轻量级网络之GhostNet
轻量级网络之GhostNet
- 前言
- 动机
- Ghost模块
- G-bneck
- GhostNet网络结构
- 实验性能
- 消融实验
- Ghost模块 pytorch代码
欢迎交流,禁止转载!!
前言
《GhostNet: More Features from Cheap Operations》
论文地址:GhostNet: More Features from Cheap Operations
来自华为诺亚方舟实验室,发表于2020年的CVPR上。提供了一个全新的Ghost模块,旨在通过廉价操作生成更多的特征图。该Ghost模块即插即用,通过堆叠Ghost模块得出Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。
动机
特征层中充足或者冗余的信息总是可以保证对输入数据的全面理解,而且特征层之间有很多是相似的,这些相似的特征层就像彼此的ghost (幻象)。考虑到特征层中冗余的信息可能是一个成功模型的重要组成部分,论文在设计轻量化模型时并没有试图去除这些冗余,而是用更低成本的计算量来获取它们。
如下图所示,在ResNet-50中,将经过第一个残差块处理后的特征图拿出来,三个相似的特征图对示例用相同颜色的框注释。
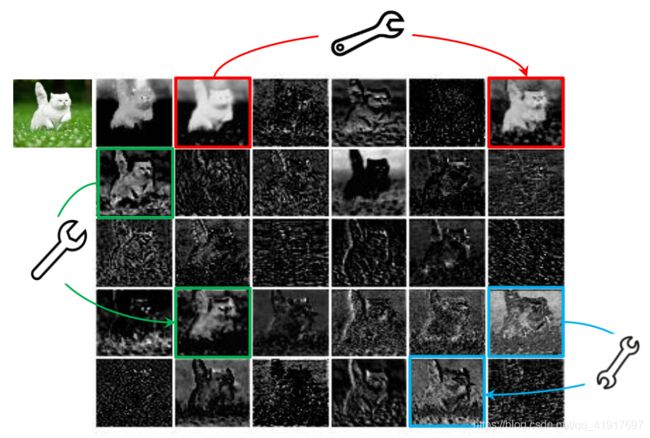
ps:同样的,我们可以看看以往的研究:ZFNet的可视化操作,卷积核也存在类似的幻象。也许这就是可以用分组卷积的原因吧。。(个人观点,之后我会去把分组卷积可视化来验证一下猜想,特征图存在幻象的本质其实不就是卷积核存在幻象嘛)

Ghost模块
卷积层的输出特征图通常包含很多冗余,并且其中一些可能彼此相似。作者指出,没有必要使用大量的FLOP和参数生成这些冗余特征图,既然有部分类似的,那么就不用全部都去卷积,直接拿一部分作为重复冗余的信息不就好了嘛。
Ghost Module则分为两步操作来获得与普通卷积一样数量的特征图:

- 少量卷积(比如:正常用32个卷积核,这里就用16个);
- cheap operations,图中的Φ,Φ是诸如3*3的卷积(Depth-wise convolutional)。
这样上下两部分的特征图就互为幻象。
参数量:

计算量:上图中s=2,考虑到CPU或GPU的实用性,在线推理会受到阻碍。因此,作者建议在一个Ghost模块中采用相同大小的线性运算(例:全3x3或5x5)。
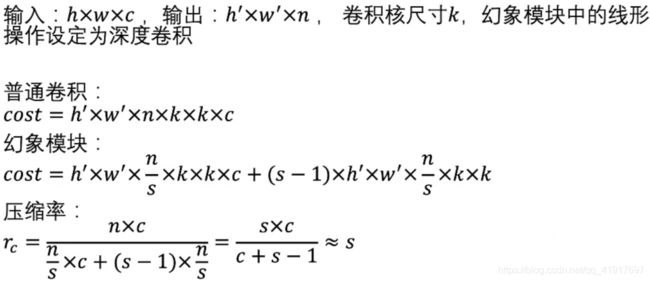
模型参数压缩和运算加速比大约都等于s。(前提是两次卷积核k一样,k不一样的话会略小于s)
如果s=2,在网络中替换该模块,可得到:

G-bneck
利用Ghost模块的优势,作者介绍了专门为小型CNN设计的Ghost bottleneck(G-bneck):

这里借鉴了MobileNetV2,第二个Ghost模块之后不使用ReLU,其他层在每层之后都应用了BN和ReLU。出于效率考虑,Ghost模块中的初始卷积是点卷积(Pointwise Convolution)。
GhostNet网络结构
遵循MobileNetV3的基本体系结构的优势,然后使用Ghost bottleneck替换MobileNetV3中的bottleneck。 SEBlock是在两个ghost module中间使用的,默认为0.25,是卷积之间的。

实验性能
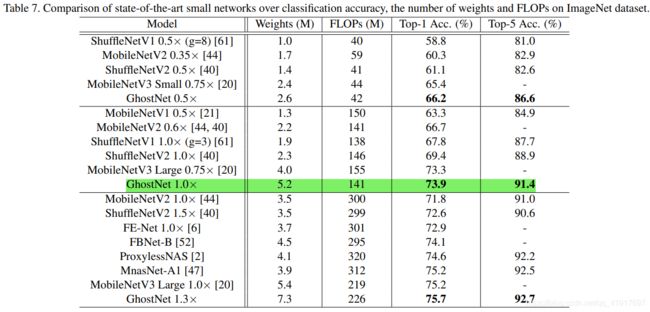
图像分类:

目标检测:

消融实验
对卷积核的大小以及分组的s进行消融实验:

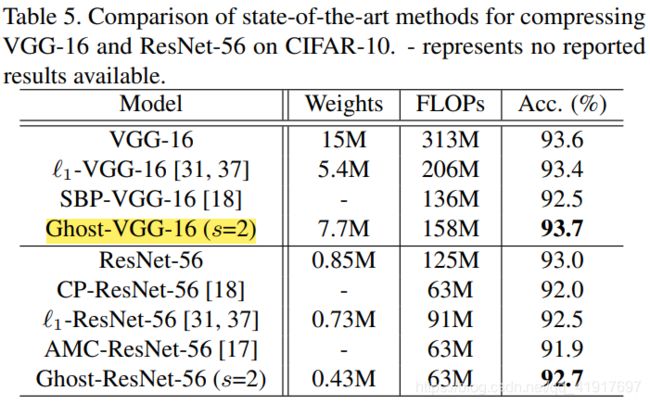
替换到其它网络上的效果:

Ghost模块 pytorch代码
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
pytorch 开源代码::https://github.com/iamhankai/ghostnet.pytorch/blob/master/ghost_net.py
欢迎交流,禁止转载!!
上一篇:轻量级网络之MixNet
下一篇:轻量级网络之EfficientNet