Transformer相关的各种预训练模型优点缺点对比总结与资料收集(Transformer/Bert/Albert/RoBerta/ERNIE/XLnet/ELECTRA)
文章目录
-
-
- 1、Transfomer
-
- 基础资料
- 基本结构
-
- single attention和 multiHead attention
-
- attention
- multi-head attention
- self-attention
- encoder和decoder
-
- Add & Norm
- Position-wise Feed-Forward Networks(Relu)
- Weight Tying
- Normalization
- decoder mask
- Optimizer
- 位置编码
- 缺陷及优点
-
- 缺陷
- 优点
- 2、Bert
-
- 基础资料
- 基本结构
-
- Input
- 代码输入参数
- Pre-training和Fine-Tuning
- MLM(mark language model)
- 训练语料及模型大小设置
- 句向量pooling
- SQuAD
- SWAG(The Situations With Adversarial Generations)
- 微调模式
- 缺陷及优点
-
- 缺陷
- 优点
- 3、Albert
-
- 基础资料
- 基本结构
-
- 嵌入向量参数化的因式分解
- 跨层参数共享(参数量减少主要贡献)
- 句间连贯性损失(SOP)
- 运行一定步后删除Dropout
- Segments-Pair
- Masked-ngram-LM
- 模型大小
- 缺陷及优点
-
- 缺陷
- 优点
- 4、RoBerta
-
- 基础资料
- 基本结构
-
- 静态Masking(Bert) vs 动态Masking(RoBerta)
- with NSP(Bert) vs without NSP(RoBerta)
- 更大的mini-batch (实际应用中,我们应该不断扩大mini_batch,直至把显卡内卡打满)
- 更多的数据,更长时间的训练
- 更改Text Encoding
- 超参设置
- 5、ERNIE(1.0)
-
- 基础资料
- 基本结构
-
- 改变mark方法
- 中文的Additional data
-
- 预训练时Dialogue data使用(Query-Response dialogue)
- 缺陷及优点
- 6、XLnet
-
- 基础资料
- 基本结构
-
- 自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型
- 排列语言建模(Permutation Language Modeling)
- Two-Stream Self-Attention(建模上面的排列语言模型)
- 部分预测
- Transformer-XL
- 相对位置编码
- 超参设置
- 缺陷及优点
-
- 优点
- 缺点
- 7、ELECTRA
-
- 基础资料
- 基本结构
-
- RTD
-
1、Transfomer
基础资料
- 论文《Attention Is All You Need》 https://arxiv.org/abs/1706.03762
- github: https://github.com/EternalFeather/Transformer-in-generating-dialogue
- 英文介绍 https://jalammar.github.io/illustrated-transformer/
- 中文介绍 https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc
- attention的mask机制:https://blog.csdn.net/weixin_40901056/article/details/97514718
- attention机制总结: https://www.jianshu.com/p/cf41f3f91d94
基本结构
single attention和 multiHead attention

attention

multi-head attention
- 通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来
- 后面要加一个线性变换(下图的红框)
- 其中head的维度是hiddensize/head的个数,不增加计算复杂度

self-attention
- 取Q,K,V相同,都是下层前馈网络的产出, 计算方法scaled dot-product
- scale(K向量维度的开方8)的目的是:缩放后值差距变小,使梯度更稳定
- mask:将padding值0屏蔽掉,不影响其它词的attention计算,将padding=0的值赋值一个无穷小,这样的话,e的无穷小次方接近于0

