准备工作(Preparatory Work )
hadoop下载 下载过程链接:https://www.jianshu.com/p/a28e2305a48c
本地部署过程(Deployment Process)
下载hadoop安装包后不作任何设置,默认的就是本地模式
本地模式最简单,使用的是本地文件系统,而不是HDFS
主要用于本地开发过程的运行调试
step1:创建存放本地模式的hadoop目录
输入:mkdir /opt/modules/hadooplocal 创建文件
step2:解压 hadoop安装包
hadoop 安装包解压就可以直接用
输入:tar -zxf /opt/software/hadoop-2.2.0.tar.gz -C /opt/modules/hadooplocal/
将存放在 /opt/software/ 目录下的安装包hadoop-2.2.0.tar.gz 解压到 /opt/modules/hadooplocal/ 目录下
在opt/modules/hadooplocal/ 目录下可用命令 ls 查看文件
step3:检查JAVA_HOME环境变量是否配置好
输入:echo ${JAVA_HOME} 查看java环境变量
若没有安装jdk或还未配置java环境变量,请看链接: https://www.jianshu.com/p/cff2b88883e4
用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce
step1: 创建mapreduce的输入文件 wc.input
输入: cd /opt/data/ 进入目录下
输入: vim wc.input 当 wc.input 文本不存在时,vim直接创建
打开文本后,按 i 键进入Inter编辑模式,输入内容

按Esc键退出编辑模式,按 :wq 保存并退出
step2:利用hadoop自带的mapreduce Demo 运行hadoop
输入: cd /opt/modules/hadooplocal/hadoop-2.2.0 找到 hadoop的安装目录
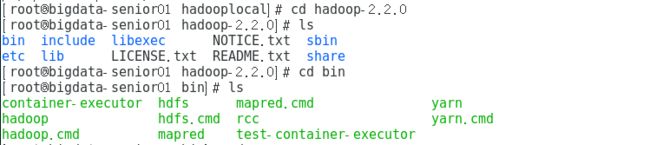
mapreduce Demo 存放在 share/hadoop/mapreduce/ 目录下
hadoop-mapreduce-examples-2.2.0.jar 是一个单词统计的功能

输入: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /opt/data/wc.input output1
运行功能的 .jar 包,wordcount是jar包需要运行的主类,wc.input 为输入的文本参数,输出结果保存到output1目录下
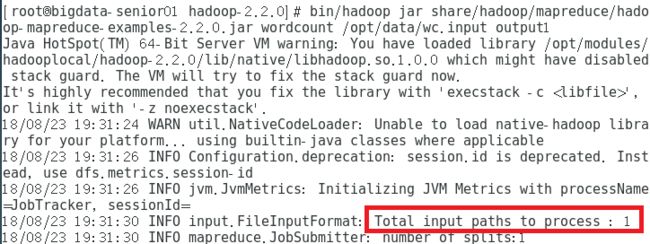


Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中
Hadoop Job的运行记录中,可知输入文件有1个(Total input paths to process:1)
这个Job被赋予了一个ID号:job_local953093661_0001,且job ID中有local字样,说明运行在本地模式下
同时还可以看到map和reduce的输入输出记录(record数及字节数)
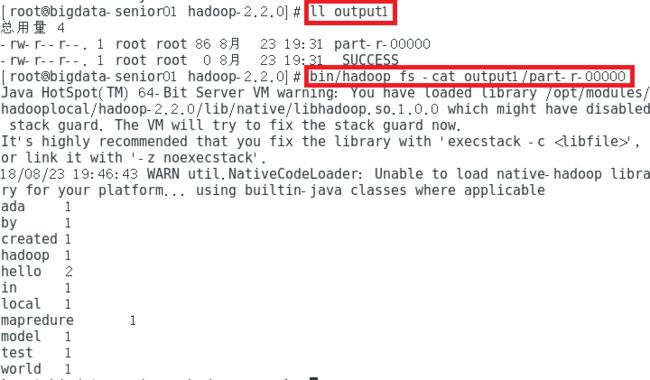
step3:查看输出文件
输入: ll output1 输出目录中有_SUCCESS文件说明JOB运行成功,part-r-00000是输出结果文件
输入: bin/hadoop fs -cat output1/part-r-00000 查看part-r-00000输出文件统计结果