我们在之前scheduler模块的分析中了解到,DAGScheduler划分stage的依据就是Shuffle Dependency,那么Shuffle是一个怎么样的过程呢?Shuffle为何成为性能调优的重点呢?接下来的shuffle模块将从源码的角度来尝试给出答案。
为什么存在shuffle
Spark分布式的架构、分布式的计算、分布式的存储导致的,当运行某些特殊的算子(aggregate),汇聚具有相同特征的数据到同一个节点来进行计算时,就会发生Shuffle(洗牌)操作,这个数据重新打乱然后汇聚到不同的节点的过程就是Shuffle。
shuffle带来的问题
1.数据量会很大,数据量级为TB、PB甚至EB的数据集分布在成百上千甚至上万台机器上
2.在汇聚过程中,数据大小大于本地内存,导致多次发生溢写磁盘
3.数据需要通过网络传输,因此数据的序列化和反序列化变得相对复杂
4.为了节省带宽,数据可能需要压缩,如何在压缩率和压缩解压时间中间做一个权衡
Shuffle策略的进化史:
在Spark 1.0版本之前,Spark只支持Hash Based Shuffle,因为很多应用场景并不需要排序,而Hadoop中MapReduce的shuffle过程:partition->spill to disk->sort->combiner->merge中,就必须要排序,多余的排序只能使性能变差。Spark为了跳过不需要的排序,最早实现的是Hash Based Shuffle,原理很简单:每个Task根据key的哈希值计算出每个key将要写入的partition,然后将数据写入一个文件供下游的Task来拉取。如果应用需要实现排序的功能,就需要用户调用相关算子(sortByKey)去实现。
但是这种Hash Based Shuffle模式有其缺点:当并行度很高时,会产生很多中间落地的文件,比如说map的并行度为500,reduce的并行度为500,那么就会有500*500=250000个中间文件生成,同时打开这么多个文件并进行随机读对系统的内存和磁盘IO会造成很大压力。
为了解决这个问题,在Spark 0.8.1中加入了Shuffle Consolidate File机制,在1.6版本之前,需要通过设置spark.shuffle.consolidateFiles设置为true(默认为false)来使用这个功能,1.6版本之后成为默认项。其实现原理为:对于同一个core的不同Task在写中间文件的时候可以共享追加同一个文件,这样就显著的减小了文件的数量。可以通过下图加深理解:

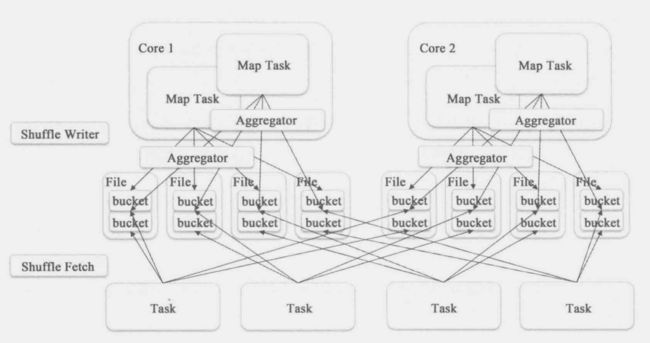
Shuffle Consolidate File机制虽然缓解了Shuffle过程产生文件过多的问题,但是并没有彻底解决内存和IO的问题,所以在Spark 1.1中实现了Sort Based Shuffle,通过spark.shuffle.manager选项可以设置,默认为Hash,而在Spark 1.2中Sort Based Shuffle取代Hash Based Shuffle成为默认选项,在Spark 2.0版本之后,Hash Based Shuffle已经不见踪影,Sort Based Shuffle成为唯一选项。
Sort Based Shuffle的实现有点复杂:首先,每个ShuffleMapTask不会为每个Reducer生成单独的一个文件,它会将所有的结果写到一个文件中,同时生成一个Index文件,Reducer可以通过这个Index文件取得它需要处理的数据,这样就避免了产生大量的中间文件,也就节省同时打开大量文件使用的内存和随机写带来的IO。过程是这样的:
- 每个Map Task会为下游的每一个Reducer,或者说每一个partition生成一个Array,将key-value数据写入到这个Array中,每一个partition中的数据并不会排序(避免不必要的排序)
- 每个Array中的数据如果超过某个阈值将会写到外部存储,这个文件会记录相应的partitionId以及保存了多少了数据条目等信息
- 最后用归并排序将不同partition的文件归并到一个新的文件中,每个partition数据在新的文件中相当于一个桶,并且需要同时生成Index索引文件来记录桶的位置信息
可通过下图加深理解:
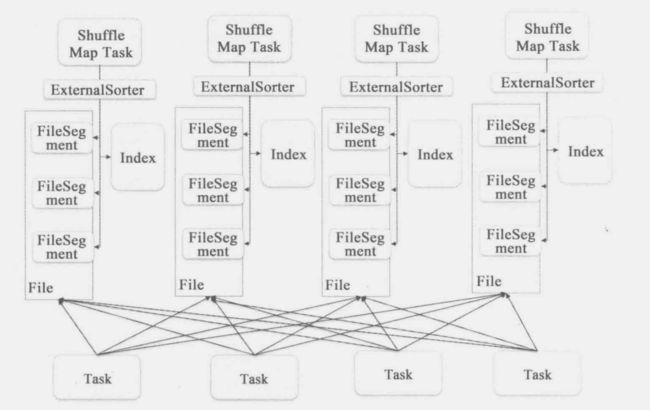
shuffle write
接下来,通过源码阅读来了解Hash、Sort两种模式的shuffle过程,首先在shuffle过程中,必定有中间落地数据,这是因为Shuffle从各个节点中找到特征相同的数据并把它们汇聚到相应的节点是一件耗时耗力的工程,为了容错,需要把中间数据持久化,其次也是因为数据量较大,内存可能会放不下。
这样,整个Shuffle过程就被分成了两个部分,shuffle write和shuffle read,在executor模块中,我们分析到了task的执行,实际上是调用Task类的runTask()方法来计算,而shuffle write过程则是存在于Task的实现类ShuffleMapTask的runTask()方法中:
override def runTask(context: TaskContext): MapStatus = {
...省略部分代码,作用为反序列化Task信息得到rdd和dependence
var writer: ShuffleWriter[Any, Any] = null //ShuffleWrite实例
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
