Vue3 composition API 和新的响应式原理解析
vue3.0已经推出了一段时间了,相信很多人都已经跃跃欲试了,其中改动最大,最让人眼前一亮的当属composition API,有的人也会说,vue3推出composition API后,看起来越来越像react的hook了,那么原本的option API存在什么问题?为什么要用composition API替换掉?原理层面又是如何实现性能的飞跃的?接下来让我们一探究竟
什么是option API?
在vue2及之前的版本,我们对于一个数据的处理,可能是在data中先进行声明,然后再methods中添加相关的处理方法,在watch、computed等等中添加一些数据处理,这种处理的方式,其实就是option API,而这种最传统的处理方式存在的问题也很显而易见,就是如果一个页面内存在的数据较多时,难以阅读和维护。
在使用option API中,一开始我们的代码可能是这样

随着功能的添加,后续就会逐渐变成这样
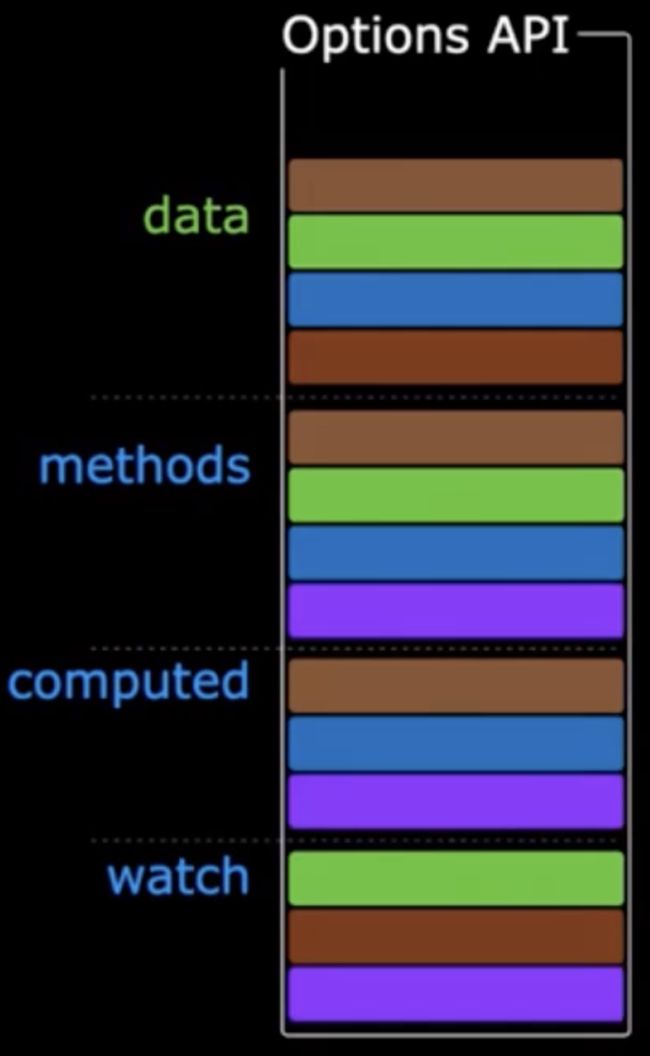
这种代码达到数百行之后,就会开始变得难以阅读和维护了,想要找一个功能相关的代码需要来回跳。在vue3以前我们可能用到的解决方案,一个是拆分组件,但是如果是关联比较紧密的功能,是不太方便拆分组件的,另一个可用的方案就是mixins了,但是mixins也没有在根本上解决这个问题。
什么是mixins?
