Day269.口罩预约抢购系统关注的问题、瞬时高流量Mysql查询缓慢原因 -Redis的高并发预约抢购系统
一、口罩预约抢购系统关注的问题
1、瞬时高流量sku缺乏监控会出现的问题
流量监控问题
如果不是值班人员细心,自己肉眼发现了这个预约SKU的涨幅不正常。
万一稍有疏忽没有观察到流量的异常,一旦到了抢购的时候到了,巨额流量将对核心的交易链路造成毁灭性打击,所以必须要有相关的流量监控给开发人员比较明确的警示,防止由于人为疏忽,引发大CASE。
2、促销预约超级热门商品时,人数过多问题
这个问题主要从以下几个方面考虑:
-
业务层面:当人数过多时,可以将针对此次预约活动,
改变策略,将原有的抢购策略改为摇号抢购 ,这样能够很好的降低热门商品给交易链路带来的冲击,也同时增强用户体验,避免大批用户在点击抢购按钮之后,抢购失败。 -
制定预约熔断机制,使得许多多余请求被过滤掉,也是起到保护核心交易链路的作用。 -
热点key的问题如何解决?一旦发生热点key的情况,很有可能产生量倾斜,这就会导致,特定的几台机器压力特别大,甚至导致redis宕机,引发缓存雪崩,巨额流量涌入关系型数据库,就有可能导致核心链路发生故障。
3、 对于热门商品读请求的几种方案
-
检查热点SKU名单,将对于热点请求的数据进行,一主多从+哨兵的redis集群架构,有多个从主机负责处理读请求。
-
在redisCluster集群架构下,
利用flink,storm等的实时计算技术,对这SKU进行热点感知,只要是热点品就将数据同步给多台master,并改变lua脚本的执行请求路由的策略。
4、对于热门商品读写请求几种方案
-
升级redis单机硬件。 -
采用多级缓存策略即每台服务器上,设置一个访问计数器,每隔一段时间将累加器里的数据和redis中的数值相加并将相加后的值刷入本地缓存,那么每次用户读请求过来就是读每台机器上的本地缓存了,这样做的坏处是关于热点SKU的一些数据展示给用户的信息,都不是实时的。
二、瞬时高流量下,Mysql查询缓慢原因
1、一些硬件知识
市面上常见的硬盘有:
-
机械硬盘(Hard Disk Drive,HDD)
-
固态硬盘(Solid State Drive,SSD)
本次主要向大家讲解机械硬盘的相关知识,机械硬盘的大致结构如下图↓:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZBFRL6bO-1621169866268)(http://qskpmm1b6.hn-bkt.clouddn.com/20210516200206.png)]
可以看到,一个磁盘最主要的是由多个盘片组成,且每个盘片又由两个盘面组成,每个盘面上都有一个读写磁头
下面近距离地看看盘片的构成,如下图↓所示:

这东西是不是有点像过去使用的蚊香片呢?那一层层的灰色圆环被称为磁道,磁道上的那个绿色弧段部分,被称为扇区,从硬件层面来说,扇区是我们读写文件的最小单位,一般扇区的大小是512字节,也有4096字节的,但是在系统层面是以一个磁盘块为最小的读写单位,一般一个磁盘块大小为4096字节,如果是512字节的扇区磁盘,那么一个磁盘块,就是由8个连续的扇区组成。
2、磁盘IO操作的时间的影响因素
决定磁盘Io速度的一些主要因素:
寻道时间: 将读写磁头移动至正确的磁道上所需要的时间,这部分是IO读写效率的最核心因素,我们开发时最应该掌控的也应该是这一块内容了,所谓的磁盘顺序读写就是极大的减少了磁头所要移动的磁道数量,磁盘的平均寻道时间一般在3-15ms,一般都在10ms左右。旋转延迟时间: 盘片将目标扇区移动到读写磁头下方所需要的时间,取决于磁盘的运转速度。数据传输时间:完成传输数据所需要的时间。
其中后两个因素我们平时不需要去关注,第一点尤为关键。
我们如果自己开发中间件系统的话,就要去多多考虑这种因素。
3、Innodb存储引擎的索引树结构
为了增强mysql数据查询效率就会根据不同的业务建立不同的索引
如图↓:

假设要搜索元素14就只能把这个链上的数据都给遍历一遍也就是O(N)的时间复杂度,而且我们在做一个假设,就是你遍历一个节点都要在磁盘上读取,如果现在有几百万条数据,怎么玩的话你想想是一个什么样的结果
那么如果把它变为二叉树会怎么样呢?如图↓:
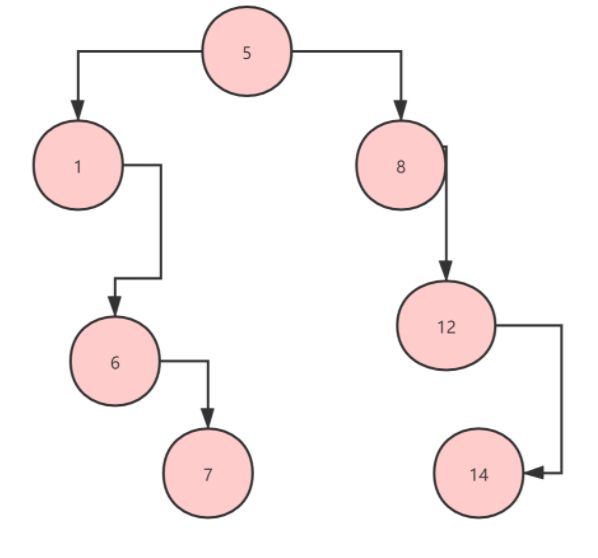
可以看到如果用二叉树的数据结构将这些节点组织起来,基本上可以天然的过滤掉一半的数据读写就能定位到,我们要的数据了。
看上去好像挺不错的,但是如果发生下图↓一类的情况呢?
