Paddle 和Keras复现VGG
Paddle和Keras复现VggNet
- 前言
- 一、VGGNet
-
- 1.简介
- 2. 网络结构
- 二、网络复现步骤
-
- 1.Paddle复现
- 2.Keras复现
- 总结
前言
大家好!距离上一篇博客已经有十天了,因为这十天我去了解Paddle了,这是百度的一个框架,官网已经有很多教程了。设计理念有点类似与Pytorch,但是之前学Keras的我,拿着代码一脸懵逼。慢慢啃了一下,这里就跟大家分享一下。另外VGGNet 用keras的复现我也做了,会在下面附上链接。我会在这篇博客简单介绍,由于我也是刚开始了解,介绍不对的地方还请大家指正。
| 内容 | 地址 |
|---|---|
| Paddle复现 | 链接 |
| Keras复现 | 链接 |
数据集在链接里都会有,这里就不给出了,只是模型的效果并不是很好,大概都只是60%左右的准确率。没有设备去跑ImageNet!
一、VGGNet
1.简介
随着深度学习的不断发展,加深的网络开始不断的出现了,VGGNet 验证了卷积网络的加深,的确能够提升网络的性能,但计算量也随之增大了。VGGNet 在2014年ILSVRC得到挑战赛中赢得了定位任务的冠军和分类任务的亚军。VGGNet的思想就是采用2个3x3的卷积核代替了5x5的卷积核,网络的结构也从传统的卷积池化相连,变成了多层卷积后再跟池化相连。有两种基本类型的VGGNet 就是我们常用的VGG16 和VGG19.
2. 网络结构
神经网络,通常都是上图比较直接。
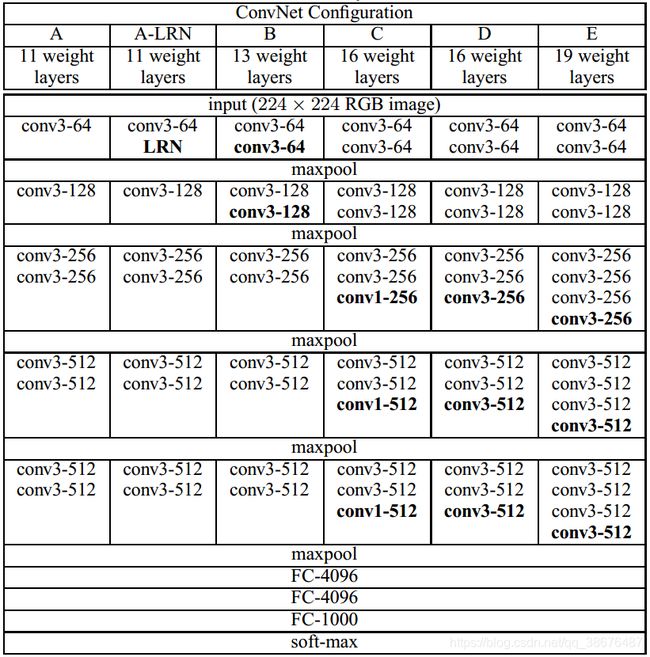
- A模型: 拥有八个卷积层(卷积核核大小均为3×3),5个最大池化和3个全连接层。
- A-LRN模型:卷积核核大小均为3×3,与A模型几乎完全相同,唯一的区别就是第一个卷积后加入了LRN(局部响应归一化层,在前面的文章AlexNet中提出)。但是通过实验证明LRN不仅会增加计算时候和内存消耗,对网络性能,并没有很大的提升。所以在后续的网络中都取消了。
- B模型:拥有10个卷积层(核大小均为3×3)、 5个最大池化层和3个全连接层。
- C模型:拥有13个卷积层(10个核大小为3×3, 3个核大小为1×1)、 5个最大池 化层和 3 个全连接层。
- D模型:拥有13个卷积层(核大小均为3×3)、 5个最大池化层和3个全连接层。
- E模型:拥有16个卷积层(核大小均为3×3)、 5个最大池化层和3个全连接层。
D,E模型就是我们常说的VGG16和VGG19啦!!!!
二、网络复现步骤
1.Paddle复现
- 数据集的读取。
Paddle的数据读取,在我看来比Keras稍微复杂了一些。他需要自己去定义一个数据集类。然后通过加载图片指定路径,将图片读入,读入后需要将图片转化为Tensor 不能直接使用numpy array进行 计算。
定义非自带数据集 paddle.io.Dataset
概述Dataset的方法和行为的抽象类。
映射式(map-style)数据集需要继承这个基类,映射式数据集为可以通过一个键值索引并获取指定样本的数据集,所有映射式数据集须实现以下方法:
getitem: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。
len: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
数据集对象的返回也是一个generator,为了防止数据量过多,读入时导致内存不足。这一点我还是觉得十分人性化的。
首先看一下文件树
├─work
├─data
│ │ maskDetect
│ │ train.txt
│ │ eval.txt
│ │ readme.json
下面我们看数据集处理的实现。
import paddle
import paddle.io
import numpy as np
class DataSet(paddle.io.Dataset):
def __init__(self,mode='train'):
super(DataSet,self).__init__()
self.data = [] #存放数据
self.label=[] #存放标签
if mode == 'train': #加载训练集
with open(train_list_path,'r') as f: #打开训练集的路径文件
lines = [line.strip() for line in f] #
print(lines)
for line in lines:
img_path,label = line.strip().split('\t') #读入文件的路径和标签 字符串
img = Image.open(img_path) #从文件中打开图片
if img.mode !='RGB': #转换图片颜色空间
img = img.convert('RGB')
img = img.resize((224,224),Image.BILINEAR) #使用双线插值 重设图像的大小 VGG输入的图像大小为224 *224
#将图片转换为数组
img = np.array(img).astype('float32')
img = img.transpose((2,0,1)) #这是转换顺序 H 0, W 1 ,C 2 从 HWC, 转换为CHW
img = img/255.0
self.data.append(img)
self.label.append(np.array(label).astype('int'))
else:
with open(eval_list_path,'r') as f: #注解同上 这里只是把路径换了 去
lines = [line.strip() for line in f]
print(lines)
for line in lines:
img_path,label = line.strip().split('\t')
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224,224),Image.BILINEAR)
#将图片转换为数组
img = np.array(img).astype('float32')
img = img.transpose((2,0,1)) #这是转换顺序 H 0, W 1 ,C 2 从 HWC, 转换为CHW
img = img/255.0
self.data.append(img)
self.label.append(np.array(label).astype('int'))
def __getitem__(self,index):
#重构这个函数的目的应该是为了到时候使用 数据记载器的时候能够找到?
#返回单一数据和标签
data = self.data[index]
label = self.label[index]
#注:这里返回的标签必须是int64
return data ,np.array(label,dtype='int64')
def __len__(self):
#返回数据的总条数
return len(self.data)
train_dataset=DataSet(mode='train')
eval_dataset=DataSet(mode='eval')
print('=============train_dataset =============')
print(train_dataset.__getitem__(1)[0].shape,train_dataset.__getitem__(1)[1])
print(train_dataset.__len__())
print('=============eval_dataset =============')
print(eval_dataset.__getitem__(1)[0].shape,eval_dataset.__getitem__(1)[1])
print(eval_dataset.__len__())
- 网络结构实现:
由于VGG的结构比较特殊,不能直接去写16或9个层,这样显然是很愚蠢的。我们先把块给定义好:
import paddle
class ConvPool(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
fliter_size=3,
pool_size=2,
pool_stride=2,
groups=1,
conv_stride=1,
conv_padding=0,
):
super(ConvPool,self).__init__()
self.conv2d_list = []
print(num_channels,num_filters)
for i in range(groups):
conv2d= self.add_sublayer(
'bb_%d'%i,
paddle.nn.Conv2D(
in_channels = num_channels, #输入通道数
out_channels= num_filters, #输出通道数
kernel_size=fliter_size, #卷积核的大小
stride=conv_stride, #卷积核的步长
padding=1 #填充
)
)
num_channels = num_filters
self.conv2d_list.append(conv2d)
self.pool2d = paddle.nn.MaxPool2D(kernel_size=pool_size,stride=pool_stride)
def forward(self,inputs):
x=inputs
for conv in self.conv2d_list:
x=conv(x)
x=self.pool2d(x)
return x
Paddle 和Keras 不同的点是需要自己去做前向传播操作。我觉得这样有助于更好的理解网络结构。Paddle 的卷积实现呢也更多的是去关注通道数。
这里我主要是去实现的VGG16。先看一下VGG16的详细结构。
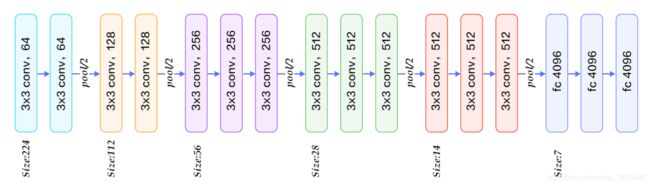
详细实现:
mport paddle
class VGGNet(paddle.nn.Layer):
def __init__(self):
super(VGGNet,self).__init__()
self.block1 = ConvPool(3,64,groups=2) # 分别是输入通道 输出通道 卷积次数 1~5块
self.block2 = ConvPool(64,128,groups=2)
self.block3 = ConvPool(128,256,groups=3)
self.block4 = ConvPool(256,512,groups=3)
self.block5 = ConvPool(512,512,groups=3)
#全连接层定义 由于训练数据过少,我就不定义多个全连接层了
self.fc1 = paddle.nn.Linear(in_features=7*7*512,out_features=2)
#定义前向传播
def forward(self,inputs):
out = self.block1(inputs)
#print(out.shape)
out = self.block2(out)
out = self.block3(out)
out = self.block4(out)
out = self.block5(out)
out = paddle.flatten(out,start_axis=1,stop_axis=-1) #和tensorflow的flatten 很像 直接把像素强行拉平
out = self.fc1(out)
out = paddle.nn.functional.softmax(out)
return out
model = paddle.Model(VGGNet())
model.summary((None,3,224,224))
网络结构输出:
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 64, 224, 224] 1,792
Conv2D-2 [[1, 64, 224, 224]] [1, 64, 224, 224] 36,928
MaxPool2D-1 [[1, 64, 224, 224]] [1, 64, 112, 112] 0
ConvPool-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 0
Conv2D-3 [[1, 64, 112, 112]] [1, 128, 112, 112] 73,856
Conv2D-4 [[1, 128, 112, 112]] [1, 128, 112, 112] 147,584
MaxPool2D-2 [[1, 128, 112, 112]] [1, 128, 56, 56] 0
ConvPool-2 [[1, 64, 112, 112]] [1, 128, 56, 56] 0
Conv2D-5 [[1, 128, 56, 56]] [1, 256, 56, 56] 295,168
Conv2D-6 [[1, 256, 56, 56]] [1, 256, 56, 56] 590,080
Conv2D-7 [[1, 256, 56, 56]] [1, 256, 56, 56] 590,080
MaxPool2D-3 [[1, 256, 56, 56]] [1, 256, 28, 28] 0
ConvPool-3 [[1, 128, 56, 56]] [1, 256, 28, 28] 0
Conv2D-8 [[1, 256, 28, 28]] [1, 512, 28, 28] 1,180,160
Conv2D-9 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,359,808
Conv2D-10 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,359,808
MaxPool2D-4 [[1, 512, 28, 28]] [1, 512, 14, 14] 0
ConvPool-4 [[1, 256, 28, 28]] [1, 512, 14, 14] 0
Conv2D-11 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,359,808
Conv2D-12 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,359,808
Conv2D-13 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,359,808
MaxPool2D-5 [[1, 512, 14, 14]] [1, 512, 7, 7] 0
ConvPool-5 [[1, 512, 14, 14]] [1, 512, 7, 7] 0
Linear-1 [[1, 25088]] [1, 2] 50,178
- 模型训练配置
模型的训练配置和Keras 十分相似这里就不细说了。
model.prepare(paddle.optimizer.Adam(
parameters=model.parameters()), #优化器
paddle.nn.CrossEntropyLoss(), #交叉熵损失函数
paddle.metric.Accuracy(topk=(1,5))) # 计算准确率的个数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log') ## 训练可视化VisualDL工具的回调函数
#启动模型训练流程
model.fit(
train_dataset, #训练集
eval_dataset, #测试集
epochs=10, #训练次数
batch_size= batch_size, #批次样本大小
# verbose=1, #日志格式
shuffle= True, #打乱样本集
save_dir='./chk_point/',
callbacks=[visualdl]
)
model.save('model_save_dir')
- 模型的预测
def load_image(img_path):
'''
预测图片预处理
'''
#具体过程与自定义数据集差不多,不再赘述
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255
return img
label_dict = train_parameters['label_dict']
#模型预测
inf_path = 'data/maskDetect/maskimages/39518ca49d9c93e3f7fc93914416f440.jpg'
img = Image.open(inf_path)
#绘制图像
import matplotlib.pyplot as plt
plt.imshow(img)
plt.show()
img = Image.open('data/maskDetect/nomaskimages/29c32eac746b3eea8f7c763d4b4c3b57.jpg')
#绘制图像
import matplotlib.pyplot as plt
plt.imshow(img)
plt.show()
infer_imgaes =[]
infer_imgaes.append(load_image(inf_path))
infer_imgaes.append(load_image('data/maskDetect/nomaskimages/29c32eac746b3eea8f7c763d4b4c3b57.jpg'))
infer_imgaes = np.array(infer_imgaes)
for i in range(len(infer_imgaes)):
data = infer_imgaes[i]
dy_x_data = np.array(data).astype('float32')
print(dy_x_data.shape)
dy_x_data = dy_x_data[np.newaxis,np.newaxis,:,:,:]
print(dy_x_data.shape)
out = model.predict(dy_x_data)
print(out)
label = np.argmax(out[0][0])
print("第{}个样本,被预测为:{}".format(i+1,label_dict[str(label)]))
print("结束")
这里有一个地方不理解的是,为何在预测时需要把图像变成五维度的向量,再输入到网络进行预测。
2.Keras复现
Keras的复现就相对比较简单了。但再这里我重点去介绍的是Keras中的ImageDataGenerator,它可以批量读取数据,并进行数据增强,不用一次把数据读入内存中。也是防止内存溢出的方法。参数含义再代码里都有注解,这里不再赘述。
我们来看一下具体实现:
#本次代码写得比较精简,同时我们不用之前封装好的代码了今天呢我发现了keras自带得数据读取,划分和增强函数,
#同时还能批量读入解决缓存不够的问题
#首先选用的数据集 是furits-360
#总共有131个分类 我们开始用我们今天的主角吧
from keras.preprocessing.image import ImageDataGenerator
train_data_dir='../input/104-flowers-garden-of-eden/jpeg-224x224/train'
val_data_dir='../input/104-flowers-garden-of-eden/jpeg-224x224/val'
test_data_dir='../input/104-flowers-garden-of-eden/jpeg-224x224/test'
train_datagen=ImageDataGenerator(
rescale=1/255.0, #归一化
rotation_range=10, #图片随机旋转的角度
zoom_range=0.05, # 图片随机缩放的幅度
width_shift_range=0.05, #图片水平偏移的幅度
height_shift_range=0.05, #图片垂直偏移的幅度
shear_range=0.05,#裁剪强度
horizontal_flip=True,#水平翻转
fill_mode='nearest')#;‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理) #验证集的占比
batch_size =50 #
#训练集
train_generator = train_datagen.flow_from_directory(
directory=train_data_dir, #图片文件路径
target_size=(224,224),#读入时设置的大小
color_mode='rgb',#颜色模式
batch_size=batch_size,
class_mode='categorical', #分类模式
shuffle=True, #乱序
seed=42 #随机数粽子
)
#验证集
val_datagen=ImageDataGenerator(rescale=1/255.0)
valid_generator = val_datagen.flow_from_directory(
directory=val_data_dir,
target_size=(224, 224),
color_mode="rgb",
batch_size=batch_size,
class_mode="categorical",
shuffle=True,
seed=42
)
#测试集
test_datagen = ImageDataGenerator(rescale=1/255.0) #测试机只设置归一化
test_generator = test_datagen.flow_from_directory(
directory=test_data_dir,
target_size=(224,224),
color_mode='rgb',
batch_size=batch_size,
class_mode=None,
shuffle=False,
seed=42
)
网络模型配置,参考前面的方法,先定义模型块。再去定义VGG16网络
# VGG 网络的定义哦,用于VGG的网络结构层数比较多 这里采用一块一块的定义
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout,Input,ZeroPadding2D,GlobalAveragePooling2D
from tensorflow.python.keras import backend
from tensorflow.python.keras.applications import imagenet_utils
from tensorflow.python.keras.engine import training
from tensorflow.python.keras.layers import VersionAwareLayers
from tensorflow.python.keras.utils import data_utils
from tensorflow.python.keras.utils import layer_utils
from tensorflow.python.lib.io import file_io
from tensorflow.python.util.tf_export import keras_export
def vgg(conv_arch, classes=10, input_shape=(224, 224, 3), input_tensor=None,include_top=False):
"""
vgg的各层卷积次数及卷积核的大小
classes 分类数量,
input_shape 输入大小
input_tensor 输入的向量
"""
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
x = ZeroPadding2D(((0, 0), (0, 0)))(img_input)
for (num_convs, num_filter) in conv_arch:
for _ in range(num_convs):
x = Conv2D(num_filter, kernel_size=3, padding='same', activation='relu')(x)
x=MaxPooling2D(pool_size=(2, 2), strides=2)(x)
if include_top:
x = Flatten()(x)
x = Dense(4096,activation='relu')(x)
x = Dense(4096,activation='relu')(x)
x=Dense(classes,activation='softmax')(x)
else:
x=GlobalAveragePooling2D()(x)
x=Dense(classes,activation='softmax')(x)
if input_tensor is not None:
inputs = layer_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
model = training.Model(inputs, x, name='Vgg')
return model
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
vgg16=vgg(conv_arch,input_shape=(224,224,3),classes=104)
vgg16.summary()
配置训练
lr=0.0001
epochs=15
opt=Adam(lr=lr,decay=lr/(epochs/0.5))
vgg16.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['acc'])
vgg16.fit(train_generator,validation_data=valid_generator,
steps_per_epoch=train_generator.n//train_generator.batch_size,
validation_steps=valid_generator.n//valid_generator.batch_size,
epochs=epochs
)
训练的准确率也大概实在60%左右!!
总结
通过学习,十天写完代码,参考的链接太多,就不再这里给出,主要时参考Paddle官网,aistudio上面大佬们分享的经验和代码。十分困难。个人感觉还是支持Paddle。后面的文章可能会使用Paddle去复现,Keras十分容易上手,推荐新手可以先从Keras 学起。不多说了,下一篇可能去复现GoogleNet。复现过程中不会去追求精度。没有设备跑ImageNet数据集。我们下一篇见。