尺光年-爱如初见', 'id': 1396536, 'cookstory': '这道地三鲜是我的拿手菜,想当初学这道菜的时候老公每天都试吃这菜,做了几次终于成功了。老公说再也不用吃不正宗的了,哈哈。这个味道就是外面饭店的味道。', 'n': '地三鲜~在家也能做出饭店的味道', 'img': 'https://cp1.douguo.com/upload/caiku/7/1/5/300_71c899c8795448414aaf426aa910a335.jpg', 'dc': 784, 'fc': 84217, 'ecs': 0, 'hq': 0, 'a': {
'id': 10146188, 'n': '咫尺光年-爱如初见', 'v': 1, 'verified_image': '', 'progress_image': '', 'p': 'http://tx1.douguo.net/upload/photo/1/0/e/70_u3574750219030220248.jpg', 'lvl': 7, 'is_prime': False, 'lv': 0}, 'p': 'https://cp1.douguo.com/upload/caiku/7/1/5/600_71c899c8795448414aaf426aa910a335.jpg', 'p_gif': 'https://cp1.douguo.com/upload/caiku/7/1/5/600_71c899c8795448414aaf426aa910a335.jpg', 'cook_difficulty': '切墩(初级)', 'cook_time': '10-30分钟', 'tags': [{
't': '咸鲜'}, {
't': '咸'}, {
't': '炒'}, {
't': '东北菜'}, {
't': '中国菜'}], 'vc': '2967774', 'recommend_label': '784人最近做过', 'display_ingredient': 1, 'major': [{
'note': '一个', 'title': '长茄子'}, {
'note': '一个', 'title': '土豆'}, {
'note': '一个', 'title': '青椒'}, {
'note': '1/3个', 'title': '彩椒'}, {
'note': '若干', 'title': '蒜'}, {
'note': '两颗', 'title': '葱'}, {
'note': '适量', 'title': '花生油'}, {
'note': '一勺', 'title': '生抽'}, {
'note': '1/3勺', 'title': '红烧酱油'}, {
'note': '两勺', 'title': '淀粉'}, {
'note': '半勺', 'title': '醋'}, {
'note': '一勺', 'title': '白糖'}, {
'note': '适量', 'title': '盐'}, {
'note': '半碗', 'title': '清水'}], 'au': 'recipes://www.douguo.com/details?id=1396536', 'pw': 800, 'ph': 800, 'rate': 4.8, 'recommendation_tag': '784人做过'}}
不过,我们会发现有广告,那之后我们可以把广告去掉。
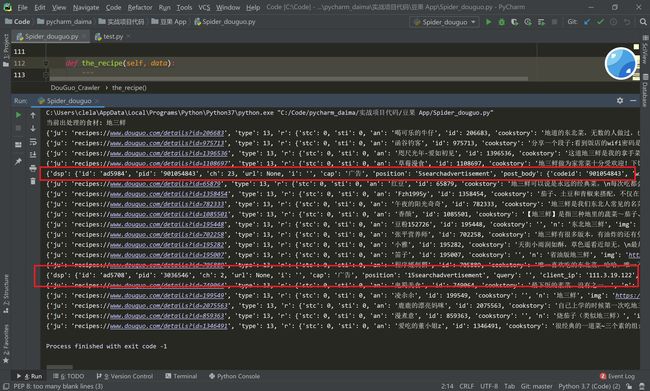
接下来,把数据返回类型为字典,我还能分析发现:type 为 13 的时候,就是我们所需要的菜谱,把需要的数据提取出来即可:

所以代码如下:
def the_recipe(self, data):
"""
抓取菜谱数据
:return:
"""
print(f"当前出处理的食材: {data['keyword']}")
recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
response = self.request(url = recipe_api, data = data).text
# print(response)
recipe_list = json.loads(response)['result']['list']
# print(type(recipe_list))
for item in recipe_list:
# recipe_info : 菜谱信息
recipe_info = {
}
recipe_info['食材'] = data['keyword']
if item['type'] == 13:
recipe_info['user_name'] = item['r']['an'] # 用户名称
recipe_info['recipe_id'] = item['r']['id']
recipe_info['cookstory'] = item['r']['cookstory'].strip()
recipe_info['recipe_name'] = item['r']['n']
recipe_info['major'] = item['r']['major']
print(recipe_info)
else:
continue
不过要注意的是,上面提取的 ID 经过我前期的分析是食材的 ID,并不是用户的 id 而是菜谱的 id,那为什么要保留它呢?因为,后面我还需要请求一个 api 请求什么呢?
