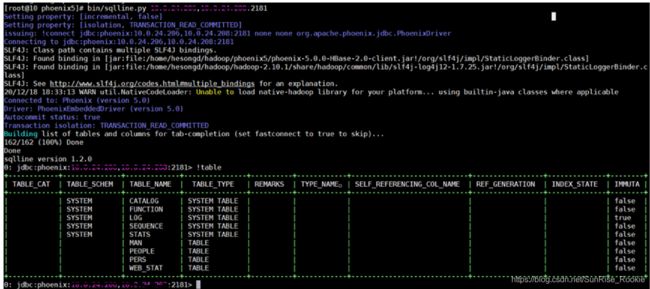
Linux hadoop zookeeper hbase phoenix集群部署
hadoop zookeeper hbase phoenix集群部署
- 1.1. 部署前准备
-
- 1.1.1. 版本
- 1.1.2. 添加节点映射
- 1.1.3. 添加免密登录
- 1.2. zookeeper集群部署
-
- 1.2.1. 编辑环境变量
- 1.2.2. zookeeper配置:
- 1.2.3. 创建myid文件
- 1.3. hadoop集群部署
- 1.4. hbase集群部署
-
-
- 编辑regionservers文件
-
- 1.5. phoenix安装
1.1. 部署前准备
1.1.1. 版本
创建一个hadoop用户 上传hadoop zookeeper hbase phoenix安装包,注意版本对应关系,本次安装使用的是hadoop-2-10-1,hbase-2.2.6,zookeeper-3.6.2,phoenix-5.0.0
Jdk-1.8.0_181
创建hadoop用户
使用root账号进行
1.1.2. 添加节点映射
Hostname 主机ip

修改后 使用hostname 命令查看 是否修改成功
在每台服务器上修改
vim /etc/hosts
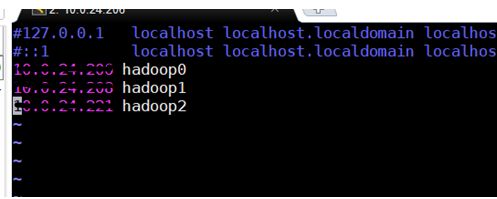
使用自己的主从节点ip 后面为别名
1.1.3. 添加免密登录
在hadoop0上执行
ssh-keygen -t rsa 一直按回车
#让 hadoop0节点也能无密码 SSH 本机
cat ./id_rsa.pub >> ./authorized_keys
#完成后可执行ssh hadoop0验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。
ssh -p 2112 hadoop0
#在hadoop0节点将上公匙传输到hadoop1、hadoop2节点
scp ~/.ssh/id_rsa.pub hadoop1:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop2:/home/hadoop/
在hadoop1、hadoop2机器执行
su - hadoop
mkdir .ssh # 如果没有该目录,则新建.ssh目录
cat id_rsa.pub >> ~/.ssh/authorized_keys
rm id_rsa.pub
su - root
chmod 700 -R /home/hadoop
chmod 644 /home/hadoop/.ssh/authorized_keys
在hadoop0上进行验证
su - hadoop
ssh -p 2112 hadoop1
ssh -p 2112 hadoop2
1.2. zookeeper集群部署
解压安装包
tar -zxvf zookeeper_3.6.2.tar.gz
mv zookeeper_3.6.2 zookeeper
创建文件夹
mkdir /home/hadoop/zookeeper/data (zk的数据目录)
1.2.1. 编辑环境变量
vim ~/.bashrc
添加
export ZOOKEEPER_HOME=/home/hadoop/zookeeper(自己的zk目录)
export PATH= P A T H : PATH: PATH:ZOOKEEPER_HOME/bin
使环境变量生效
source .bashrc
1.2.2. zookeeper配置:
zoo_sample.cfg 重命名为 zoo.cfg,
tickTime: ZooKeeper 中使用的基本时间单元, 以毫秒为单位, 默认值是 2000。它用来调节心跳和超时。例如, 默认的会话超时时间是两倍的 tickTime。
initLimit: 默认值是 10, 即 tickTime 属性值的 10 倍。它用于配置允许 followers 连接并同步到 leader 的最大时间。如果 ZooKeeper 管理的数据量很大的话可以增加这个值。
syncLimit: 默认值是 5, 即 tickTime 属性值的 5 倍。它用于配置leader 和 followers 间进行心跳检测的最大延迟时间。如果在设置的时间内 followers 无法与 leader 进行通信, 那么 followers 将会被丢弃。
dataDir: ZooKeeper 用来存储内存数据库快照的目录, 并且除非指定其它目录, 否则数据库更新的事务日志也将会存储在该目录下。建议配置 dataLogDir 参数来指定 ZooKeeper 事务日志的存储目录。
clientPort: 服务器监听客户端连接的端口, 也即客户端尝试连接的端口, 默认值是 2181。
集群模式中, 集群中的每台机器都需要感知其它机器, 在 zoo.cfg 配置文件中, 可以按照如下格式进行配置, 每一行代表一台服务器配置:
server.id=host:port:port
id 被称为 Server ID, 用来标识服务器在集群中的序号。同时每台 ZooKeeper 服务器上, 都需要在数据目录(即 dataDir 指定的目录) 下创建一个 myid 文件, 该文件只有一行内容, 即对应于每台服务器的Server ID。
ZooKeeper 集群中, 每台服务器上的 zoo.cfg 配置文件内容一致。
server.1 的 myid 文件内容就是 “1”。每个服务器的 myid 内容都不同, 且需要保证和自己的 zoo.cfg 配置文件中 “server.id=host:port:port” 的 id 值一致。
id 的范围是 1 ~ 255。
ticketTime=2000
clientPort=2181
dataDir=/home/zookeeper/data(自己的目录)
dataLogDir=/home/zookeeper/logs(自己的目录)
initLimit=10
syncLimit=5
server.1=hadoop0:2888:3888
server.2=hadoop1:2888:3888
server.3=hadoop2:2888:3888
1.2.3. 创建myid文件
在 dataDir 指定的目录下 (即 /home/hadoop/zookeeper/data 目录) 创建名为 myid 的文件, 文件内容和 zoo.cfg 中当前机器的 id 一致。根据上述配置, master 的 myid 文件内容为 1。
