写在前面的话
酱酱,又到了程序媛拯救世界的时间,程序猿们解决不了的问题看来又只能靠我们女程序员来帮大家解决了。不好意思,我又要纰漏网上一大堆程序猿们在写这个知识点中存在的众多错误了。我们就是要保证科学的严谨性以及正确性吗,而且这个课是我最爱的老师讲的,不能让这么美妙的科学被毁了
酱酱,宝宝只做能力范围内最好的研究~~~biubiu
这篇文章主要的贡献当然是来自于我们伟大是standford 的课件还有老师上课的讲解了。我只是知识的搬运工
Background运用背景
怎么发现“相似”的集合或者项在一个非常大的集合里而不需要一个一个的比较(两两对比)。因为这样的比较是一个二次方的时间复杂度,所以我们的LSH就这样应运而生啦
Locality Sensitive Hashing(LSH) 一般的思想就是hash items (项)到一个桶里(bins)很多次,并且留意在同一个bin 里的items
仅仅只有那些高相似度的items 有更多的可能在同一个桶里。
相似的文档是由相似的集合组成的。
许多的数据挖掘问题都可以表示为发现相似的集合的问题:
网页有很多的相似的词汇,可以用来根据主题来分类
电影的推荐系统
根据某个电影找到喜欢同类电影的人
相似的文档例子
1. 镜像网站(mirror sites)
2. 剽窃问题 包括大量的引用
3. 相似的新闻在很多的不同的网站
Big pitcture
基本概念
shingling: 表示的是对一个文档的转换 ,可以理解为对一个文档进行切割
minhashing: 将一个大的集合中的元素转换为很多短小的签名,但是保持了这些集合中的元素的相似性
Locality-sensitive hashing: 关注的是签名对可能的相似性
整体架构
一下这个图揭示了Locality Sensitive Hashing 的一个整体结构图。

当接受到文档,或者输入文档之后,我们开始shingling 他们,就是将这个文档切割成一个一个的元素,这些元素是由很多的字符串组成的(由k个字符串组成)
用Minhashing 得到我们集合元素的签名
产生可能的候选对
Shingles
K-shingle
又叫做是k-gram 。一个文档可以看成是K个字符组成的一个集合。
这个概念该什么NLP的同学应该很熟悉了,在我之前的文章中也有提到了,怎么得到我们的shingles. 还有代码的呢。
例如; k=2; doc=adcab 这个集合的2-shingles={ab,ba,ca}
我们对这个字符串进行划分,得到的是ad dc ca ab 由于集合是唯一性的所以不可能有重复的元素
k=2 其实是一个比较糟糕的选择,我们一般选择K在实际情况中一般会选择9或者10,我们要求这个k一般要大于我们文章中出现的单词的长度。这样的选择会比较合理一些
Shingles 和相似性
文档如果是相似的,那么他们理论上(intuitively)应该有很多的shingles 是相同的。这里的相似其实是指的是在文本上的相似 text similarity 不涉及到我们说的其他的主题相似等另外一些情况。
交换文档的两个段落只会影响 2k 的shingles 在段落的边界处
e.g.
k=3, “The dog which chased the cat” 转换成 “The dog that chased the cat”.
这个时候被替换的3-shingles 就是g_w, wh, whi, hic, ich, ch, and h_c
MinHashing
在介绍MinHashing 之前我们有必要来介绍一些重要的基本概念。在这里最重要的就是我们的Jaccard Similarity
Jaccard Similarity
Jaccard similarity 指的就是两个集合交集的个数除以两个几何并集的个数
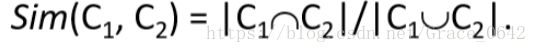
看下面这个例子我们也可以理解:

在这里有两个集合,交集中元素的个数是3,而并集中元素的个数是8
这个时候我们的Jaccard Similarity 相似度就是3/8
我们来看下面的这个例子来说明我们的列的相似性

这个很好理解,我们看列的相似性,我们只看含有1 的那些行,所以我们的并集个数就是5, 而我们的交集个数就是2 所以相似性就是 0.4
这里需要注意的是,我们的并集不是 0 1,1 0,11,00,我们的交集也不是11,00
这里我们一行一行的看,每一行表示的其实是一个属性值,你这个数据集或者是单个的个体有没有我这个属性,每一行是不同的,而且我们不考虑我们要比较的这两个元素都没有这个特征值

