论文笔记 | Transformer-XL:Attentive Language Models Beyond a Fixed-Length Context
作者:韩
单位:燕山大学
论文地址:https://arxiv.org/pdf/1901.02860.pdf
代码地址:https://github.com/kimiyoung/transformer-xl
目录
- 一、Transformer
- 二、vanilla Transformer
- 三、Transformer-XL
-
- 3.1 片段级递归机制
- 3.2 相对位置编码机制
- 四、实验分析
- 五、总结
一、Transformer
目前在NLP领域中,处理语言建模问题最先进的基础架构即Transformer。2017年6月,Google Brain在论文《Attention Is All You Need》中提出了Transformer架构,其模型设计完全摒弃了RNN的循环机制,采用一种self-attention的方式进行全局处理。接收一整段文本序列,并使用三个可训练的权重矩阵——Query、Key和Value来一次性学习输入序列中各个部分之间的依赖关系。因此解决了RNN中的长距离依赖、无法并行计算的缺点,也解决了CNN中远距离特征捕获难的问题。
Transformer网络由多个层组成,每个层都由多头注意力机制和前馈网络构成。由于在全局进行注意力机制的计算,忽略了序列中最重要的位置信息。因此Transformer为输入添加了位置编码(Positional Encoding),使用正余弦函数为每个部分生成位置向量,用于帮助网络学习其位置信息。其结构如下图所示:


这种架构目前来看已经取得了令人瞩目的成就,但其存在的缺点也极为明显:
- 首先在理论上Transformer模型可以学习到输入文本的长距离依赖关系和全局特性,但在语言建模中受到固定长度上下文的限制,一般默认设置的最大序列长度为512,因此Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。
- 其次在处理长文本时传统的做法为对输入的文本进行分段,即将文本划分为多个segment,将每一个segment分别进行计算,这就造成了每个segment之间没有任何的信息交互进而导致上下文碎片化(context fragmentation)。
二、vanilla Transformer
2018年Al-Rfou等人基于Transformer提出了一种训练语言模型的方法《Character-Level Language Modeling with Deeper Self-Attention》,根据之前的字符预测序列中的下一个字符。例如:它使用 x 1 , x 2 , . . . , x n − 1 x_1,x_2,...,x_{n-1} x1,x2,...,xn−1预测字符 x n x_n xn,而在 x n x_n xn之后的序列则被mask掉。但模型仅限于处理 512个字符这种相对较短的输入,因此它将输入分成多个segment,并分别从每个segment中进行学习,如下图所示。 在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。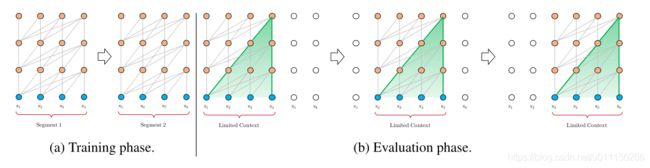
我们可以很清楚的发现,每个segment之间是没有任何交互的,并且在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
三、Transformer-XL
基于以上问题2019年Zihang Dai等提出了Transformer-XL架构,Transformer-XL在vanilla Transformer的基础上引入了两点创新:
- 片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell,记录每个segme信息),用来建模segment之间的联系。使得片段之间产生交互,解决上下文碎片化问题。
- 相对位置编码机制(relative position embedding scheme),引入相对位置编码代替绝对位置编码。在memory的循环计算过程中,避免时序混淆,位置编码可重用。
3.1 片段级递归机制
在结构设计上Transformer-XL仍然是使用切分segment的方式进行建模,但其与vanilla Transformer有本质的不同,主要区别为Transformer-XL引入了segment与segment之间的循环机制,使得当前segment在建模的时候能够利用之前segment的信息来实现长期依赖性。实现方法为每次计算后都会缓存一个segment的信息即本次计算的hidden state,在下次计算new segment时将之前保存的hidden state与本次的hidden state拼接在一起,再进行后续计算。由于会缓存前一个segment的信息,因此在推理的时候每次移动窗口都不需要重新进行计算,进而极大地缩减了计算时间,其具体结构如下图所示:

在模型的训练阶段,我们可以清楚的看到,每个segment隐藏层都会接收两部分输入:
- 第一部分是本次计算的segment隐藏层的输出,这部分与vanilla Transformer相同。
- 第二部分是上次计算保留的segment信息,也就是前一个segment隐藏层的输出,其作用是可以使模型创建长期依赖关系。
之后对这两部分输入进行拼接操作,用于计算当前segment的Key和Value矩阵。对于某个segment的某一层的具体计算公式如下:
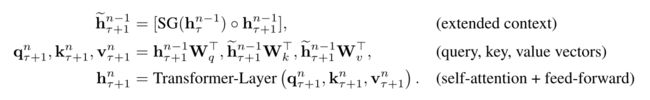
其中h表示的是hidden state, τ τ τ表示第 τ τ τ个segment,SG函数表示的是不更新梯度,[ h i h_i hi∘ h j h_j hj]表示在相同维度上的两个隐层状态的拼接, W W W是 q q q, k k k, v v v的权重矩阵。因此第一个公式的意思即:第 τ + 1 τ+1 τ+1个segment的第 n − 1 n-1 n−1层的hidden state 等于第 τ τ τ个segment第 n − 1 n-1 n−1层的hidden state拼接上第 τ + 1 τ+1 τ+1个segment第 n − 1 n-1 n−1层的hidden state。但有一点需要注意,此时的 q q q矩阵是由未拼接的hidden state计算得出, k k k、 v v v是由拼接后的hidden state计算得出的,因为 q q q表示的是当前的segment,所以不需要拼接(此处的原理类似于Transformer中的enc-dec-attn)。同时与vanilla Transformer每次只能前进一个step,并且需要重新构建segment,并全部从头开始计算有本质区别,Transformer-XL中,每次可以前进一整个segment,并利用之前段的数据来预测当前segment的输出,这也正是Transformer-XL的核心点。
通过公式可以看到,对于第一个segment来说,hidden state是没有额外需要拼接的值的,从第二个segment开始才需要拼接,在论文中,每次都是和上一个segment进行拼接,理论上来说每次可以拼接多个segment,但一般情况下保存一个segment进行拼接就已经足够了,因为文本本身的依赖关系一般也不会超过一个segment的距离。
3.2 相对位置编码机制
