原创 | 从ULMFiT、Transformer、BERT等经典模型看NLP 发展趋势

自然语言处理(Natural Language Process,简称NLP)是计算机科学、信息工程以及人工智能的子领域,专注于人机语言交互,探讨如何处理和运用自然语言。自然语言处理的研究,最早可以说开始于图灵测试,经历了以规则为基础的研究方法,流行于现在基于统计学的模型和方法,从早期的传统机器学习方法,基于高维稀疏特征的训练方式,到现在主流的深度学习方法,使用基于神经网络的低维稠密向量特征训练模型。
总结过去二十年里,无数先辈辛劳付出带来的璀璨成果,以下3个代表性工作应该被列为里程碑事件:
1)2003年Bengio提出神经网络语言模型NNLM,从此统一了NLP的特征形式——Embedding;
2)2013年Mikolov提出词向量Word2vec,延续NNLM又引入了大规模预训练(Pretrain)的思路;
3)2017年Vaswani提出Transformer模型,实现用一个模型处理多种NLP任务。2018年底,基于Transformer架构,开始出现一大批预训练语言模型,刷新众多NLP任务。
当前,随着深度学习以及相关技术的发展,NLP领域的研究取得一个又一个突破,研究者设计各种模型和方法,来解决NLP的各类问题。如今,NLP应用已经变得无处不在。我们似乎总是不经意间发现一些网站和应用程序,以这样的或那样的形式利用了自然语言处理技术。实际上,在近年来的自然语言处理方向的顶会上,深度学习也往往占据了大量的篇幅,自然语言处理方向成为模型与计算能力的较量。为此,本文介绍了自2018年起一些顶级的预训练模型,读者们可以用它们来开始你的自然语言处理之旅,并复制该领域的最新研究成果。
一、NLP模型盘点
1、ULMFiT
GitHub 项目地址:
https://github.com/fastai/fastai/tree/master/courses/dl2/imdb_scripts
ULMFiT的预训练模型论文:
https://www.paperswithcode.com/paper/universal-language-model-fine-tuning-for-text
其他研究论文
https://arxiv.org/abs/1801.06146

ULMFiT 由 fast.ai 的 Jeremy Howard 和 DeepMind 的 Sebastian Ruder 提出并设计。ULMFiT 是 Universal Language Model Fine-Tuning(通用语言模型微调)的缩写。其实根据它的名字,基本就可以知道它的操作流程,具体见上图:一共是分为3个阶段,首先是语言模型的预训练、然后是语言模型的finetune、最后是分类任务的finetune。
ULMFiT 使用新的自然语言生成技术实现了最先进的结果。该方法包括在 Wikitext 103 数据集上训练的预处理语言模型进行微调,使其不会忘记以前所学的内容,从而将其微调为一个新的数据集。在文本分类任务方面,ULMFiT 的性能优于许多最先进的技术。使用这种预训练的语言模型,让我们能够在使用更少的标记数据的情况下训练分类器。尽管网络上未标记的数据几乎是无穷无尽的,但标记数据的成本很高,而且非常耗时。
2、Transformer
GitHub 项目地址:
https://github.com/tensorflow/models/tree/master/official/transformer
Transformer预训练模型论文《Attention IsAll You Need》
https://www.paperswithcode.com/paper/attention-is-all-you-need
其他研究论文
https://arxiv.org/abs/1706.03762
2017年之前,语言模型都是通过RNN、ISTM来建模,这样虽然可以学习上下文之间的关系,但是无法并行化,给模型的训练和推理带来了困难,因此Google研究者提出了一种完全基于attention来对语言建模的模型,叫做Transformer。Transformer摆脱了NLP任务对于RNN、ISTM的依赖,使用了self-attention的方式对上下文进行建模,提高了训练和推理的速度,Transformer也是后续更强大的NLP预训练模型的基础。
实践发现,当模型变得越来越大,样本数越来越多的时候,self-attention无论是并行化带来的训练提速,还是在长距离上的建模,都是要比传统的RNN、ISTM好很多。Transformer现在已经各种具有代表性的NLP预训练模型的基础,Bert系列使用了Transformer的encoder,GPT系列使用了Transformer的decoder。在推荐领域,Transformer的multi-head attention也应用得很广泛。
3、BERT
GitHub 项目地址:
https://github.com/google-research/bert
BERT预训练模型论文
https://www.paperswithcode.com/paper/bert-pre-training-of-deep-bidirectional#code
其他研究论文
https://arxiv.org/pdf/1810.04805.pdf
BERT,是 Bidirectional Encoder Representations