看上面这个图我们也可以很清楚的看到。
但是我们也可以用另一种眼观来看,就是假设只有两列,我们的数据集,也就是说有两个元素,那么行的类型也就是说是有4种就是 A 有B没有或者是A没有B有或者是两个都有或者是两个都没有的情况。
如下图所示:

在这里我们a 看做是两个元素都具有的属性的 个数。
b 就是C1 元素有而C2元素没有的情况的个数。
c 就是C2有而C1元素没有的情况下的个数。
d 就是两个元素都没有的情况下的个数。
所以我们的Jaccard Sim = a/(a+b+c)
定义
minhash 函数 h(c) = 表示的是在某一列中的第一个出现1的那一行的行号,我们用这个行号中第一次出现1的那个行来做我们这个矩阵的那一列的特征值。
如下图所示,这里有一个矩阵

我们对这个矩阵的每一行标注一个号码,就是紫色的这个部分
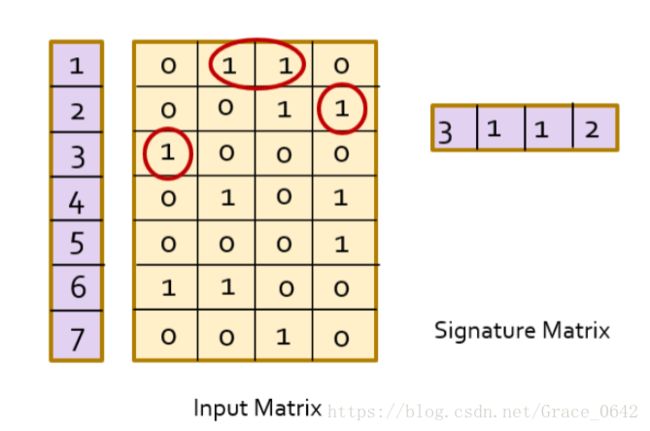
从这里我们可以看出我们的输入的这个布尔矩阵的可以得到一个特征矩阵
这个时候我们的到的一个签名矩阵 就是这个 输入矩阵的第一个出现1的行数 特征值是3,1,1,2
接下来我们对我们的这个输入矩阵进行重拍,得到一个新的矩阵。

我们在对这个输入矩阵进行第三次的重排,这个时候我们又可以得到一个新的特征值
我们对这个矩阵重拍之后得到一个新的矩阵,绿色的那个表示重排之后 这个时候它表示的第一排是最后一排,最后一排是第一排的意思。

得到的特征值就是 2,2,1,3
为什么这么做,因为我们可以用这个singnature matrix 的相似性(Jaccard similarity) 来表示我们的这个input matrix 的相似性
我们来看我们的这个例子

我们来看我们的 第1列和第2列,这个时候我们需要观察的就是我们的input matrix 这个矩阵。
这两个样本的相似性我们可以看出来是 1/4 根据我们刚才介绍的公式 sim=a/(a+b+c)
我们要比较 第一列和第二列我们拿出这两列来看
0 1
0 0
1 0
0 1
0 0
1 1
0 0
我们只关注有1 的列
0 1
1 0
0 1
1 1
a 的个数是1
并集的个数是4 所以我们得到的是1/4
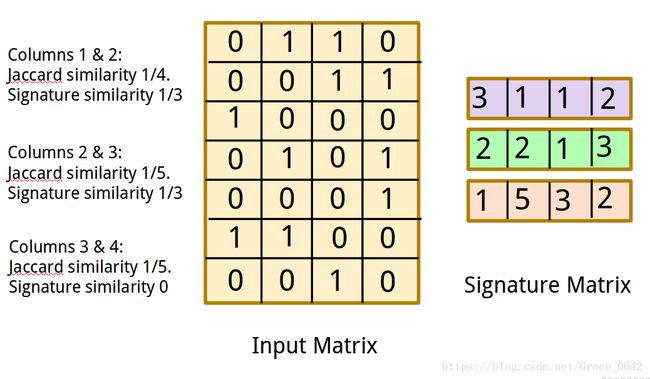
我们看我们的签名矩阵signature matrix
第一列 和第二列拿出来看
3 1
2 2
1 5
签名的相似性 1/3
以此类推我们可以得到我们所求的图中要求的相似性
我们看图中第2 列和第3列 Jaccard similarity 就是 1/5
我们签名的相似性就是1/3
根据上面我们计算分析的例子发现其实我们可以用signature matrix 中hash 值的相似性来表示我们的样本的相似性
这就推理出了我们重要的属性
Surprising Property
这个标题觉得就叫surprising property 比较好,翻译过来我都想不到比较好的词汇,惊奇的属性
我们用MinHash 计算我们的样本 我们的minhash 函数h(C1)=h(C2) 当我们的函数值相等的话,这个时候这个值有很大的可能性等于我们这两列的相似性 sim(C1,C2)
而且他们都等于 a/(b+c+a)
这个结论和我们刚才实验自己计算的结果是一致的!!!
这个也是我们LSH 的原理,在一开始的时候我们也提到了,如果对一些元素进行hash ,他们如果这些元素是相似的或者是相同的,那么他们就有可能被映射到我们的同一个桶里。
更重要的是我们想一想我们的算法
我们是从上往下看找到我们列举的C1 和C2 中出现的第一个1
只有是类型a 的行的时候我们才有 h(C1)=h(C2).如果是类型b 或者是类型c这样是不可能相等的,他们的minhash 的值。
这个其实比较容易能够想明白的,必须同一行都是1才可能出现他们的minhash 是相同的情况。
签名的相似性
签名的相似行就是minhash 函数中 值相同的分数的分子
这句话要怎么理解呢,我们可以看下面这个图