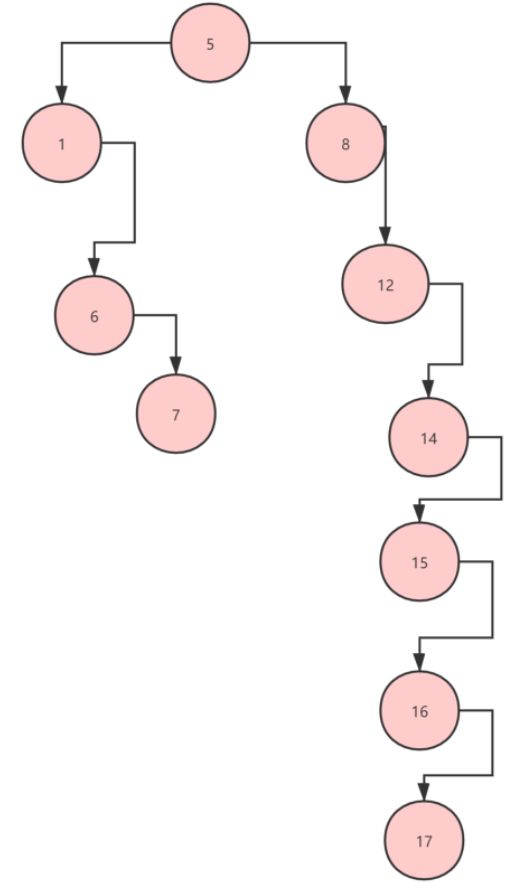
假设现在要找值为17的元素,我们还是要进行O(N)的时间复杂度的遍历,所以这种二叉树的高度有可能会很高,导致产生大量的读磁盘,而且每个节点里只有一个数据,也就是说我们现在要实现两点需求:
降低树的高度,减少磁盘的读操作让每个节点拥有更多的数据,这样一次读磁盘可以获取更多数据,如果这些数据暂时用不到,也可以将它缓存起来,如果用到了直接从缓存中拿就可以了,避免过多的磁盘IO。
数据融合 ,如下图↓所示:
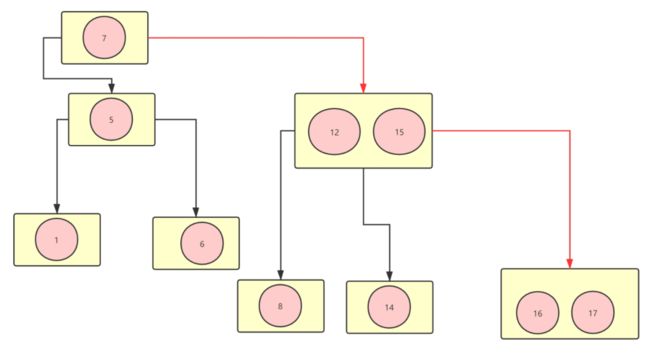
↑上图可以看到 数据融合之后我们如果要找到17这个数据从根节点开始算只要经历3个节点就可以了。大大降低了读磁盘的次数。像↑上图那样的数据结构就是B树结构,常应用于文件系统。
现在再来做一个实验,在现有的数据结构中加入18和19两个数字,看看是什么效果 ,如图↓:
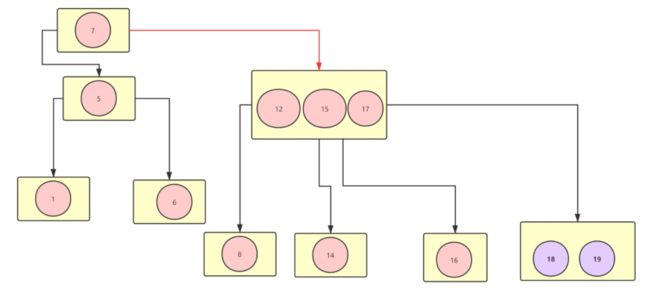
在加了两个结点之后,数据节点发生了分裂,而这些操作都是在磁盘中进行的,你想一下如果数百万条预约请求打过来,那么在那一瞬间,数据库频繁的发生这种数据块的分裂对cpu造成的负载可见一斑。
甚至不夸张的说都有宕机的风险,而且这种分裂是可以产生连锁反应的,也就是说当一个节点产生分裂那么就有可能导致它的父节点也跟着产生分裂,这种现象叫做上溢,因为B树必须严格遵守一个数据的排列规定,才能保证树的平衡。
4、B树的定义
就像上面的那颗B树被称为4阶B树,我们假设这个B树的阶为X,每个数据节点的包含的元素个数为J,那么这个B树,必须遵守如下约定:
- 根节点的元素数量1<=J<=X-1
- 非根节点的元素数量 ceil((X-1)/2)<=J<=X-1
- 如果一个数据节点有子结点的话,那么该数据节点的子节点数量等于J+1
