前段时间我们分享过玩转Flume+Kafka原来也就那点事儿(http://mp.weixin.qq.com/s?__biz=MzAwNjQwNzU2NQ==&mid=402561857&idx=2&sn=f79761fe60d0d51151eb3bba16d36080#rd)和Flume-NG源码分析-整体结构及配置载入分析(http://mp.weixin.qq.com/s?__biz=MzAwNjQwNzU2NQ==&mid=402640265&idx=1&sn=75c3846e02539bc37d36eecb36844660#rd)这二篇文章,主要介绍了flume的简单使用和配置文件加载的全过程,那么今天我们重点分析flume核心原理,从而了解Source、Channel和Sink的全链路过程。
一、Flume架构分析
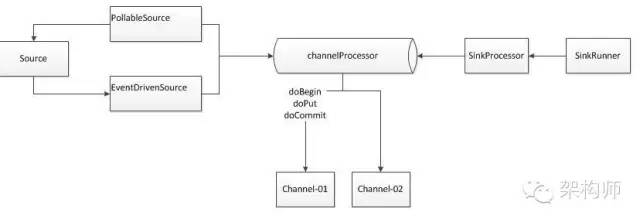
F7C59934-2C22-4F45-BE12-FCC9BB2A1708.png
这个图中核心的组件是:
Source,ChannelProcessor,Channel,Sink。他们的关系结构如下:

二、各组件详细介绍
1、Source组件
Source是数据源的总称,我们往往设定好源后,数据将源源不断的被抓取或者被推送。
常见的数据源有:ExecSource,KafkaSource,HttpSource,NetcatSource,JmsSource,AvroSource等等。
所有的数据源统一实现一个接口类如下:
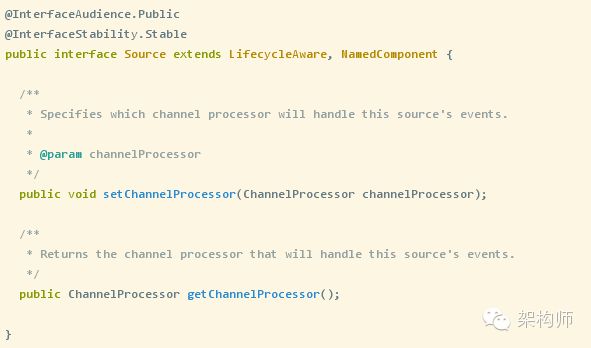
Source提供了两种机制: PollableSource(轮询拉取)和EventDrivenSource(事件驱动):
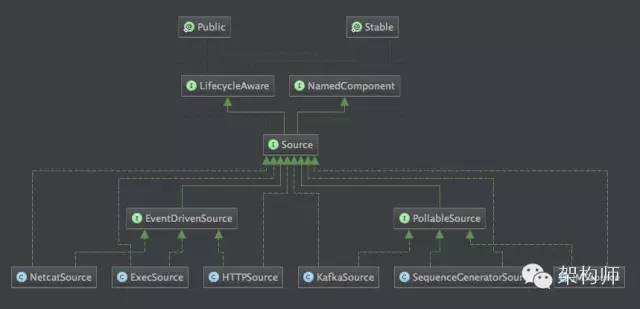
B0F4FCCA-7DAF-4E2B-B1DB-1AC23ACA2128.png
上图展示的Source继承关系类图。
通过类图我们可以看到NetcatSource,ExecSource和HttpSource属于事件驱动模型。KafkaSource,SequenceGeneratorSource和JmsSource属于轮询拉取模型。
Source接口继承了LifecycleAware接口,它的的所有逻辑的实现在接口的start和stop方法中进行。
下图是类关系方法图:
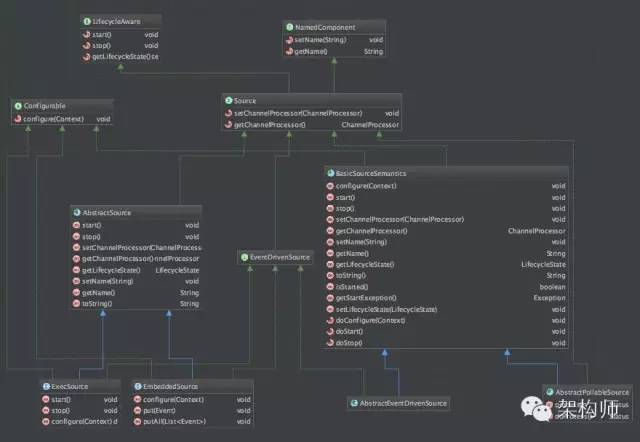
E8953D29-35EC-4A63-AC72-78675BE0A56E.png
Source接口定义的是最终的实现过程,比如通过日志抓取日志,这个抓取的过程和实际操作就是在对应的Source实现中,比如:ExecSource。那么这些Source实现由谁来驱动的呢?现在我们将介绍SourceRunner类。将看一下类继承结构图:
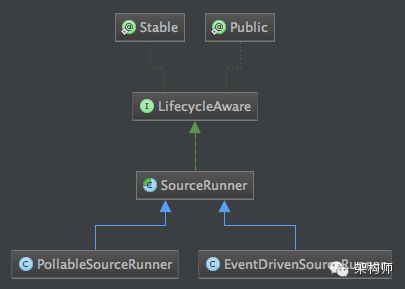
Paste_Image.png
我们看一下PollableSourceRunner和EventDrivenSourceRunner的具体实现:


注:其实所有的Source实现类内部都维护着线程,执行source.start()其实就是启动了相应的线程。
刚才我们看代码,代码中一直都在展示channelProcessor这个类,同时最上面架构设计图里面也提到了这个类,那它到底是干什么呢,下面我们就对其分解。
2、Channel组件
Channel用于连接Source和Sink,Source将日志信息发送到Channel,Sink从Channel消费日志信息;Channel是中转日志信息的一个临时存储,保存有Source组件传递过来的日志信息。
先看代码如下:
ChannelSelectorConfiguration selectorConfig = config.getSelectorConfiguration();
ChannelSelector selector = ChannelSelectorFactory.create(sourceChannels, selectorConfig);
ChannelProcessor channelProcessor = new ChannelProcessor(selector);
Configurables.configure(channelProcessor, config);
source.setChannelProcessor(channelProcessor);
ChannelSelectorFactory.create方法实现如下:
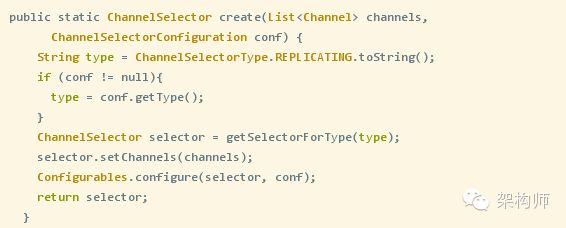
其中我们看一下ChannelSelectorType这个枚举类,包括了几种类型:

ChannelSelector的类结构图如下所示:

Paste_Image.png
注:RelicatingChannelSelector和MultiplexingChannelSelector是二个通道选择器,第一个是复用型通道选择器,也就是的默认的方式,会把接收到的消息发送给其他每个channel。第二个是多路通道选择器,这个会根据消息header中的参数进行通道选择。
说完通道选择器,正式来解释Channel是什么,先看一个接口类:

注:put方法是用来发送消息,take方法是获取消息,transaction是用于事务操作。
类结构图如下:
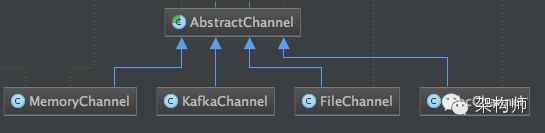
Paste_Image.png

Paste_Image.png
3、Sink组件
Sink负责取出Channel中的消息数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Sink接口类内容如下:
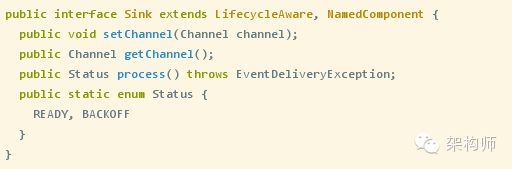
Sink是通过如下代码进行的创建:
DefaultSinkFactory.create方法如下:

注:Sink是通过SinkFactory工厂来创建,提供了DefaultSinkFactory默认工厂,程序会查找org.apache.flume.conf.sink.SinkType这个枚举类找到相应的Sink处理类,比如:org.apache.flume.sink.LoggerSink,如果没找到对应的处理类,直接通过Class.forName(className)进行直接查找实例化实现类。
Sink的类结构图如下:

Paste_Image.png
与ChannelProcessor处理类对应的是SinkProcessor,由SinkProcessorFactory工厂类负责创建,SinkProcessor的类型由一个枚举类提供,看下面代码:
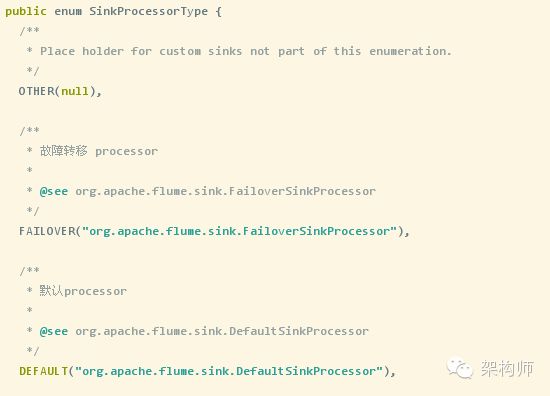

SinkProcessor的类结构图如下:
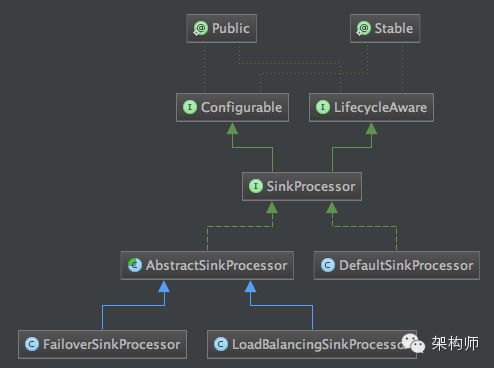
Paste_Image.png
说明:
1、FailoverSinkProcessor是故障转移处理器,当sink从通道拿数据信息时出错进行的相关处理,代码如下:

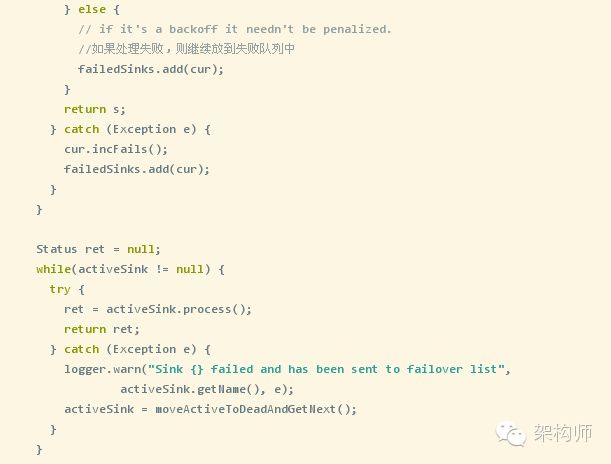
2、LoadBalancingSinkProcessor是负载Sink处理器
首先我们和ChannelProcessor一样,我们也要重点说明一下SinkSelector这个选择器。
先看一下SinkSelector.configure方法的部分代码:

结合上面的代码,再看类结构图如下:
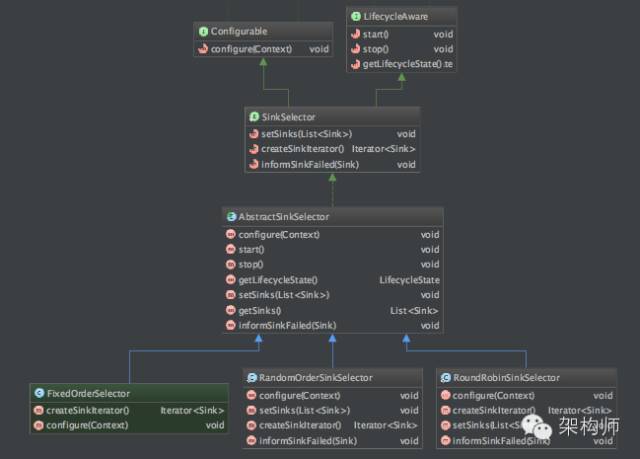
Paste_Image.png
注:RoundRobinSinkSelector是轮询选择器,RandomOrderSinkSelector是随机分配选择器。
最后我们以KafkaSink为例看一下Sink里面的具体实现:

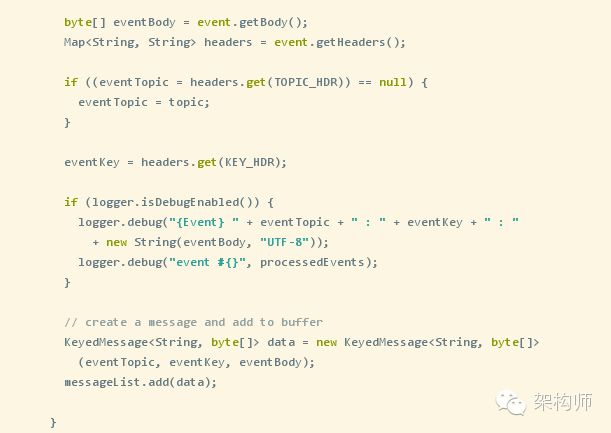


注:方法从channel中不断的获取数据,然后通过Kafka的producer生产者将消息发送到Kafka里面
来源:>小程故事多
原文:http://www.jianshu.com/p/befa9c06baad