比如说我们要比较的是这个签名矩阵(Signature Matrix )的相似性,我们比较我们的第1列和第二列的相似性,那么我们的签名的相似性就是 我们要比较这两列中行里面的数字相同的个数
我们根据我们的相似性矩阵我们来看;这个矩阵第一列和第二列的相似性就是1/3 ; 在第二行相同。
因此,我们比较希望的是两个签名的相似性和我们原先两个样本也就是两个原始的列,在没有计算MinHash 的原始的两个列的它们两个的Jaccard similarity 要一致,或者说是要接近。
我说的比较啰嗦,也就是签名的相似性和原先矩阵的相似性要是比较接近的或者说是一样的。
这里说的就是我们上面这张图片上显示的在最左边的这个 列的Jaccard Similarity 必须和我们的签名的相似性保持比较接近。怎么能做到保持比较接近呢,当然就是我们的签名的矩阵越长越好了。
我们可以看看下面的这个例子

充分的说明了上面我们说的问题。
好的这里解释完了,我想在这里放上standford 的课件给大家参考一下,尤其是理解一下中文的翻译和理解和英文在表述上的差距,我希望我的讲解能够让各位豁然开朗。

Minhashing 的执行
虽然刚才讲了一堆废话,介绍了我们Minhash 算法以及对应的函数的映射规则,但是一般来说基本上上面等于废话,白说。创造LSH的时候就是为了能够处理大数据,上面的那个只能针对数据集比较小的情况才考虑。
如果情况变了呢?
假设如下的情况
如果我们有 10亿行这么多的数据,这个时候我们按照上面的方式来玩,显然是行不通的。把10亿行数据放到内存中排序,这样显然是不科学的。有的人写代码不仅是把行考虑进去了,还考虑了矩阵,这就更尴尬了,你不仅考虑了这么多属性,你还要考虑样本?
按照刚才上面说的这些方法来执行的话,容易出现下面的这些问题:
1. 很难对10亿个数据进行排序。
2. 没有这么大的内存空间
3. 容易造成系统奔溃
所以,我们就要换种玩法。我们刚刚说了,要看两个列的相似性我们可以从签名矩阵上来看,签名矩阵的长度越长的话,这样出错的机会或者说相似的机会就比较小。 我们没有必要挑选比较所有的行,我们只要保证我们的签名矩阵的长度合理就可以了。
执行对策
所以我们想了下面的这个执行对策:
1. 我们不用对所有的行进行一个随机的排序,我们只需要挑选,我们用100个不同的哈希函数来对我们的行号进行计算就可以得到新的数据,这个数据就代表我们原先的行号变更出来的行号,可以看成是对我们整个矩阵的行进行洗牌。
2. 其实这样的Hash 函数很难找到,因为可能是会存在hash 值的碰撞,但是这个不影响我们这个算法的执行。
3. 这个想法就是把我们选择hash 行数对行号做计算,得出来的数字就是相应的排序行号,哈哈,我是不是搞得有点啰嗦啊
4. 在这里我们引入一个Slot 的值我们把这个值叫做M,M的初始值是无穷大。我们有100个hash 函数我们这么来表示我们的hash 函数 hihi, i 的取值是从1 到100 的,我们用hash 函数 hihi 计算得到一个Hash值,如果我们的样本,也就是某一列的某一行是1我们将这个计算出来的Hash值如果比我们的M值要小,那么M就保存着我们计算出来的较小的hash 值,实际上就是我们默认排列出来较小的行号。
这个算法的思想实在是太帅了,有没有!如果你脑子好使,一定已经发现它迷人的规律和为什么这么想的方式了。
下面我们来看算法的具体描述
MinHashing 算法(MinHashing algorithm)
foreach hashfunctionhi do compute hi (r);foreach column cifc has1inrow rforeach hashfunctionhi doifhi (r) is smaller than M(i, c) then M(i, c) := hi (r);end;