这段代码中首先反序列化收到的Task信息,然后调用了ShuffleWrite实例的write方法,我们首先来看writer的实例化代码writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
其中,manager是ShuffleManager,在1.6.3版本中,它有两个实现类:HashShuffleManager和SortShuffleManager,而在2.3.0版本中,HashShuffleManager已经不见踪影,只剩下SortShuffleManager实现类,Hash Based Shuffle已经被优化掉,但我们依然会分析这俩种Shuffle过程来做一个对比。
Hash Shuffle Write
HashShuffleManager中getWriter方法创建了HashShuffleWriter实例
override def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext)
: ShuffleWriter[K, V] = {
new HashShuffleWriter(
shuffleBlockResolver, handle.asInstanceOf[BaseShuffleHandle[K, V, _]], mapId, context)
}
接着调用了这个实例的write方法,在方法中首先判断是否存在aggregator聚合操作,并进一步判断是否为map端的聚合mapSideCombine,如果是的话就调用combineValuesByKey方法对records进行聚合(spark中很多算子实现了mapSideCombine,例如reduceByKey),否则的话就直接返回records。
override def write(records: Iterator[Product2[K, V]]): Unit = {
val iter = if (dep.aggregator.isDefined) { //如果需要聚合操作
if (dep.mapSideCombine) { //如果是map端的聚合
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else { //如果不需要聚合
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1) //获取该element需要写的partition
shuffle.writers(bucketId).write(elem._1, elem._2) //写到本地,writer调用shuffleBlockResolver.forMapTask方法中的writer
}
}
val bucketId = dep.partitioner.getPartition(elem._1)
这一行代码对应我们上面说的根据Key的哈希值来计算出对应的partition Id,dep对应着传入的ShuffleHandle,那么相应的Partitioner就是HashPartitioner,以下是其getPartition的实现:
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
再点进去看nonNegativeMod方法其实很简单:key的hashCode对numPartitions取模并保证结果为非负数。
再来看接下来的第二行代码
shuffle.writers(bucketId).write(elem._1, elem._2)
其中shuffle是ShuffleWriterGroup的实例
private val shuffle: ShuffleWriterGroup = shuffleBlockResolver.forMapTask(dep.shuffleId, mapId, numOutputSplits, ser,writeMetrics)
ShuffleWriterGroup顾名思义writer组,用来存储writers,为每一个reducer或者说每一个partition都保存一个writer,而这每一个writer其实是DiskBlockObjectWriter的实例,其中封装了本地文件的信息。
以下是forMapTask方法的代码:
def forMapTask(shuffleId: Int, mapId: Int, numReducers: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics): ShuffleWriterGroup = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numReducers))
private val shuffleState = shuffleStates(shuffleId)
val openStartTime = System.nanoTime
val serializerInstance = serializer.newInstance()
val writers: Array[DiskBlockObjectWriter] = {
Array.tabulate[DiskBlockObjectWriter](numReducers) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
// 本地文件
val blockFile: File = blockManager.diskBlockManager.getFile(blockId)
val tmp = Utils.tempFileWith(blockFile)
blockManager.getDiskWriter(blockId, tmp, serializerInstance, bufferSize, writeMetrics)
