2021招行Fintech数据赛Rank15开源分享
一、赛题理解
- 时序预测、回归类问题
任务一:预测未来一个月,A/B两个岗位按天的业务量
任务二:预测未来一个月,A/B两个岗位每天48个时段的细分业务量(半小时一个时间段) - 数据:
date:日期
post_id:A、B两种业务类型
biz_type:业务类型细分,A有13种,B只有一种
period:时段(每天48个)
amount:业务量(label)
PS;我又截图截晚了,官网只剩下这点了。。

二、数据预处理
- 周期性
取2020年11月的数据观察,分A/B两种业务类型,可以发现具有明显的周期性。
- A类型:以一周为周期,工作日业务量大,周末骤减,且周六业务量总大于周日业务量。

- B类型:以一周为周期,工作日业务量大,周末基本为0。11月数据有上升趋势(这一点比赛时有些忽视)。

2. 对称性:
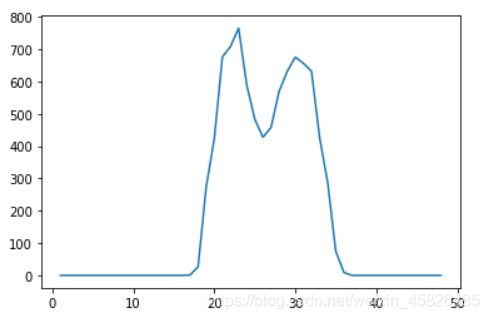
取任意一天数据,可以观察出明显的对称性。
- 工作时间有业务量,非工作时间业务量为0。中午时间会有短暂的业务量下降,以正午时刻为对称轴,业务量有对称趋势。
- 同时,周中也会有对称性:周一、周五业务量较大,周三业务量会下降。
- 异常数据
由于跨越了2020年初的这段时间(疫情影响),所以,业务量会有不规则突变,考虑将这部分数据剔除。
训练集数据仅选取2020年4月以后的数据 - 数据筛选
由于预测的11、12月均没有节日和调休情况出现,所以去掉’NH’,‘SS’,'WS’三种类型的数据。
三、特征工程
- 基础特征:年、月、日等时间特征
- 原始重要特征:periods(时段)、WKD_TYP_CD(指示是否是工作日)
- 周期性特征:
dayofweek(星期几):用于刻画周期性 - 对称性特征:
abs_period:与中间时段的绝对值差,能体现正午对称性。
abs_week:以周三为对称轴的绝对值差,周末置为0。 - 趋势性特征:年底业务量增大,刻画出向上递增的趋势。
week_num:一年内的周数(1-52)
day_num:一年内的天数(1-365) - 其他特征:
work_time:刻画工作时间的特征
q1:特征交叉,强特增益。(效果不明显,不过其他比赛可以用)
四、模型优化
比赛时囤积了不少模型,从最开始开源的lightgbm开始,后面又做了XGB、catboost、RandomForest等等(全部都是树模型)。
- 模型选择:XGB
无论是A榜还是B榜,XGB都表现出非常好的稳定性。
A榜任务一单模:0.0505
B榜任务二单模:0.1699 - 做法:由于A/B换榜时shake了一下。任务一换榜之后,单模0.1,但任务二XGB单模能到0.169,任务二预测较为稳定准确。最后通过分析数据走势,采取通过任务二按天汇总(求和)得到任务一按天的结果,此方式0.08255。
- 网格搜索调参:有一定的提升,但只在万分位上提升了一点点吧。
- 换评价函数MAPE:之前一直选取的是xgb自带的rmse评价指标,B榜突发奇想换了一下,对于B类型的业务有不小的提升。0.169—>0.164
五、规则与Trick
- 调整系数
由于年底业务量增加,特征和模型对于这部分识别不到位,需要人为的去调整一下。A/B类型业务分开乘以系数。
0.08225–>0.063左右 - 放缩操作
由于任务一调整系数之后预测的准确率较高,将任务二的每个时段占全天业务量的比例计算出来,乘以任务一中每天的业务量,对于任务二的数据按比例放缩。
0.163–>0.147左右
六、最终结果
任务一:0.062
任务二:0.147
总分:0.08752
七、总结与感悟
又到了矫情阶段,求轻喷555~~
- 数据为基、特征为王:
真的是数据竞赛永恒不变的真理。
(1)看榜一大佬,只多加了2018年10-12月的数据,多做了两个节假日前后标识特征,任务一能上到0.048+。数据筛选做的好,特征构造的巧,上分如喝水。
(2)我本人当时limzero大佬开源baseline之后,只加了一个貌似week_num特征就从0.11–>0.095,可见特征重要性。 - 多做图多观察:
在写这篇分享帖时,为了让周期性和对称性展示的更明显,特地去画了几张图,观察到了比赛时没有发现的规律:B业务每周整体有一个向上的递增,趋势性十分明显。如果早点观察到这一点,我可能会在乘系数阶段对B业务每周乘以不同的系数,呜呜呜,千金难买早知道啊,哎~ - 对规则部分可以刻画的更细致一些。
比如:上面说的每周递增
再比如:不光是用乘法,可以加一个值说不定有好的效果呢。 - 模型要多元化
该学学别的模型了,别总用那几个树模型(此处应该配一张锤自己脑壳儿的表情包hhh)。看大佬们分享的prophet、时间序列分解等等,应该勇于创新,不能总停留在一个“舒适区”。这样A/B换榜时,储存多个模型也不容易被shake下去。 - 不管怎么说,还是要感谢limzero大佬的开源分享,在基础上二次创新,让我A榜能很快上到一个非常高的分(A榜0.078,rank3)。
- 多总结多分享。
我是看别人baseline一点点学习数据竞赛的,不断成长。所以,也想把这份爱心传递下去吧,在总结分享的过程中,也是对自己的学习方法一种复习,如果能帮助到大家就更好了,嘻嘻~ - 最后,还是要感谢群里各位大佬们的思路分享,开阔视野,一起提升成长。感谢朋友“爱撒谎的小超”、“尼888888”、“不学无墅”的支持与帮助。
附上代码,供参考:
import pandas as pd
import numpy as np
import datetime
import math
import os
# import xgboost as xgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.min_rows', 100)
#--------------------特征工程函数-------------------
def timer(x):
if x in range(18,25):
return 3
elif x in range(25,30):
return 2
elif x in range(30,37):
return 3
elif x in range(37,39):
return 1
else:
return 0
def date_feature(data):
data['type']=data['WKD_TYP_CD'].map({
'WN':0,'SN': 1, 'NH': 1, 'SS': 1, 'WS': 0})
data['date']=pd.to_datetime(data['date'])
data['dayofweek']=data['date'].dt.dayofweek+1
data['day']=data['date'].dt.day
data['month']=data['date'].dt.month
