爬虫网页解析之css用法及实战爬取中国校花网
前言
我们都知道,爬虫获取页面的响应之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,
python从网页中提取数据的包很多,常用的解析模块有下面的几个:
-
BeautifulSoup API简单 但解析速度慢,不推荐使用
-
lxml 由C语言编写的xml解析库(libxm2),解析速度快 但是API复杂
-
Scrapy 综合以上两者优势实现了自己的数据提取机制,被称为Selector选择器。
它是由lxml库构建的,并简化了API ,先通过XPath或者CSS选择器选中要提取的数据,然后进行提取
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。
Selector选择器的用法
下面我们以 Scrapy Shell 和 Scrapy 文档服务器的一个样例页面(url=http://doc.scrapy.org/en/latest/_static/selectors-sample1.html)
来了解选择器的基本用法:
构造选择器
Scrapy selector 可以以 文字(Text),二进制(content)或 TextResponse 构造的 Selector。其根据输入类型自动选择最优的分析方法
以文字构造:
url = "http://doc.scrapy.org/en/latest/_static/selectors-sample1.html"
response = requests.get(url=url)
selector = Selector(text=response.text)
以 response 构造:
selector = Selector(response=response)
以二进制构造:
selector = Selector(text=response.content)
使用选择器
这里强烈推荐使用 scrapy shell 来进行调试!
为什么要使用 scrapy shell ?
当我们需要爬取某个网站,然后提取数据的时候,要用到 xpath css 或者正则提取方法等
但是有时候这些xpath 或者css 语句不一定一次就能写对,有时候需要我们不断地去调试。
可能有些人会说,我每写一次然后重新去请求,输出结果测试一下就知道了。只能说这种做法就比较愚蠢了,如果遇到那种容易封IP的网站,你这样频繁的去请求测试,测不了几次,你的ip就被封了
这时候,我们要使用 scrapy shell 去调试,测试成功后,在拷贝到我们的项目中就可以了
如何使用 scrapy shell?
首先打开 Shell, 然后输入命令 scrapy shell url
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
当然在 pycharm中, 也可以使用
当 shell 载入后,将获得名为 response 的 shell 变量,url 响应的内容保存在 response 的变量中,可以直接使用以下方法来获取属性值
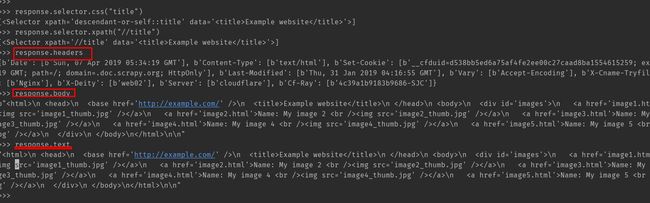
response.body
response.headers
response.headers['Server']
由于在 response 中使用 XPath、CSS 查询十分普遍,因此,Scrapy 提供了两个实用的快捷方式:
response.css()
response.xpath()
比如,我们获取该网页下的 title 标签,方法如下:
>>> response.css("title")
[<Selector xpath='descendant-or-self::title' data='Example website '>]
>>> response.xpath("//title")
[<Selector xpath='//title' data='Example website '>]
.xpath() 以及 .css() 方法返回一个类 SelectList 的实例,它是一个新选择器的列表。这个 API 可以用来快速的提取嵌套数据。
为了提取真实的原文数据,需要调用 .extract() 等方法
提取数据
extract():返回选中内容的Unicode字符串。
extract_first():SelectorList专有,返回其中第一个Selector对象调用extract方法。通常SelectorList中只含有一个Selector对象的时候选择调用该方法。
re() 使用正则表达式来提取选中内容中的某部分。
举个例子
>>> selector.xpath('.//b/text()') .extract()
[‘价格:99.00元’,‘价格:88.00元’,‘价格:88.00元’]
>>> selector.xpath('.//b/text()').re('\d+\.\d+')
[ '99.00','88.00','88.00']
re_first() 返回SelectorList对象中的第一个Selector对象调用re方法。
>>> selector.xpath('.//b/text()').re_first('\d+\.\d+')
'99.00'
css语法简单介绍
" * " 选择所有节点
" # container " 选择id为container的节点
" .container " 选择class包含container的节点
"li a " 选择 所有 li 下的所有 a 节点
“ul + p” 选择所有ul后面的第一个p元素
“#container > ul” 选择id为container的第一个ul节点
"a[class] " 选取所有有class属性的a元素
“a[href=“http://b.com”]” 含有href="http://b.com"的a元素
"a[href*=‘job’] " 包含job的a元素
"a[href^=‘https’] " 开头是https的a元素
“a[href$=‘cn’]” 结尾是cn的a元素
我们以上面的样例网页为例
下面是样例的html的源码
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
<link rel="stylesheet" href="/10994125-6b4dfbe961384f54928ea988268cedc6.css?1554613507" type="text/css"/>
<script language="javascript" type="text/javascript" src="/10994125-ea42c7db7c884a6691551d5756c02302.js?1554613507" charset="utf-8"></script>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