encoder和decoder
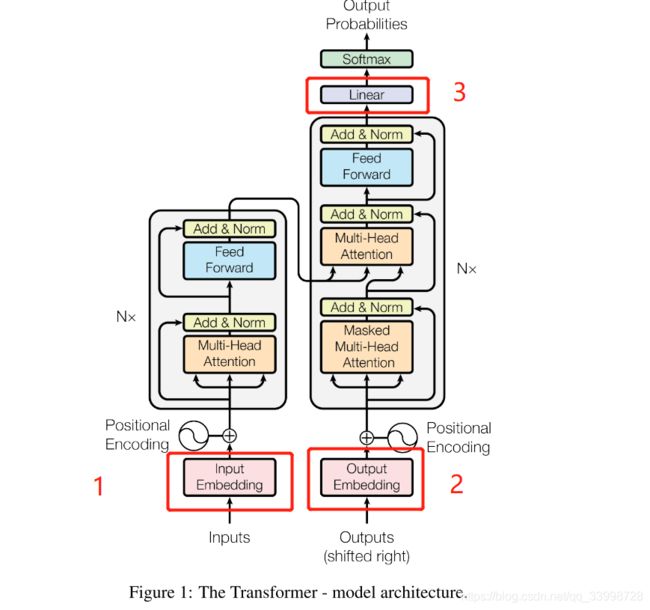
Add & Norm
- Add 残差连接:加入一个常量,深层网络可以防止梯度消失
- Norm :标准化:multi-Head,每个head产出结果的量级或范围不一定一致,需要归一化才能接全连接
Position-wise Feed-Forward Networks(Relu)

- 该全连接是先接一个4*hidden_size的全连接,用relu筛选后,再恢复hidden_size的维度,目的是将每个位置的Attention结果映射到一个更大维度的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复回原始维度。需要说明的是,在抛弃了 LSTM 结构后,FFN 中的 ReLU成为了一个主要的能提供非线性变换的单元
Weight Tying
- 上图Figure1中红色框框的1、2、3,使用同一个参数矩阵(C*H),1、2是将词vocabSize的向量映射成hidden_size的向量,3是将hidden_size的向量映射成vocabSize的向量,这样后面接softmax,预测词汇
- 训练过程中,1当成变量,由encoder训练,2和3当成常量直接使用
Normalization
- Dropout:3个地方使用,1、token embedding + position embedding;2、attention;3、全连接
- Label Smoothing
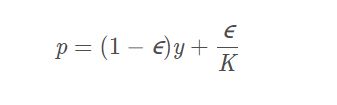
decoder mask
- 训练时,decoder的input要mask掉后面的词汇,因为真实预测时,并看不到后面的值
Optimizer
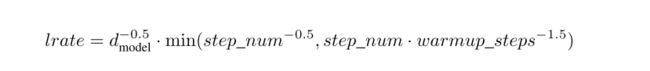
- warmup的好处:
1. 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
2. 有助于保持模型深层的稳定性

位置编码

缺陷及优点
缺陷
- 计算量太大,self.attention的复杂度是n的2次方,解决办法:set transformer的的attention因式分解,先投影到低维空间,由低维空间和自己算attention,然后再投影到高维空间
- 位置信息利用不明显,transformer的postionEmbedding效果不好,而且无法捕获长距离的信息,解决办法:transformer_xl,修改positionEmbedding公式;类似rnn,分段计算attention,把上一段的attention输出作为下一段attention的context
- multiHead,并不是所有的head都有用,可以通过剪枝方式减少head,从而减少参数量
优点
- 每个元素可以像CNN一样和全局的信息进行交互,忽略距离
- 突破了 RNN 模型不能并行计算的限制
- 自注意力可以产生更具可解释性的模型。我们可以从模型中检查注意力分布。各个注意头(attention head)可以学会执行不同的任务
2、Bert
基础资料
- 论文 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 https://arxiv.org/abs/1810.04805
- github:https://github.com/google-research/bert
- BERT相关论文、文章和代码资源汇总:https://zhuanlan.zhihu.com/p/50717786
- Bert代码解读:https://daiwk.github.io/posts/nlp-bert-code-annotated-framework.html
- bert结构介绍:https://www.jianshu.com/p/23050ce9493a
- Bert参数量统计:https://blog.csdn.net/weixin_43922901/article/details/102602557
- Bert测试集描述:https://blog.csdn.net/shuibuzhaodeshiren/article/details/87743286
基本结构
Input

代码输入参数
- input_ids:输入的词汇在词表中的id,padding为0
- input_mask:确定哪些词是padding,padding的位置为0,其它为1,[1,1,1,1,1,0,0,0,0,0]
- segment_ids:确定哪些词汇属于SentenceA,哪些属于SentenceB,padding为0,[0,0,0,0,1,1,1,1,1,0,0,0,0]
- masked_lm_positions:mask词汇的position 索引位置,就是哪几个词被mask
- masked_lm_ids:mask词汇的词表中的id
- masked_lm_weights:mask词汇的权重,默认全是1
- next_sentence_labels:1表示真正的上下句,0表示random获取的
Pre-training和Fine-Tuning

MLM(mark language model)
- 每条训练样本有15%的要被mark,设置最多mark个数,shuffle word,然后遍历word,当被mark的数量满足15%或最多mark数量时,停止
- 当word被选择为mark word时,80%被mark,10%不变(这是为了一定程度上,预训练和微调保持一致),10%被替换任意词汇(这是为了防止过拟合,就是加入噪音)
训练语料及模型大小设置
- 训练语料:Wiki和book corpus,内容比较正经,对于口语化严重的场景下,会有一点影响
- 模型大小:Base:110M(LayerSize=12,HiddenSize=768,MultiHead=12);Large:340M(LayerSize=24,HiddenSize=1024,MultiHead=16)
详细模型大小计算,可参考基础资料里面的《Bert参数量统计》
句向量pooling
当需要选择encoder的output作为sentence的represention时候,我们一般选择[CLS]对应位置的词向量,因为[CLS]本身没有含义,所以它和其它word的attention正好就是sentence的context表示,所以选择它比较合适(其实这也是一种pooling选择,可以像set transformer一样pooling)
SQuAD
SQuAD 是斯坦福大学于2016年推出的数据集,一个阅读理解数据集,给定一篇文章,准备相应问题,需要算法给出问题的答案。
Fine_tuning方法:query作为SentenceA,text作为SentenceB,组成input输入到Bert中,然后在output中通过下面公式计算

S是answer开始符合的编码,通过这种方式找到answer的开始位置和结束位置,训练目标:使得anwer的开始位置和结束位置的log-likelihoods之和最大
SWAG(The Situations With Adversarial Generations)
给出一个陈述句子和4个备选句子, 判断前者与后者中的哪一个最有逻辑的连续性, 相当于阅读理解问题
Sentence A是陈述句子,SentenceB是备选句子,训练参数:一个vector,该条句子的score是这个vector和CLS的产出的点乘
微调模式

缺陷及优点
缺陷
- 微调和预训练不一致,微调数据中没有mark,预训练有15%*80%的mark(xlnet一定程度解决,但也没完全解决,预测时没有mark)
- 模型文件太大,训练时间太长,一方面,这是因为self.attention的训练复杂度时n的2次方(set transformer解决这个问题);另一方面,每轮只有15%的词汇预测,太慢(ELECTRA 通过在encoder后面加了一个识别器,识别所有单词是否为原生的,这样就解决了15%的限制)
- 训练语料不全,albert、RoBerta、ERNIE都在通过丰富语料来提高效果
- mark 单一word导致专有名词、实体等,不能分开的词组,学不到和其它实体的关系(百度的ERNIE通过词组识别,mark词组)(albert 使用mark的n-gram方法)
- 静态mark,一个word一旦被选定为mark,在所有的epoch中都会被选中,这不合理,RoBerta通过复制多份数据,每份数据的mark都不一样
- NEP:只能学习两个句子的联系,RoBerta 加入连续多个句子,学习多个句子之间的联系;albert使用SOP判断两个句子是否被交换过顺序
- Bert产出的句向量,在计算句子相似度时,不合适直接进行点积或余弦相似度计算,因为区别度不高,可以使用neural tensor layer进行训练,公式如下:
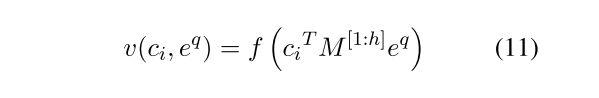
优点
- 借用transformer的self.attention优势,真正实现双向文本表示(不像elmo那样,两个单向相加还是单向的,下图所示)
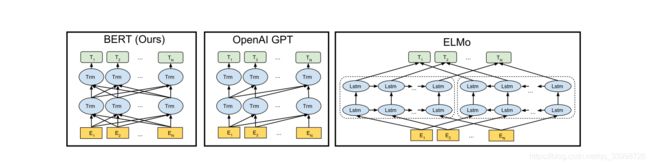
- fine_tuning效果好于Feature-based(ELMo,结合下游任务产出encoder的向量表示),摆脱下游任务,使用MLM和NSP,学习词级别和句级别的表示,然后再结合下游任务微调,效果达到很好
3、Albert
基础资料
- 论文资料 《ALITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》 https://openreview.net/pdf?id=H1eA7AEtvS
- GitHub 英文:https://github.com/google-research/albert;中文:https://github.com/brightmart/albert_zh
- albert简介:https://blog.csdn.net/jiaowoshouzi/article/details/102320781
- 解读ALBERT:https://blog.csdn.net/weixin_37947156/article/details/101529943
基本结构
嵌入向量参数化的因式分解
对于 ALBERT 而言,研究者对词嵌入参数进行了因式分解,将它们分解为两个小矩阵。研究者不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显
可以参考《用深度矩阵分解给词向量矩阵瘦身》https://zhuanlan.zhihu.com/p/85339902,简化词向量参数的数量级

跨层参数共享(参数量减少主要贡献)
对于 ALBERT,研究者提出了另一种跨层参数共享机制来进一步提升参数效率。其实目前有很多方式来共享参数,例如只贡献前馈网络不同层之间的参数,或者只贡献注意力机制的参数,而 ALBERT 采用的是贡献所有层的所有参数,研究者发现 ALBERT 从一层到另一层的转换要比 BERT 平滑得多,结果表明,权重共享有效地提升了神经网络参数的鲁棒性。
句间连贯性损失(SOP)
谷歌自己把它换成了 SOP。这个在百度 ERNIE 2.0 里也有,叫 Sentence Reordering Task,而且 SRT 比 SOP 更强,因为需要预测更多种句子片段顺序排列。ERNIE 2.0 中还有一些别的东西可挖,比如大小写预测
Captialization Prediction Task、句子距离 Sentence Distance Task。
- NOP:下一句预测, 正样本=上下相邻的2个句子,负样本=随机2个句子
- SOP:句子顺序预测,正样本=正常顺序的2个相邻句子,负样本=调换顺序的2个相邻句子
- NOP任务过于简单,只要模型发现两个句子的主题不一样就行了,所以SOP预测任务能够让模型学习到更多的信息
句子样本选取的考虑如下:
- BERT使用的NSP损失,是预测两个片段在原文本中是否连续出现的二分类损失。目标是为了提高如NLI等下游任务的性能,但是最近的研究都表示 NSP 的作用不可靠,都选择了不使用NSP。
- 作者推测,NSP效果不佳的原因是其难度较小。将主题预测和连贯性预测结合在了一起,但主题预测比连贯性预测简单得多,并且它与LM损失学到的内容是有重合的。
- SOP的正例选取方式与BERT一致(来自同一文档的两个连续段),而负例不同于BERT中的sample,同样是来自同一文档的两个连续段,但交换两段的顺序,从而避免了主题预测,只关注建模句子之间的连贯性。
运行一定步后删除Dropout
删除的原因(bert的dropout应用可以参考上文bert)
- 模型的内部任务(MLM,SOP等等)都没有过拟合
- dropout是为了降低过拟合而增加的机制,所以对于bert而言是弊大于利的机制
Segments-Pair
BERT为了加速训练,前90%的steps使用了128个token的短句子,最后10%才使用512个token的长句子训练位置向量。
ALBERT貌似90%的情况下使用512的segment,从数据上看,更长的数据提供更多的上下文信息,可能显著提升模型的能力
Masked-ngram-LM
BERT的MLM目标是随机MASK15%的词来预测,ALBERT预测的是N-gram片段,包含更多的语义信息,每个片段长度n(最大为3),根据概率公式计算得到。比如1-gram、2-gram、3-gram的的概率分别为6/11、3/11、2/11.越长概率越小:

模型大小
对Embedding因式分解
下图是E选择不同值的一个实验结果,尴尬的是,在不采用参数共享优化方案时E设置为768效果反而好一些,在采用了参数共享优化方案时E取128效果更好一些。

跨层的参数共享
下图是BERT与ALBERT的一个对比,以base为例,BERT的参数是108M,而ALBERT仅有12M,但是效果的确相比BERT降低了两个点。由于其速度快的原因,我们再以BERT xlarge为参照标准其参数是1280M,假设其训练速度是1,ALBERT的xxlarge版本的训练速度是其1.2倍,并且参数也才223M,评判标准的平均值也达到了最高的88.7



缺陷及优点
缺陷
在初闻ALBERT时,以为其减少了总的运算量,但实际上是通过参数共享的方式降低了内存,预测阶段还是需要和BERT一样的时间,如果采用了xxlarge版本的ALBERT,那实际上预测速度会更慢。
优点
ALBERT解决的是训练时候的速度提升,如果要真的做到总体运算量的减少,的确是一个复杂且艰巨的任务,毕竟鱼与熊掌不可兼得。不过话说回来,ALBERT也更加适合采用feature base或者模型蒸馏等方式来提升最终效果。
4、RoBerta
基础资料
- 论文 《RoBERTa: A Robustly Optimized BERT Pretraining Approach》https://arxiv.org/abs/1907.11692
- Github:https://github.com/pytorch/fairseq
- 改进版的RoBERTa到底改进了什么?https://www.jianshu.com/p/eddf04ba8545
- 文献阅读笔记 https://blog.csdn.net/ljp1919/article/details/100666563
基本结构
静态Masking(Bert) vs 动态Masking(RoBerta)
静态Masking: 原来Bert对每一个序列随机选择15%的Tokens替换成[MASK],为了消除与下游任务的不匹配,还对这15%的Tokens进行(1)80%的时间替换成[MASK];(2)10%的时间不变;(3)10%的时间替换成其他词。但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。
动态Masking: 而RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。

with NSP(Bert) vs without NSP(RoBerta)
with NSP(Bert):原本的Bert为了捕捉句子之间的关系,使用了NSP任务进行预训练,就是输入一对句子A和B,判断这两个句子是否是连续的。在训练的数据中,50%的B是A的下一个句子,50%的B是随机抽取的。
without NSP(RoBerta):而RoBERTa去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES),而原来的Bert每次只输入两个句子。实验表明在MNLI这种推断句子关系的任务上RoBERTa也能有更好性能。
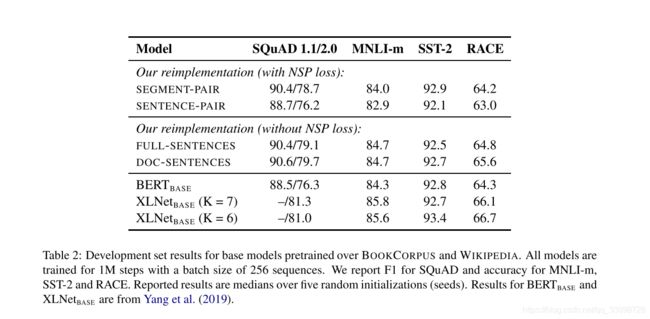
更大的mini-batch (实际应用中,我们应该不断扩大mini_batch,直至把显卡内卡打满)
原本的BERTbase 的batch size是256,训练1M个steps。RoBERTa的batch size为8k。为什么要用更大的batch size呢?(除了因为他们有钱玩得起外)作者借鉴了在机器翻译中,用更大的batch size配合更大学习率能提升模型优化速率和模型性能的现象,并且也用实验证明了确实Bert还能用更大的batch size。
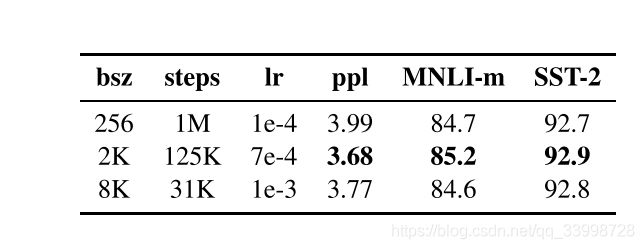
更多的数据,更长时间的训练
借鉴XLNet用了比Bert多10倍的数据,RoBERTa也用了更多的数据。性能确实再次彪升。当然,也需要配合更长时间的训练。

Additional data:CC-NEWS;OPENWEBTEXT;STORIES
更改Text Encoding
字节对编码(BPE)(Sennrich et al.,2016)是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。
当采用 bytes-level 的 BPE 之后,词表大小从3万(原始 BERT 的 char-level )增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。
总结下两种BPE实现方式:
- 基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到
- 基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
超参设置


5、ERNIE(1.0)
基础资料
- 论文 《Enhanced Representation from kNowledge IntEgration》https://www.aclweb.org/anthology/P19-1139.pdf
- Github:https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
- ERNIE预览:百度 知识增强语义表示模型ERNIE:https://www.jianshu.com/p/fb66f444bb8c
- ERNIE - 清华 详解 https://zhuanlan.zhihu.com/p/103208601
基本结构
改变mark方法

实体主要是person name, place name, organization name这几类
考虑到有可能存在错误的token-entity alignmnent,具体操作:
- 5%的时间,对于一个token-entity alignmnent,随机替换entity,让模型预测正确的entity
- 15%的时间,随机mask掉 token-entity alignmnents,让模型去正确预测token-entity alignment。
- 剩下的时间,token-entity alignmnents不变,让模型将知识进行融合。
中文的Additional data
Chinese Wikepedia, Baidu Baike, Baidu news and Baidu Tieba
预训练时Dialogue data使用(Query-Response dialogue)

负样本选取:我们通过用随机选择的句子替换查询或响应来生成伪造的样本,该模型旨在判断多轮对话是真实的还是假的
缺陷及优点
优点:善于捕获词语之间相互关系,在完型填空等类型的任务中的表现良好。
6、XLnet
基础资料
- 论文 《XLNet: Generalized Autoregressive Pretraining for Language Understanding》https://arxiv.org/pdf/1906.08237.pdf
- Github https://github.com/zihangdai/xlnet
- xlnet和bert对比:https://zhuanlan.zhihu.com/p/70257427
- xlnet原理解读:https://blog.csdn.net/weixin_37947156/article/details/93035607
- transformer_xl 《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
- Transformer-XL介绍 https://zhuanlan.zhihu.com/p/84159401
基本结构
自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型
自回归(Autoregressive, AR)(ELMo和GPT):自回归是时间序列分析或者信号处理领域喜欢用的一个术语,我们这里理解成语言模型就好了:一个句子的生成过程如下:首先根据概率分布生成第一个词,然后根据第一个词生成第二个词,然后根据前两个词生成第三个词,……,直到生成整个句子。

自编码(autoencoding)模型(Bert):自编码器是一种无监督学习输入的特征的方法:我们用一个神经网络把输入(输入通常还会增加一些噪声)变成一个低维的特征,这就是编码部分,然后再用一个Decoder尝试把特征恢复成原始的信号。
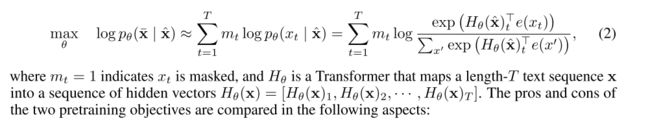
自回归的问题:1、独立假设:被mask的word之间是相互独立的;2、预训练与微调不一致:BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tuning中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
自编码的问题:语言模型只能参考一个方向的上下文,而BERT可以参考双向整个句子的上下文,因此这一点BERT更好一些。ELMo和GPT最大的问题就是传统的语言模型是单向的——我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。
排列语言建模(Permutation Language Modeling)

