读书笔记 --《算法图解》
文章目录
-
- 1. 大O表示法
-
- 1. 旅行商前往n个城市,确保旅程最短。求可能的排序:n!种可能方案
- 2. 仅当列表是有序的时候,二分查找才管用
- 2. 选择排序
-
- 1. 数组 & 链表
- 3.递归
-
- 1. 递归
- 2. 栈
- 4. 快速排序
- 5. 散列表
- 6. 广度优先搜索
- 7. 狄克斯特拉算法(计算加权图的最短路径)
- 8. 贪婪算法
- 9. 动态规划
- 10. K最近邻算法
- 11. 扩展
1. 大O表示法
- 算法的运行时间用大O表示法表示
- 大O运行时间转换为操作数
- 算法的速度指的并非时间,而是操作数的增速(随着输入的增加,其大O运行时间将以什么样的速度增加)
| 快到慢函数 | 函数 |
|---|---|
| O(1) | 常量时间,哈希 |
| O(log2(n)) | 对数时间,二分查找 |
| O(n) | 线性时间,简单查找 |
| O(nlog2(n)) | 快速排序 |
| O(n2) | 选择排序(冒泡) |
| O(n!) | 旅行商问题 |
- 说明:
1. 旅行商前往n个城市,确保旅程最短。求可能的排序:n!种可能方案
2. 仅当列表是有序的时候,二分查找才管用
# 简单查找
def search(target_list,item):
for i in target_list:
if i == item:
return i
return None
# 二分查找
def binary_search(tlist,item):
low = 0
high = len(tlist)-1
while low <= high:
mid = int((low + high)/2)
if item < tlist[mid]:
high = mid-1
elif item >tlist[mid]:
low = mid+1
else:
return (mid,tlist[mid])
return None
2. 选择排序
1. 数组 & 链表
-
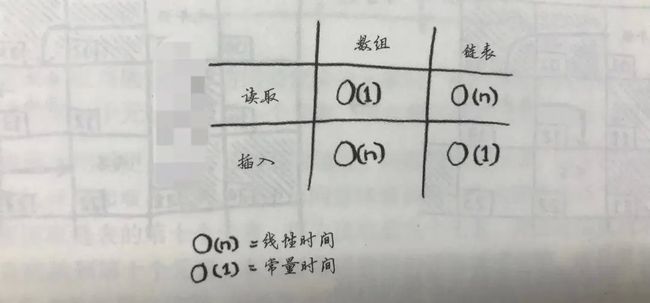
数组: 内存中连续存储,随意查询元素,随机查询快(知道索引),增删改慢(因为有顺序,有预设内存空间,中间插入或者超出预留内存,就会重新构建)
-
链表: 内存中分散,每一个元素记录下一个元素位置,随机查询慢(只能从第一个往后推),要全部查询的情况下也不慢,增删改快(分散存储只要更改上一个元素的记录)
# 选择排序(冒泡排序)
# 先把数组中最小值找到,然后把该最小值添加到一个新数组中
def findsmallest(arr):
smallest_index = 0
smallest_num = arr[0]
for i in range(1, len(arr)):
if smallest_num > arr[i]:
smallest_index = i
smallest_num = arr[i]
return smallest_index
def selectsort(arr):
"""
:param arr:
:return: new arr for sorted
"""
new_arr = []
for i in range(len(arr)):
smallest_index = findsmallest(arr)
new_arr.append(arr.pop(smallest_index))
return new_arr
3.递归
1. 递归
- 递归指的是调用自己的函数
- 每个递归函数都有两个条件:基线条件和递归条件
- 尾递归 (将结果也放入函数参数,内存里面调用栈只有一个当前运行的函数进程)
2. 栈
-
栈是一种简单的后进先出数据结构,栈有两种操作:压入(插入)和弹出(删除并读取)
-
所有函数调用都进入调用栈
-
调用栈可能很长,这将占用大量的内存
-
调用栈: 每当调用函数时,计算机都像这样将函数调用涉及的所有变量的值存储到内存中。调用另一个函数时,当前函数暂停并处于未完成状态。该函数的所有变量的值都还在内存中。这个栈用于存储多个函数的变量,被称为调用栈。