也就是我们目前抓取到的数据,里面并没有 做法 ,同学们自行对比哈。
那这个做法在哪呢?
也就是说,这里还有一个数据包,我们没有抓取到,待会我们再次请求做法的时候抓包看一下该做法的数据包时怎样的。所以,我们需要先把这个 id 留着。
3.3.9 抓包——recipe 烹饪方法
接下来,我们打开我们的 Fiddler 重新抓包,APP 里面直接停留在菜谱列表里面,直接进行抓包。最终我们抓取到了如下数据包:
表明这就是我们需要的数据包:

3.3.9.1 构造烹饪方法 url
所以我们接下来就来把这个请求编写成爬虫,我们把 API 复制出来:
http://api.douguo.net/recipe/detail/1091474
上面的 1091474 其实就是我们保存的上面保存的 id,然后构造 url:
detaile_cookstory_url = 'http://api.douguo.net/recipe/detail/{id}'.format(id = recipe_info['recipe_id'])
3.3.9.2 构造烹饪方法的 data
那接下来我们要构造一下 data 的数据,也是把它复制下来,并进行解码:

# 解码之前
client=4&_session=1590191363409355757944762497&author_id=0&_vs=11101&_ext=%7B%22query%22%3A%7B%22kw%22%3A%22%E7%BA%A2%E7%83%A7%E8%82%89%22%2C%22src%22%3A%2211101%22%2C%22idx%22%3A%221%22%2C%22type%22%3A%2213%22%2C%22id%22%3A%221091474%22%7D%7D&is_new_user=1&sign_ran=fa68eee8c3458c196bd65c15c4b06c3b&code=e5cf0cdca6a10f39
# 解码之后
client=4&_session=1590191363409355757944762497&author_id=0&_vs=11101&_ext={
"query":{
"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}&is_new_user=1&sign_ran=fa68eee8c3458c196bd65c15c4b06c3b&code=e5cf0cdca6a10f39
优化:
client=4&_session=1590191363409355757944762497&author_id=0&_vs=11101&_ext={
"query":{
"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}
也是构造成字典:
"client":"4",
"_session":"1590191363409355757944762497",
"author_id":"0",
"_vs":"11101",
"_ext":"{"query":{"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}",
我们还需要对上面的 "{"query":{"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}", 进优化,显示的不正常:

也就语法错误,把双引号换成单引号即可,修改成如下:
'{"query":{"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}'
最终我们的 cookstory_data 如下:
cookstory_data = {
"client": "4",
"_session": "1590191363409355757944762497",
"author_id": "0",
"_vs": "11101",
"_ext": '{"query":{"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}',
}
而我们的 session 不需要我们可以注释掉,而我们的 id 、kw 是不断变化的,其他的我们不做变更,因为你通过几次抓包就会知道,它其实是一样的。这里为了满足懒惰的小白,我随机选择一道菜谱再次进行抓包。
3.3.9.3 对比 data 的不变的数据
我们再来看看它的数据:
# 解码之前:
client=4&_session=1590361734034355757944762497&author_id=0&_vs=11101&_ext=%7B%22query%22%3A%7B%22kw%22%3A%22%E7%BA%B8%E6%9D%AF%E8%9B%8B%E7%B3%95%22%2C%22src%22%3A%2211101%22%2C%22idx%22%3A%221%22%2C%22type%22%3A%2213%22%2C%22id%22%3A%221204922%22%7D%7D&is_new_user=1&sign_ran=a866cb568112ed9fd859fc2689fa0aaa&code=3ca60fe2ceb34663
# 解码之后:
client=4&_session=1590361734034355757944762497&author_id=0&_vs=11101&_ext={
"query":{
"kw":"纸杯蛋糕","src":"11101","idx":"1","type":"13","id":"1204922"}}&is_new_user=1&sign_ran=a866cb568112ed9fd859fc2689fa0aaa&code=3ca60fe2ceb34663
我们来进行对比一下上面的红烧肉的数据:
# 红烧肉
client=4&_session=1590191363409355757944762497&author_id=0&_vs=11101&_ext={
"query":{
