淘宝抢购
淘宝购物代码
- 一、前言
- 二、Python+pycharm的安装
-
- 1. python安装包下载地址:
- 2. pycharm安装
- 三、火狐浏览器安装+环境变量设置
-
- 1. 火狐浏览器安装
- 2. 环境变量设置
- 四、geckodriver配置
- 五、第三方库的下载(selenium)
-
- 1. setting下载
- 2. 操作台下载
- 六、代码
- 七、 效果图
- 八、 心得
- 九、资料网盘(代码+安装包):
一、前言
本篇文章主要介绍了从Python 安装到代码演示的全过程,通过selenium实现毫秒级自动购物,通过扫码登录即可自动完成下单操作,购物时间自己可调整,将购物车中的商品全部下单。
二、Python+pycharm的安装
1. python安装包下载地址:
顺便说一下,下载3.x版本比较好,2.x还是3.x 其实都可以的
详情可以看文章比较一下:Python下载哪个版本比较好?
官网下载:https://www.python.org/downloads/
搜狗下载:https://xiazai.sogou.com/detail/34/16/6122277939738274613.html?e=1970
百度云盘:https://pan.baidu.com/s/1mUS1ocR5haUt16eLERnHfw ;提取码:echo
安装步骤图:
①双击安装

②选择路径
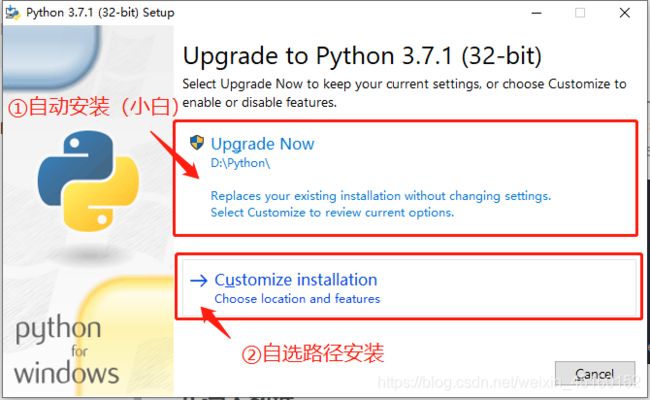
③安装完成

2. pycharm安装
文件有点大,是下载方式
官网下载:https://www.jetbrains.com/pycharm/download/#section=windows
百度云盘:https://pan.baidu.com/s/1mUS1ocR5haUt16eLERnHfw ;提取码:echo
安装步骤图:
①双击安装
②安装
③选择路径

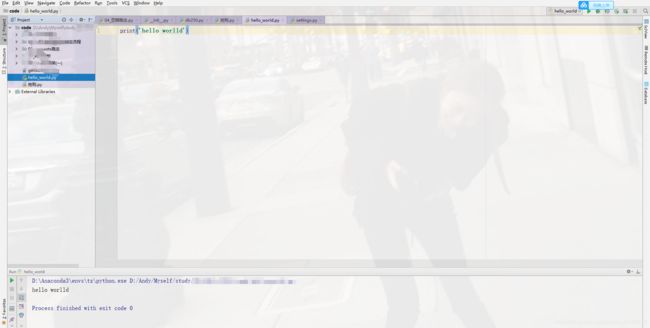
④安装完成

⑤进去新建python文件即可
三、火狐浏览器安装+环境变量设置
官网下载:https://www.firefox.com.cn/
百度云盘:https://pan.baidu.com/s/1mUS1ocR5haUt16eLERnHfw ;提取码:echo
1. 火狐浏览器安装
安装步骤图:
①安装
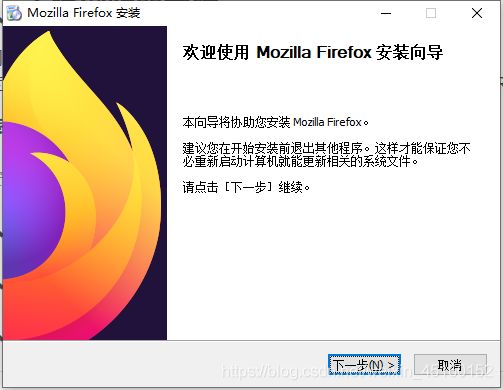
②选择
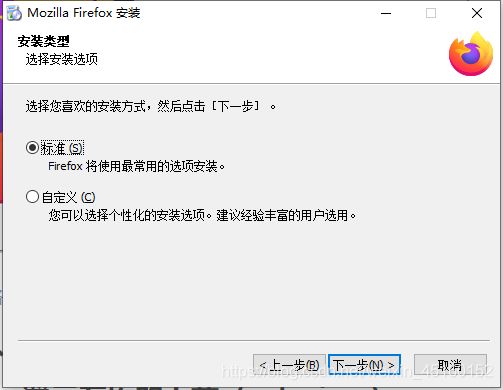
③安装完成