由此可见虽然B树能够有效的减少磁盘的读写次数,但是维护数据的顺序排列也是需要很大的成本的,所以必须要根据数据库所涉及到的不同业务场景来建立索引树。
5、B树如何进行范围查找
若果此时要基于B树进行范围查询会怎么样?如图↓:
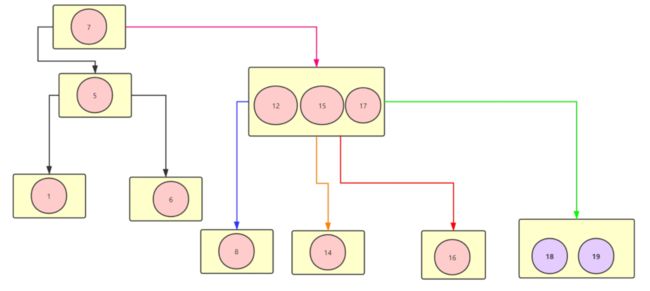
上图↑中假设我们要找到 大于等于8的元素 那么我们可以看到 橙色,红色,绿色的指针都指向的是叶子节点,而且叶子节点相互之间彼此之间没有任何指针让它们直接互通,这也就意味着如果要把符合要求的数据基本上就是要把所有的节点给扫描一遍才行这是非常损耗性能的。
所以当务之急是要确保范围查询效率。其次还有一个问题,如图↓:
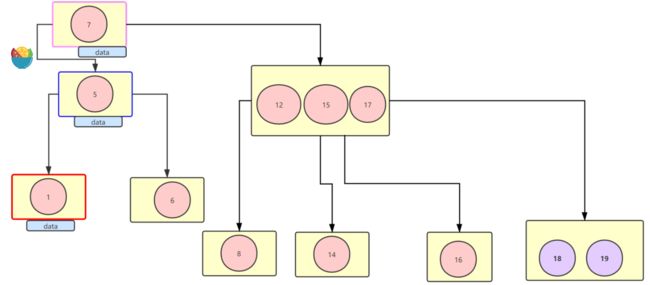
比如我要找索引为7的数据那么只要O(1)的复杂度,那么我要找索引为5的数据那么要O(2)的复杂度,查询索引为1的数据就只能是O3的时间复杂度,那么也就是说我要从数据库里找数据,查询的性能完全看运气,没有一个稳定性,时快时慢,这让对数据库的性能没有一个较为精准的评估。
6、以上问题优化方案
那么针对这两个问题,应该如何去优化呢?如图↓所示:

这里简化了,现在只有叶子节点存储数据,所以所有查询基本上花的时间是一致的,然后范围查询的话,所有的叶子节点都组成了双向链表,可以很方便的进行范围查询了。
这就是所谓的B+树,值得一提的是,一直以来B+树有两种实现方式,上图是以维基百科上面定义的B+树所写的。即 非叶子节点的节点元素=子节点数-1
那么还有一种就是百度百科上定义的B+树。即非叶子节点的子节点数量=父节点的元素个数,如图↓:
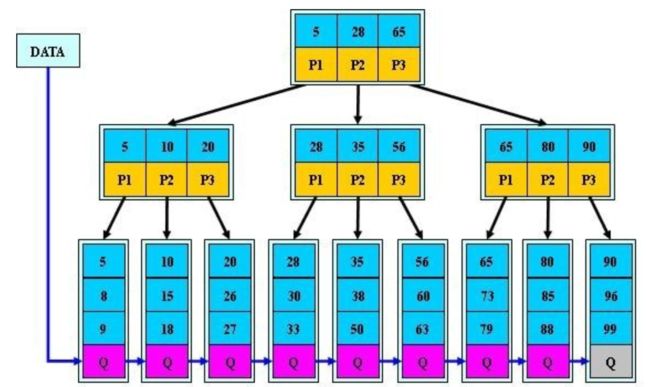
mysql采用的是第二种,即百度百科上定义的那一种。