"kw":"红烧肉","src":"11101","idx":"1","type":"13","id":"1091474"}}&is_new_user=1&sign_ran=fa68eee8c3458c196bd65c15c4b06c3b&code=e5cf0cdca6a10f39
# 纸杯蛋糕
client=4&_session=1590361734034355757944762497&author_id=0&_vs=11101&_ext={
"query":{
"kw":"纸杯蛋糕","src":"11101","idx":"1","type":"13","id":"1204922"}}&is_new_user=1&sign_ran=a866cb568112ed9fd859fc2689fa0aaa&code=3ca60fe2ceb34663
可以,观察出确实是除了 kw、id 之外,src、type 等数据是不变的。
这个时候有同学可能会自己会在课下进行对比,发现 idx 这个数字有时候会不一样,我这里先做回答:
答:可能豆果美食升级后做了改动,抓包后,通过 python 去构造,注释掉一部分参数,也可以请求到数据,那么就不必去关心他变还是不变了,或者你在请求时,1是A结果,2是B结果。(也经过我的测试目前 idx 不用修改数据也是准确的。
3.3.9.4 编写代码
def the_recipe(self, data):
"""
抓取菜谱数据
:return:
"""
print(f"当前出处理的食材: {data['keyword']}")
recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
response = self.request(url = recipe_api, data = data).text
# print(response)
recipe_list = json.loads(response)['result']['list']
# print(type(recipe_list))
for item in recipe_list:
# recipe_info : 菜谱信息
recipe_info = {
}
recipe_info['食材'] = data['keyword']
if item['type'] == 13:
recipe_info['user_name'] = item['r']['an'] # 用户名称
recipe_info['recipe_id'] = item['r']['id']
recipe_info['cookstory'] = item['r']['cookstory'].strip()
recipe_info['recipe_name'] = item['r']['n']
recipe_info['major'] = item['r']['major']
# print(recipe_info)
detaile_cookstory_url = 'http://api.douguo.net/recipe/detail/{id}'.format(id = recipe_info['recipe_id'])
# print(detaile_cookstory_url)
cookstory_data = {
"client": "4",
# "_session": "1590191363409355757944762497",
"author_id": "0",
"_vs": "11101",
"_ext": '{"query":{"kw":"%s","src":"11101","idx":"1","type":"13","id":"%s"}}'%(str(data['keyword']), str(recipe_info['recipe_id'])),
}
recipe_detail_resopnse = self.request(url = detaile_cookstory_url, data = cookstory_data).text
# print(recipe_detail_resopnse)
detaile_response_dict = json.loads(recipe_detail_resopnse)
recipe_info['tips'] = detaile_response_dict['result']['recipe']['tips']
recipe_info['cook_step'] = detaile_response_dict['result']['recipe']['cookstep']
logger.info(f'当前的 recipe_info:>>>{recipe_info}')
# logger.info('当前入库的数据')
else:
continue
运行结果如下,省略部分结果:
当前出处理的食材: 可乐鸡翅
2020-05-25 16:45:07,613 - __main__ - INFO - 当前的 recipe_info:>>>{
'食材': '可乐鸡翅', 'user_name': 'stta小铭', 'recipe_id': 206667, 'cookstory': '', 'recipe_name': '可乐鸡翅[简单到没下过厨也会做]', 'major': [{
'note': '10个', 'title': '鸡翅'}, {
'note': '一片', 'title': '姜'}, {
'note': '两根', 'title': '葱'}, {
'note': '一瓶易拉罐', 'title': '可乐'}, {