先解释一下什么是mixins,mixins最直接的理解,就是英文单词的直译,也就是“混入”。当我们有多个页面中存在风格不同,但是存在类似的处理逻辑与状态时,我们就可以采用mixins,举个比较简单的例子,比如数个页面中均存在弹窗,我们控制弹窗的可见性的方法以及可见性的状态,就可以抽离成一个mixins,然后再注入到各个页面中去。
我们还是用一段demo代码来作为说明
// mixin.js
export const MyMixin = {
data () {
visible: false
},
methods: {
toggleVisible() {
this.visible = !this.visible
}
}
}
以上是我们准备为多个弹窗共用的mixins,接下来我们将其分配给其他的组件,这里以其中一个组件的引用为例。
// ConsumingComponent.js
import MyMixin from "./MyMixin.js";
export default {
mixins: [MyMixin],
data: () => ({
myLocalDataProperty: null
}),
methods: {
myLocalMethod () {
... }
}
}
多个组件使用,也都是这样引用,相当于把公共的属性方法抽离,提高复用性。
联系上面的功能结构图,mixins就好比把一个功能,也就是相同的色块抽离出来,单纯从这个角度来看,mixins似乎解决了option API存在的弊病,但是实际上mixins被认为是有害的。
mixins存在什么问题?
以上的使用方式,乍一看似乎没什么问题,但是稍微思考一下就会发现一个比较明显的问题,和一个隐藏的问题:
1.如果mixins内声明的状态名和方法名,和组件内部自带的重复了怎么办?
2.mixins实际上和组件并没有层级关系,也就是并非父子,可以互相调用彼此的属性和方法,如果在mixins里调用了组件内的属性,一旦组件内的属性名发生变化,mixins内部会怎么样?
当mixins和组件内的状态名重复,vue组件的默认将组件的属性覆盖mixins的属性;而隐式依赖关系中,如果组件的属性被mixins中占用,组件中又改了名字,在组件中看不出异常,代码构建中也不会报错,但是一旦开始运行就会报错了。以上的两个问题,其实也是mixins至今一直被人诟病的点,以至于被认为“有害”。而在vue3中,composition API替代了mixins,接下来让我们理解一下composition API,看看是否解决了mixins存在的问题。
Composition API
首先我们先回到之前的option API下的代码结构
如果换做用composition API来处理,就会变成如下的结构
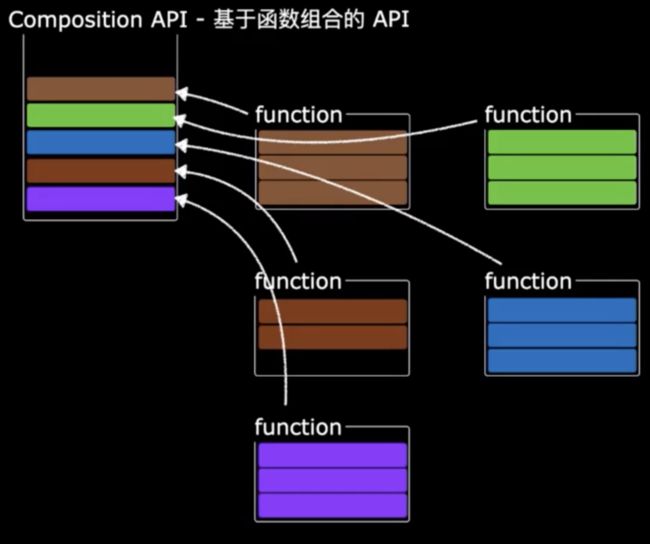
从这个结构图也不难看出,composition API整体的思路可以说是和mixins一致,依然是把可以共用的属性、方法等抽离,我们先看如何使用,以及如何解决了mixins存在的问题,最后再看看composition API的原理是什么。
Composition API的用法
在这里列出几个最常用也是最重要的API,主要用来帮助我们理解composition API的用法和代码编写思路,详细的全部API可以去github上去查阅。
ref、reactive与setup函数
ref和reactive是vue3新增的用来创建响应式数据的函数,需要搭配setup函数使用,setup函数是用来替代原本的created和beforeCreate,setup函数仅会执行一次,ref与reactive的区别是一个用来创建简单数据类型,一个用来创建复杂数据类型,用一个最简单的demo来展示一下这三个函数的使用方式
<template>
<div>
<p>{
{
count}}</p>
<button @click="add"></button>
</div>
</template>
<script>
import {
ref } from 'vue'
export default {
setup() {
let count = ref(0)
function add() {
count.value ++
}
return {
count, add }
}
}
</script>
以上就是一个最简单的应用composition API的例子,ref传入初始值,用一个变量接收,可以在setup函数中写一些状态变化的方法,好比vue2中的methods中的方法,最后将声明的状态和处理函数都一起返回。
当然实际开发不可能这么简单,我们用reactive做一个比较简单的todo list,并逐渐扩充功能,来充分理解composition API。
<template>
<div>
<input v-model="state.val" />
<button @click="addTodo">添加</button>
<ul>
<li v-for=" todo in state.todos" :key="todo.name">{
{
todo.name}}</li>