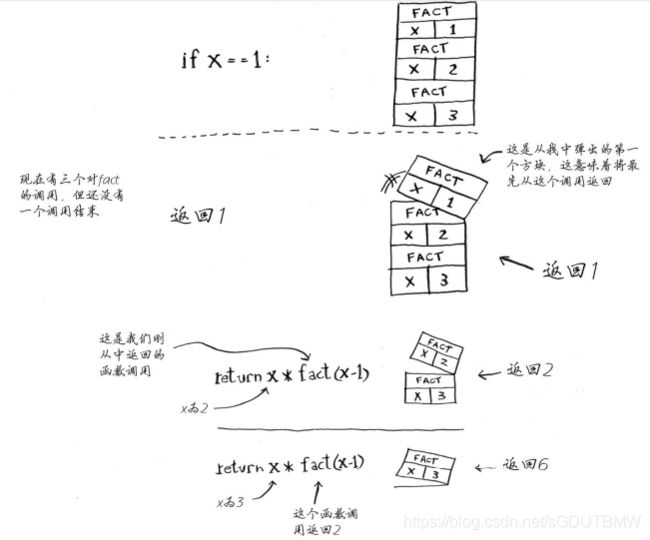
# 递归 阶乘f(n) = n!
def fact(x):
if x == 1:
return 1
else:
return x * fact(x-1) #注意这里跟尾递归不同
# 尾递归
def factorial(x,result):
if x == 1:
return result
else:
return factorial(x-1,x*result)
if __name__ == '__main__':
print(fact(5)) #5*4*3*2*1 = 120
print(factorial(5,1)) #120
4. 快速排序
- 快速排序使用分而治之的策略
分而治之D&G(divide and cpnquer)
工作原理:
1. 找出基线条件,这个条件必须尽可能的简单
2. 不断将问题分解(或者说缩小规模),直到符合基线条件
涉及数组的递归函数时,基线条件通常是数组为空或只包含一个元素。陷入困境时,请检查基线条件是不是这样的
# D&C和递归应用举例
# 列表元素值求和
def sum(list):
if not list:
return 0
return list[0] + sum(list[1:])
# 编写一个递归函数来计算列表包含的元素数
def count(list):
if not list:
return 0
return 1 + count(list[1:])
# 找出列表中最大数字
def max(list):
if len(list) == 2:
return list[0] if list[0] > list[1] else list[1]
sub_max = max(list[1:])
return list[0] if list[0] > sub_max else sub_max
print(sum([1, 3, 6, 2, 9, 0]))
print(count([1, 3, 6, 2, 9, 0]))
print(max([1, 3, 6, 2, 9, 0]))
# 两种快速排序,平均运行时间为 O(n * log n)
# 基准值为第一个元素
def quicksort(sort_list):
if len(sort_list) < 2:
return sort_list
else:
base_num = sort_list[0]
less = [i for i in sort_list[1:] if i <= base_num]
greater = [i for i in sort_list[1:] if i > base_num]
return quicksort(less) + [base_num] + quicksort(greater) # []直接列表化 和 list()将可迭代对象列表化
# 基准值为最中间元素
def quicksort2(sort_list):
if len(sort_list) < 2:
return sort_list
else:
mid_index = len(sort_list) // 2
less = [i for i in sort_list[:mid_index] if i <= sort_list[mid_index]] + \
[i for i in sort_list[mid_index + 1:] if i <= sort_list[mid_index]]
greater = [i for i in sort_list[:mid_index] if i > sort_list[mid_index]] + \
[i for i in sort_list[mid_index + 1:] if i > sort_list[mid_index]]
return quicksort2(less) + [sort_list[mid_index]] + quicksort2(greater)
print(quicksort([10, 5, 2, 3, 6]))
print(quicksort2([10, 5, 2, 3, 6]))
- 合并排序,或者叫归并排序
-
合并排序也是建立在归并操作上的一种有效的排序算法。也是采用分治法的一个非常典型的应用
-
合并排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列
-
归并排序的时间复杂度任何情况下都是 O(n*log n),但并不如快排应用广泛,因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间,也就是说它不是原地排序算法

# 冒泡排序时间复杂度O(n^2)
def simpleSort(array):
for i in range(len(array)-1):
for j in range(i,len(array)):
if array[i] > array[j]:
temp = array[i]
array[i] = array[j]
array[j] = temp
return array