'note': '三汤匙', 'title': '酱油(味极鲜)'}], 'tips': '鸡翅用刀子或者叉子扎扎更容易入味,有功夫的话可以提前腌制,腌制有条件的话加几滴柠檬汁有加分哦。不用加盐巴,腌制可以用料酒和酱油,酱油生抽老抽无所谓,腌制20分钟以上就可以。\n--------------------------------------------------------\n常见问题问答:\n\n问:放不放盐巴?\n答:酱油里面含有盐分了。\n\n问:请问酱油是用生抽还是老抽?\n答:本文所用酱油为“味极鲜”\n\n问:鸡翅需要提前腌制吗?怎么腌?\n答:少许酱油和料酒腌制就可以了。\n\n问:我腌制的时候放了酱油了,煮的时候还要放吗?\n答:要!\n\n问:请问鸡翅需要焯水吗?\n答:如果您的鸡翅中间是白色,没有红色或者黑色血块,那可以不需要。反之则需要。\n\n问:不焯水不就很脏?\n答:请冲洗。\n\n问:请用问什么可乐好?\n答:便宜的那个。\n\n---------------------------------------------------------------------\n这道菜口味偏甜\n如果您是云贵川、或者西部的朋友,您可以加点辣椒(请勿加花椒)\n\n如果您是北方的朋友尤其是山东的朋友,200毫升的可乐请换成100毫升可乐+100毫升料酒\n---------------------------------------------------------------------\n感慨一下\n\n今天根据自己的菜谱做了一次,果然好简单,菜谱的做法也没问题。\n\n发布菜谱到现在,好不容易从料理小白,到厨师,到西餐主厨,日料主厨。真的喜欢做菜,有你们真好!有豆果真好!', 'cook_step': [{
'position': '1', 'content': '锅底放点油爆香姜和葱白', 'thumb': 'https://cp1.douguo.com/upload/caiku/f/6/1/140_f6ebfcafae6e4aa5b7f3e367f26b04b1.jpg', 'image_width': 640, 'image_height': 480, 'image': 'https://cp1.douguo.com/upload/caiku/f/6/1/800_f6ebfcafae6e4aa5b7f3e367f26b04b1.jpg'}, {
'position': '2', 'content': '放入鸡翅翻炒到发白,加入可乐和酱油,盖上锅盖', 'thumb': 'https://cp1.douguo.com/upload/caiku/d/a/4/140_da0d38fa2c885b8e829d17b1dcbbbd34.jpg', 'image_width': 640, 'image_height': 480, 'image': 'https://cp1.douguo.com/upload/caiku/d/a/4/800_da0d38fa2c885b8e829d17b1dcbbbd34.jpg'}, {
'position': '3', 'content': '中火煮到收汁就行', 'thumb': 'https://cp1.douguo.com/upload/caiku/1/b/3/140_1b122a5b97b867d9119caf2274e413c3.jpg', 'image_width': 640, 'image_height': 480, 'image': 'https://cp1.douguo.com/upload/caiku/1/b/3/800_1b122a5b97b867d9119caf2274e413c3.jpg'}]}
2020-05-25 16:45:12,295 - __main__ - INFO - 当前的 recipe_info:>>>{
'食材': '可乐鸡翅', 'user_name': '葉子的爱与厨房', 'recipe_id': 201871, 'cookstory': '这道菜太值得推荐了,别说孩子喜欢,老人也会喜欢吃。而且非常适合减肥人士,因为一滴油都不需要放喔。我的外甥女第一次吃这鸡翅的时候,破天荒的吃了7个鸡翅,吓的我妈妈一直在喊:不能吃了不能吃了。还有我那3岁半的干儿子,挑食挑的头疼,但是吃了这个,连汤汁都不放过,拌了一小碗米饭吃的干干净净。 \n\n 所以,要是家里有个吃饭费劲的孩子,就动手试试这个吧。在寒冷的冬日,要是把它端上桌,不知有多合适了。还真别低估了它的魅力!这个真的比普通的可乐鸡翅好吃的多!', 'recipe_name': '可乐鸡翅(无油加姜版)', 'major': [{
'note': '400g', 'title': '鸡中翅'}, {
'note': '15g', 'title': '姜'}, {
'note': '1罐', 'title': '可乐'}, {
'note': '半个', 'title': '柠檬'}, {
'note': '2勺', 'title': '生抽'}, {
'note': '1勺', 'title': '老抽'}, {
'note': '2g', 'title': '糖(可不放)'}, {
'note': '2g', 'title': '盐'}], 'tips': '1,鸡翅扎眼和切口都是为了让鸡翅更入味。 \n2,用柠檬汁是为了去腥,也能更好的软化肉质。缩短煎的时间。并且增加口味。效果非常好 \n3,煎的时候正面先朝下。不过一定要不粘锅的锅喔。 \n4,鸡翅会自己出很多油,所以千万不要再放油了。油是足够的。 \n5,糖不要加多,因为可乐里糖分已经很重。怕甜的也可以不放糖 \n6,姜可以大胆多放些,因为可乐和姜的味道一融合就会让你受宠若惊。 \n7,撇掉锅里的泡沫,除了用勺子。也可以准备一小张锡纸,用手捏皱,然后打开放进去注意下。拿出来泡沫就 被吸在锡纸的褶皱里了,很简便的一种方法。 \n8,中火可以多煮一下,这样可以更入味。然后大火收汁,可乐里含糖分,很快会收干的。 \n9,汤汁拌点米饭,也特别好吃喔。', 'cook_step': [{
