本文已被 Apache Kylin 官方收录,传送门:https://kyligence.io/zh/resources/apache-kylin-query-analysis/?utm_source=wechat&utm_medium=social&utm_campaign=kylin
阅读本文前,请先阅读:
- Apache Kylin 概览 -
- Apache Kylin 查询流程源码剖析 -
Apche Kylin 是 Hadoop 大数据平台上的一个开源 OLAP 引擎。它采用多维立方体(Cube)预计算技术,可以将某些场景下的大数据 SQL 查询速度提升到亚秒级别(相对于之前的分钟乃至小时级别的查询速度)。
由于其在 OLAP 领域出色的表现,在国内外积累了很多用户。我们知道,当用户输入一条 sql 提交给 Kylin 进行查询时,该 sql 是面向事实表和维度表的,而不是面向 Cube 的。当我看到这样的描述时,忍不住会想 Kylin 是怎么做到这一点的呢?相信很多使用 Kylin 的用户也会有相同的疑问,但遗憾的是,目前不管是出版的书籍还是网上能搜到的资料,都没有对这方面详细的介绍,所以就有了这篇文章。
本文将以一个典型的例子和大家一起从源码级别看看 Kylin 到底是怎么做到把对原始表的查询转换为对 Cube 的查询的。虽是源码级,但不会贴很多代码,尽量做到以流程图加描述的方式讲清楚这个过程。
一、概览
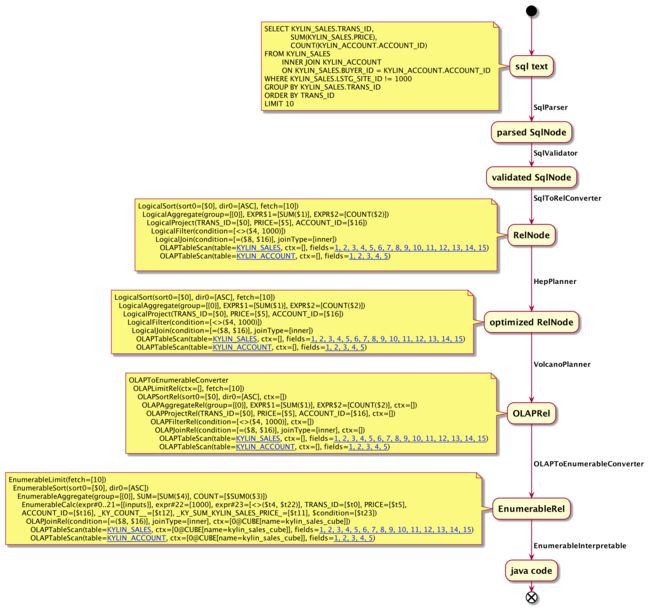
如上图,sql text 到物理执行计划主要分几个阶段:
- sql text -> parsed SqlNode:使用 SqlParser 解析 SQL, 把 SQL 转换成为 AST(抽象语法树),用 SqlNode 来表示
- parsed SqlNode -> validated SqlNode:使用 SqlValidator 语法检查,根据 meta 的元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树
- validated SqlNode -> RelNode:使用 SqlToRelConverter 进行语义分析,根据 SqlNode 及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan)
- RelNode -> optimized RelNode:使用 HepPlanner 应用 calcite 内置 rules 进行优化
- optimized RelNode -> OLAPRel:使用 VolcanoPlanner 应用 Kylin 自定义的 OLAP 相关 rules 到 HepPlanner 优化得到的 RelNode 上,得到 OLAPRel,OLAPRel 还是逻辑执行计划。OLAP rules 如下:
- OLAPToEnumerableConverterRule: RelNode -> OLAPToEnumerableConverter
- OLAPFilterRule: LogicalFilter -> OLAPFilterRel
- OLAPProjectRule: LogicalProject -> OLAPProjectRel
- OLAPAggregateRule: LogicalAggregate -> OLAPAggregateRel
- OLAPJoinRule: LogicalJoin -> OLAPJoinRel/OLAPFilterRel
- OLAPLimitRule: Sort -> OLAPLimitRel
- OLAPSortRule: Sort -> OLAPSortRel
- OLAPUnionRule: Union -> OLAPUnionRel
- OLAPValuesRule: LogicalValues -> OLAPValuesRel
- OLAPRel -> EnumerableRel:通过 OLAPToEnumerableConverter#implement 将 OLAPRel 转化为物理执行计划 EnumerableRel,这个过程中会递归调用各个 OLAPRel 节点的 implementOLAP、implementRewrite 等方法,也是在这一步中计算要使用哪个 Cube
- EnumerableRel -> java code:通过物理执行计划生成最终要执行的 java code,java code 包含读取数据、数据处理、计算结果
上例中生成的 java code 见下文
二、OLAPRel 生成物理执行计划
该过程主要封装在 OLAPToEnumerableConverter#implement 中,主要流程如下:
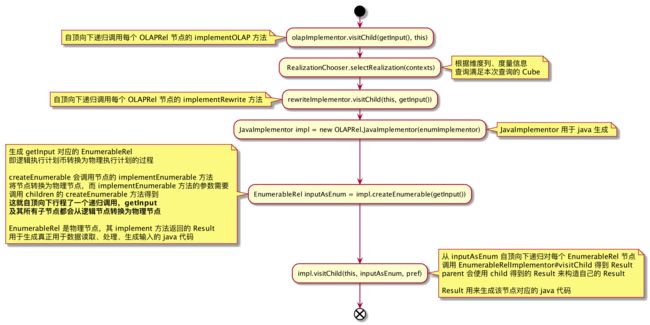
implementOLAP、implementRewrite、implementEnumerable 为 OLAPRel 接口的方法,每个 OLAPRel 实现类都要有自己的实现,虽然各个实现不同,但可以进行一些归纳:
void implementOLAP(OLAPImplementor implementor) :
- 生成或修改自身一些成员,会影响自身 implementRewrite 的行为
- 修改 OLAPContext 的一些成员,会影响其他 OLAPRel implementOLAP 或 implementRewrite 或 生成物理节点、生成物理节点对应的 java code
void implementRewrite(RewriteImplementor rewriter) :
- 会对算子、参数进行改写;这是把 sql 表达的查原始表(事实表、维度表)改为查 Cube 的关键
- 虽然每个 OLAPRel 子类都实现了该方法,但不是所有的子类都会真正的去做重写
- rewrite 行为受自身或 OLAPContext 记录的上下文信息影响
EnumerableRel implementEnumerable(List :
- 将自身转换成 EnumerableRel,即逻辑节点转为物理节点
-
EnumerableRel#implement方法返回的 Result 用来生成该物理节点对应的 java code
我们以概览中的 sql 来作为示例来对生成物理执行计划的过程进行分析
三、递归调用各 OLAPRel#implementOLAP
3.1、OLAPTableScan#implementOLAP
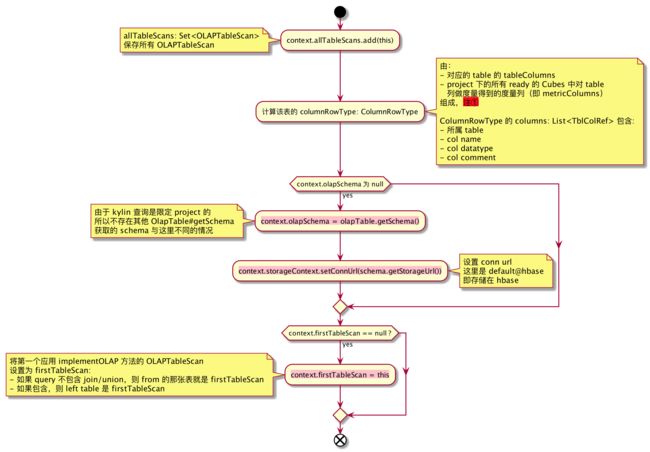
我们对以下几个被修改的实例进一步说明:
- context.firstTableScan:在一个 query 或 subQuery 中,如果包含 join,join 的 left side 要查的表就是 firstTableScan;如果 query 不包含 join,from 后面的表就是 firstTableScan
- firstTableScan 会被当做是 factTable,无论它事实上是不是
- factTable 会影响后面的 realization 选择
由于 firstTableScan 会被当做是 factTable,与概览中的 sql 同义的下面这条 sql 查询时会报 No realization found 的异常,这是因为 Kylin 很不智能的把 left table 作为 firstTableScan(及对应 factTable),但在 Kylin 中没有用以 KYLIN_SALES 为事实表的 model/cube:
SELECT KYLIN_SALES.TRANS_ID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_ACCOUNT
INNER JOIN KYLIN_SALES ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10;
注①:为什么 OLAPTableScan 除了自身的 tableColumns 外,还会包含 metricColumns ?
- 由于 OLAPTableScan 必定是整个 plan(或者说某个 subquery )的叶子节点,上层任何算子要操作的列只能由 OLAPTableScan 提供,如上层要把对 factTable 某列做 count 转化为对 cube 对应 metrics(count 度量)做 SUM,那就必须要有这个 metrics 列
- 作为 OLAPTableScan 并不知晓上层需要哪些列或 metrics 列做怎么样的转换或重写,所以需要把这个表对应的 tableColumns 和 metricsColumns 全都提供出来
- metricsColumns 确实会来自不同的 model 或 cube,不过这没关系,后面会有一个 realization 选择的步骤,并不会导致 query 中的 aggs 某些来自 Cube A,另一些来自 Cube B 这种情况
metricsColumns 命名规则:
- 如果是
COUNT,返回_KY_COUNT_ - 如果是
COUNT (DISTINCT KYLIN_SALES.TRANS_ID),返回_KY_COUNT_DISTINCT_1_3c0c94b7_TRANS_ID_ - 其他,如
SUM(KYLIN_SALES.PRICE),返回_KY_SUM_1_3c0c94b7_PRICE_
其中 1_3c0c94b7 是 KYLIN_SALES 的别名,别名的目的是为了防止出现计算的 SUM(KYLIN_.SALESPRICE) 和 SUM(KYLIN_SALES.PRICE) 的 metricsColumn name 一样的问题
3.2、OLAPJoinRel#implementOLAP

我们对以下几个被修改的实例进一步说明:
- this.isTopJoin:树结构最上层的 join 是 top join,其 isTopJoin 成员才是 true
- context.hasJoin:
- 影响 OLAPProjectRel rewrite 行为,若 context.hasJoin 为 true 且 project 在最内层 join 的内部(context.afterJoin 为 false),则该 OLAPProjectRel 无需做 rewrite。这是因为 OLAPProjectRel#implementRewrite 主要是增加 projectList,增加的是维度做 agg 的度量列(如增加了 Count 的 metrics 列,OLAPAggregateRel 会对该列做 Sum 来替换对原始表相应维度列的 Count),OLAPAggregateRel 会使用该新增的度量列进行 aggregation 部分的 rewrite
- 当一个 OLAPJoinRel 执行 implementOLAP 方法时,context.hasJoin 为 true,则说明该 join 不是最顶层的 join
3.3、OLAPFilterRel#implementOLAP
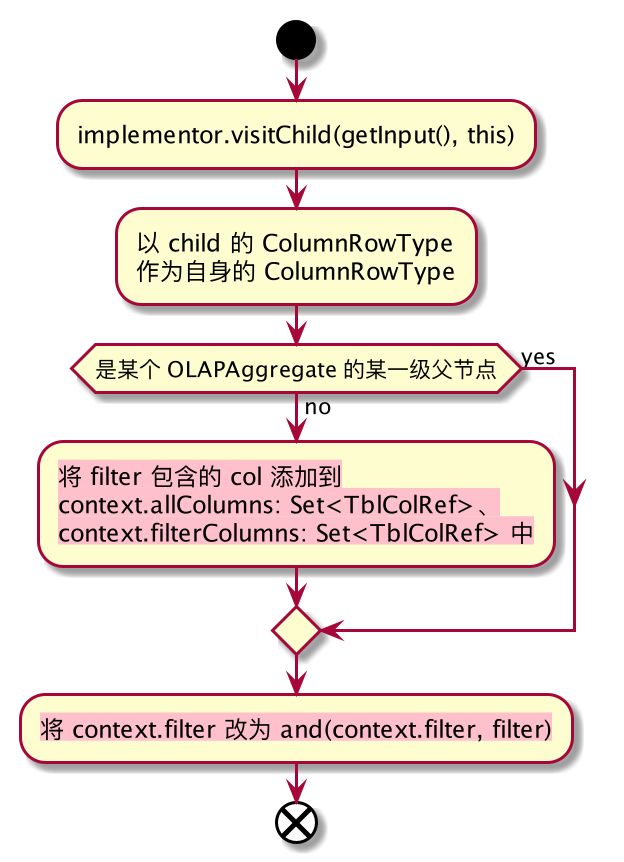
- context.allColumns、context.filterColumns 会影响之后的 cube 选择
- context.filter 会被用来过滤 cube 下的 segments 以及将该 filter 下推到查某个 segment 的数据(会反应在生成发送给 HBase Coprocessor 的代码中)
3.4、OLAPProjectRel#implementOLAP
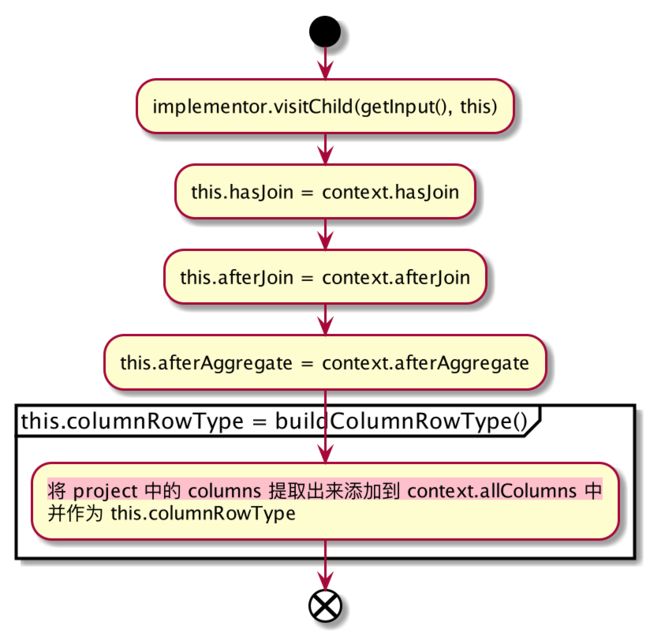
- 如果
this.hasJoin && !this.afterJoin,则 OLAPProjectRel 不会进行 rewrite(visitChild 除外)。这是因为 OLAPProjectRel rewrite 干的事情主要是增加 projectList,增加的是对维度做 agg 的度量列,OLAPAggregateRel 使用该新增的度量列进行 aggregation 部分的 rewrite(比如 OLAPProjectRel rewrite 增加了 Count 的 metrics 列,OLAPAggregateRel 会对该 metrics 列做 SUM 来替换对相应维度列的 COUNT) - context.allColumns 将对最终的 realization 选择产生影响
3.5、OLAPAggregateRel#implementOLAP
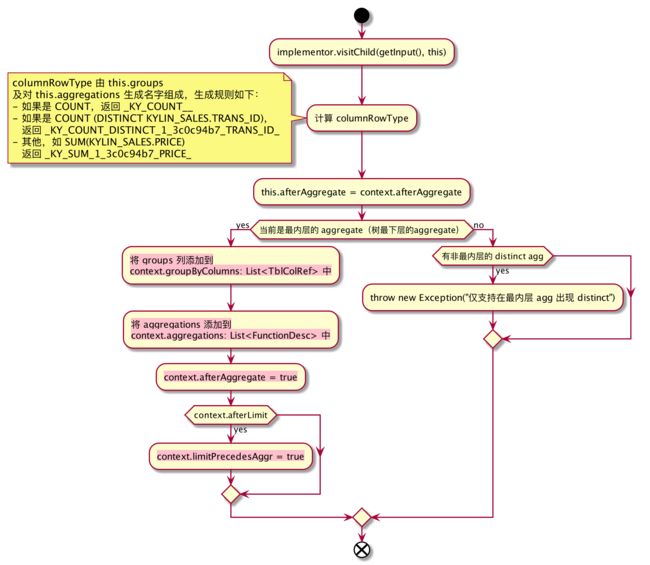
- 计算 columnRowType 时为什么要对 agg 列名做转换?为了与 OLAPTableScan 提供的 metricsColumn 匹配上,以在之后把对源表的列 agg 操作转换为对 cube 的 metricsColumn 列做 agg
- context.groupByColumns、context.aggregations、context.limitPrecedesAggr 会对之后的 realization 产生影响
仅支持最内层的 agg 出现 count distinct 的一个示例如下
SELECT COUNT(DISTINCT TID)
FROM (
SELECT KYLIN_SALES.TRANS_ID AS TID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
) a
报错[图片上传失败...(image-2b7d64-1558959393134)]其实这里可以做个优化,对于这种情况的外层 COUNT DISTINCT 其实可以先对 subQuery 使用预计算
四、选择 Realization
整个过程封装在 RealizationChooser#``selectRealization 中,分为几步来讲
4.1、对 model 及对应的 realizations 进行过滤及排序
- 获取属于该 project 下 factTableName 与查询中事实表相等的所有 realizations,factTableName 即 context.firstTableScan.getTableName
- 对 realizations 执行过滤,得到 filteredRealizations
- NOT READY cube 会被过滤
- 黑名单中的 cube 会被过滤
- cube.allColumns 必须与 OLAPContext.allColumns 相等或是其父集
- cube.allColumns:事实表的外键列;维度表的主键列;所有度量涉及的列;所有维度列
- OLAPContext.allColumns:均在 OLAPRel#implementOLAP 方法中添加
- filterColumns 列,在 OLAPFilterRel#implementOLAP 中添加
- project 包含的列(即 agg 参数列即 group by 列),在 OLAPProjectRel#implementOLAP 添加
- 遍历 filteredRealizations,对于每个 realization,获取其 model,并记录每个 mode 对应的最小的 realization cost 及 model 对应的 Set
- 根据各个 model 对应的最小 realization cost,对各个
model -> ``Set<``IRealization``>进行排序,得到modelMap: Map
如果 modelMap 为空,则抛 No model found for ... 异常
4.2、从 modelMap 中选择最终的 realization
遍历 modelMap: Map
- IRealization realization = QueryRouter.selectRealization(context, entry.getValue())
- 若 realization 不为 null,则 realization 就是选中的 realization,设置为 context.realization,选择过程结束;否则,continue,对下一个 entry 进行同样的调用
- 若遍历完所有的 entry,依然没有符合要求的 realization,则抛异常 NoRealizationFoundException
IRealization selectRealization(OLAPContext olapContext, Set 逻辑如下:
- 对候选的 realizations 应用 3 条规则,以进行过滤和重新排序:
- 移除黑名单、被配置
kylin.query.realization-filter过滤的 - 移除不适用的(逻辑封装在 CubeCapabilityChecker#check 中),以下几种情况不适用:
- OLAPContext 维度列(其 groupByColumns(在 OLAPAggregateRel#implementOLAP 中添加) + filterColumns(在 OLAPFilterRel#implementOLAP 中添加))中存在不在 cube 维度列中的情况
- OLAPContext aggregations(在 OLAPAggregateRel#implementOLAP 中添加) 中存在不在 cube aggregations 中的情况
- limit 在 agg 之前(使用 OLAPContext#limitPrecedesAggr 判断,在 OLAPAggregateRel#implementOLAP 中进行判断),会导致 cube 的度量结果与查询不一致
- 对剩下的进行排序,优先级最高、cost 最小的胜出
五、递归应用 implementRewrite
5.1、OLAPAggregateRel#implementRewrite part1
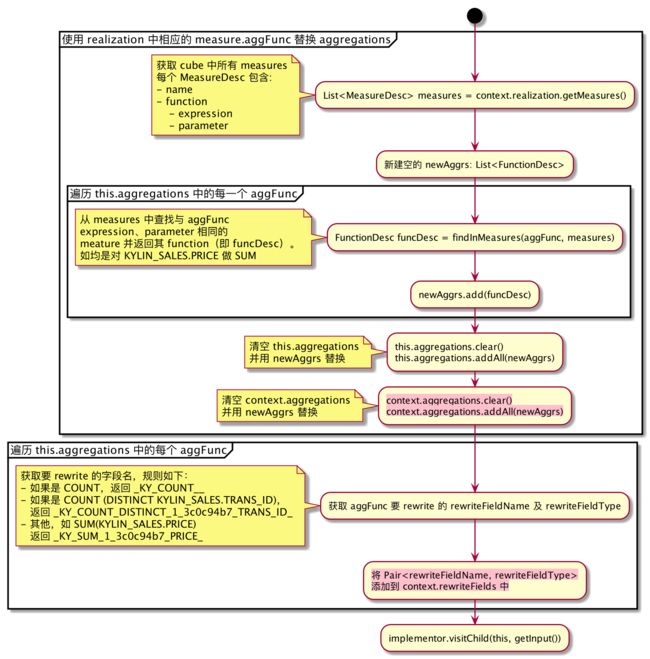
如上,主要分两步:
- 使用 realization 中的 metrics 的 agg 替换原有的 agg,要求 metrics 与原有的 agg 是对相同的列做相同的 agg 计算
- 根据第 1 步中选择的 metrics 计算出 rewriteFields(并添加到 context.rewriteFields 中),会在 OLAPProjectRel#implementOLAP 和 OLAPAggregateRel#implementOLAP part2 中使用
5.2、OLAPProjectRel#implementRewrite
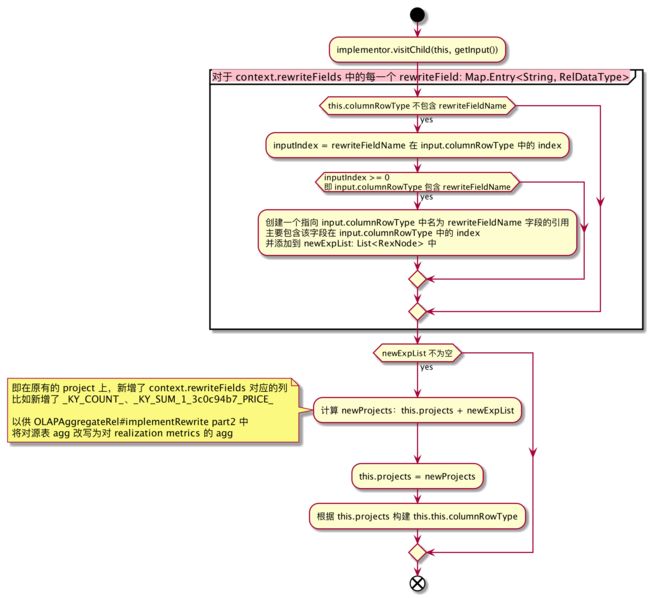
若 context.rewriteFields 不为空,则说明后续 OLAPAggregateRel#implementRewrite part2 会需要把对源表列的 agg 操作重写为对 cube metrics 列的 agg,这这里需要准备好 OLAPAggregateRel#implementRewrite part2 需要的 metrics 列
5.3、OLAPAggregateRel#implementRewrite part2
下面流程图按下标遍历 aggCalls 中的每个元素 aggCall,下标为 i

把对源表列的 agg 操作重写为对 cube metrics 列的 agg,其中如果是 COUNT 操作,需要重写为 SUM。需要注意的是,在这些 OLAPRel 中,columnRowType 各个 col 主要是通过在 input.columnRowType 中的 index 来引用,而不是直接使用 name(当然也会包含 name)
本例中:
- 把
SUM(KYLIN_SALES.PRICE)重写为SUM(_KY_SUM_1_3c0c94b7_PRICE_)- PRICE 在 input.columnRowType 中 index 为 1
-
_KY_SUM_1_3c0c94b7_PRICE_在 input.columnRowType 中 index 为 4
- 把
COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)重写为SUM(_KY_COUNT__)- ACCOUNT_ID 在 input.columnRowType 中 index 2
-_KY_COUNT__在 input.columnRowType 中 index 3
- ACCOUNT_ID 在 input.columnRowType 中 index 2
六、生成物理执行计划及 code gen
由于 Calcite 各个物理节点及 code gen 涉及代码及模块非常多,暂不在这里展开
每个EnumerableRel#implement 方法返回的 Result 都会生成一段 java code,parent EnumerableRel 生成的 java code 还会包含 child 生成的 java code,最终最顶层的 EnumerableRel 生成的 java code 就是完整的。
在 Kylin 中,OLAPJoinRel 对应的物理节点还是其自身,当 OLAPJoinRel#implement 生成用于生成 java code 的 Result 时,并不会使用到其 children,而是直接使用 OLAPContext.firstTableScan 作为事实表来获取其对应的 OLAPQuery 实例,如本例中的 join 生成的最终代码如下
return ((org.apache.kylin.query.schema.OLAPTable) root.getRootSchema()
.getSubSchema("DEFAULT").getTable("KYLIN_SALES")).executeOLAPQuery(root, 0);
事实上,虽然 OLAPJoinRel#implement 没有直接使用 children 生成的代码,但其 left OLAPTableScan#implement 得到的 Result 生成的代码也是
return ((org.apache.kylin.query.schema.OLAPTable) root.getRootSchema()
.getSubSchema("DEFAULT").getTable("KYLIN_SALES")).executeOLAPQuery(root, 0);
另外,OLAPToEnumerableConverter 也继承了 EnumerableRel,实现了自己的 implement 物化方法,也就是触发了本文中所有:
- 自顶向下递归调用各个 OLAPRel 节点 implementOLAP 方法
- realization 选择
- 自顶向下递归调用各个 OLAPRel 节点 implementRewrite 方法
- 将各个 OLAPRel 转为 EnumerableRel
- 自顶向下递归调用各个 EnumerableRel 节点 implement 方法得到用于生成 java code 的 Result
上述例子生成的 java 代码如下:
// _inputEnumerable 为 OLAPQuery 类型,OLAPQuery
final org.apache.calcite.linq4j.Enumerable _inputEnumerable = ((org.apache.kylin.query.schema.OLAPTable) root.getRootSchema().getSubSchema("DEFAULT").getTable("KYLIN_SALES")).executeOLAPQuery(root, 0);
final org.apache.calcite.linq4j.AbstractEnumerable child = new org.apache.calcite.linq4j.AbstractEnumerable(){
public org.apache.calcite.linq4j.Enumerator enumerator() {
return new org.apache.calcite.linq4j.Enumerator(){
// 类型,OLAPQuery.enumerator() 得到的 inputEnumerator 为 OLAPEnumerator 类型
// inputEnumerator 会调用 StorageEngine 去 HBase 中查询指定 cube、指定 cuboid(及可能的 filter 下推)数据
public final org.apache.calcite.linq4j.Enumerator inputEnumerator = _inputEnumerable.enumerator();
public void reset() {
inputEnumerator.reset();
}
public boolean moveNext() {
while (inputEnumerator.moveNext()) {
final Integer inp4_ = (Integer) ((Object[]) inputEnumerator.current())[4];
if (inp4_ != null && inp4_.intValue() != 1000) {
return true;
}
}
return false;
}
public void close() {
inputEnumerator.close();
}
public Object current() {
final Object[] current = (Object[]) inputEnumerator.current();
return new Object[] {
current[0],
current[5],
current[13],
current[11],
current[10]};
}
};
}
};
return child.groupBy(new org.apache.calcite.linq4j.function.Function1() {
public Long apply(Object[] a0) {
return (Long) a0[0];
}
public Object apply(Object a0) {
return apply(
(Object[]) a0);
}
}
, new org.apache.calcite.linq4j.function.Function0() {
public Object apply() {
java.math.BigDecimal a0s0;
boolean a0s1;
a0s1 = false;
a0s0 = new java.math.BigDecimal(0L);
long a1s0;
a1s0 = 0;
Record3_0 record0;
record0 = new Record3_0();
record0.f0 = a0s0;
record0.f1 = a0s1;
record0.f2 = a1s0;
return record0;
}
}
, new org.apache.calcite.linq4j.function.Function2() {
public Record3_0 apply(Record3_0 acc, Object[] in) {
final java.math.BigDecimal inp4_ = in[4] == null ? (java.math.BigDecimal) null : org.apache.calcite.runtime.SqlFunctions.toBigDecimal(in[4]);
if (inp4_ != null) {
acc.f1 = true;
acc.f0 = acc.f0.add(inp4_);
}
acc.f2 = acc.f2 + org.apache.calcite.runtime.SqlFunctions.toLong(in[3]);
return acc;
}
public Record3_0 apply(Object acc, Object in) {
return apply(
(Record3_0) acc,
(Object[]) in);
}
}
, new org.apache.calcite.linq4j.function.Function2() {
public Object[] apply(Long key, Record3_0 acc) {
return new Object[] {
key,
acc.f1 ? acc.f0 : (java.math.BigDecimal) null,
acc.f2};
}
public Object[] apply(Object key, Object acc) {
return apply(
(Long) key,
(Record3_0) acc);
}
}
).orderBy(new org.apache.calcite.linq4j.function.Function1() {
public Long apply(Object[] v) {
return (Long) v[0];
}
public Object apply(Object v) {
return apply(
(Object[]) v);
}
}
, org.apache.calcite.linq4j.function.Functions.nullsComparator(false, false)).take(10);