print(simpleSort([9,8,6,7,4,5,3,11,2])) #[2, 3, 4, 5, 6, 7, 8, 9, 11]
# 归并排序时间复杂度是O(nlogn) ,最坏情况也是O(nlogn)
def mergeSort(array):
if len(array) < 2:
return array
else:
mid = int(len(array)/2)
left = mergeSort(array[:mid])
right = mergeSort(array[mid:])
return merge(left, right)
def merge(left, right): #并两个已排序好的列表,产生一个新的已排序好的列表
result = [] # 新的已排序好的列表
i = 0 # 下标
j = 0
# 对两个列表中的元素 两两对比
# 将最小的元素,放到result中,并对当前列表下标加1
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 此时left或者right其中一个已经添加完毕,剩下的就全部加到result后面即可
result += left[i:]
result += right[j:]
return result
array = [9,5,3,0,6,2,7,1,4,8]
result = mergeSort(array)
print('排序后:',result) #排序后: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
5. 散列表

-
散列函数
-
散列函数是这样的函数,既无论你给它什么数据,它都还你一个数字。即散列函数"将输入映射到数字"
-
散列表应用
1. 快速查找
2. 文件安全性传输交验
3. 可以防止重复 (一旦发现重复,该哈希函数就不安全了。也就是说被破译了)
4. 缓存/ 记住数据,以免服务器再通过处理来生成它们
- 散列表
- 散列表更复杂一些,它使用散列函数来确定元素的存储位置。。散列表也使用数组来存储数据,因此其获取元素的速度与数组一样快
小结
1. 散列表时一种功能强大的数据结构,其操作速度快,能以不同的方式建立数据模型。
2. 可以结合散列函数和数组来创建散列表。
3. 冲突很糟糕,应该使用可以最大限度减少冲突的散列函数。
4. 散列表的查找,插入和删除速度都非常快。
5. 散列表适合用于模拟映射关系。
6. 一旦装填因子超过0.7,就该调整散列表的长度.
7. 散列表可用于缓存数据。
8. 散列表非常适用于防止重复。
6. 广度优先搜索
-
广度优先搜索采用双端队列
-
处理过程中,将所有有关的节点都添加到处理队列中
-
非加权图(无向图)中查找最短路径
-
从你的朋友关系网中,找出一个芒果销售商。(假设芒果销售商名字是以m结尾)
from collections import deque
#需编写函数person_is_seller,判断一个人是不是芒果销售商,如下所示。
def person_is_seller(name):
return name[-1] == 'm' #这个函数检查人的姓名是否以m结尾:如果是,他就是芒果销售商。。
def bfs(graph,name):
search_queue = deque()
search_queue += graph[name]#graph["you"]是一个数组,其中包含你的所有邻居,如["alice", "bob","claire"]。这些邻居都将加入到搜索队列中。
searched =[]
while search_queue:
person = search_queue.popleft()
if not person in searched:
if person_is_seller(person):
print(person + " is a mango seller!")
return True
else:
search_queue += graph[person]
searched.append(person)
return False
if __name__=='__main__':
graph = {
}
graph["you"] = ["alice", "bob", "claire"]
graph["bob"] = ["anuj", "peggy"]
graph["alice"] = ["peggy"]
graph["claire"] = ["thom", "jonny" ]
graph["anuj"] = []
graph["peggy"] = []
graph["thom"] = []
graph["jonny"] = []
print(graph)
'''
{'you': ['alice', 'bob', 'claire'],
'bob': ['anuj', 'peggy'],
'alice': ['peggy'],
'claire': ['thom', 'jonny'],
'anuj': [],
'peggy': [],
'thom': [],
'jonny': []}
'''
bfs(graph,"you") #thom is a mango seller!
- 小结
- 广度优先搜索指出是否有从A到B的路径。
- 如果有,广度优先搜索将找出最短路径。
- 面临类似于寻找最短路径的问题时,可尝试使用图来建立模型,再使用广度优先搜索来解决问题。
- 有向图中的边为箭头,箭头的方向指定了关系的方向,例如,rama→adit表示rama欠adit钱。
- 无向图中的边不带箭头,其中的关系是双向的,例如,ross - rachel表示“ross与rachel约会,而rachel也与ross约会”。
- 队列是先进先出(FIFO)的。
- 栈是后进先出(LIFO)的。
- 你需要按加入顺序检查搜索列表中的人,否则找到的就不是最短路径,因此搜索列表必须是队列。
- 对于检查过的人,务必不要再去检查,否则可能导致无限循环。
7. 狄克斯特拉算法(计算加权图的最短路径)
- 迪克斯特拉的关键4个步骤:
- 找出最便宜的节点,即可在最短时间内前往的节点
- 对于该节点的邻居,检查是否有前往它们的更短路径,如果有,就更新其开销
- 重复这个过程,直到对图中的每个节点都这样做了。
- 计算最终路径
# 将节点的所有邻居和和前往邻居的开销都存储在一个散列表
# 每个节点都有开销。开销指的是从起点前往该节点需要多长时间
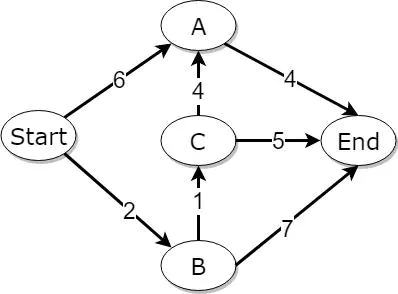
graph = {
}
graph["Start"] = {
}
graph["Start"]["A"] = 6
graph["Start"]["B"] = 2
graph["A"] = {
}
graph["A"]["End"] = 4
graph["B"] = {
}
graph["B"]["C"] = 1
graph["B"]["End"] = 7
graph["C"] = {
}
graph["C"]["A"] = 4
graph["C"]["End"] = 5
infinity = float("inf")
costs = {
}
costs["A"] = 6
costs["B"] = 2
costs["C"] = infinity
costs["End"] = infinity
parents = {
}
parents["A"] = "Start"
parents["B"] = "Start"
parents["C"] = None
parents["End"] = None
def findLowestCostNode(costs, processed):
lowest_cost = infinity
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
def Dijkstra():
processed = []
node = findLowestCostNode(costs, processed)
while node is not None and node != "End":
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost + neighbors[n]
if new_cost < costs[n]:
costs[n] = new_cost
parents[n] = node
processed.append(node)
node = findLowestCostNode(costs, processed)
Dijkstra()
print(costs)
print(parents)
# 小结
# 1. 计算非加权图中的最短路径,使用广度优先搜索。
# 2. 计算加权图中的最短路径,使用狄克斯特拉算法。即只适用于有向无环图(DAG)
# 3. 最短路径指的并不一定是物理距离,也可能是让某种度量指标最小
# 4. 如果图中包含负权边,请使用贝尔曼-福德算法
8. 贪婪算法
- 贪婪算法寻找局部最优解,企图以这种方式获得全局最优解,易于实现、运行速度快,是不错的近似算(一种 NP 完全问题的近似解)
- 广度优先搜索与迪克斯特拉算法都算贪婪算法
# 判断NP方法的一些条件
1. 元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢
2. 涉及"所有组合"的问题通常是NP完全问题
3. 不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题
4. 如果问题涉及序列(如旅行商问题中的城市)且难以解决,它可能就是NP完全问题
5. 如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题
6. 如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题
9. 动态规划
- 动态规划:将问题分成小问题,并先着手解决这些小问题,都可以画网格解决
- 小偷背包问题


def bag(goods,size):
cell = [[0 for col in range(size)] for row in range(len(goods))]
package_size= [i+1 for i in range(size)]
for j in range(size):
if(goods[0][1]<=package_size[j]):
cell[0][j] = goods[0][0]
for i in range(1,len(goods)):
for j in range(size):
if (package_size[j]-goods[i][1]>0) and (goods[i][0] + cell[i-1][package_size[j]-1-goods[i][1]]) > cell[i-1][j]:
cell[i][j] = goods[i][0] + cell[i-1][package_size[j]-goods[i][1]-1]
elif (package_size[j]-goods[i][1]==0) and (goods[i][0] > cell[i-1][j]):
cell[i][j] = goods[i][0]
else:
cell[i][j] = cell[i-1][j]
print(cell) #[[1500, 1500, 1500, 1500], [1500, 1500, 1500, 3000], [1500, 1500, 2000, 3500]]
return cell[len(goods) - 1][size - 1]
if __name__ == '__main__':
goods = [[1500,1],[3000,4],[2000,3]]
print(bag(goods,4)) #3500
- 最长公共子串(fish和hish)
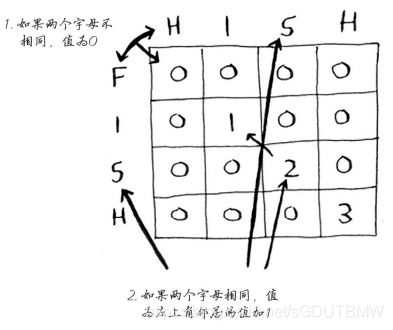
# 最长公共子串
if word_a[i] == word_b[j]:
cell[i][j] = cell[i-1][j-1] + 1
else:
cell[i][j] = 0
- 最长公共子序列(fish和fosh)
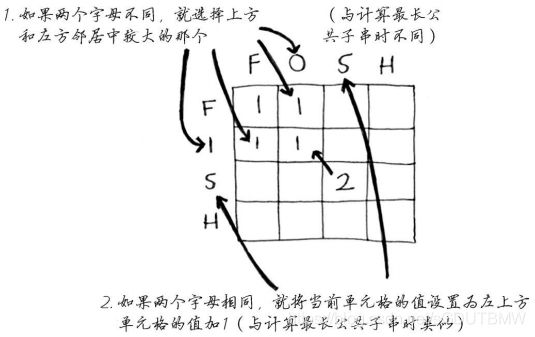
# 最长公共子序列
if word_a[i] == word_b[j]:
cell[i][j] = cell[i-1][j-1] + 1
else:
cell[i][j] = max(cell[i-1][j], cell[i][j-1])
10. K最近邻算法
- KNN算法真的是很有用,堪称你进入神奇的机器学习领域的领路人!