'position': '1', 'content': '把鸡中翅洗干净,沥水。或用厨房纸巾吸干水分,在鸡翅正面用叉子叉些眼(有鸡皮疙瘩的一面),在鸡翅背面用小刀横切2道小口 \n把姜切成姜丝3MM宽的姜丝。不要太细\n鸡翅放进一个大碗里,然后用手捏柠檬,尽量挤出柠檬汁,拌匀,放置3--5分钟', 'thumb': 'https://cp1.douguo.com/upload/caiku/b/f/b/140_bf8213a5b765c86f9acdbb6f09bc4f1b.jpg', 'image_width': 1600, 'image_height': 1200, 'image': 'https://cp1.douguo.com/upload/caiku/b/f/b/800_bf8213a5b765c86f9acdbb6f09bc4f1b.jpg'}, {
'position': '2', 'content': '拿不粘锅的平底锅,加热后,直接放入鸡翅,有鸡皮疙瘩的一面先朝下', 'thumb': 'https://cp1.douguo.com/upload/caiku/9/1/2/140_91dca0da2408ee6a51e34600a36b9242.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/9/1/2/800_91dca0da2408ee6a51e34600a36b9242.jpg'}, {
'position': '3', 'content': '出油后,翻面煎', 'thumb': 'https://cp1.douguo.com/upload/caiku/4/6/2/140_46b090e16b541d87597d893f14e021c2.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/4/6/2/800_46b090e16b541d87597d893f14e021c2.jpg'}, {
'position': '4', 'content': '然后可以像我图中一样,尽量煎一下鸡翅的侧面,待双面鸡翅油差不多都出来,一直煎到两面金黄', 'thumb': 'https://cp1.douguo.com/upload/caiku/d/0/d/140_d0d236c86bd23dd50a099e1395397bbd.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/d/0/d/800_d0d236c86bd23dd50a099e1395397bbd.jpg'}, {
'position': '5', 'content': '放入切好的姜丝,和鸡翅一起翻炒一下,大约30秒', 'thumb': 'https://cp1.douguo.com/upload/caiku/2/9/7/140_297dadc823cf0fdd60fb93ac4c588e97.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/2/9/7/800_297dadc823cf0fdd60fb93ac4c588e97.jpg'}, {
'position': '6', 'content': '倒入可乐,刚刚和鸡翅一样平或稍微没过鸡翅都可以。放盐,糖,生抽,老抽 。', 'thumb': 'https://cp1.douguo.com/upload/caiku/2/f/2/140_2f02fab255f69267708c2d37479d4922.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/2/f/2/800_2f02fab255f69267708c2d37479d4922.jpg'}, {
'position': '7', 'content': '撇掉锅里的泡沫', 'thumb': 'https://cp1.douguo.com/upload/caiku/d/1/2/140_d11065f96e24b947ddcf6d0b4deb4752.jpg', 'image_width': 800, 'image_height': 600, 'image': 'https://cp1.douguo.com/upload/caiku/d/1/2/800_d11065f96e24b947ddcf6d0b4deb4752.jpg'}, {
'position': '8', 'content': '中火煮10分钟左右。然后大火收汁即可', 'thumb': 'https://cp1.douguo.com/upload/caiku/f/e/7/140_fe29798d4cd536b447f1aea295371c77.jpg', 'image_width': 670, 'image_height': 446, 'image': 'https://cp1.douguo.com/upload/caiku/f/e/7/800_fe29798d4cd536b447f1aea295371c77.jpg'}]}
2020-05-25 16:45:13,519 - __main__ - INFO - 当前的 recipe_info:>>>{
'食材': '可乐鸡翅', 'user_name': '拾光机', 'recipe_id': 1070655, 'cookstory': '良心保证,一个步骤做出超好吃可乐鸡翅!一个步骤就是——打开电饭锅,放进材料,按下煮饭键!是不是很简单!材料用量也很很好掌握,鸡翅按根来算,可乐买500毫升的小瓶装,连酱油、料酒和油都是用陶瓷汤匙来量取,我就不信还会有人做失败!', 'recipe_name': '电饭锅版可乐鸡翅', 'major': [{
'note': '1小瓶(500ML)', 'title': '可乐'}, {
'note': '8根', 'title': '鸡翅'}, {
'note': '2汤匙', 'title': '酱油'}, {
'note': '8片', 'title': '生姜'}, {
'note': '1汤匙', 'title': '米酒或料酒'}, {
'note': '1汤匙', 'title': '油'}], 'tips': '不用加盐,酱油带咸味了。用普通酱油就行。', 'cook_step': [{
