在博客上看到一篇正则表达式的,感觉对于刚接触python的小伙伴挺有收益的,但是请喷子绕道。不是每篇文章都能获得大家的赞同赞赏。你要看我很欢迎,不看我也不奢求,所以请各位喷子绕道,谢谢,相当于喷子我更喜欢伸手党。好了bb了这么多。在分享之前,我给大家推荐我的一个java高级开发群:283904828 群里有资料免费领群,也有大牛热心解答。也经常提供一些比较好的文章,给大家找好方向,欢迎初学者和进阶者还有大牛者进群,加入这个大家庭!
好了,接下来就是给大家分享了,
实际上爬虫一共就四个主要步骤:
1.明确目标:需清楚目标网站
2.爬:将所有的目标网站的内容全部爬下来
3.取:在爬下来的网站内容中去掉对我们没有用处的数据,只留取我们需要的数据
4.处理数据:按照我们想要的方式存储和使用留取的数据
我们在前面的案例里实际上都省略了第3步,也就是“取”的步骤。因为我们down下了的数据是全部的网页,这些数据很庞大并且很混乱,其中大部分的东西是我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。那么对于文本的过滤和者规则的匹配,最强大的就是正则表达式了。那么什么是正则表达式:
. 正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个规则的文本。
. 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
给定的字符串是否符合正则表达式的过滤逻辑(“匹配”)
通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)

正则表达式规则

Python的re模块
在Python中,我们可以使用内置的re模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用对特殊字符进行黑底,所以如果我们要使用原始字符串,只需要加一个r前缀:r'i love\t\.\tpython'
re模块的一般使用步骤如下:
1.使用compile()函数将正则表达式的字符串形式编译为一个Pattern对象
2.通过Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个Match对象。
3.最后使用Match对象提供的属性和方法获得信息,根据需要进行其他操作。
compile函数
compile函数用于编译正则表达式,生成一个Pattern对象,它的一般使用形式如下:

在上面,我们已将一个正则表达式编译成Pattern对象,接下来,我们就可以利用pattern的一系列方法对文本匹配查找了。
Pattern对象的一些常用方法主要有:
match()方法:从起始位置开始查找,一次匹配
search()方法:从任何位置开始查找,一次匹配
findall()方法:全部匹配,返回列表
finditer()方法:全部匹配,返回迭代器
split()方法:分割字符串,返回列表
sub()方法:替换
match()方法
match()方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。因此,当你不指定pos和endpos时,match()方法默认匹配字符串的头部。
当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。

在上面,当匹配成功时返回一个Match对象,其中:
group([group1,...])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0)
start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为0
end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引 + 1),参数默认值为0
span([group])方法返回(start(group), end(group))
再看一个例子:

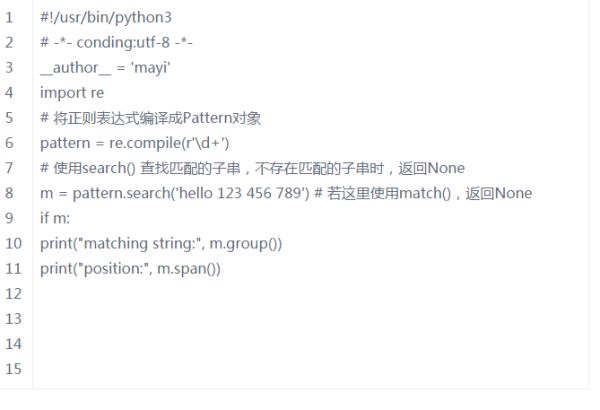
search()方法
search()方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。
当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。
如下例子:

再看一个例子:
执行结果:

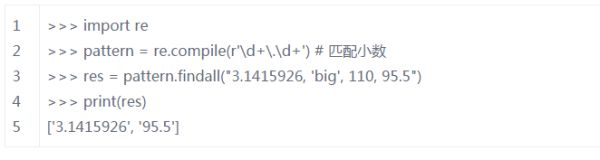
findall()方法
上面的match()和search()方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall()方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。
findall()以列表形式返回全部能匹配的子串,如果没有匹配成功,则返回一个空列表。
如下:

再看一个例子:
finditer()方法
finditer()方法的行为跟findall()的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
如下:

执行结果:

split()方法
spilt()方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit用于指定最大分割次数,不指定将全部分割。
如下:

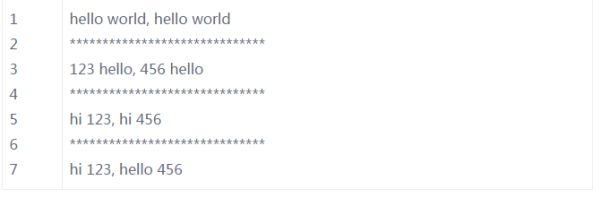
sub()方法
sub()方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl可以是字符串也可以是一个函数:
如果repl是字符串,则会使用repl去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl还可以使用id的形式来引用分组,但不能使用编号0
如果repl是函数,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)
count用于指定最多替换次数,默认全部替换
如下:

执行结果:
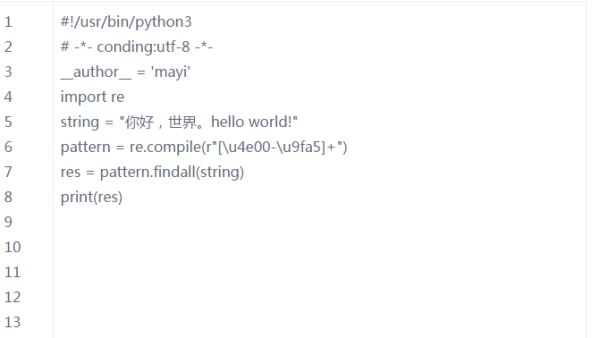
匹配中文
在某些情况下,我们想匹配文本中的汉字,中文的unicode编码范围主要在[u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
例如:要想把字符串s = "您好,世界。hello world!"中的中文提取出来,可以这么做
输出结果
1. 世界你好
一件平凡的事,当你做了一万遍,就会变得伟大!!!