给定长度为T的序列xx,总共有T!种排列方法,也就对应T!种链式分解方法。比如假设x=x1x2x3,那么总共用3!=6种分解方法:

注意p(x2|x1x3)指的是第一个词是x1并且第三个词是x3的条件下第二个词是x2的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是x1并且第二个词是x3的条件下第三个词是x2,那么就不对了。
因此我们可以遍历T!种路径,然后学习语言模型的参数,但是这个计算量非常大(10!=3628800,10个词的句子就有这么多种组合)。因此实际我们只能随机的采样T!里的部分排列。(论文没提到如何随机)
Two-Stream Self-Attention(建模上面的排列语言模型)
- query流:为了预测x位置的词汇,只能使用x位置信息而不能使用x以及之后信息,这是显然的:你预测一个词当然不能知道要预测的是什么词。同时,也是为了防止上层的attention用到下层x位置的mark词汇信息。
- content流:为了预测x位置之后的词,必须编码x位置的信息(语义)


我们首先把查询隐状态g初始化为一个变量w(使用embedding*g矩阵生成w),把内容隐状态h初始化为词的Embedding 。
content流分解如下:fine_tuning时也只有content流


query流分解如下:预训练时计算损失函数时也只用到了query流的向量,去和embedding做点乘softmaxt计算log_likelihood
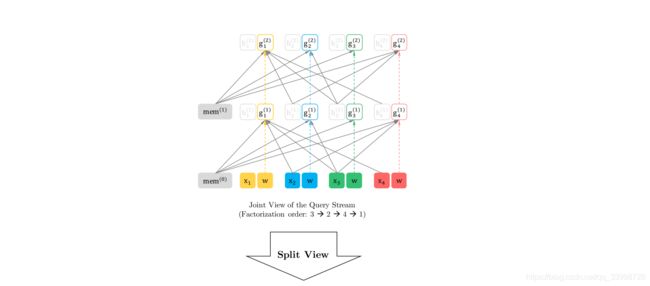

部分预测
为了减少计算量,故对于一个因式分解样本,只预测后部分的词汇,那么训练目标就是后部分词汇的log-likelihood最大,所以同时前部分的query就不计算了,只计算content流,减少计算量

Transformer-XL

为解决self.attention的n方复杂度,以及超长文本获取信息冗余问题,限制输入文本的长度,一般的transformer在处理超长文本时,训练时segment分开,一个一个训练,预测时,segment步长为1进行移动,效率太低,故transformer_xl提出了Multiple Segments模型。

这张图上有一个点需要注意,在当前segment中,第n层的每个隐向量的计算,都是利用下一层中包括当前位置在内的,连续前L个长度的隐向量,这是在上面的公式组中没有体现出来的,也是文中没有明说的。每一个位置的隐向量,除了自己的位置,都跟下一层中前(L-1)个位置的token存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1),如下图中Evaluation phase所示,所以最长的依赖关系长度是N(L-1),N是模型中layer的数量。N通常要比L小很多,比如在BERT中,N=12或者24,L=512,依赖关系长度可以近似为O(N*L)
相对位置编码
在传统的Transformer中,输入序列中的位置信息是怎么表示的?通过POS函数生成,它是位置i和维度d的函数,也就是不同输入segment在相同绝对位置中的位置表示是相同的。在传统的Transformer中,每个segment之间的表示是没有关联的,这当然就没有问题。但是在TransformerXL中,因为引入了前一时刻segment的信息,就需要对不同时刻,同样是第i个的词进行区分。