'position': '1', 'content': '鸡翅洗净,生姜切片。', 'thumb': 'https://cp1.douguo.com/upload/caiku/8/5/9/140_85dc807a52611577111a41f624c274f9.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/8/5/9/800_85dc807a52611577111a41f624c274f9.jpg'}, {
'position': '2', 'content': '在电饭锅里倒入1汤匙食用油,放进姜片抹匀油。', 'thumb': 'https://cp1.douguo.com/upload/caiku/2/9/e/140_2984b75726ab83d613a8ec9bdc47c64e.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/2/9/e/800_2984b75726ab83d613a8ec9bdc47c64e.jpg'}, {
'position': '3', 'content': '放进鸡翅。姜片要放在鸡翅底下,去腥,防止粘锅。', 'thumb': 'https://cp1.douguo.com/upload/caiku/6/5/a/140_65581e3a3cf1c590e2456cc0f8be6c5a.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/6/5/a/800_65581e3a3cf1c590e2456cc0f8be6c5a.jpg'}, {
'position': '4', 'content': '加入1小瓶(500ml)可乐,确保可乐没过鸡翅。', 'thumb': 'https://cp1.douguo.com/upload/caiku/4/d/6/140_4dbfef984db6d25341b969f92d3136d6.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/4/d/6/800_4dbfef984db6d25341b969f92d3136d6.jpg'}, {
'position': '5', 'content': '加2汤匙酱油,1汤匙料酒。', 'thumb': 'https://cp1.douguo.com/upload/caiku/1/5/e/140_156df43cd12523824965719c22d387be.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/1/5/e/800_156df43cd12523824965719c22d387be.jpg'}, {
'position': '6', 'content': '按下煮饭键。', 'thumb': 'https://cp1.douguo.com/upload/caiku/3/0/a/140_302ee95370e83cecd8b0d93b797e07ca.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/3/0/a/800_302ee95370e83cecd8b0d93b797e07ca.jpg'}, {
'position': '7', 'content': '等电饭锅跳到保温档就好啦。', 'thumb': 'https://cp1.douguo.com/upload/caiku/8/4/5/140_847f877dddb7859e7f0d2d221f923095.jpg', 'image_width': 2448, 'image_height': 3264, 'image': 'https://cp1.douguo.com/upload/caiku/8/4/5/800_847f877dddb7859e7f0d2d221f923095.jpg'}, {
'position': '8', 'content': '对了,喜欢吃辣的可以加干辣椒,加几粒大蒜味道也不错。', 'thumb': 'https://cp1.douguo.com/upload/caiku/d/2/3/140_d20df3ba8675ff5339a0b2af547574b3.jpg', 'image_width': 3456, 'image_height': 5184, 'image': 'https://cp1.douguo.com/upload/caiku/d/2/3/800_d20df3ba8675ff5339a0b2af547574b3.jpg'}]}
我们可以把输出的数据转换成 json 方便阅读,代码如下:
json_recipe_iinfo = json.dumps(recipe_info)
logger.info(f'当前的 recipe_info:>>>{json_recipe_iinfo}')
3.3.10 数据入库逻辑编写
那到现在,我们还需要进行数据的入库,ip 隐藏,当然还有多线程我们还没有实现。这里我们需要导入这样的一个库:
import pymongo
不过这里,我们会选择把存储数据的代码放入到单独的一个代码文件,这里我在项目目录下创建一个 db.py 的文件。
如果,你对 Python 操作 MongoDB 不了解的话,可以参考如下链接:https://www.aiyc.top/archives/516.html
数据库代码如下:
"""
project = 'Code', file_name = 'db.py', author = 'AI悦创'
time = '2020/5/26 7:25', product_name = PyCharm, 公众号:AI悦创
code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
"""
import pymongo
from pymongo.collection import Collection
class Connect_mongo(object):
def __init__(self):