(双向编码器表示)的缩写,它从单词的两边(左边和右边)来考虑上下文。在BERT之前,将预训练的embedding应用到下游任务的方式大致可以分为2种,一种是feature-based,例如ELMo这种将经过预训练的embedding作为特征引入到下游任务的网络中;一种是fine-tuning,例如GPT这种将下游任务接到预训练模型上,然后一起训练。然而这2种方式都会面临同一个问题,即无法直接学习到上下文信息,比如ELMo只是分别学习上文和下文信息,然后concat起来表示上下文信息;而GPT只能学习上文信息。因此,作者提出一种基于Transformer encoder的预训练模型,可以直接学习到上下文信息,叫做BERT。BERT使用了12个transformer encoder block,在13G的数据上进行了预训练,可谓是NLP领域大力出奇迹的代表。
BERT 是第一个无监督、深度双向的自然语言处理模型预训练系统。它只使用纯文本语料库进行训练。在发布的时候,BERT 在 11 个自然语言处理任务上取得了最先进的结果。这真是相当了不起的成就。你可以在短短几个小时内(在单个 GPU 上)使用 BERT 训练自己的自然语言处理模型(例如问答系统)。总之,BERT真正地影响了学术界和工业界。无论是GLUE,还是SQUAD,现在榜单上的高分方法都是在BERT的基础之上进行了改进。不过BERT也并不是万能的,BERT的框架决定了这个模型适合解决自然语言理解的问题,因为没有解码的过程,所以BERT不适合解决自然语言生成的问题。因此如何将BERT改造成适用于解决机器翻译,文本摘要问题的框架,是今后值得研究的一个点。
4、Transformer-XL
GitHub 项目地址:
https://github.com/kimiyoung/transformer-xl
研究论文 :
https://arxiv.org/abs/1901.02860
Transformer-XL由 Google AI 团队开发,是对Transformer的改进或变种,主要是解决长序列的问题,其中XL表示extra long,可以帮助机器理解超出固定长度限制的上下文。Transformer-XL 比普通的 Transformer 要快上 1800 倍。在最近流行的XLNet中就是使用Transformer-XL作为基础模块。
5、XLNet
GitHub 项目地址:https://github.com/topics/xlnet
2018年底谷歌推出了BERT,该模型一经问世就占据了NLP界的统治地位,如今CMU和Google brain联手推出了BERT的改进版XLNet。在这之前也有很多公司对BERT进行了优化,包括百度、清华的知识图谱融合,微软在预训练阶段的多任务学习等等,但是这些优化并没有把BERT致命缺点进行改进。XLNet作为BERT的升级模型,主要在以下三个方面进行了优化:
采用AR模型替代AE模型,解决mask带来的负面影响
双流注意力机制
引入transformer-xl
6、GPT-2
GitHub 项目地址:
https://github.com/openai/gpt-2
研究论文:
https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
GPT-2 是一种基于transformer 的大型语言模型,具有 15 亿个参数,在 800 万网页数据集上进行训练。它是论文《语言模型是无人监督的多任务学习者》(Language Models are Unsupervised Multitask Learners)的代码实现。
GPT-2 经过训练后,可以预测 40GB 互联网文本数据的下一个出现的单词。该模型在 800 万个 Web 页面的数据集进行训练。为了供研究人员和工程师测试,开发人员发布了一个小得多的 GPT-2 版本。原始模型有 15 亿个参数,而开源的示例模型仅有 1.17 亿个。
7、MPNet
代码和模型链接:
https://github.com/microsoft/MPNet
论文地址:
https://arxiv.org/pdf/2004.09297.pdf
近年来,预训练语言模型无疑成为了自然语言处理的研究热点。这些模型通过设计有效的预训练目标,在大规模语料上学习更好的语言表征来帮助自然语言的理解和生成。其中,BERT 采用的掩码语言模型 MLM 和 XLNet 采用的排列语言模型 PLM 是两种比较成功的预训练目标。然而,这两种训练目标各有优缺,具有较大的提升空间。为此,结合BERT、XLNet的思路,南京大学和微软在2020年共同提出了新的预训练语言模型MPNet:Masked and Permuted Pre-training for Language Understanding。它在 PLM 和 MLM 的基础上扬长避短,在自然语言理解任务 GLUE 和 SQuAD 中,超越 BERT、XLNet 和 RoBERTa 等预训练模型,取得了更好的性能。
8、ALBert
论文地址:
https://arxiv.org/pdf/1909.11942.pdf
尽管GPT-2.0,XLNET,RoBERTa等预训练模型确实都基于BERT了做了一些改进,在模型结构、训练模式等方面都有一些创新,但是大部分的预训练模型也有一个共通的“特点”,即模型相对“笨重”,预训练成本高。ALBERT的作者就是基于这样的背景,提出ALBERT这个模型的。其试图解决大部分预训练模型训练成本高,参数量巨大的问题。ALBERT为了减少模型参数主要有以下几点:
1.词嵌入参数因式分解;
2.隐藏层间参数共享
为了提升模型性能,ALBERT提出了一种新的训练任务:句子间顺序预测。
