【爬虫】B站视频弹幕爬取
一、 找和弹幕相关的API
B站的API有很多,网上也有很多人挖出来了
代码已上传:B站弹幕数量可视化
通过查找B站的API,找到B站弹幕API
'https://api.bilibili.com/x/v2/dm/history?type=1&oid='+cid+'&date='+time
其中cid是视频id,time是弹幕时间
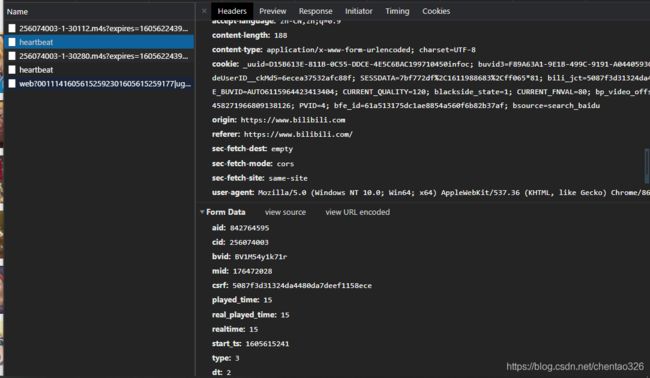
在heartbeat中找到cid
time可以在视频上方获取![]()
同样存在API可以获取到这类信息
二、通过request获取内容
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36",
'Cookie': "_uuid=D15B613E-811B-0C55-DDCE-4E5C6BAC199710450infoc; buvid3=F89A63A1-9E1B-499C-9191-A0440593CD4D138366infoc; sid=916ze85v; DedeUserID=176472028; DedeUserID__ckMd5=6ecea37532afc88f; SESSDATA=7bf772df%2C1611988683%2Cff065*81; bili_jct=5087f3d31324da4480da7deef1158ece; rpdid=|(u)~mum)l)m0J'ulmYRJY~k~; LIVE_BUVID=AUTO6115964423413404; CURRENT_QUALITY=120; blackside_state=1; CURRENT_FNVAL=80; bp_video_offset_176472028=454934553883672194; bp_t_offset_176472028=457902131473234478; _dfcaptcha=e61555d961b3fc689d6828441ae3f249; PVID=2"
}
def getDanmuKu(url):
danmu = requests.get(url, headers=headers)
# 解码弹幕内容为utf-8
danmu = danmu.content.decode('utf-8')
# 用BeatifulSoup提取弹幕信息
danmu = BeautifulSoup(danmu)
danmus = danmu.findAll('d')
# 将弹幕信息和内容分别用两个列表保存
danmu_info = []
danmu_text = []
for iter in danmus:
danmu_info.append(iter['p'].split(','))
danmu_text.append(iter.text)
return danmu_info,danmu_text
(可以再优化的,等日后有时间)
headers={}记得修改
三、时间列表
def create_assist_date(datestart = None,dateend = None):
if datestart is None:
datestart = '2016-01-01'
if dateend is None:
dateend = datetime.datetime.now().strftime('%Y-%m-%d')
datestart = datetime.datetime.strptime(datestart, '%Y-%m-%d')
dateend = datetime.datetime.strptime(dateend, '%Y-%m-%d')
date_list = []
date_list.append(datestart.strftime('%Y-%m-%d'))
while datestart < dateend:
# 日期叠加一天
datestart += datetime.timedelta(days=+1)
# 日期转字符串存入列表
date_list.append(datestart.strftime('%Y-%m-%d'))
return date_list
可以生成一个从datestart开始到dateend结束的列表
没指定时默认从’2016-01-01’开始到现在结束
四、储存
用两个文件储存
def saveInCsv(all_info, all_text, date):
# 将弹幕文件保存在csv文件中
f=open('file\danmuinfo.csv','w', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(["时间", "弹幕模式", "字号大小", "颜色", "Unix格式时间戳", "弹幕种类", "发送者ID", "rowID"])
for single_info in all_info:
single_info = str(single_info).split(',')
csv_writer.writerow(single_info)
f.close()
f = open('file\danmutext.csv', 'w', encoding='utf-8')
csv_writer=csv.writer(f)
for single_text in all_text:
csv_writer.writerow(single_text)
f.close()
这段代码还可以修改
不一定要储存到文件中
这边的作用是将getDanmuKu()中的返回的数据清洗储存下来
同样,可以存到变量中,在后续的清洗中调用
对内存有压力
如果有人看的话,可以记得提醒我重写
完整代码:
import datetime
import requests
from bs4 import BeautifulSoup
import pandas as pd
def create_assist_date(datestart = None,dateend = None):
if datestart is None:
datestart = '2016-01-01'
if dateend is None:
dateend = datetime.datetime.now().strftime('%Y-%m-%d')
datestart = datetime.datetime.strptime(datestart, '%Y-%m-%d')
dateend = datetime.datetime.strptime(dateend, '%Y-%m-%d')
date_list = []
date_list.append(datestart.strftime('%Y-%m-%d'))
while datestart < dateend:
# 日期叠加一天
datestart += datetime.timedelta(days=+1)
# 日期转字符串存入列表
date_list.append(datestart.strftime('%Y-%m-%d'))
return date_list
# 这里填入自己的User-agent和cookie信息
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36",
'Cookie': "_uuid=D15B613E-811B-0C55-DDCE-4E5C6BAC199710450infoc; buvid3=F89A63A1-9E1B-499C-9191-A0440593CD4D138366infoc; sid=916ze85v; DedeUserID=176472028; DedeUserID__ckMd5=6ecea37532afc88f; SESSDATA=7bf772df%2C1611988683%2Cff065*81; bili_jct=5087f3d31324da4480da7deef1158ece; rpdid=|(u)~mum)l)m0J'ulmYRJY~k~; LIVE_BUVID=AUTO6115964423413404; CURRENT_QUALITY=120; blackside_state=1; CURRENT_FNVAL=80; bp_video_offset_176472028=454934553883672194; bp_t_offset_176472028=457902131473234478; _dfcaptcha=e61555d961b3fc689d6828441ae3f249; PVID=2"
}
def saveInCsv(all_info, all_text, date):
# 将弹幕文件保存在csv文件中
f=open('file\danmuinfo.csv','w', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(["时间", "弹幕模式", "字号大小", "颜色", "Unix格式时间戳", "弹幕种类", "发送者ID", "rowID"])
for single_info in all_info:
single_info = str(single_info).split(',')
csv_writer.writerow(single_info)
f.close()
f = open('file\danmutext.csv', 'w', encoding='utf-8')
csv_writer=csv.writer(f)
for single_text in all_text:
csv_writer.writerow(single_text)
f.close()
def getDanmuKu(url):
danmu = requests.get(url, headers=headers)
# 解码弹幕内容为utf-8
danmu = danmu.content.decode('utf-8')
# 用BeatifulSoup提取弹幕信息
danmu = BeautifulSoup(danmu)
danmus = danmu.findAll('d')
# 将弹幕信息和内容分别用两个列表保存
danmu_info = []
danmu_text = []
for iter in danmus:
danmu_info.append(iter['p'].split(','))
danmu_text.append(iter.text)
return danmu_info,danmu_text
def cleanAndSave(info,text,data):
import pandas as pd
text = pd.Series(text,name=['content'])
if __name__ == '__main__':
cid = '254605200'
start = '2020-11-11'
for time in create_assist_date(start):
url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid='+cid+'&date='+time
danmu_text,danmu_info = getDanmuKu(url)
print(danmu_info,danmu_text)
saveInCsv(danmu_text,danmu_info, time)
五、清洗
这边打算做可视化,用的是见齐大佬的可视化工具
具体见见齐大佬的GitHub:Historical-ranking-data-visualization-based-on-d3.js
其中对于文件格式有要求:

代码
import re,string
import csv
from video_danmu_可视化.get_danmu import create_assist_date
start = '2020-11-15'
danmuCount = dict()
danmuNum = 0
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。?》《{} oh1O○〇●哈'
with open('file\danmuku3.csv', 'a', encoding='gb18030') as savefile:
writer = csv.writer(savefile)
writer.writerow(['name','type','value','date'])
for date in create_assist_date(start):
with open('file\danmutext.csv', 'r', encoding='utf-8') as csvfile:
print('---分析日期', date, '弹幕...\n')
reader = csv.reader(csvfile)
for line in reader:
danmuNum = danmuNum + 1
line = "".join(line)
line = re.sub(r"[%s]+" % punc, "", line)
# words_list = jieba.lcut(line)
# for word in words_list:
# data[line] = data[line] + 1
# line = line.lower()
if len(line) >= 2 and len(line) <= 15:
if danmuCount.get(line):
danmuCount[line] = danmuCount[line] + 1
else:
danmuCount[line] = 1
sortList = sorted(danmuCount.items(), key=lambda item:item[1], reverse=True)
if len(sortList)>10:
pltLists = sortList[:10]
for plttuple in pltLists:
saveLine = []
saveLine.append(plttuple[0])
saveLine.append(str(plttuple[1]))
saveLine.append(plttuple[1])
saveLine.append(date)
writer.writerow(saveLine)
import pandas as pd
data = pd.read_csv('file\danmuku3.csv',encoding='gbk')
print(data.shape)
data.dropna(axis=0)
data=data.drop_duplicates(subset=['name','type','value','date'], keep='first')
data.drop([len(data)-1],inplace=True)
data.to_csv('file\data.csv',encoding='utf-8',index=0)
由于我是参考爬取B站弹幕并可视化-流浪地球
里面的代码是对文件操作,可能在搬砖的时候出错了,会在文件中重复很多次
于是我用pandas去重去空
等日后,用pandas改进下