2. 环境变量设置
设置步骤图:
①进入高级系统设置
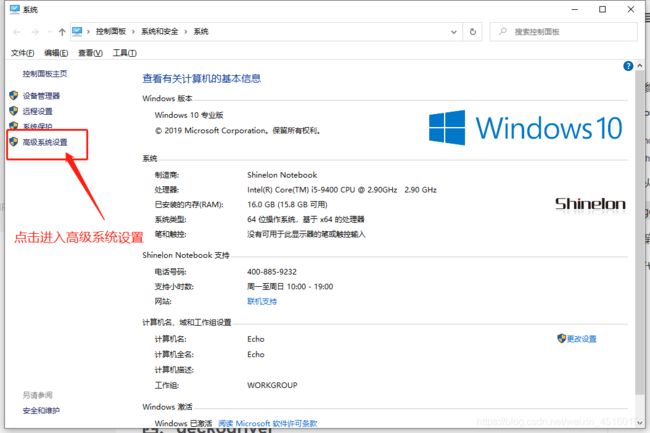
②添加path路径

四、geckodriver配置
建议选择高一点的版本,不然代码会报错 我用的是0.29.0的
镜像下载:http://npm.taobao.org/mirrors/geckodriver/
百度云盘:https://pan.baidu.com/s/1mUS1ocR5haUt16eLERnHfw ;提取码:echo
安装步骤图:
①下载之后解压
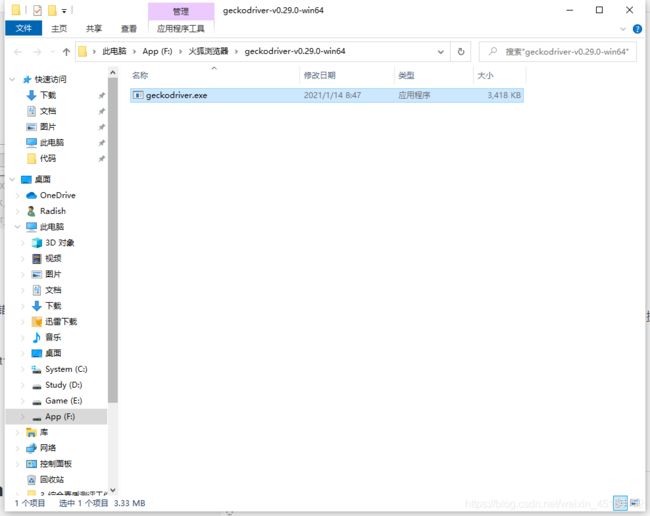
②将解压好的文件分别存放到火狐浏览器安装目录和python编译器目录下
firefox目录下:
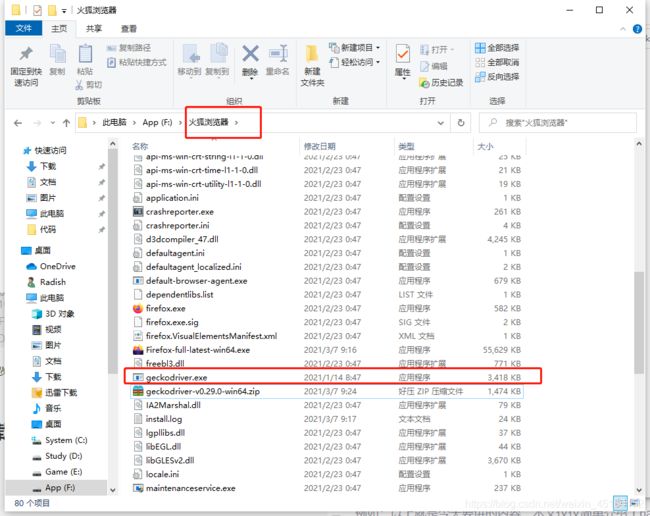
