简介
Base是Apache Hadoop的数据库,能够对大数据提供随机、实时的读写访问功能,HBase是Bigtable的开源山寨版本,是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统.
HBase存储的是松散型的数据,它介于Nosql和RDBMS之间,仅通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作).主要用来存储非结构化和半结构化的松散数据,与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力,但与hadoop相比,Hbase所要求的服务器性能要比hadoop的高。
体系结构
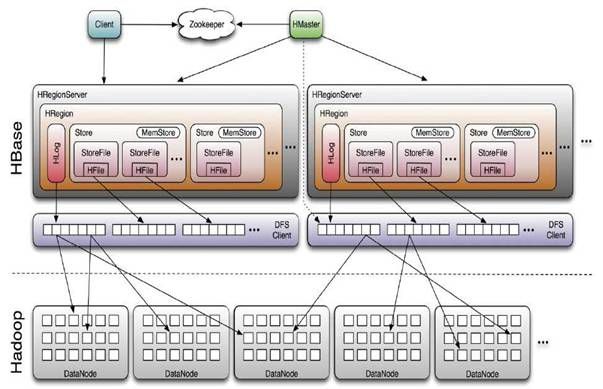
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion服务器(HRegion Server)和HMaster 服务器组成。HMaster负责管理所有的HRegion服务器,而HBase中的所有的服务器都是通过zookeeper来进行协调并处理HBase服务器运行期间可能遇到的错误。HBase Master并不存储HBase中的任何数据.HBase逻辑上的表可能会被划分成多个HRegion,然后存储到HRegion服务器中,HBase Master服务器中存储的是从数据到HRegion 服务器的映射。因此,HBase体系结构如图所示:
HRegion
当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分。从物理上来说,一张表是被拆分成了多块,每一个块就是一个HRegion.我们用表名+开始/结束 主键来区分每一个HRegion。一个HRegion会保存一个表里面的某段连续的数据,从开始主键到结束主键,一张完整的表格是保存在多个HRegion上面的。
HRegion服务器
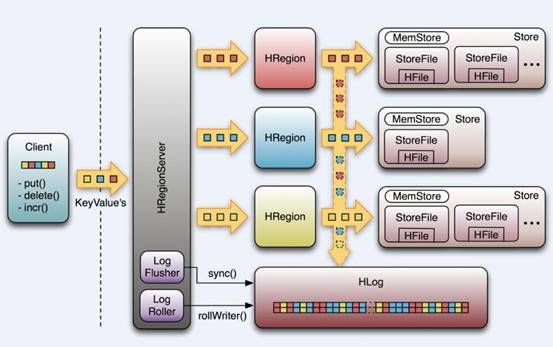
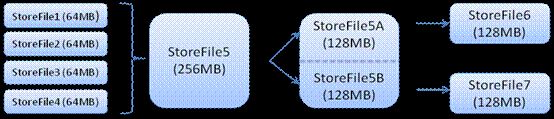
HRegion服务器包含两大部分:HLOG部分和HRegion部分,其中HLOG部分是用来存储数据日志,采用的是WAL(先写日志)的方式.HRegion部分是由很多的Store部分组成的,存储的是实际的数据,而Store是由MemStore和StoreFile组成的,每一个Store实际上存储的是一个列族(Column Family)的数据,当数据到来的时候首先会写到HLOG中,然后写入到MemStore中,而MemStore是驻留在内存中的,当MemStore的大小达到一定的阀值后,会写入到StoreFile(又名HFile),当StoreFile的数量达到一定的阀值后,会进行compact操作,当单个StoreFile文件的大小达到一定的阀值,会将当前的Region进行split操作,产生2个HRegion,同时父HRegion会下线,HMaster会把这2个HRegion分配到其他的HRegionServer上,以此来达到负载均衡
总结下流程:data---->HLOG----->MemStore---->StoreFile---->compact---->Region Split
HBase中不涉及数据的直接删除和更新操作,所有的数据均通过追加的方式进行更新,数据的删除和更新在HBase合并(compact)的时候进行的
HBase Master服务器
HMaster的主要任务就是告诉每个HRegion服务器它要维护哪些HRegion
当一台新的HRegion服务器登录到HMaster服务器时,HMaster会告诉它先等待分配数据.而当一台HRegion死机时,HMaster会把它负责的HRegion标记为未读,然后再把它们分配到其他的HRegion服务器上
HMaster在功能上主要负责table和HRegion的管理工作,具体包括:
1.管理用户对Table的增删改查
2.管理HRegion服务器的负载均衡,调整HRegion的分布
3.在HRegion分裂后,负责新HRegion的分配
4.在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移
ROOT和META表
META(元数据):用来区分不同的HRegion的数据,表达符是:表名+开始主键+唯一ID,用此表达符来唯一表示HRegion,而元数据本身也是存储在HReion中的,我们称这个表为元数据表(META)表
ROOT表:保存所有元数据表的位置,根数据表是不能分割的,永远只存在一个
元数据表和根数据表的每一行都包含一个列族(info列族)
ROOT表包含META表所在的区域列表,META表包含所有的用户空间区域列表,以及Region服务器的地址,客户端能够缓存所有的已知的ROOT表和META表,从而提高访问的效率
Zookeeper
zookeeper存储的是HBase中ROOT表和META表的位置.此外,zookeeper还负责监控各个机器的状态(每台机器到Zookeeper中注册一个实例).当某个机器发生故障的时候,zookeeper会第一时间感知到,并通知HBase Master进行相应的处理,同时,当HBase Master发生故障的时候,Zookeeper还负责HBase Master的恢复工作,能够保证在同一时刻系统中只有一台HBase Master提供服务
数据模型
HBase是一个类似BigTable的分布式数据库,它是一个稀疏的长期存储的(存在硬盘上)、多维度的、排序的映射表,这张表的索引是行关键字、列关键字和时间戳,HBase中的数据都是字符串,没有类型
列名字的格式是"
HBase的写操作是锁行的,每一行都是一个原子元素,都可以加锁
概念视图
我们可以把一个表想象成一个大的映射关系,通过行键,行键+时间戳或行键+列(列族:列修饰符),就可以定位特定数据,HBase是稀疏存储数据的,因此某些列可以是空白的
每一条数据对应的时间戳都用数字来表示,编号越大表示数据越旧,反之表示数据越新
物理视图
在物理存储上面,它是按照列表来保存的
在概念视图上面有些列是空白的,这样的列实际上并不会被存储,当请求这些空白的单元格时,会返回null值