}
}
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, so should be included in the shuffle write time.
writeMetrics.incShuffleWriteTime(System.nanoTime - openStartTime)
override def releaseWriters(success: Boolean) {
shuffleState.completedMapTasks.add(mapId)
}
}
}
每一个MapTask针对下游的每个partition生成一个本地文件来存储信息,这样的话就会生成M*R个中间文件(M为Mapper的数量,R为Reducer的数量),这就是我们上面说的HashBasedShuffle的弊病。
根据Key的哈希值取得对应的writer后,最后通过DiskBlockObjectWriter的write方法将数据写到本地文件:
/**
* Writes a key-value pair.
*/
def write(key: Any, value: Any) {
if (!initialized) {
open()
}
objOut.writeKey(key)
objOut.writeValue(value)
recordWritten()
}
Sort Shuffle Write
以下是SortShuffleWriter类的write方法:
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) { //如果是map端的聚合
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C]( //key value combiner
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else { //如果不需要聚合
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output: File = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
// 写本地文件,返回的是写入一个partition数据的长度
val partitionLengths: Array[Long] = sorter.writePartitionedFile(blockId, tmp)
// 根据返回的长度写Index文件
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
在这个方法中,首先考虑聚合,如果是mapSideCombine,那么创建一个带有aggregator和Key的排序器的外部排序器ExternalSorter,否则就创建一个不带聚合和Key的排序器的ExternalSorter,然后将数据都放入排序器中。
然后将数据从排序器的数据结构中利用归并排序写入到本地文件中,并根据返回的parititionLengths创建Index文件。
下面,我们可以从外部排序器ExternalSorter入手来了解这个过程,以下是它的writePartitionedFile方法:
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
if (spills.isEmpty) { //如果spills是空的说明数据都在内存中
// Case where we only have in-memory data
//如果有聚合,则内存的数据结构为PartitionedAppendOnlyMap,否则为PartitionedPairBuffer
val collection = if (aggregator.isDefined) map else buffer
// 根据传入的比较器获取数据结构中数据的有序迭代器
// 如果是首先是根据分区partition排序的,其次根据Key的Hash值
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
// 获取writer
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics.shuffleWriteMetrics.get)
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
writer.commitAndClose() //提交时需要纪录初始位置和结束位置,结束位置以文件的length来确定
val segment = writer.fileSegment() //根据初始位置和结束位置创建一个FileSegment
lengths(partitionId) = segment.length //记录Segment的长度和partitionId之间的关系
}
} else { //如果数据已溢出至磁盘,则必须用归并排序将文件合并
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) { //partitionedIterator中将spills与in-memory合并
if (elements.hasNext) { //获取writer并按照partitionId写入FileSegment
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics.shuffleWriteMetrics.get)