vim /home/hadoop/zookeeper/data/myid
1
按照相同步骤, 为 hadoop1和 hadoop2配置 zoo.cfg 和 myid 文件。
zoo.cfg文件内容相同,
hadoop1的 myid 文件内容为 2,
hadoop2的 myid 文件内容为 3。
在集群中的每台机器上执行以下启动命令:
zkServer.sh start
查看启动信息
./zkServer.sh status

主节点的mode 为 leader
从节点为 follower
1.3. hadoop集群部署
在hadoop目录下
#解压
tar -xvf hadoop_2.10.1.tar.gz
#目录重命名
mv hadoop_2.10.1.tar.gz hadoop
配置环境变量
Vim /etc/profile

执行 下面命令 使资源生效
source /etc/profile
修改配置
集群模式需要修改 hadoop 中的配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、hadoop-env.sh 。
文件 slaves
将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。本教程让Master节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:hadoop1和hadoop2。
在 /home/hesongd/hadoop/hadoop-2.10.1/etc/hadoop/目录下
vi slaves
添加如下内容
hadoop1
hadoop2
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/hesongd/hadoop/hadoop-2.10.1/tmp value>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop0:8020value>
property>
configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode..http-addressname>
<value>hadoop0:50070value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop1:50090value>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>hd
<property>
<name>dfs.namenode.name.dirname>
<value>file: /home/hesongd/hadoop/hadoop-2.10.1/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file: /home/hesongd/hadoop/hadoop-2.10.1/hdfs/datavalue>
property>
configuration>
将mapred-site.xml.template 重命名为 mapred-site.xml 然后修改配置:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop0:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop0:19888value>
property>
configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHadnlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>hadoop0: 8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>hadoop0:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>hadoop0:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>hadoop0:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>hadoop0:8088value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
configuration>
Hadoop-env.Sh
修改java_home 并添加如下
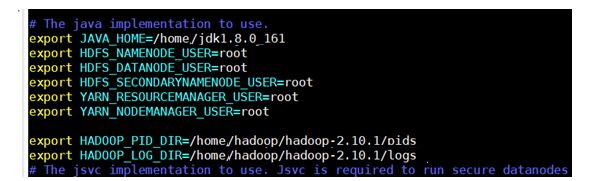
配置好后,将Master上的 /home/hesongd/hadoop/hadoop-2.10.1/ 文件夹复制到各个节点上。
在Master节点上执行:
Scp -r /home/hesongd/hadoop/hadoop-2.10.1/ hadoop1: /home/hesongd/hadoop
scp -r /home/hesongd/hadoop/hadoop-2.10.1/hadoop2: /home/hesongd/hadoops
首次启动需要先在 hadoop0 节点执行 NameNode 的格式化:
hdfs namenode -format #首次运行需要执行初始化,之后不需要
启动hadoop
/home/hesongd/hadoop/hadoop-2.10.1/sbin 下
./start-all.sh
查看启动情况
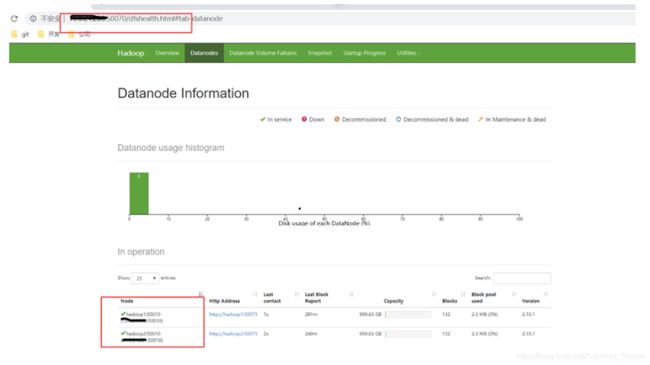
此时表示启动成功 有两个从节点hadoop1、hadoop2, 一个主节点hadoop0。
停止hadoop集群
在 sbin目录下
./stop-all.sh
Hadoop 集群安装成功
1.4. hbase集群部署
解压hbase安装包
在/home/hesongd/hadoop/hbase/config目录下
vim hbase-env.sh
修改JAVA_HOME
export JAVA_HOME=本机java地址
HBASE_MANAGES_ZK变量,此变量默认为true,告诉HBase是否启动/停止ZooKeeper集合服务器作为HBase启动/停止的一部分。如果为true,这Hbase把zookeeper启动,停止作为自身启动和停止的一部分。如果设置为false,则表示独立的Zookeeper管理。我们将其设置为false.