css用法实例
>>> response.css("title ::text").extract_first('') # 获取文本
'Example website'
>>> response.css("#images ::attr(href)").extract() # 获取 id= images 下的所有href属性
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
>>> response.css('a[href*=image]::attr(href)').extract() # 获取所有包含 image 的 href 属性
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
>>> response.css("#images a")[0].css("::attr(href)").extract() # css选取第一个a标签里面的href属性
['image1.html']
>>> response.xpath(".//div[@id='images']/a[1]").xpath("@href").extract() # xpath选取第一个a标签里面的href属性
['image1.html']
css用法实战
目标地址:中国大学校花网
http://www.xiaohuar.com/hua/
爬虫整体思路:
1、先将总页数拿下来
2、根据总页数循环去拿图片地址
3、再请求图片链接,将图片保存到本地
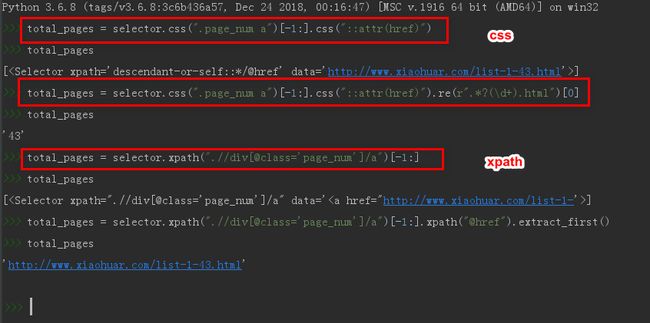
F12打开浏览器开发者工具,找到尾页再网页源码中的位置
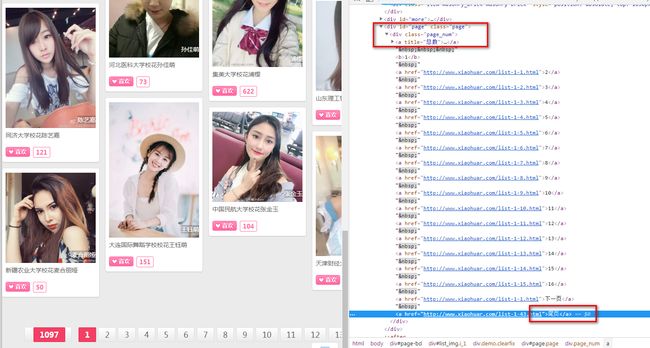
可以看到尾页链接在 a 标签列表里面的末尾,在 css 中我们可以使用切片的方法来获取最后一个值
语法如下:
total_pages = selector.css(".page_num a")[-1:].css("::attr(href)").re(r".*?(\d+).html")[0] # css
total_pages = selector.xpath(".//div[@class='page_num']/a")[-1:].xpath("@href").re(r".*?(\d+).html")[0] # xpath
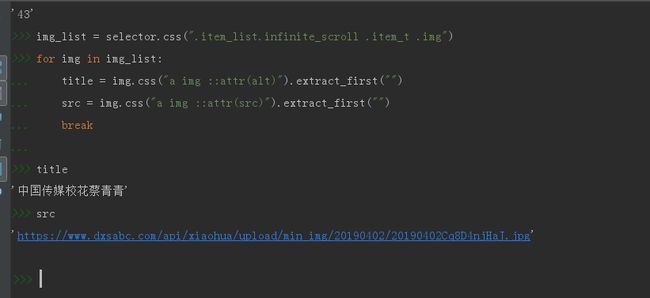
同样的方法(不细说了),我们获取图片的地址和名称
语法如下:
img_list = selector.css(".item_list.infinite_scroll .item_t .img")
for img in img_list:
title = img.css("a img ::attr(alt)").extract_first("")
src = img.css("a img ::attr(src)").extract_first("")
因为只是用来测试,所以我只爬了前几页,如果想爬全部,将循环的页数改成 total_pages 即可
最终效果如下:
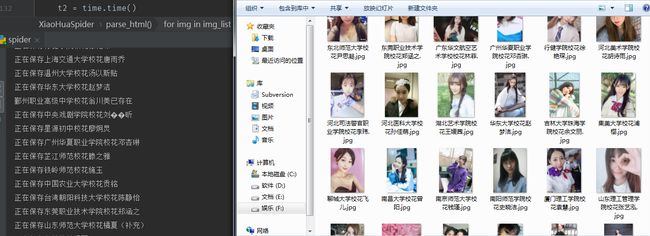
不到2分钟,就全部爬完了,因为是爬虫入门的教程,所以就没用异步的爬虫框架,下面是源码
# coding: utf-8
import requests
import time
from scrapy import Selector
import os
class XiaoHuaSpider(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
def spider(self):
"""
爬虫入口
:return:
"""
url = "http://www.xiaohuar.com/hua/"
response = requests.get(url, headers=self.headers)
selector = Selector(text=response.text)
total_pages = selector.css(".page_num a")[-1:].css("::attr(href)").re(r".*?(\d+).html")[0] # 总页数
self.parse_html(selector) # 第一页爬取
for page in range(1, 5): # 第二页至第五页
url = f"http://www.xiaohuar.com/list-1-{page}.html"
response = requests.get(url, headers=self.headers)
selector = Selector(text=response.text) # 创建选择器
self.parse_html(selector) # 解析网页
def parse_html(self, selector):
img_list = selector.css(".item_list.infinite_scroll .item_t .img")
for img in img_list:
title = img.css("a img ::attr(alt)").extract_first("")
src = img.css("a img ::attr(src)").extract_first("")
if "file" in src: # 第一个图片和其他图片地址不一样
src = "http://www.xiaohuar.com" + src
img_res = requests.get(src, headers=self.headers)
data = img_res.content
self.save_img(title, data)
@staticmethod
def save_img(title, data):
"""
保存图片到本地
:param title:
:param data:
:return:
"""
os.chdir("F:\\测试\\校花") # 需要先在本地创建此目录
if os.path.exists(title + ".jpg"):
print(f"{title}已存在")
else:
print(f"正在保存{title}")
with open(title + ".jpg", "wb")as f:
f.write(data)
if __name__ == '__main__':
spider = XiaoHuaSpider()
t1 = time.time()
spider.spider()
t2 = time.time()
print(t2 - t1)
