Python爬虫实战(一)疫情数据
github地址:
https://github.com/ZhengLin-Li/leaning-spider-COVID19Situation
1. BeautifulSoup的find方法
# for example
soup.find('a') # 根据标签名查找
soup.find(id='link1') # 根据属性查找
soup.find(attrs={
'id':'link1'}) # 根据属性查找
soup.find(test='aaa') # 根据标签文本内容查找
2. Tag对象
find方法返回的是Tag对象,有如下属性
Tag对象对应于原始文档中的html标签
name:标签名称
attrs:标签属性的键和值
text:标签的字符串文本
3. 正则表达式
. \d
+*?
()
[]
\
r原串
import re
rs = re.findall('\d','123')
rs = re.findall('\d*','456')
rs = re.findall('\d+','789')
rs = re.findall('a+','aaabcd')
print(rs)
import re
# 分组的使用
rs = re.findall('\d{1,2}','chuan13zhi2')
rs = re.findall('aaa(\d+)b','aaa91b')
print(rs)
# 一般的正则表达式匹配一个\需要四个\
rs = re.findall('a\\\\bc','a\\bc')
print(rs)
print('a\\bc')
# 使用r原串
rs = re.findall(r'a\\rbc','a\\rbc')
print(rs)
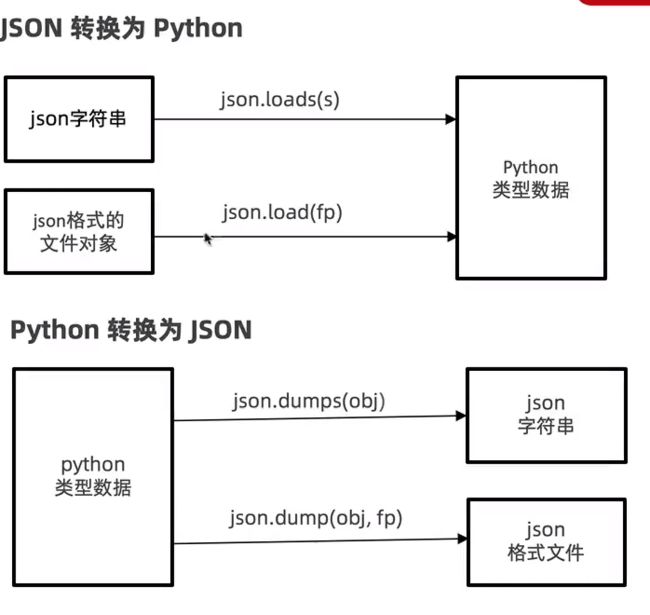
4. json字符串互转python数据
import json
json_str = '''[{"a":"thia is a",
"b":[1,2,3]},{"a":"thia is a",
"b":[1,2,3]}]'''
rs = json.loads(json_str)
print(rs)
print(type(rs)) # import json
json_str = '''[
{
"a": "this is a",
"b": [1, 2,"熊猫"]
},
{
"c": "thia is c",
"d": [1, 2, 3]
}
]'''
rs = json.loads(json_str)
json_str = json.dumps(rs,ensure_ascii=False)
print(json_str)
5. json格式文件互转python数据
# json格式文件转python数据
with open('data/test.json') as fp:
python_list = json.load(fp)
print(python_list)
print(type(python_list)) # with open("data/test1.json",'w') as fp:
json.dump(rs,fp,ensure_ascii=False)
我的邮箱:[email protected]
我的博客:http://9pshr3.coding-pages.com/
或https://zhenglin-li.github.io/
我的csdn:https://me.csdn.net/Panda325
我的简书:https://www.jianshu.com/u/e2d945027d3f
我的今日头条:https://www.toutiao.com/c/user/4004188138/#mid=1592553312231438
我的博客园:https://www.cnblogs.com/zhenglin-li/