在Transformer中,一个非常重要的点是Transformer将整个序列同时输入到模型中,因此丧失了输入序列的位置信息。在传统的Transformer中,通过使用正余弦函数计算输入序列的位置信息(Positional Encoding),也就是绝对位置编码。但是在Transformer-XL的递归机制中,模型首先会将输入文本分割成多个segment,如果仅仅对于每个segment直接使用Transformer中的绝对位置编码,即每个不同segment在同一个位置上使用相同的位置编码,就会出现问题。比如,第 i − 1 i-1 i−1个segment和第 i + 1 i+1 i+1个segment的第一个位置将具有相同的位置编码,但它们对于第 i i i个segment的建模重要性显然并不相同。同时,在多个segment的情况下,我们假设每个segment的长度为5,那么第 j j j个segment中的1号位置,在递归机制中会注意到第 j − 1 j-1 j−1个segment的4,5号位置信息,如果此时使用的仍然是绝对位置编码,那必然会造成时序混乱问题。因此,在Transformer-XL的递归机制中需要一种新的位置编码方式来保证模型学习到正确的编码信息。
这里相对位置编码对原来attention score计算进行了一些修改,原始Transformer中attention的计算是采用如下公式:
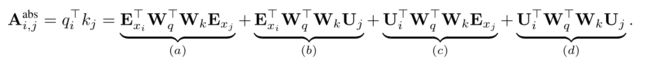
其中U就是绝对位置编码,由于在开始计算embedding的时候是使用的加法,所以可以拆成b和d两部分。新的attention score计算公式如下:

考虑一下在注意力机制中,当query与key进行计算时,实际上并不需要知道key的绝对位置编码,因为模型实际上需要知道的只是输入文本中词的顺序。所以,知道query与key的相对位置即可。因此Transformer-XL做出了几点改动:
- 将绝对位置编码换成相对位置编码R,这里和原始的Transformer是一样的,都是使用的正弦编码矩阵,因此这是一个固定编码,不需要学习。
- 将查询的 U i U_i Ui, W q W_q Wq向量转化为一个可学习的参数向量。
- 在原来计算q,k,v的时候,embedding和position embedding时使用的同一个参数进行线性变换。但是在这里转换成了不同的参数,即 W K , E W_{K,E} WK,E和 W K , R W_{K,R} WK,R。
更新后的transformer-xl的完整的计算公式如下:

四、实验分析
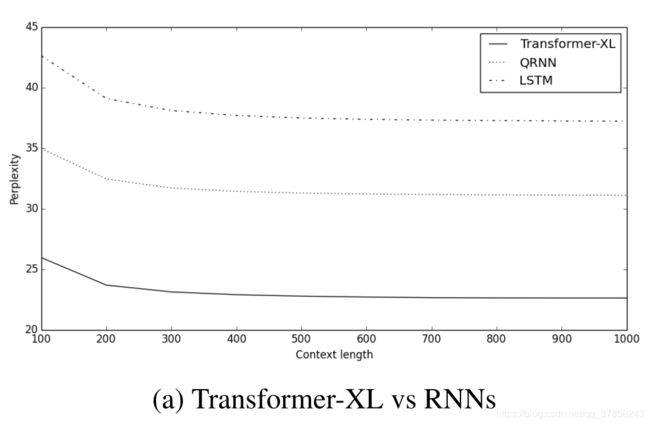
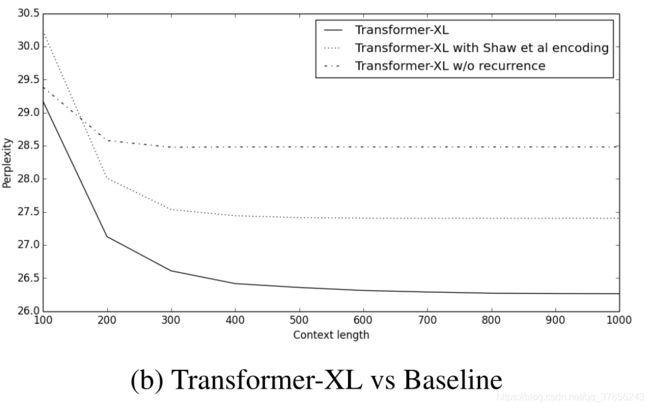
Transformer-XL从语言模型建模指标出发,比较了模型在单词级别和字符级别上不同数据集的表现,并且与RNN和vanilla Transformer都做了比较。实验证明,Transformer-XL在各个不同的数据集上均实现了目前的SoTA:在大型单词级别数据集WikiText-103上,Transformer-XL将困惑度从20.5降到18.3;在enwiki8数据集上,12层Transformer-XL的bpc达到了1.06,24层Transformer-XL的bpc更是达到了0.99;在One Billion Word数据集上和Penn Treebank数据集上也取得了SoTA的效果,前者的困惑度从23.7到21.8,后者的困惑度从55.3到54.5。表明了Transformer-XL的先进性能。具体对比结果如下图所示:
五、总结
Transformer-xl主要解决的就是长距离依赖的问题,同时提高了模型的推理速度。在几种不同的数据集(WikiText-103、enwiki8、text8、lm1b)均实现了最先进的语言建模结果。但目前并未尚未在具体的NLP任务上进行应用,如文本摘要、阅读理解等。同时论文中也没有对基于Transformer模型所设计的预训练模型进行比较,如BERT等。因此虽然Transformer-XL在语言建模上有着很大的优势,但是在实际应用中的价值仍然有待确定。