</ul>
<div>共有:{
{
total}}个任务</div>
</div>
</template>
<script>
import {
reactive, computed } from 'vue'
export default {
setup() {
let state = reactive({
todos: [{
name:'写代码',done:false},{
name:'打游戏',done:false}],
val: ''
})
let total = computed(() => state.todos.length)
function addTodo() {
state.todos.push({
name:state.val,done:false})
state.val = ''
}
return {
state, addTodo, total }
}
}
</script>
以上就是一个用reactive做的一个稍微复杂一点的demo,但是也是比较简单的,额外引入了一个computed,对于之前的option API像watch之类,都可以通过这种方式引入。
上面是最基本的用法,我们回想一下,一开始我们说的composition API的理念是基于函数组合的API,可以理解为两个关键词,一个是基于函数,一个是组合,但是现在亮点都还没有提现出来。接下来我们将这个demo进行小改造,体验一下第一个关键词:基于函数,也就是可以把逻辑放到一个函数里
<template>
<div>
<input v-model="state.val" />
<button @click="addTodo">添加</button>
<ul>
<li v-for=" todo in state.todos" :key="todo.name">{
{
todo.name}}</li>
</ul>
<div>共有:{
{
total}}个任务</div>
</div>
</template>
<script>
import {
reactive, computed } from 'vue'
export default {
setup() {
let {
state, addTodo, total } = useAddTodo()
return {
state, addTodo, total }
}
}
function useAddTodo() {
let state = reactive({
todos: [{
name:'写代码',done:false},{
name:'打游戏',done:false}],
val: ''
})
let total = computed(() => state.todos.length)
function addTodo() {
state.todos.push({
name:state.val,done:false})
state.val = ''
}
return {
state, addTodo, total }
}
</script>
以上就是在单文件内,将一个功能相关的状态、方法等都放在一个函数中,既然能提取到函数中,我们也可以提取到不同的js文件中,上述例子我们就可以提取到一个todos.js文件中,在js文件中也是可以使用computed、mounted等函数的,只是生命周期前面多了一个on
import {
reactive, computed, onMounted, onCreated } from 'vue'
function useAddTodo() {
let state = reactive({
todos: [{
name:'写代码',done:false},{
name:'打游戏',done:false}],
val: ''
})
let total = computed(() => state.todos.length)
function addTodo() {
state.todos.push({
name:state.val,done:false})
state.val = ''
}
onMounted(() => {
// do something...
})
return {
state, addTodo, total }
}
export default useAddTodo
同样的,我们还可以有很多其他的js文件,A.js、B.js、C.js等等,用来存放不同的功能,在展示页面中就可以这样写
<template>
<div>
<input v-model="state.val" />
<button @click="addTodo">添加</button>
<ul>
<li v-for=" todo in state.todos" :key="todo.name">{
{
todo.name}}</li>
</ul>
<div>共有:{
{
total}}个任务</div>
</div>
</template>
<script>
import useAddTodo from './useAddTodo'
// import fn1 from '...'
export default {
setup() {
let {
state, addTodo, total } = useAddTodo()
// let { a, b, c } = fn1
return {
state, addTodo, total }
}
}
</script>
这样看起来,是不是清爽了很多?我们每一个功能拆分到独立的函数中去,在需要使用的地方引入,可以自由组合。
看到这里,我们可以发现composition API的思路和mixins极为相似,都是组件功能抽离到单独js文件后按需引入,那么mixins存在的问题又是怎么解决的呢?
mixins遗留问题的解决
命名冲突
之前的mixins在使用文件导入时,mixins相当于是一个黑盒,里面都有哪些东西完全是未知的,而现在我们每次使用composition API,引入都需要用变量去接收函数的返回值,这样数据来源清晰可见,也就避免了命名冲突。第一个问题圆满解决
隐式依赖
我们先梳理一下之前mixins里存在的问题,隐式依赖其实就是在mixins的方法中,有使用组件的本地属性,也就是组件内声明的data,如果组件重构导致变量名修改,在未执行对应方法时,这个方法并不会报错,这就是隐式依赖。
改成了composition API后,如果想在composition API中使用本地属性,那就需要在组件中作为实参传入导入的函数里,比如上述的todo list例子,就需要在使用useAddTodo时将本地状态传入。
composition API如何实现响应式?
至此我们理解了composition API的用法和优点,composition API还有一个比较奇妙的点,就是和vue2的option API是完美兼容的,一个组件可以既使用composition API,又使用option API。那么可能我们会有这样的疑问,creative函数如何创建的响应式对象?都说vue3性能有了很大的提升,究竟是怎么实现的?这些问题就需要我们深入到源码中,对原理进行深入理解。
object.defineproperty
object.object.defineproperty这个函数大家肯定不陌生,是响应式的原理,但是实际上他本身存在一定的弊病,object.defineproperty如果不对监听的变量加额外的处理,实际上他只能监听基本数据类型,或者复杂数据类型的最外层地址,我们直接修改一个对象内的某个属性,或者给数组push一条数据,都不会触发内部的set和get,所以其实在vue2中,是对数组和对象都做了额外的处理。
对于对象,vue2中的处理方式是递归遍历,在项目一开始编译时,就会将全部的状态进行递归,且无法监听原本对象里不存在的属性;对于数组,vue2的做法是数据劫持,重写了像push、unshift一些的数组原生方法来触发响应式,在这里暂且不谈数据劫持对原型链产生的影响,单纯递归遍历把数据变成响应式数据就是比较损耗性能的,这也是为什么在vue3中用proxy替换object.defineproperty。
用proxy替换了object.defineproperty后,虽然说想监听深层属性依然是需要递归的,但是从构建时的全部的递归变成了在取值时按需递归,从而避免了项目初始化时递归导致的初始化时间过长。上面我们使用的reactive方法,就是使用了proxy来实现了响应式,接下来让我们对reactive的源码进行理解
reactive源码理解
reactive的源码也比较好找,vue3对reactive创建了一个单独的reactive.ts文件,我们首先看我们直接使用的reactive函数
export function reactive(target: object) {
if (readonlyToRaw.has(target)) {
return target
}
if (readonlyValues.has(target)) {
return readonly(target)
}
// 调用createReactiveObject创建reactive对象
return createReactiveObject(
target,
rawToReactive,
reactiveToRaw,
mutableHandlers,
mutableCollectionHandlers
)
}
代码不多,但是有几个关键的变量,这几个关键变量我们从名字就可以看出用途,前两个readonlyToRaw、readonlyValues都是只读相关的东西,后面的都是xxx to xxx,这大多是一些映射,首先确定的是,reactive返回的是一个proxy,从这一点出发再去看源码,如果是只读对象到原对象的映射,这就说明传入的target已经是一个proxy了,所以直接返回,如果是只读属性,那么通过readonly方法去获取原proxy对象,再返回。不是只读的情况调用了createReactiveObject,创建了一个响应式对象,传入了五个参数,第一个是原对象,剩下的从名字看就是两个映射和两个处理函数,我们再继续向下看。
// WeakMaps that store {raw <-> observed} pairs.
const rawToReactive = new WeakMap<any, any>()
const reactiveToRaw = new WeakMap<any, any>()
const rawToReadonly = new WeakMap<any, any>()
const readonlyToRaw = new WeakMap<any, any>()
// WeakSets for values that are marked readonly or non-reactive during
// observable creation.
const readonlyValues = new WeakSet<any>()
const nonReactiveValues = new WeakSet<any>()
const collectionTypes = new Set<Function>([Set, Map, WeakMap, WeakSet])
这一部分是reactive函数中用到的一些集合的声明,用的是weakMap和weakset,map和set大家应该不陌生,weakMap和weakSet和map、set基本上是一致的,只是是弱引用,无论是读还是写都更节省性能,具体的语法可以参照es6中对weakMap和weakSet的描述,在这里不赘述。
从名字我们可以看出这些映射的用途,rawToReactive是原对象到响应式对象的映射,reactiveToRaw则是反过来,rawToReadonly是原对象到只读对象的映射,readonlyToRaw也是反过来,readonlyValues、nonReactiveValues是两个集合,分别是只读对象和不可响应对象的集合,最后是一个Set, Map, WeakMap, WeakSet的集合,这两部分联系起来看,变量的定义和使用我们基本理解了个大概,就是声明了一些集合,在只读的情况下,返回只读的proxy对象,在其他情况,创建响应式对象再返回,那么最核心的部分其实就是createReactiveObject了,接下来我们再看这个函数的源码
function createReactiveObject(
target: unknown,
toProxy: WeakMap<any, any>,
toRaw: WeakMap<any, any>,
baseHandlers: ProxyHandler<any>,
collectionHandlers: ProxyHandler<any>
) {
// 如果不是对象,直接返回,开发环境下会给警告
if (!isObject(target)) {
if (__DEV__) {
console.warn(`value cannot be made reactive: ${
String(target)}`)
}
return target
}
// toProxy中获取到了说明已经有了proxy的映射,将取到的映射返回
let observed = toProxy.get(target)
if (observed !== void 0) {
return observed
}
// toRaw中取到了说明target本身就是响应式对象
if (toRaw.has(target)) {
return target
}
// Set、Map、WeakMap、WeakSet的响应式对象handler与Object和Array的响应式对象handler不同
const handlers = collectionTypes.has(target.constructor)
? collectionHandlers
: baseHandlers
// 创建Proxy
observed = new Proxy(target, handlers)
// 更新rawToReactive和reactiveToRaw映射
toProxy.set(target, observed)
toRaw.set(observed, target)
return observed
}
这个函数的行数也不算多,我们从头到尾依次去看,在项目起初看传入的原对象target是不是对象,如果不是直接返回,开发环境给予警告,接下来分别去传入的第二、第三个参数中尝试去取映射,toProxy和toRaw就是我们之前传入的rawToReactive和reactiveToRaw这两个weakMap,也就是原对象和响应式对象的互相映射表,如果在toProxy里面查到了key,说明是已经存储过的响应式对象,将取出的proxy返回,如果在toRaw里查到了key,说明target本身就已经是响应式对象了,所以直接返回target。
接下来根据传入的数据类型来判断要取哪个handle函数,collectionTypes已经存储了Set、Map、WeakMap、WeakSet,所以这部分是把这四种数据类型和object和array做了区分,能进入这里说明传入的target要么是没有缓存过,要么不是响应式对象,所以new 一个proxy,并传入处理函数,再更新原对象和响应式数据的映射表,最后返回了new的proxy对象。
到这里整体流程基本已经清晰了,剩下的还有一个关键点,也是整段源代码的重中之重,处理函数,也称之为陷阱函数,接下来让我们分别看一下mutableCollectionHandlers和mutableHandlers。
mutableHandlers是object和array的处理函数,所以我们先看这个函数
export const mutableHandlers: ProxyHandler<object> = {
get: createGetter(false),
set,
deleteProperty,
has,
ownKeys
}
这个函数依然只是个入口,我们再看这里几个方法的定义,这几个方法也是最核心的部分,首先是作为get在使用的createGetter。
Get
function createGetter(isReadonly: boolean) {
return function get(target: object, key: string | symbol, receiver: object) {
// 通过Reflect拿到原始值
const res = Reflect.get(target, key, receiver)
// 如果是内置方法,不做依赖收集
if (isSymbol(key) && builtInSymbols.has(key)) {
return res
}
// 如果是ref对象,代理到ref.value
if (isRef(res)) {
return res.value
}
// track用于收集依赖
track(target, OperationTypes.GET, key)
// 判断是嵌套对象,如果是嵌套对象,需要另外处理
// 如果是基本类型,直接返回代理到的值
return isObject(res)
// 这里createGetter是创建响应式对象的,传入的isReadonly是false
// 如果是嵌套对象的情况,通过递归调用reactive拿到结果
? isReadonly
? // need to lazy access readonly and reactive here to avoid
// circular dependency
readonly(res)
: reactive(res)
: res
}
}
这个函数行数也不多,但是还是难免有几个小疑问,首先就是为什么用reflect去取值而不是直接用key去target里面取?在最后为什么要做判断进行递归调用reactive?我们依次来看问题
首先关于reflect的语法可以查阅mdn,最关键的其实就是第三个参数receiver,这个参数在这个函数里的指向是代理后的proxy对象,我们看这样一个例子
const target = {
foo: 24,
get bar () {
return this.foo
}
}
const observed = reactive(target)
此时,如果不用 Reflect.get,而是 target[key],那么 this.foo 中的this就指向的是 target,而不是observed,已经指向了原对象而非响应式对象,如果 observed.foo = 20 改变了 foo 的值,那么是无法触发依赖回调的,所以需要利用 Reflect.get 将 getter 里的 this 指向代理对象。
在这段代码的地步,有一个比较有意思的写法,就是在底部做了判断是否进行递归,在这个逻辑上面写的英文注释也很有意思,翻译成中文就是:需要延迟地使用 readonly 和 readtive 来避免循环引用,其实proxy也是只能代理一层数据,无法深层代理,那就需要递归才能进行深层次的监听,但如果是普通的监听,对于循环引用的js数据就会产生问题了,如这样一个数据:
const a = {
b: {
}
}
a.b.c = a
如果对这个数据进行递归监听数据必然会造成内存溢出,所以在vue3中做了个判断,判断一下当前是不是对象,如果是对象就递归一次,为什么说是延迟呢?是因为只有在调用到了get的方法,也就是读值的时候才会进行判断,而非一开始就进行判断,又因为reactive在一开始会在各个weakMap表去读,如果发现这个数据已经被代理过,就不会继续代理,既避免了在初始化时全部递归导致的初始化速度过慢,又避免了循环引用产生的问题。
set
function set(
target: any,
key: string | symbol,
value: any,
receiver: any
): boolean {
// 获取旧值
value = toRaw(value)
const oldValue = target[key]
if (isRef(oldValue) && !isRef(value)) {
oldValue.value = value
return true
}
// 对象上是否有这个 key,有则是 set,无则是 add
const hadKey = hasOwn(target, key)
// 利用 Reflect 来执行 set 操作
const result = Reflect.set(target, key, value, receiver)
// don't trigger if target is something up in the prototype chain of original
// 如果 target 原型链上的数据,那么就不触发依赖回调
if (target === toRaw(receiver)) {
/* istanbul ignore else */
if (__DEV__) {
// 开发环境操作,只比正式环境多了个 extraInfo 的调试信息
const extraInfo = {
oldValue, newValue: value }
if (!hadKey) {
trigger(target, OperationTypes.ADD, key, extraInfo)
} else if (value !== oldValue) {
trigger(target, OperationTypes.SET, key, extraInfo)
}
} else {
// 上面讲过,有这个 key 则是 set,无则是 add
if (!hadKey) {
trigger(target, OperationTypes.ADD, key)
} else if (value !== oldValue) {
// 只有当 value 改变的时候才触发
trigger(target, OperationTypes.SET, key)
}
}
}
return result
}
set和get比多接收了一个参数,因为是set必然会接受value,多的就是这个value,首先判断是不是观察过的响应式数据,头几行还好,就是取值,isRef(oldValue) && !isRef(value)这一段的判定需要推敲,这一段的逻辑是如果旧的值是ref,新的值不是ref,就把传入的新值赋值给旧值,为什么会有这种逻辑呢?我们来看一段demo
const a = {
b: ref(1)
}
const observed = reactive(a) // { b: 1 }
用这个例子来看,如果修改了observed里的b,旧值是a中的ref,新值是给observed赋的值,直接赋值然后return,是因为ref已经是响应式数据了,他本身就已经有依赖,所以不需要再继续向下走重新搜集依赖了。
后面又判断了是set还是get操作,接下来又是一个有点绕的判定,target === toRaw(receiver),target是原对象,receiver是proxy代理后的对象,代理后的对象又用toRaw找原对象,这两个值按说应该永远相等,这为什么会进行这个比较呢?这个疑问可以查阅mdn上对receiver的定义:最初被调用的对象。通常是 proxy 本身,但 handler 的 set 方法也有可能在原型链上或以其他方式被间接地调用(因此不一定是 proxy 本身)。到这里就理解了,我们可能在非本身方法调用的时候,触发了set,这个情况他的原对象,和根据映射去查找到的对象确实不会是同一个,这里也自然不应当去触发相应的处理函数。再下面的trigger也就是搜集依赖的过程,这里不做深入研究。
其他方法
// 劫持属性删除
function deleteProperty(target: any, key: string | symbol): boolean {
const hadKey = hasOwn(target, key)
const oldValue = target[key]
const result = Reflect.deleteProperty(target, key)
if (result && hadKey) {
/* istanbul ignore else */
if (__DEV__) {
trigger(target, OperationTypes.DELETE, key, {
oldValue })
} else {
trigger(target, OperationTypes.DELETE, key)
}
}
return result
}
// 劫持 in 操作符
function has(target: any, key: string | symbol): boolean {
const result = Reflect.has(target, key)
track(target, OperationTypes.HAS, key)
return result
}
// 劫持 Object.keys
function ownKeys(target: any): (string | number | symbol)[] {
track(target, OperationTypes.ITERATE)
return Reflect.ownKeys(target)
}
其他的方法相对就比较简单了,本质上还是调用的原生的方法,这个思路与vue2中的对数组方法做的变异比较类似,就是先获取到原生方法,在进行返回前把和这个数据相关的依赖搜集上来,再进行返回,可以理解为数据劫持、延迟调用,在这里不过多赘述。
在vue2中使用composition API
我们现在使用的项目,大多都是vue2,项目整体替换vue3也会有较大风险,所以想体验composition API,我们可以选择另外一种方式,单独下载composition API的包,首先是引入
npm i @vue/composition-api -S
然后是使用
import Vue from 'vue'
import VueCompositionApi from '@vue/composition-api'
Vue.use(VueCompositionApi)
如此设置,我们就可以在vue2中也使用composition API了,而因为composition API和option API的兼容性,并不会对之前的代码产生影响
总结
总体来看vue3比vue2提升了很多,无论是写法上带来的清爽感,还是内部底层数据处理的优化,都有非常大的提升,也有人感叹vue3越来越像react,两个框架最后都逐渐走向了函数式编程,从目前vue3的改变来看,将来vue3一定会是大趋势,让我们拥抱vue3吧!