我们可以看到,整个计算过程迭代的读取指定 cube、指定 cuboid 数据,并执行相应的计算逻辑,是一个基于内存的单机计算过程
七、支持/不支持 场景
7.1、支持
1、project list 中对 group col、agg 做一些计算
SELECT KYLIN_SALES.TRANS_ID * 6, SUM(KYLIN_SALES.PRICE) + 1, COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10;
通过多加了一层 Project 来实现

2、count 参数不是直接的列
SELECT KYLIN_SALES.TRANS_ID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID + 100)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10;
7.2、不支持
1、非最内层的 agg 包含 COUNT DISTINCT
SELECT COUNT(DISTINCT TID)
FROM (
SELECT KYLIN_SALES.TRANS_ID AS TID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
) a
报错

其实这里可以做个优化,对于这种情况的外层 COUNT DISTINCT 其实可以先对 subQuery 使用预计算
2、修改 agg 参数(count 除外)
SELECT KYLIN_SALES.TRANS_ID, SUM(KYLIN_SALES.PRICE + 100), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_SALES
INNER JOIN KYLIN_ACCOUNT ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10
报错

3、join 把维表作为左表
SELECT KYLIN_SALES.TRANS_ID, SUM(KYLIN_SALES.PRICE), COUNT(KYLIN_ACCOUNT.ACCOUNT_ID)
FROM KYLIN_ACCOUNT
INNER JOIN KYLIN_SALES ON KYLIN_SALES.BUYER_ID = KYLIN_ACCOUNT.ACCOUNT_ID
WHERE KYLIN_SALES.LSTG_SITE_ID != 1000
GROUP BY KYLIN_SALES.TRANS_ID
ORDER BY TRANS_ID
LIMIT 10
报错

Kylin 机械的将 join 坐表作为 factTable
4、最内层的 agg 内还有 limit
SELECT SUM(KYLIN_SALES.PRICE) FROM KYLIN_SALES
查询成功
SELECT SUM(PRICE) FROM (
SELECT * FROM KYLIN_SALES LIMIT 1000
) A
报错

7.3、与 Calcite Materialized Views 比较
- predicate 补偿:不支持、也不需要
- grouping 补偿:支持
- agg 补偿:支持
Kylin 是怎么做到 grouping 和 agg 补偿的?答:在计算哪个 cuboid 可满足 query 的时候,会优先根据 grouping cols、agg cols、filter cols 来计算一个 cuboid id:
- 当该 cuboid id 对应的 cuboid 存在,则使用该 cuboid
- 当不存在,则会尝试从已经存在的 cuboids 中寻找一个最佳的替代 cuboid,具体过程封装在
CuboidScheduler#findBestMatchCuboid中,比如当 cuboid id 为001000000000000100的 cuboid 不存在,会使用 id 为111111111111111111的 cuboid
上述使用替代的 cuboid 与 grouping 补偿和 agg 补偿原理一致,均是通过更细粒度的 grouping 或 agg 来实现