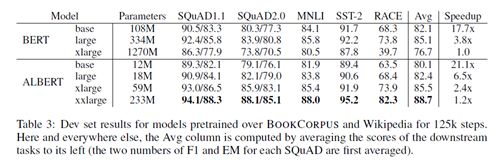
Albert效果
从结果看,相比于BERT,ALBERT能够在不损失模型性能的情况下,显著的减少参数量。此外,ALBERT还有一个albert_tiny模型,其隐藏层仅有4层,模型参数量约为1.8M,非常的轻便。相对于BERT,其训练和推理预测速度提升约10倍,但精度基本保留,语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。对于一些相对比较简单一些或实时性要求高的任务,如语义相似度计算、分类任务等,ALBERT很适合。
9、ELECTRA
GitHub地址:
https://github.com/google-research/electra
论文地址:
https://openreview.net/pdf?id=r1xMH1BtvB
ELECTRA来自谷歌AI,不仅拥有BERT的优势,效率还比它高。它是一种新预训练方法,叫做replaced token detection (RTD)。它能够高效地学习如何将收集来的句子进行准确分词,也就是我们通常说的token-replacement。在效率上,只需要RoBERTa和XLNet四分之一的计算量,就能在GLUE上达到它们的性能。并且在SQuAD上取得了性能新突破。这就意味着“小规模,也有大作用”,在单个GPU上训练只需要4天的时间,精度还要比OpenAI的GPT模型要高。目前,ELECTRA已经作为TensorFlow的开源模型发布,包含了许多易于使用的预训练语言表示模型。
10、ELMo
GitHub 项目地址:
https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md
研究论文
https://arxiv.org/pdf/1802.05365.pdf
ELMo(是 Embedding fromLanguage Models 的缩写)是一种用向量和嵌入表示单词的新方法,在构建自然语言处理模的上下文非常有用。2018年3月份,ELMo出世。该paper是NAACL18 Best Paper。在之前2013年的word2vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时,将一句话或一段话输入模型,模型会根据上线文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如apple,可以根据前后文语境理解为公司或水果。
二、NLP发展趋势
从目前来看,大规模语料预训练+finetune的方式,应该会是NLP接下去几年的主流。各种基于语言模型的改进也是层出不穷。虽然玩法种类各异,我们还是可以看出一些具有突破性的方向。
1、巨无霸系列:T5、GPT3、MegatronLM
前期BERT到RoBERTa,GPT到GPT2效果的提升,已经证明更多数据可以跑出更强大更通用的预训练模型。去年底到今年,英伟达、谷歌、Open-AI相继放出巨无霸模型MegatronLM(83亿参数)、T5(110亿)、GPT3(1500亿),不断刷榜令人咋舌的同时也彰显了巨头们的实力。相信未来,巨无霸模型依然会成为大公司的研究目标之一,却让普通科研人员可望不可及。
2、小而美系列:DistillBERT、TinyBERT、FastBERT
没有前排巨头们的经济实力,普通公司和科研机构沿着相反赛道-模型轻量化下足了功夫。如何在尽可能少的参数量下,取得和大模型接近的效果,同时训练/预测速度翻倍,是很实际很有价值的课题。这其中,有代表性的工作如华为诺亚方舟实验室发布的TinyBERT、北大的FastBERT都取得了瞩目的效果。例如FastBERT在BERT的每一层都接入一个分类器,通过样本自适应机制自动调整每个样本的计算量(容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程)。
3、潜力股系列:few shotlearning
在实际业务场景中,对于中小AI企业往往容易出现数据量不足的问题。这种情况下,迁移学习、小样本学习可能会非常有帮助。受到人类具有快速从少量(单)样本中学习能力的启发,让模型在少量样本中学习获得有力的泛化能力,成为近年的研究热点之一。
总结近些年自然语言处理发展的过程,我们会发现有如下趋势变化:
第一,神经网络深入到NLP各个领域之中,由此带来的崭新的神经NLP的建模、学习和推理方法,在我刚才所介绍的典型NLP任务中都取得了很好的进展;
第二,以BERT为代表的一系列预训练模型得到了广泛应用,体现了大规模语言数据所蕴含的普遍语言规律和知识与具体应用场景巧妙结合的潜力;
第三,低资源的NLP任务获得了广泛重视并得到了很好的发展。
除了以上技术上的显著进步,中国的NLP的进展也引起了世界瞩目。从顶会(ACL、EMNLP、COLING 等)论文发表来看,过去五年来连续居于世界第二名;仅次于美国,远远高于其他国家;以中文为中心的机器翻译,现在在世界上处于领先水平;在聊天和对话方面,中国也位居世界前列。总之,从中国到亚洲到世界,NLP领域的整个趋势是不同的层次、不同水平都在进行努力。正如微软亚洲研究院副院长周明所说,NLP进入了黄金十年。随着未来国民经济发展和人工智能对NLP带来的庞大的需求,大规模的各类数据可供模型训练,以神经网络NLP为代表的各种新方法将一步步提升建模水平,各种评测和各种开放平台推动NLP研究和推广的能力,日益繁荣的AI和NLP领域促进专门人才的培养等等,相信NLP领域将会迎来更多里程碑实践,越来越多的智能应用将随之落地。
编辑:文婧
校对:汪雨晴
