selenium中文文档:
https://selenium-python-zh.readthedocs.io/en/latest/navigating.html#id2
查找元素:

image.png
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
下面是 By 类的一些可用属性:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
login_form = driver.find_element_by_id('loginForm')#id
username = driver.find_element_by_name('username')#name
password = driver.find_element_by_name('password')
continue = driver.find_element_by_name('continue')
login_form = driver.find_element_by_xpath("/html/body/form[1]")#xpath
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
定位元素,lxml和selenium的区别

image.png
表单元素

image.png
select
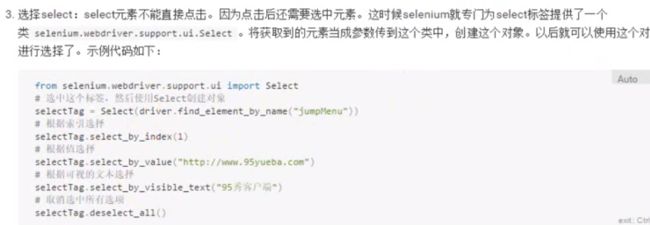
image.png
按钮的点击事件

image.png
行为链
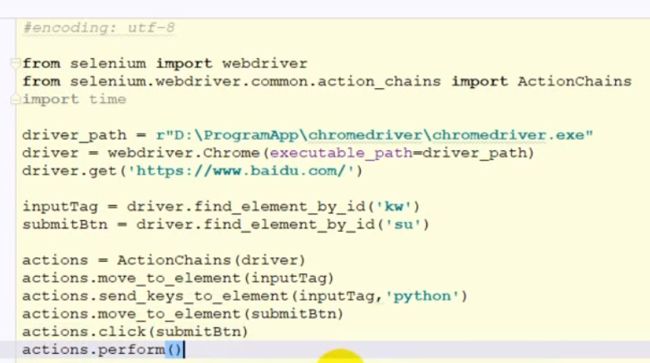
image.png

image.png
cookie操作

image.png
打开一个页面 driver.get(“ http://www.example.com”)
现在设置Cookies,这个cookie在域名根目录下(”/”)生效 cookie = {‘name’ : ‘foo’, ‘value’ : ‘bar’} driver.add_cookie(cookie)
现在获取所有当前URL下可获得的Cookies driver.get_cookies()
页面等待
显式等待是你在代码中定义等待一定条件发生后再进一步执行你的代码。 最糟糕的案例是使用time.sleep(),它将条件设置为等待一个确切的时间段。 这里有一些方便的方法让你只等待需要的时间。WebDriverWait结合ExpectedCondition 是实现的一种方式。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)#最多等10s,有就有,没就抛异常
finally:
driver.quit()
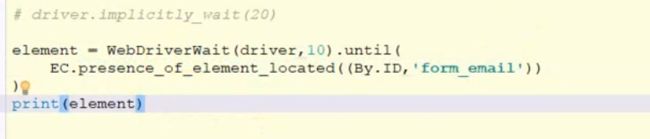
image.png
隐式等待
如果某些元素不是立即可用的,隐式等待是告诉WebDriver去等待一定的时间后去查找元素。 默认等待时间是0秒,一旦设置该值,隐式等待是设置该WebDriver的实例的生命周期。
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds,等待10s,没有就报错
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
打开一个新的页面(切换页面)

image.png
driver切换到新的页面:driver.switch_to_window(handle)
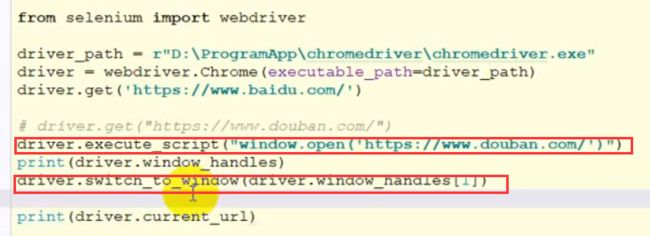
image.png

image.png
设置代理ip

image.png

image.png
WebElement

image.png
拉勾网爬虫
1、方法一:分析接口,但是会被限制,如果太快,加headers参数,cookies,referer。。。
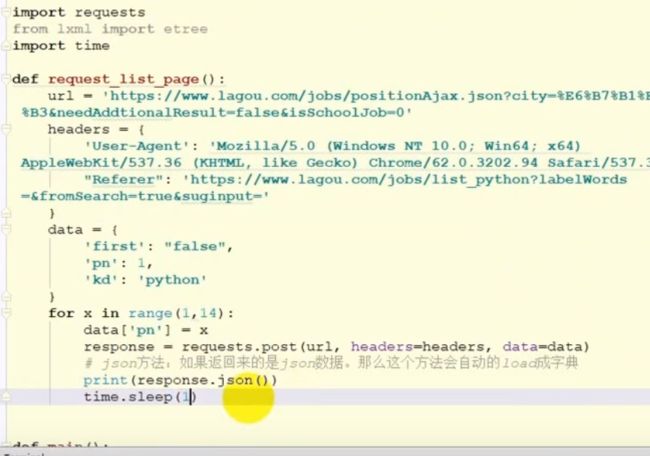
image.png
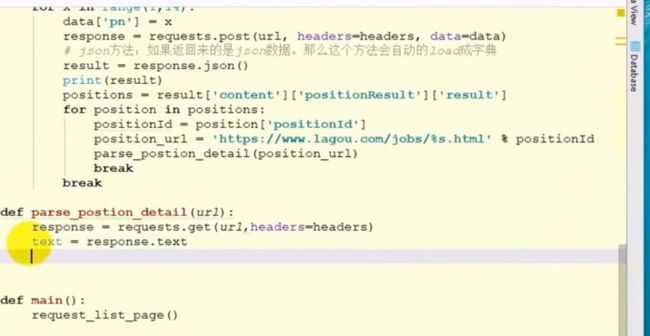
image.png

image.png

image.png
2、方法二:selenium

image.png

image.png

image.png

image.png


image.png

image.png

image.png

image.png

image.png

image.png

image.png
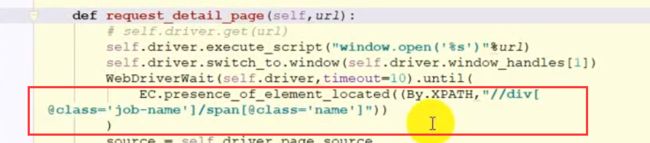
这里不能有text
代码:
from selenium import webdriver
import requests
from lxml import etree
import time
import csv
class Lagou(object):
driver_path = r"C:/Users/ASUS/AppData/Local/Programs/Python/Python36/Scripts/chromedriver.exe"
def __init__(self, *args, **kwargs):
self.driver = webdriver.Chrome(executable_path=Lagou.driver_path)
self.url = 'https://www.lagou.com/jobs/list_java?city=%E6%9D%AD%E5%B7%9E&cl=false&fromSearch=true&labelWords=&suginput='
self.positions = []
self.count = 0
def run(self):
self.driver.get(self.url)
while True:
source = self.driver.page_source
try:
self.parse_list_page(source)
next_btn = self.driver.find_element_by_xpath("//div[@class='pager_container']//span[last()]")
if self.count == 2 or ("pager_next_disabled" in next_btn.get_attribute("class")):
self.export_csv()
break
else:
next_btn.click()
self.count += 1
except:
self.export_csv()
print(source)
time.sleep(1)
def export_csv(self):
headers = {'name','salary','company'}
with open('job.csv','w',encoding='utf-8',newline='') as fp:
writer = csv.DictWriter(fp,headers)
writer.writeheader()
writer.writerows(self.positions)
def parse_list_page(self,source):
html = etree.HTML(source)
urls = html.xpath("//div[@class='position']//a[@class='position_link']/@href")
for url in urls:
self.parse_page(url)
def parse_page(self,url):
self.driver.execute_script("window.open('%s')" %url)
self.driver.switch_to_window(self.driver.window_handles[1])
source = self.driver.page_source
self.parse_detail_page(source)
self.driver.close()
self.driver.switch_to_window(self.driver.window_handles[0])
def parse_detail_page(self,source):
html = etree.HTML(source)
job_name = html.xpath("//div[@class='job-name']//span[@class='name']/text()")[0].strip()
salary = html.xpath("//dd[@class='job_request']//span[@class='salary']/text()")[0].strip()
company = html.xpath("//div[@class='job_company_content']//em[@class='fl-cn']/text()")[0].strip()
position = {
'name' : job_name,
'salary' : salary,
'company' : company
}
self.positions.append(position)
if __name__ == "__main__":
lagou = Lagou()
lagou.run()

image.png
遇到的问题:
爬到第二页,需要登录。。就被迫停止了
解决了,加了一个微信扫码登录,等待10s,然后发现跳转到的页面是首页,所以得搜索,添加输入和点击
from selenium import webdriver
import requests
from lxml import etree
import time
import csv
class Lagou(object):
driver_path = r"C:/Users/ASUS/AppData/Local/Programs/Python/Python36/Scripts/chromedriver.exe"
def __init__(self, *args, **kwargs):
self.driver = webdriver.Chrome(executable_path=Lagou.driver_path)
self.url = 'https://www.lagou.com/'
self.positions = []
self.count = 0
def run(self):
self.driver.get(self.url)
self.login()
self.search()
while True:
source = self.driver.page_source
try:
self.parse_list_page(source)
next_btn = self.driver.find_element_by_xpath("//div[@class='pager_container']//span[last()]")
if self.count == 2 or ("pager_next_disabled" in next_btn.get_attribute("class")):
self.export_csv()
break
else:
next_btn.click()
self.count += 1
except:
self.export_csv()
print(source)
time.sleep(1)
def login(self):
login_btn = self.driver.find_element_by_xpath("//div[@class='passport']//a[@class='login']")
login_btn.click()
weixin_login_btn = self.driver.find_element_by_xpath("//div[@class='third-login-btns']//a[@class='wechat']")
weixin_login_btn.click()
time.sleep(10)
def search(self):
inputTag = self.driver.find_element_by_id("search_input")
inputTag.send_keys("java")
btn = self.driver.find_element_by_id("search_button")
btn.click()
def export_csv(self):
headers = {'name','salary','company'}
with open('job.csv','w',encoding='utf-8',newline='') as fp:
writer = csv.DictWriter(fp,headers)
writer.writeheader()
writer.writerows(self.positions)
def parse_list_page(self,source):
html = etree.HTML(source)
urls = html.xpath("//div[@class='position']//a[@class='position_link']/@href")
for url in urls:
self.parse_page(url)
def parse_page(self,url):
self.driver.execute_script("window.open('%s')" %url)
self.driver.switch_to_window(self.driver.window_handles[1])
source = self.driver.page_source
self.parse_detail_page(source)
self.driver.close()
self.driver.switch_to_window(self.driver.window_handles[0])
def parse_detail_page(self,source):
html = etree.HTML(source)
job_name = html.xpath("//div[@class='job-name']//span[@class='name']/text()")[0].strip()
salary = html.xpath("//dd[@class='job_request']//span[@class='salary']/text()")[0].strip()
company = html.xpath("//div[@class='job_company_content']//em[@class='fl-cn']/text()")[0].strip()
position = {
'name' : job_name,
'salary' : salary,
'company' : company
}
self.positions.append(position)
if __name__ == "__main__":
lagou = Lagou()
lagou.run()
一直报
ERROR:platform_sensor_reader_win.cc(244)] NOT IMPLEMENTED
这个错
查到有这个解决办法:
禁止chromedriver打印日志console信息
添加参数 log-level
options = webdriver.ChromeOptions()
options.add_argument('--log-level=3')
browser = webdriver.Chrome(chrome_options=options)
browser.get(url)
## INFO = 0,
## WARNING = 1,
## LOG_ERROR = 2,
## LOG_FATAL = 3
## default is 0
来自https://blog.csdn.net/myfishmyds/article/details/88885576