MapReduce之基本数据类的排序
MapReduce之基本数据类的排序
-
- 一、需求说明
- 二、测试数据
- 三、编程思路
- 四、实现步骤
- 四、打包上传到集群中运行
一、需求说明
- 要求:将各个部门降序排列,利用MapReduce实现将emp.csv中的部门倒序排列
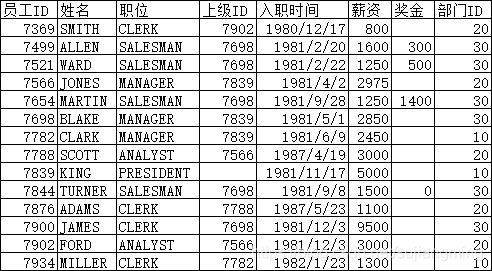
二、测试数据
- 员工信息表:下载地址
- 表字段说明:
三、编程思路
- 因在MapReduce中基本数据类型(如int)默认是升序排序的,因此我们只需要写一个类继承IntWritable.Comparator,重写compare方法即可
四、实现步骤
-
在Idea或eclipse中创建maven项目
-
在pom.xml中添加hadoop依赖
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>2.7.3version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-hdfsartifactId> <version>2.7.3version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-mapreduce-client-commonartifactId> <version>2.7.3version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-mapreduce-client-coreartifactId> <version>2.7.3version> dependency> -
添加log4j.properties文件在资源目录下即resources,文件内容如下:
### 配置根 ### log4j.rootLogger = debug,console,fileAppender ## 配置输出到控制台 ### log4j.appender.console = org.apache.log4j.ConsoleAppender log4j.appender.console.Target = System.out log4j.appender.console.layout = org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern = %d{ABSOLUTE} %5p %c:%L - %m%n ### 配置输出到文件 ### log4j.appender.fileAppender = org.apache.log4j.FileAppender log4j.appender.fileAppender.File = logs/logs.log log4j.appender.fileAppender.Append = false log4j.appender.fileAppender.Threshold = DEBUG,INFO,WARN,ERROR log4j.appender.fileAppender.layout = org.apache.log4j.PatternLayout log4j.appender.fileAppender.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n -
编写序列化类Employee.java,用于映射到emp.csv文件内容
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class Employee implements Writable { //7369,SMITH,CLERK,7902,1980/12/17,800,,20 private IntWritable empNo; private Text empName; private Text empJob; private IntWritable leaderNo; private Text hireDate; private IntWritable empSalary; private Text empBonus; private IntWritable deptNo; public Employee() { this.empNo = new IntWritable(); this.empName = new Text(""); this.empJob = new Text(""); this.leaderNo = new IntWritable(); this.hireDate = new Text(""); this.empSalary =new IntWritable(); this.empBonus = new Text(""); this.deptNo = new IntWritable(); } public Employee(int empNo, String empName, String empJob, int leaderNo, String hireDate, int empSalary, String empBonus, int deptNo) { this.empNo = new IntWritable(empNo); this.empName = new Text(empName); this.empJob = new Text(empJob); this.leaderNo = new IntWritable(leaderNo); this.hireDate = new Text(hireDate); this.empSalary =new IntWritable(empSalary); this.empBonus = new Text(empBonus); this.deptNo = new IntWritable(deptNo); } @Override public void write(DataOutput out) throws IOException { //序列化 this.empNo.write(out); this.empName.write(out); this.empJob.write(out); this.leaderNo.write(out); this.hireDate.write(out); this.empSalary.write(out); this.empBonus.write(out); this.deptNo.write(out); } @Override public void readFields(DataInput in) throws IOException { this.empNo.readFields(in); this.empName.readFields(in); this.empJob.readFields(in); this.leaderNo.readFields(in); this.hireDate.readFields(in); this.empSalary.readFields(in); this.empBonus.readFields(in); this.deptNo.readFields(in); } @Override public String toString() { return "Employee{" + "empNo=" + empNo + ", empName=" + empName + ", empJob=" + empJob + ", leaderNo=" + leaderNo + ", hireDate=" + hireDate + ", empSalary=" + empSalary + ", empBonus=" + empBonus + ", deptNo=" + deptNo + '}'; } public IntWritable getEmpNo() { return empNo; } public void setEmpNo(IntWritable empNo) { this.empNo = empNo; } public Text getEmpName() { return empName; } public void setEmpName(Text empName) { this.empName = empName; } public Text getEmpJob() { return empJob; } public void setEmpJob(Text empJob) { this.empJob = empJob; } public IntWritable getLeaderNo() { return leaderNo; } public void setLeaderNo(IntWritable leaderNo) { this.leaderNo = leaderNo; } public Text getHireDate() { return hireDate; } public void setHireDate(Text hireDate) { this.hireDate = hireDate; } public IntWritable getEmpSalary() { return empSalary; } public void setEmpSalary(IntWritable empSalary) { this.empSalary = empSalary; } public Text getEmpBonus() { return empBonus; } public void setEmpBonus(Text empBonus) { this.empBonus = empBonus; } public IntWritable getDeptNo() { return deptNo; } public void setDeptNo(IntWritable deptNo) { this.deptNo = deptNo; } } -
编写自定义Mapper类
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class EmployeeMapper extends Mapper<LongWritable, Text, IntWritable,Employee> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //数据格式:<0,7369,SMITH,CLERK,7902,1980/12/17,800,,20> //1、分词 String[] splits = value.toString().split(","); //2、创建Employee对象,并且赋值 Employee employee = null; //判断员工是否有上级领导,如果没有,则给该字段设置一个0 if (null == splits[3] || "".equals(splits[3])){ splits[3] = "0"; } //判断员工是否有奖金 if(null != splits[6] && !"".equals(splits[6])){ employee = getEmpInstance(splits); }else{ splits[6] = "0"; employee = getEmpInstance(splits); } //3、通过context写出去 context.write(employee.getDeptNo(),employee); } private Employee getEmpInstance(String[] splits){ Employee employee = new Employee( Integer.parseInt(splits[0]),splits[1],splits[2], Integer.parseInt(splits[3]),splits[4],Integer.parseInt(splits[5]), splits[6],Integer.parseInt(splits[7])); return employee; } } -
编写自定义Reducer类
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class EmployeeReducer extends Reducer<IntWritable,Employee,IntWritable,IntWritable> { @Override protected void reduce(IntWritable key, Iterable<Employee> values, Context context) throws IOException, InterruptedException { //1、对数据进行处理:取出工资和奖金,求和操作 int sum = 0; for (Employee e: values) { IntWritable salary = e.getEmpSalary(); Text bonus = e.getEmpBonus(); if (bonus.getLength() > 0){ sum += salary.get() + Integer.valueOf(bonus.toString()); }else{ sum += salary.get(); } } //2、将结果通过context写出去 context.write(key,new IntWritable(sum)); } } -
编写自定义比较器类NumComparator.java
import org.apache.hadoop.io.IntWritable; public class NumComparator extends IntWritable.Comparator { @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { return -super.compare(b1, s1, l1, b2, s2, l2);//-代表降序 } -
编写自定义Driver类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.util.Random; public class EmployeeJob { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(EmployeeJob.class); job.setMapperClass(EmployeeMapper.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(Employee.class);//Employee job.setReducerClass(EmployeeReducer.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); //设置比较器 job.setSortComparatorClass(NumComparator.class); //先使用本地文件做测试 FileInputFormat.setInputPaths(job,new Path("F:\\NIIT\\hadoopOnWindow\\input\\emp.csv")); FileOutputFormat.setOutputPath(job,new Path(getOutputDir())); boolean result = job.waitForCompletion(true); System.out.println("result:" + result); } //用于产生随机输出目录 public static String getOutputDir(){ String prefix = "F:\\NIIT\\hadoopOnWindow\\output\\"; long time = System.currentTimeMillis(); int random = new Random().nextInt(); return prefix + "result_" + time + "_" + random; } } -
本地运行代码,测试下结果正确与否
四、打包上传到集群中运行
-
上传emp.csv到hdfs中的datas目录下
-
本地运行测试结果正确后,需要对Driver类输入输出部分代码进行修改,具体修改如下:
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1])); -
将程序打成jar包,需要在pom.xml中配置打包插件
<build> <plugins> <plugin> <groupId>org.apache.maven.pluginsgroupId> <artifactId> maven-assembly-plugin artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependenciesdescriptorRef> descriptorRefs> configuration> <executions> <execution> <id>make-assemblyid> <phase>packagephase> <goals> <goal>singlegoal> goals> execution> executions> plugin> plugins> build>按照如下图所示进行操作
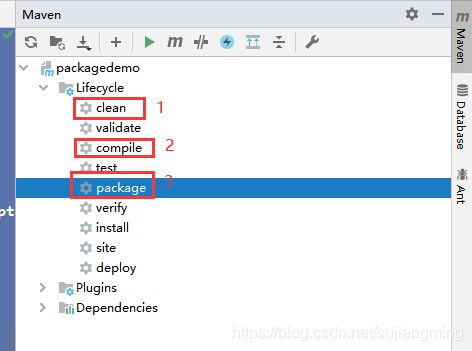
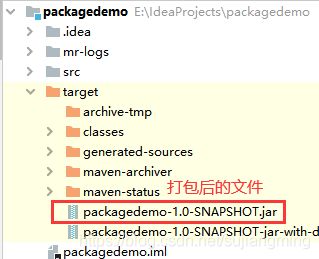
-
提交集群运行,执行如下命令:
hadoop jar packagedemo-1.0-SNAPSHOT.jar com.niit.mr.EmployeeJob /datas/emp.csv /output/emp/至此,所有的步骤已经完成,大家可以试试,祝大家好运~~~~