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
writer.commitAndClose()
val segment = writer.fileSegment()
lengths(id) = segment.length
}
}
}
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.internalMetricsToAccumulators(
InternalAccumulator.PEAK_EXECUTION_MEMORY).add(peakMemoryUsedBytes)
lengths
}
这个方法也是一分为二,如果spills是空的,说明数据全在内存的数据结构中,没有溢写到磁盘,否则说明内存和磁盘中都有records。
如果数据都在内存中,那么又一分为二,其中定义过aggregator的数据放在PartitionedAppendOnlyMap中,没有的话就放在PartitionedPairBuffer中:
val collection = if (aggregator.isDefined) map else buffer
// map和buffer实例创建
private var map = new PartitionedAppendOnlyMap[K, C]
private var buffer = new PartitionedPairBuffer[K, C]
这两个数据结构的实现比较复杂,它们主要的功能是用来存放records,如果达到某个阈值则spill到磁盘,落成文件,两者的区别为:map用来存放有聚合需求的数据,buffer用来存放没有聚合需求的数据,具体可关注这两个类的源码。
最后在内存中的数据都通过叫作FileSegment的实例封装,其中包括每个partition的起始和终止position,并且返回一个数组,用来记录partitionId与每个Segment的长度的关系,即每一个partition的数据写入一个FileSegment,所有的FileSegment有序落入一个文件。
如果数据已经溢出至外部存储,那么这部分数据需要采用归并排序的方式合并成一个文件,实现细节在ExternalSorter的partitionedIterator方法中:
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
val usingMap = aggregator.isDefined
val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer
if (spills.isEmpty) {
// Special case: if we have only in-memory data, we don't need to merge streams, and perhaps
// we don't even need to sort by anything other than partition ID
if (!ordering.isDefined) {
// The user hasn't requested sorted keys, so only sort by partition ID, not key
groupByPartition(collection.partitionedDestructiveSortedIterator(None))
} else {
// We do need to sort by both partition ID and key
groupByPartition(collection.partitionedDestructiveSortedIterator(Some(keyComparator)))
}
} else {
// Merge spilled and in-memory data
merge(spills, collection.partitionedDestructiveSortedIterator(comparator))
}
}
可以看出,这里也是按照是否有mapSideCombine分为使用map还是buffer,并且如果没有传入key的比较器,则直接按照partitionId来排序,否则还需要加上KeyComparator,最后将spills的数据与in-memory的数据使用归并排序合并到一个文件中。
writePartitionedFile方法最后返回一个数组,其中数组下标为partitionID,而内容就是对应的FileSegment的长度,拿到这个数组是用来建立Index文件,至此,sort shuffle write结束。
总结
Hash-Based-Shuffle设计之初是为了避免多余的排序操作,但是出现了中间落地文件过多的问题,即使采用ConsolidateFile机制,也不能有效解决问题,而在生产环境中,当数据量很大时,并行度也会很高,相应的shuffle上下游map和reduce的partition数量就会很多,导致中间落地文件数量过多,从而出现内存溢出和磁盘IO性能瓶颈,在spark 2.0版本以后消失不见。
Sort-Based-Shuffle为了解决这个问题,采用了FileSegment的概念,通过partitionId对数据分桶,写入一个文件,并且建立Index文件提供offset在Reducer拉取数据时使用,并且在合并文件的时候仅根据partitionId来排序,避免了多余的排序,在spark 1.2版本以后已经成为默认选项。
这篇文章分析了这两种模式的shuffle-writer过程,下一篇文章将继续分析shuffle-read过程。