我们来描述一下我们的算法
1.首先我们先把我们的M slot 值设置为无穷大
2. 就假设我们有100 个hash 函数
我们从每一个hash 函数开始 对我们的行号进行计算,当然,你想要你的签名矩阵(signature matrix ) 长度有多长你最外围的循环就来几次
每一个hash 函数 hihi 对我们的行 r 做计算,我们把行号表示为r hihi 作用在上面就是 hi(r)hi(r)
3. 这个时候查看我们的每一列,我们只考虑我们的列中只含有1的元素,为个毛呢,这是因为我们的minhash 函数本来就是要找的就是随机排序之后的某一列中出现1 的行号的第一个
4. 如果我们的hash 函数值比我们的M值小这个时候我们就替换我们M 值
其实就是不断让M保持我们的搜索到1的最小的行号,这个就是这个算法的精髓所在。
下面我们来看一个例子

这个是我们的行,以及我们的两列样本的对应属性的情况
我们设置了两个hash 函数来计算我们的signature 的签名应该要哪个
h(x)=xmod5h(x)=xmod5
g(x)=(2x+1)mod5g(x)=(2x+1)mod5
如果我们按照常规方法来计算的话,我们要对这个行号进行一个排序,然后找到行号第一个为1 的来做我们的特征值,现在换了计算特征值的方法,我们对行号进行hash 不断的替换我们的最小行号达到我们原始的目的
我们设置两个签名的M值都为无限大,这个时候我们计算行号对应的hash 值
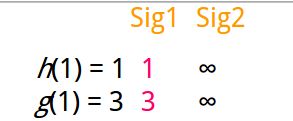
这个时候我们看到 两个hash 值分别为1 和 3
这个时候我们查看他们的对应的原始行也就是第一行的每一列,我们看到只有第一列有元素为1所以我们要替换的只能是第一列的M值 如上图所示。这个时候我们在依次计算我们的以下几行的hash 值

计算到第二行的时候得到两个hash 值分别是2,0 但是我们检查列只有第2列有1,所以比较大小之后替换 得到上面的这个结果

接下来我们来查看我们第三行的Hash 值,我们发现计算的是3,2 并且我们两列的值都是为1 的这个时候我们就要来看看替换谁,只能替换的结果是越来越小的。
3 比sig1 和sig2 的值都要大,所以我们保留不替换,我们看2 比sig1 大,所以被替换的就是它。以此类推,我们得到了下面的结果

其次,这样做的目的是因为我们的数据常常是按照我们的列来给出的,而不是按照行来给出的,如果按照行来给出,我们只需要对矩阵进行一次排列即可。
我们一般会得到很多的文档,以及文档被划分出来的shingles

候选签名
我们用上述的这些算法得到的签名其实是一些候选的相似对,对于这些相似的对我们必须要对他们进行一个评估。对于我们的signature matrix 我们必须对这个hash 得到的列在进行Hash ,这个时候要让这些元素映射到不同的bucket中。(注意,这里的hash 函数可以用一些比较传统的hash 函数) 这样我们认为这些列映射到我们相同的buckets 中的就是我们的候选的相似的对,或者说是我们候选可能相似的样本。
我们要得到我们的候选签名,这个时候我们就要设置一个阈值threshold,这个阈值必须是小于1的当我们的相似度超过了这个阈值的时候我们就认为这些候选的签名是相似的
我们来看一下怎么对我们得到的这个Matrix M 进行处理又或者说是怎么对我们的这个signature M进行处理
我们看下面的这个图,以上的图都来自与这个PPT
http://i.stanford.edu/~ullman/cs246slides/LSH-1.pdf