self.client = pymongo.MongoClient(host='localhost', port=27017)
self.db = self.client['dou_guo_meishi_app'] # 指定数据库
def insert_item(self, item):
db_collection = Collection(self.db, 'dou_guo_mei_shi_item') # 创建表(集合)
# db_collection = self.db.dou_guo_mei_shi_item
db_collection.insert_one(item)
mongo_info = Connect_mongo()
我们还在 Spider_douguo.py 添加了如下代码:
from db import mongo_info
def the_recipe(self, data):
"""
抓取菜谱数据
:return:
"""
# print(f"当前出处理的食材: {data['keyword']}")
recipe_api = 'http://api.douguo.net/recipe/v2/search/0/20' # 先拿前 20 条数据进行测试
response = self.request(url = recipe_api, data = data).text
# print(response)
recipe_list = json.loads(response)['result']['list']
# print(type(recipe_list))
for item in recipe_list:
# recipe_info : 菜谱信息
recipe_info = {
}
recipe_info['食材'] = data['keyword']
if item['type'] == 13:
recipe_info['user_name'] = item['r']['an'] # 用户名称
recipe_info['recipe_id'] = item['r']['id']
recipe_info['cookstory'] = item['r']['cookstory'].strip()
recipe_info['recipe_name'] = item['r']['n']
recipe_info['major'] = item['r']['major']
# print(recipe_info)
detaile_cookstory_url = 'http://api.douguo.net/recipe/detail/{id}'.format(id = recipe_info['recipe_id'])
# print(detaile_cookstory_url)
cookstory_data = {
"client": "4",
# "_session": "1590191363409355757944762497",
"author_id": "0",
"_vs": "11101",
"_ext": '{"query":{"kw":"%s","src":"11101","idx":"1","type":"13","id":"%s"}}'%(str(data['keyword']), str(recipe_info['recipe_id'])),
}
recipe_detail_resopnse = self.request(url = detaile_cookstory_url, data = cookstory_data).text
# print(recipe_detail_resopnse)
detaile_response_dict = json.loads(recipe_detail_resopnse)
recipe_info['tips'] = detaile_response_dict['result']['recipe']['tips']
recipe_info['cook_step'] = detaile_response_dict['result']['recipe']['cookstep']
# json_recipe_iinfo = json.dumps(recipe_info)
# logger.info(f'当前的 recipe_info:>>>{json_recipe_iinfo}')
logger.info(f"当前入库的菜谱是:>>>{recipe_info['recipe_name']}")
mongo_info.insert_item(recipe_info)
else:
continue
运行代码之后,我们可以查看数据库中的数据:
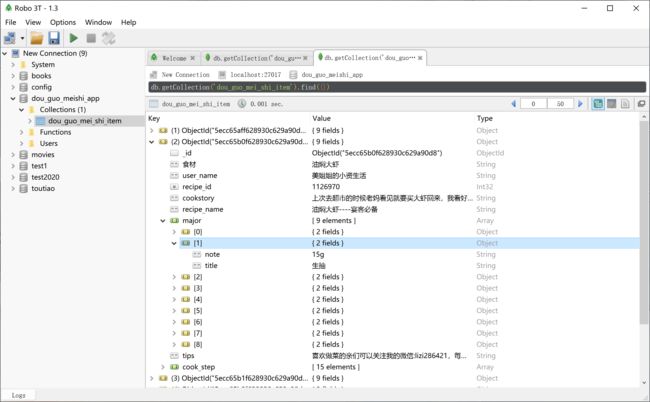
3.3.11 多线程逻辑编写
这里我只是演示了前20条菜谱,同学们可以自行构造 url,接下来我们就可以编写多线程,这里我们需要导入如下库:
from concurrent.futures import ThreadPoolExecutor
main 函数的代码如下:
def main(self):
# url = 'http://api.douguo.net/recipe/v2/search/0/20'
url = 'http://api.douguo.net/recipe/flatcatalogs'
html = self.request(url = url, data = self.index_data).text
# print(html)
self.parse_flatcatalogs(html)
# print(queue_list.qsize())
# for _ in range(queue_list.qsize()):
# data = queue_list.get()
with ThreadPoolExecutor(max_workers=20) as thread:
while queue_list.qsize() > 0:
thread.submit(self.the_recipe, queue_list.get())
运行之后,就可以看到抓取到的数据:

3.3.12 IP 隐藏
IP 隐藏的目的以及作用,我这里就不做赘述了。这里,我创建一个测试文件,来测试我们的代理是否有效,这里我使用的是 【阿布云代理】:https://www.abuyun.com/ ,同学们可以自行选择,如果对代理的使用不清楚的话,可以点击此链接阅读:https://mp.weixin.qq.com/s/eAsFO7u0z1xU4QZW1V9vbg
▌使用付费代理
上面,我们只使用了一个代理,而在爬虫中往往需要使用多个代理,那有如何构造呢,这里主要两种方法:
- 一种是使用免费的多个 IP;
- 一种是使用付费的 IP 代理;
免费的 IP 往往效果不好,那么可以搭建 IP 代理池,但对新手来说搞一个 IP 代理池成本太高,如果只是个人平时玩玩爬虫,完全可以考虑付费 IP,几块钱买个几小时动态 IP,多数情况下都足够爬一个网站了。
这里推荐一个付费代理「阿布云代理」,效果好也不贵,如果你不想费劲地去搞 IP 代理池,那不妨花几块钱轻松解决。
首次使用的话,可以选择购买一个小时的动态版试用下,点击生成隧道代理信息作为凭证加入到代码中。



将信息复制到官方提供的 Requests 代码中,运行来查看一下代理 IP 的效果:
https://www.abuyun.com/http-proxy/dyn-manual-python.html
import requests
# 待测试目标网页
targetUrl = "http://icanhazip.com"
def get_proxies():
# 代理服务器
proxyHost = "http-dyn.abuyun.com"
proxyPort = "9020"
# 代理隧道验证信息
proxyUser = "H8147158822SW5CD"
proxyPass = "CBE9D1D21DC94189"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
for i in range(1,6):
resp = requests.get(targetUrl, proxies=proxies)
# print(resp.status_code)
print('第%s次请求的IP为:%s'%(i,resp.text))
get_proxies()
可以看到每次请求都会使用不同的 IP,是不是很简单?比搞 IP 代理池省事多了。
第1次请求的IP为:125.117.134.158
第2次请求的IP为:49.71.117.45
第3次请求的IP为:112.244.117.94
第4次请求的IP为:122.239.164.35
第5次请求的IP为:125.106.147.24
[Finished in 2.8s]
当然,还可以这样设置:
"""
project = 'Code', file_name = 'lession', author = 'AI悦创'
time = '2020/5/26 10:36', product_name = PyCharm, 公众号:AI悦创
code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
"""
import requests
# 112.48.28.233
url = 'http://icanhazip.com'
# 下面的 try:......except:......是一个防错机制
# username:password@代理服务器ip地址:port
proxy = {
'http':'http://H8147158822SW5CD:[email protected]:9020'}
try:
response = requests.get(url, proxies = proxy)
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
# 如果报错,则输出报错信息
print(e.args)
以上,介绍了 Requests 中设置代理 IP 的方法。
▌没用代理之前
import requests
url = 'http://icanhazip.com'
# 下面的 try:......except:......是一个防错机制
try:
response = requests.get(url) #不使用代理
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
# 如果报错,则输出报错信息
print(e.args)
输出结果:
200
112.48.28.233
[Finished in 1.0s]
▌使用代理
import requests
# 112.48.28.233
url = 'http://icanhazip.com'
# 下面的 try:......except:......是一个防错机制
# username:password@代理服务器ip地址:port
proxy = {
'http':'http://H8147158822SW5CD:[email protected]:9020'}
try:
response = requests.get(url, proxies = proxy)
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
# 如果报错,则输出报错信息
print(e.args)
输出结果:
200
221.227.240.111
这样我们就成功的使用代理了,接下来我们写入爬虫代码。
▌代理写入

因为,我买的每秒只能请求五次,所以我的线程池也要改成5,不然会报错。(有钱人随意购买或者考虑赞赏小编,下一篇抖音)


我 max_workers 我改成了 2。
如果,觉得本篇对你有帮助欢迎转发给你的小伙伴们,也可以考虑赞赏嘿嘿,在看走起,skr~。
对于本文内容有不理解的可以点击阅读原文在原文留言,还有就是加入交流群交流。