python编译器目录下: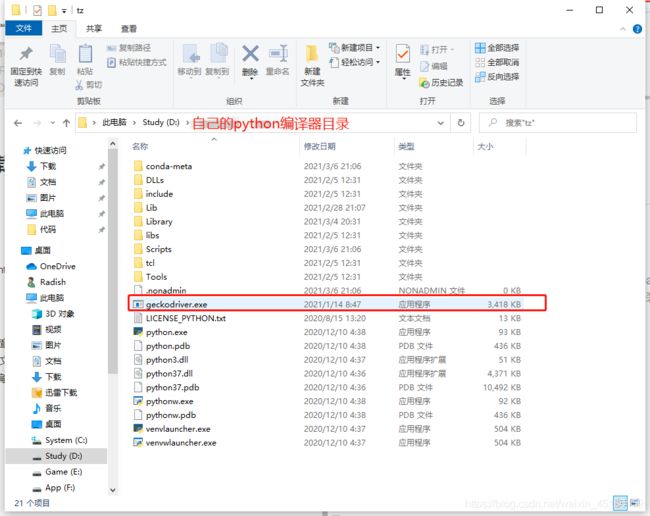
五、第三方库的下载(selenium)
直接进入pycharm操作一波,或者在操作台操作
pycharm: setting > project code > project interpreter > + > selenium
操作台: win+r > cmd >pip install selenium
1. setting下载
安装步骤图:
①setting中下载
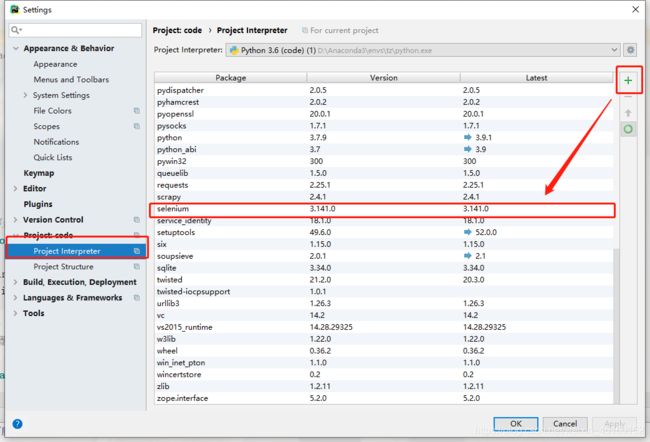
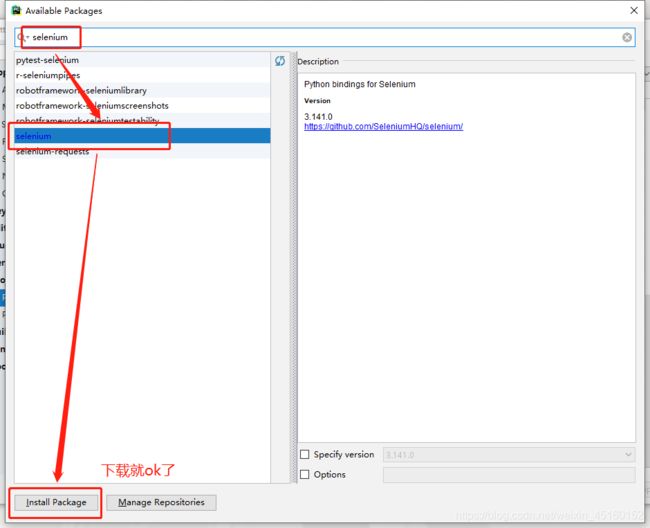
2. 操作台下载
安装步骤图:
①操作台(在操作台下载要将python的环境变量配置好,跟配置火狐浏览器的环境变量是一样的)
②我这里是已经下载好了的

pip install selenium
六、代码
最重要的时刻来了 ahhh 代码献上
from selenium import webdriver
import datetime
import time
#打开火狐浏览器
web = webdriver .Firefox()
# 登录方式
def login():
# 打开淘宝登录页,并进行扫码登录
web.get("https://www.taobao.com")
time.sleep(4) #给足够的载入网页的时间
#通过xpath定位,定位到登录按键,click点击登录
# 通过F12 查看html的格式找到登录按钮,复制xpath地址
if web.find_element_by_xpath('/html/body/div[4]/div[2]/div[1]/div[2]/div[2]/div[1]/a[1]'):
web.find_element_by_xpath('/html/body/div[4]/div[2]/div[1]/div[2]/div[2]/div[1]/a[1]').click()
num = 15 #设置计时秒数
print(str(num)+"秒内完成扫码") #提示
time.sleep(num) #给足够的时间扫码登录
# 提醒登录成功
now = datetime.datetime.now()
print('登陆成功:', now.strftime('%Y-%m-%d %H:%M:%S:%f'))
#购物车选择
def take():
# 进入淘宝的购物车
web.get("https://cart.taobao.com/cart.htm")
time.sleep(4) #给足够的载入网页的时间
# 点击购物车里全选按钮 xpath路径
if web.find_element_by_xpath('//*[@id="J_SelectAll1"]'):
web.find_element_by_xpath('//*[@id="J_SelectAll1"]').click()
# 购买
def buy(buytime):
# while循环设置抢购
while True:
# 获取现在的时间
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
print("当前时间" + now)
# 对比时间,时间到的话就点击结算
if now > buytime:
try:
# 点击结算按钮
if web.find_element_by_xpath('//*[@id="J_Go"]'):
web.find_element_by_xpath('//*[@id="J_Go"]').click()
#自动提交订单
web.find_element_by_link_text('提交订单').click()
except:
# 如果报错的话就暂停一段时间
time.sleep(0.1)
# 隔一段时间重新抢购
time.sleep(0.1)
if __name__ == "__main__":
# 时间格式:"2021-03-08 20:29:00.000000"
login()
take()
buy("2021-03-08 20:29:00.000000")
七、 效果图
有图有真相
①二维码登陆后,直接跳转购物车页面全选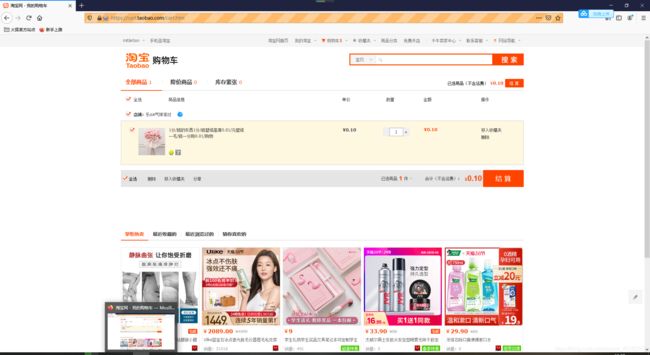
②代码框有时间对比显示当前时间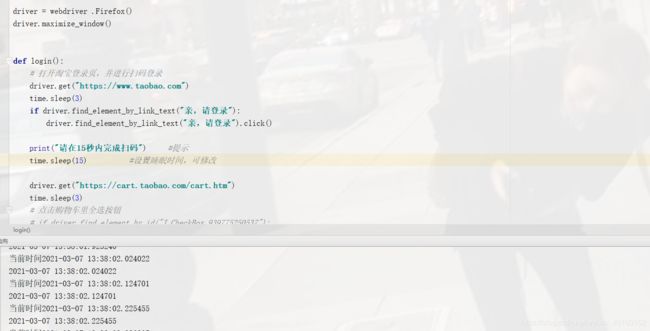
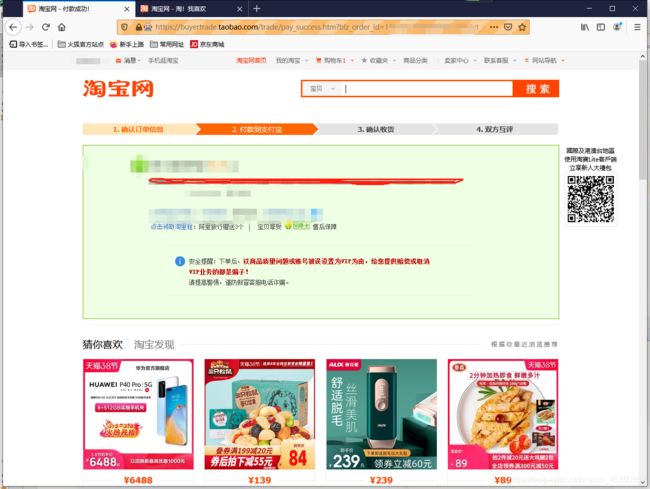
③购买成功
八、 心得
通过在网上不断学习,有bug就有进步ahhh,我的报错就是geckodriver的版本太低了,selenuim适应不了。
要不是抢k40也不知道这个脚本,希望能帮助到大家,有问题的话可以留言讨论。资料都放在网盘上面,大家有需要就去拿吧。
写一篇博客也太累了 啊哈哈哈。希望以后有时间再更新爬虫或者小程序的学习心得吧。
九、资料网盘(代码+安装包):
百度云盘:https://pan.baidu.com/s/1mUS1ocR5haUt16eLERnHfw ;提取码:echo