export HBASE_MANAGES_ZK=false
修改Hbase堆设置,将其设置成4G,
export HBASE_HEAPSIZE=4G
编辑配置文件hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.quorumname>
<value>zookeeper集群的地址value>
property>
<property>
<name>hbase.rootdirname>
<value>hdfs:hadoop0:9000/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/home/hesongd/hadoop/hbase//tmpvalue>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
configuration>
hbase.zookeeper.quorum: 这个参数是用来设置zookeeper服务列表,每个服务器之间使用使用逗号分隔,2181是zookeeper默认端口号,你可以自行根据你的端口号添加,默认的端口号加不加都无所谓。
hbase.rootdir: 这个参数是用来设置RegionServer 的共享目录,用来存放HBase数据。特别需要注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。
hbase.cluster.distributed: HBase 的运行模式。为 false 表示单机模式,为 true 表示分布式模式。
编辑regionservers文件
配置从服务器,去掉 localhost,添加 slaves 节点
hadoop1
hadoop2
把 hadoop 的 hdfs-site.xml 复制一份到 hbase 的 conf 目录下
如果需要添加备用主节点需要手动添加
vim backup-masters 里面写备份的主节点 我们这里使用hadoop1作为备份主节点
将配置好的 habase 分发到其它节点对应的路径下
scp -r /home/hesongd/hadoop/hbase hadoop1: /home/hesongd/hadoop
scp -r /home/hesongd/hadoop/hbase hadoop2:/home/hesongd/hadoop
分别在三台服务器上增加HBASE_HOME环境变量,修改vim /etc/profile
export HBASE_HOME=(hbase路径)
export PATH=$HBASE_HOME/bin:$PATH
使配置生效
source /etc/profile
启动hbase 集群
/home/hesongd/hadoop/hbase/bin
./start-hbase.sh
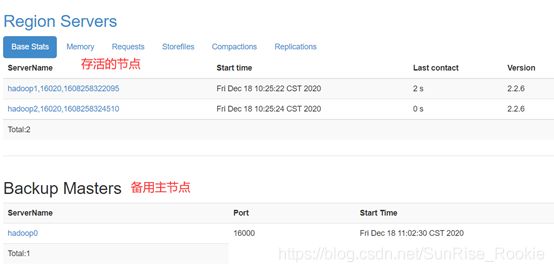
停止hbase 集群
./spot-hbase.sh
Hbase 集群搭建完成
1.5. phoenix安装
解压 phoenix
重命名为 phoenix-5.0.0
将hbase的hbase-site.xml 文件复一份到phoenix的 bin 目录下
将phoenix中的
这三个jar包复制一份在hbase中lib包中
重启hbase集群
在phoenix 目录下使用此命令连接hbase
ip为zookeeper集群的任一或多个ip 加zookeeper的端口
!quit 退出当前连接 单ip写法
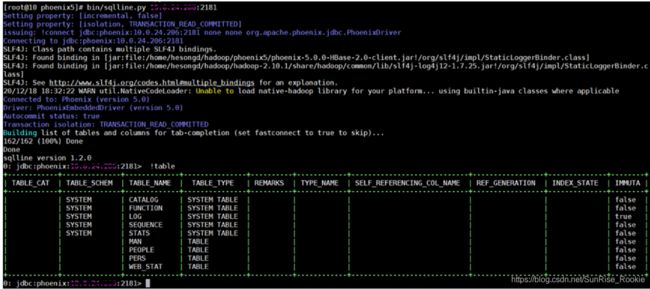
多ip写法