对比来看,主要有三点变化:
-
在b和d这两项中,将所有绝对位置向量Ui,Uj都转为相对位置向量Ri−j,与Transformer一样,这是一个固定的编码向量,不需要学习。
-
在c这一项中,将查询的U_iT*W_qT向量转为一个需要学习的参数向量u,因为在考虑相对位置的时候,不需要查询绝对位置i,因此对于任意的i,都可以采用同样的向量。同理,在d这一项中,也将查询的U_iT*W_qT向量转为另一个需要学习的参数向量v。
-
将K的权重变换矩阵Wk转为Wk_E 和Wk_R,分别作为content-based key vectors和location-based key vectors。
总的来说,Relative Positional Encodings就是在计算attention分数时,用相对位置R_i_j编码来代替原来的绝对位置编码Ui和Uj。并且学习了相对位置v和u用来调整不同距离和不同嵌入的得分。
TransformerXL对Transformer进行了一些调整,试图解决一些问题。按照论文的描述,TransformerXL学习的依赖关系比RNN长80%,比传统Transformer长450%,在短序列和长序列上都获得了更好的性能,并且在评估阶段比传统Transformer快1800+倍
超参设置


缺陷及优点
优点
1、解决了mark词之间的相互依赖关系;
2、通过transform_xl的加入,可以捕获更长距离的信息;
缺点
由于预训练的每一轮都是掩码矩阵的行列排列,而fine_tuning阶段是普通的transformer
7、ELECTRA
基础资料
- 论文 《ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators》 https://arxiv.org/abs/2003.10555
- Github https://github.com/google-research/electra
- 中文模型下载及使用方法:https://react.ctolib.com/ymcui-chinese-electra.html#%E6%A8%A1%E5%9E%8B%E4%B8%8B%E8%BD%BD
基本结构
当下流行的MLM(Masked Language Modeling)方法会大大增加计算开销,原因:模型只学到每个example中15%的tokens信息,而且有些token可能会很简单。
因此,我们创新性地提出了RTD (Replaced Token Detection)这样的新的预训练任务(可以判断每个example的所有词汇是不是被替换过,加快训练速度)。
RTD

-
损失函数

通常采用两个Bert实现上面的结构,并且通过两个Bert的参数共享减少参数量 -
Weight Sharing:Generator和Discriminator使用参数相同(attention参数和embedding参数)的Bert产出(用Bert的目的就是为了和Bert效果对比);实验结果显示只共享embedding时效果最好
-
Smaller Generators:可以从下图中看到,生成器的大小在判别器的1/4到1/2之间效果是最好的。作者认为原因是过强的生成器会增大判别器的难度

-
Training Algorithms:
实际上除了MLM loss,作者也尝试了另外两种训练策略:- Adversarial Contrastive Estimation:ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM loss换成了最大化判别器在被替换token上的RTD loss。但还有一个问题,就是新的生成器loss无法用梯度下降更新生成器,于是作者用强化学习Policy Gradient的思想,将被替换token的交叉熵作为生成器的reward,然后进行梯度下降。强化方法优化下来生成器在MLM任务上可以达到54%的准确率,而之前MLE优化下可以达到65%。
- Two-stage training:即先训练生成器,然后freeze掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。
-
当采用Bert作为generator且参数全共享时,训练时间以及GLUE对比
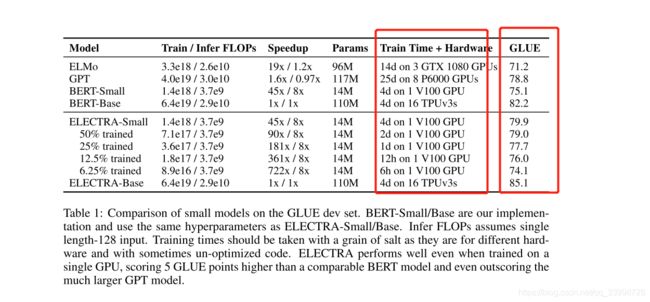
微调阶段,ELECTRA与各个模型在GLUE各个任务上的效果对比,ELECTRA-small++只有BERT-Base大小的大概10分之一,但效果类似

-
超参设置


NLP预训练模型综述 :https://www.sohu.com/a/387592630_500659