- 使用KNN 来做两项基本工作—— 分类和回归,需要考虑最近的邻居
- 要计算两点的距离(相似程度),可使用毕达哥拉斯公式:
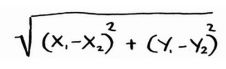
-
分类就是编组 回归就是预测结果(如一个数字)–凭着得出的相似程度计算估值
-
选择邻居个数一般为sqrt(n)个数,n为总量
-
特征抽取意味着将物品(如水果或用户)转换为一系列可比较的数字
-
除了距离公式,实际上更常用余弦相似度



- 机器学习的例子
1. 水果分类
2. 电影推荐系统
3. OCR指的是光学字符识别(optical character recognition)
(1)浏览大量的数字图像,将这些数字的特征提取出来。 --训练
(2)遇到新图像时,你提取该图像的特征,再找出它最近的邻居都是谁!
(3)这与判断水果是橙子还是柚子时一样。OCR算法提取线段、点和曲线等特征
4. 垃圾邮件过滤器
(1)使用一种简单算法——朴素贝叶斯分类器 (Naive Bayes classifier )
(2)朴素贝叶斯分类器能计算出邮件为垃圾邮件的概率,其应用领域与KNN 相似
11. 扩展
- 二叉树,B树(数据库常用它来存储数据),红黑树,堆,伸展树

# 二叉树
- 对于其中的每个节点,左子节点的值都比它小,而右子节点的值都比它大
- 反向索引
# 反向索引(inverted index)
- 一个散列表,将单词映射到包含它的页面。反向索引常用于创建搜索引擎。
- 傅里叶变换
# 傅里叶变换
- 傅里叶变换非常适合用于处理信号
- 傅里叶变换能够将其中的各种频率分离出来
- 将音频文件分解为音符。傅里叶变换能够准确地指出各个音符对整个歌曲的贡献,让你能够将不重要的音符删除
- 压缩音乐如MP3,图片JPG,地震预测和DNA分析
- 并行算法
# 并行算法
- 要改善性能和可扩展性
- 速度并不是线性的,会受到并行性管理开销和负载均衡的影响
- MapReduce
# MapReduce
- MapReduce基于两个简单的理念:映射(map)函数和归并(reduce)函数
- 映射是将一个数组转换为另一个数组
- 归并是将一个数组转换为一个元素
arr1 = [1, 2, 3, 4, 5]
arr2 = map(download_page, arr1) # [2, 4, 6, 8, 10]
reduce(lambda x,y: x+y, arr1) # 15
- 布隆过滤器和 HyperLogLog
# 概率型算法
- 概率型数据结构,使用散列表时,答案绝对可靠,
而使用布隆过滤器时,答案却是很可能是正确的
- 它不能给出准确的答案,但也八九不离十,而占用的内存空间却少得多
- SHA 算法
- 散列函数是安全散列算法(secure hash algorithm ,SHA )函数)
- 给定一个字符串,SHA返回其散列值,可用于比较文件/检查密码
- 局部敏感的散列算法
- 如:Simhash。(SHA算法局部不敏感)
- 需要检查两项内容的相似程度时,Simhash很有用
- Diffie-Hellman 密钥交换
- Diffie-Hellman使用两个密钥:公钥和私钥 --非对称加密
- 线性规划
- 线性规划使用Simplex算法,使结果最优化,约束条件是某些变量