data['year']=data['date'].dt.year
data['week_num']=data['date'].dt.weekofyear
data['abs_period']=data['periods'].apply(lambda x:abs(x-24))
data['day_num']=data['date'].dt.dayofyear
data['abs_week']=data['dayofweek'].apply(lambda x:0 if x in [6,7] else abs(x-3)+1)
data['work_time1']=data['periods'].apply(timer)
data['sin_period']=data['periods'].apply(lambda x:math.sin(x*math.pi/48))
data['q1']=data['abs_period']**2+data['abs_week']**2
data['q2']=data['day_num']**2+data['periods']**2
data['quarter']=data['date'].dt.quarter
data.drop(['date','post_id'],axis=1,inplace=True)
return data
def xgb_model(train_x, train_y, test_x):
predictors = list(train_x.columns)
train_x = train_x.values
test_x = test_x.values
folds = 5
seed = 2021
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros((train_x.shape[0]))
test = np.zeros((test_x.shape[0]))
test_pre = np.zeros((folds, test_x.shape[0]))
total_prevalue_test = np.zeros((folds, test_x.shape[0]))
cv_scores = []
cv_rounds = []
for i, (train_index, test_index) in enumerate(kf.split(train_x, train_y)):
print("Fold", i)
X = train_x[train_index]
Y = train_y[train_index]
fol_x = train_x[test_index]
fol_y = train_y[test_index]
train_matrix = xgb.DMatrix(X, label=Y)
test_matrix = xgb.DMatrix(fol_x, label=fol_y)
evals = [(train_matrix, 'train'), (test_matrix, 'val')]
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'min_child_weight':2,
'max_depth': 12,
'subsample': 0.8,
'colsample_bytree': 0.8,
'learning_rate': 0.05,
'seed': 2021,
'nthread': 8,
}
num_round = 4000
early_stopping_rounds = 200
if test_matrix:
model = xgb.train(params, train_matrix, num_round, evals=evals, verbose_eval=200,
early_stopping_rounds=early_stopping_rounds
)
pre = model.predict(xgb.DMatrix(fol_x),ntree_limit = model.best_iteration)
pred = model.predict(xgb.DMatrix(test_x),ntree_limit = model.best_iteration)
train[test_index] = pre
test_pre[i, :] = pred
cv_scores.append(mean_squared_error (fol_y, pre))
cv_rounds.append(model.best_iteration)
total_prevalue_test[i, :] = pred
print("error_score is:", cv_scores)
test[:] = test_pre.mean(axis=0)
#-----------------------------------------
print("val_mean:" , np.mean(cv_scores))
print("val_std:", np.std(cv_scores))
return train, test, total_prevalue_test, np.mean(cv_scores)
def my_mape(real_value, pre_value):
real_value, pre_value = np.array(real_value), np.array(pre_value)
return np.mean(np.abs((real_value - pre_value) /( real_value+1)))
def eval_score(pre, train_set):
real = train_set.get_label()
score = my_mape(real, pre)
return 'eval_score', score
def xgb_model2(train_x, train_y, test_x):
predictors = list(train_x.columns)
train_x = train_x.values
test_x = test_x.values
folds = 5
seed = 2021
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros((train_x.shape[0]))
test = np.zeros((test_x.shape[0]))
test_pre = np.zeros((folds, test_x.shape[0]))
total_prevalue_test = np.zeros((folds, test_x.shape[0]))
cv_scores = []
cv_rounds = []
for i, (train_index, test_index) in enumerate(kf.split(train_x, train_y)):
print("Fold", i)
X = train_x[train_index]
Y = train_y[train_index]
fol_x = train_x[test_index]
fol_y = train_y[test_index]
train_matrix = xgb.DMatrix(X, label=Y)
test_matrix = xgb.DMatrix(fol_x, label=fol_y)
evals = [(train_matrix, 'train'), (test_matrix, 'val')]
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'min_child_weight':10,
'max_depth': 10,
'colsample_bylevel':0.7,
'subsample': 0.8,
'colsample_bytree': 0.8,
'learning_rate': 0.05,
'seed': 2021,
'nthread': 8,
}
num_round = 4000
early_stopping_rounds = 200
if test_matrix:
model = xgb.train(params, train_matrix, num_round, evals=evals, verbose_eval=200,feval=eval_score,
early_stopping_rounds=early_stopping_rounds
)
pre = model.predict(xgb.DMatrix(fol_x),ntree_limit = model.best_iteration)
pred = model.predict(xgb.DMatrix(test_x),ntree_limit = model.best_iteration)
train[test_index] = pre
test_pre[i, :] = pred
cv_scores.append(mean_squared_error (fol_y, pre))
cv_rounds.append(model.best_iteration)
total_prevalue_test[i, :] = pred
print("error_score is:", cv_scores)
test[:] = test_pre.mean(axis=0)
#-----------------------------------------
print("val_mean:" , np.mean(cv_scores))
print("val_std:", np.std(cv_scores))
return train, test, total_prevalue_test, np.mean(cv_scores)
#读取数据
train=pd.read_csv('./data/train_v2.csv')
test2=pd.read_csv('./data/test_v2_periods.csv')#按0.5h计算
week=pd.read_csv('./data/wkd_v1.csv')
week=week.rename(columns={
'ORIG_DT':'date'})
train['date']=pd.to_datetime(train['date'], format='%Y/%m/%d')
test2['date']=pd.to_datetime(test2['date'], format='%Y/%m/%d')
week['date']=pd.to_datetime(week['date'], format='%Y/%m/%d')
#数据处理
train_period_A=train[train['post_id']=='A'].copy()
train_period_A.reset_index(drop=True,inplace=True)
train_period_A=train_period_A.groupby(by=['date','post_id','periods'], as_index=False)['amount'].agg('sum')
train_period_B=train[train['post_id']=='B'].copy()
train_period_B.reset_index(drop=True,inplace=True)
train_period_B.drop(['biz_type'],axis=1,inplace=True)
train_period_A=train_period_A.merge(week)
train_period_B=train_period_B.merge(week)
train_period_A['amount']=train_period_A['amount']/1e4
train_period_B['amount']=train_period_B['amount']/1e4
train_period_A=train_period_A[~train_period_A['WKD_TYP_CD'].isin(['NH','SS','WS'])]
train_period_B=train_period_B[~train_period_B['WKD_TYP_CD'].isin(['NH','SS','WS'])]
train_period_A=date_feature(train_period_A)
train_period_B=date_feature(train_period_B)
test_period_A=test2[test2['post_id']=='A'].reset_index(drop=True)
test_period_B=test2[test2['post_id']=='B'].reset_index(drop=True)
test_period_A=test_period_A.merge(week)
test_period_B=test_period_B.merge(week)
test_period_A=date_feature(test_period_A)
test_period_B=date_feature(test_period_B)
test_period_A.drop(['amount'],axis=1,inplace=True)
test_period_B.drop(['amount'],axis=1,inplace=True)
print("训练集维度:",train_period_A.shape)
print("测试集维度:",test_period_A.shape)
#-----------------------树模型-----------------------
feature=['periods','type','year','month','day','dayofweek','week_num','abs_period','day_num','abs_week','work_time1','q1']
#-------筛选数据月份---------
month_num=3
#----------------------------
train_input=train_period_A#训练集
train_input=train_input[(train_input['year']==2020) & (train_input['month']>month_num)].reset_index(drop=True)
test_input=test_period_A#测试集
train_x = train_input[feature].copy()
train_y = train_input['amount']
test_x = test_input[feature].copy()
print('特征维度A:',train_x.shape)
xgb_train, xgb_test, ol, cv_scores = xgb_model(train_x, train_y, test_x)
xgb_test_A=[i if i>0 else 0 for i in xgb_test]
#
train_input=train_period_B#训练集
train_input=train_input[(train_input['year']==2020) & (train_input['month']>month_num)].reset_index(drop=True)
test_input=test_period_B#测试集
train_x = train_input[feature].copy()
train_y = train_input['amount']
test_x = test_input[feature].copy()
print('特征维度B:',train_x.shape)
xgb_train, xgb_test, ol, cv_scores = xgb_model2(train_x, train_y, test_x)
xgb_test_B=[i if i>0 else 0 for i in xgb_test]
#
#------------------拼接文件------------------
pre_period=[]
pre_hour_A=xgb_test_A
pre_hour_B=xgb_test_B
len_day=int(len(pre_hour_A)/48) #天数
for i in range(len_day):#每一天
for j in range(48):#每一个时间段
pre_period.append(1e4*pre_hour_A[48*i+j])
for j in range(48):
pre_period.append(1e4*pre_hour_B[48*i+j])
test2['amount']=pre_period
test2['amount']=(test2['amount']).astype(int) #变为整数
test2['date']=test2['date'].dt.strftime('%Y/%#m/%#d')
#汇总预测结果得到test1
test2['date']=pd.to_datetime(test2['date'], format='%Y/%m/%d')
test1=test2.groupby(by=['date','post_id'],as_index=False)['amount'].agg('sum')
#调整test1
test1A=test1[test1.post_id=='A'].copy()
test1B=test1[test1.post_id=='B'].copy()
test1A['amount']=test1A['amount']*1.07
test1=pd.merge(test1,test1A,on=['date','post_id'],how='left')
test1B['amount']=test1B['amount']*1.032
test1=pd.merge(test1,test1B,on=['date','post_id'],how='left')
test1.fillna(0,inplace=True)
test1['amount']=test1['amount_y']+test1['amount']
test1['amount']=(test1['amount']).astype(int)
test1.drop(['amount_x','amount_y'],axis=1,inplace=True)
#规划test2(使用每天总和)
test1['amount']=test1['amount'].apply(lambda x:0 if x<200 else x)
temp=test2.groupby(by=['date','post_id'],as_index=False)['amount'].agg({
'amount_sum': 'sum'})
test1=pd.merge(test1,temp,on=['date','post_id'],how='left')
test2=pd.merge(test2,test1,on=['date','post_id'],how='left')
test2['amount']=test2['amount_x']/test2['amount_sum']*test2['amount_y'] #规划
test2.fillna(0,inplace=True)
test2['amount']=test2['amount'].astype(int)
#
test1.drop(['amount_sum'],axis=1,inplace=True)
test2.drop(['amount_x','amount_y','amount_sum'],axis=1,inplace=True)
test1['date']=test1['date'].dt.strftime('%Y/%#m/%#d')
test2['date']=test2['date'].dt.strftime('%Y/%#m/%#d')
#输出结果
if not os.path.exists('zhengty/'):
os.makedirs('zhengty/')
test1.to_csv('zhengty/final_test1.txt',sep=',',index=False)
nku_zhengty
2020.05