上面的这个图黄色的部分就是我们的Matrix M,或者说是我们的signature matirx
每一列我们可以看成是一个样本的签名,就是我们图中的粉红色的条形的部分,就是一列,这一列就是我们样本中的一个签名或者说是样本的特征值,指纹,你都可以这么理解。
然后把这个矩阵划分成了b 个bands 也就是b 个条状。 每一条含有r 行。
接下来我们要做的就是
对每一个signature 分段之后的每一个band 计算一个Hash值 然后让它映射到一个长度为K的bucket 里面。我们的k 要设置的尽量的大一些。这样子是为了减少碰撞的发生。
我们候选的candidate就是我们认为可能相似的样本就是那些 列的hash 值被映射到同一个bucket 里面的,一般有 band 的投射 个数>=1
我们通过调节我们的 b 以及 r 能够捕捉到大多数的相似的pair ,但是很难捕捉到不相似的pair
我们看下面的这个图

我们发现第二列和第6 列经过计算一个Hash值之后被映射到了同一个桶里面,这个时候我们可以认为这两个band 很有可能是相同的。当然也有极小的概率是发生了碰撞。
是这样的吗?
我们来计算一个概率看一看:
假设我们 C1 和C2 有80% 的相似度, 在这里我们设置一个Matrix M 它有100 行,我们把这个矩阵分成了20 个bands 每一个band 里面都有5 行 (r)
这个时候我们来计算一下C1 以及C2 在某个特定的band 里面相似的概率,记住我们有5行,每一行相同的情况是 0.8 的概率:
(0.8)5=0.328(0.8)5=0.328
那么我们是不是可以计算出C1 ,C2 在任何一个band 都不相似的概率就是:
(1−0.328)20=0.00035(1−0.328)20=0.00035
这个时候我们可以得到如果我们设置相似度的阈值是80% 那么它的false nagatives 的概率约为1/3000
我们在看另外的一个例子:
假设我们认为C1,C2的相似度只有40%
C1 和C2在同一个band 里面相同的概率:
注意我们还是认为我们有100行,也就是我们的签名矩阵(signature matrix 或者说是我们的matrix M)有100 行,同样是被分成了20个band,每一个band还是有5行
这样,如果C1 和C2 在某个特定的band 里面是相同的概率:
(0.4)5=0.01(0.4)5=0.01
那么在20 个band 里面都不相同的概率就是
(1−0.01)20=0.9920=0.82(1−0.01)20=0.9920=0.82
我们计算一下如果C1,C2在1个band 或者2,3,4,…20 个band里面都相同的概率
1-0.82<0.2
我们的false positive 是远小于40% 的
所以当我们设定一个阈值,相似度大于阈值的时候,如果列的相似度非常的大,他们在同一个bucket的概率是非常大的

我们看下面的例子,s 表示的是相似度

所以实际的情况就是下面的这个样子

这个就说明了我们的LSH 如果其中有两个band 被映射到同一个 bucket 我们可以认为这两列就是相似的。说了这么多意思就是尽管我们的文档很大,产生的最后的Matrix M 也很多。 但是我们只需要计算一个band .我们就可以大概的预测出我们样本的相似性了。
看完,学完这个LSH是不是想拍着大腿直呼 66666666了呢,反正我是被震撼到了。
OK,当处理大数据的时候,方法也就是这个原理了,你们学会了没有呢。
References
i.stanford.edu/~ullman/cs246slides/LSH-2.pptx
https://web.stanford.edu/class/cs345a/slides/05-LSH.pdf
https://www.youtube.com/watch?v=bQAYY8INBxg
https://www.youtube.com/watch?v=MaqNlNSY4gc&t=2010s
https://www.youtube.com/watch?v=_rWpSC-s4vU
https://www.youtube.com/watch?v=c6xK9WgRFhI 3 1 Finding Similar Sets 13 37
3 2 Minhashing https://www.youtube.com/watch?v=96WOGPUgMfw
Locality Sensitive Hashing https://www.youtube.com/watch?v=_1D35bN95Go
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf

