oracle
oracle是国企里用得最多的关系型数据库了,其对大并发、大访问量支持力度更好;在企业级应用比例达到40%
作为java后端开发人员,需要关注的oracle知识点:大概的执行的流程;常接触的对象;常用的sql操作;执行计划;索引及优化;复杂的统计脚本
大概的执行的流程
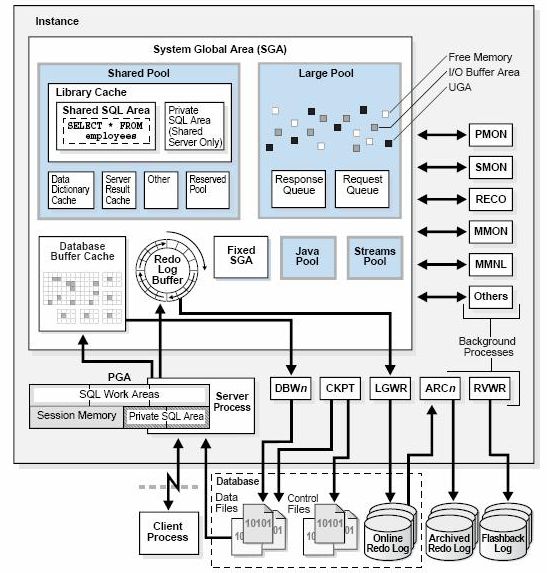
1. client请求oracle服务时,建立基于TCP长连接的一个session,oracle单独为该连接分配一个处理进程PID和内存区域PGA;
2. oracle判断sql语句语法和对象权限是否有误;
3. oracle进行语法分析,去SGA查找是否有该sql(哈希得到散列值)的执行计划。没有时,基于成本或者优先级的,生成最优的执行计划;以防后续复用,缓存到SGA中的sharedpool;
4. 执行执行计划,首先会去SGA中的database buffer cache(存储数据块,是oracle进行操作的最小单位)找数据,没有的话从底层datafile中取数据并放入SGA中,便于后续复用;
5. 最后取到数据返回给client
会话查询及死锁查询
在 Oracle 系统中能自动发现死锁,并选择代价最小的,即完成工作量最少的事务予以撤消,释放该事务所拥有的全部锁
-- 查出锁住该表的会话id,serial#
SELECT o.object_name,s.sid, s.serial#
FROM v$locked_object l, dba_objects o, v$session s
WHERE l.object_id = o.object_id
AND l.session_id = s.sid
AND o.object_name='SJ_AFFAIR'
--查询除了用户的,还包括系统内的对象
SELECT o.object_name,s.sid, s.serial#
FROM v$lock l, dba_objects o, v$session s
WHERE l.id1 = o.object_id
AND l.SID = s.sid
--删除掉被锁住的会话
alter system kill session 'sid, serial#';
查询后oracle清除缓存
性能测试的时候,遇到第一次读取数据库很慢,以后几次都瞬间读取完成。 应该是Oracle缓存的作用,第一次读完以后放入缓存,以后读取就很快了。
ALTER SYSTEM FLUSH SHARED_POOL
ALTER SYSTEM FLUSH BUFFER_CACHE
ALTER SYSTEM FLUSH GLOBAL CONTEXT
sql中关键字的执行顺序
FROM
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
UNION
ORDER BY
常接触的对象
表、视图、索引;物化视图、触发器、存储过程、函数、DBLink;分区表;
table和index
-- 在要统计的时候来一次同步,调producer
begin dbms_stats.gather_table_stats(OWNNAME =>'CSID', TABNAME => 'dba_extents',METHOD_OPT => 'FOR ALL');
end;
--查看所有的对象
select t.OWNER, t.OBJECT_NAME, t.OBJECT_TYPE, t.status
from dba_objects t
where t.OWNER = 'GTJAKH'
and t.OBJECT_TYPE = 'TABLE'
--table
select t.TABLE_NAME,
t.NUM_ROWS,--表记录数
t.BLOCKS, --高水平线下的数据块个数
t.EMPTY_BLOCKS,
t.AVG_SPACE,
t.CHAIN_CNT,
t.AVG_ROW_LEN--行平均长度
from user_tables t
where t.table_name = 'NRNG_NEWMATCH';
--查看表中index
select t.index_name,
t.num_rows,-- 索引行
t.leaf_blocks,--索引叶块数
t.distinct_keys,--索引不同键数
t.blevel,--btree深度
t.avg_leaf_blocks_per_key,--
t.avg_data_blocks_per_key,
t.clustering_factor--索引的聚簇因子,标识表中存储数据顺序和索引字段顺序的符合程度
from user_indexes t
where t.table_name = 'LOG_KHYW_BUSI_HISTORY'
and t.index_name = 'INDEX_KHYWHIST3_CREATTIME';
--或者查询整个dba的dba_tables、dba_indexes
高水位线(HWM) 随着表记录增多,存储块也增多,HWM也会升高;但删除数据(delete,truncate不会)不会导致HWM降低,这样全包扫描时,从头一直读到HWM线,会很耗时;所以需要table move操作,以回收空间提高查询效率;(以此衡量table是否要重构)
索引的聚簇因子clustering_factor,标识表中存储数据顺序和索引字段顺序的符合程度;值越接近表块BLOCKS个数,性能越好,越接近表行数NUM_ROWS,性能越差(以此衡量索引的有效程度)
索引类型:
1. B树索引,normal
创建B-tree索引,即构建一个相同深度的二叉树,索引值存储在叶子节点--双向链表;
适用于非稀疏值的列;精确查找、范围查找、模糊查找等
多级索引/级联索引,慎选第一列(第1列会被解析器作为索引使用)
2. 函数索引
针对函数的,只能是单行返回的;具体值使用normal或者bitmap则由系统确定
3. 位图索引,bitmap
适用于稀疏值的索引,即对每个值创建一个所有记录的位数组,0和1代表是否存在;命中时,根据begin rowid和end rowid和偏移量计算出记录的rowid
位图索引不适合并发环境,在并发环境下可能会造成大量事务的阻塞
不能在分区表上创建global位图索引,因为对分区表而言,每个分区的物理存储分开
5. 唯一索引,unique
主键时默认创建的索引,使用B树结构
oracle中index的unusable,usable ,disable,enable
--如果出现unusable的话,需要进行重建
alter index index_name rebuild;
drop index index_name;
create index index_name on xxxxx;
--enable和disable仅仅只针对函数索引
alter index index_name enable;
alter index index_name disable;
Procedure存储过程
封装连续的动作,手动控制事务,且处理异常
会预编译,效率较高
plsql提供组件进行调试/测试
function函数
函数相比存储过程可以return值,并在select中直接调用
解决嵌套查询两级以上不能使用最外层值的问题=》直接传递外部值为参数
materialized view 物化视图
与一般视图的区别:查询已经执行并将结果集存入了一张表中,好处是预先计算了查询结果并且在特定查询执行的时候可以直接调取该结果。
适用于查询汇总的,考虑到速度的
占用存储空间,并且可以设置索引,物理存储为segment
``sql
--查看快照/物化视图的刷新时间
select * from ALL_SNAPSHOT_REFRESH_TIMES;
--物化视图
select * from dba_snapshots;
--日志物化视图
select * from dba_snapshot_logs;
--删除
drop snapshot log on cust_info;
create snapshot log on cust_info;
#### 触发器trigger
> 触发器类似过程和函数,都有声明、执行和异常处理过程的PL/SQL块;
> 触发器是由一个事件来启动运行,触发器不能接收参数
### 常用的sql操作
> rownum和rowid;merge;窗口函数、行列互换、操作父子数据;
### 执行计划
> oracle生成执行计划基于两种方式:
> 1、RBO基于规则(根据oracle确定的具有优先级的规则来计算,可以手动指定);
> 2、CBO基于成本(oracle目前采用,默认where语句之间独立)
> 数据库优化器的目标:产生让SQL执行总成本最低的执行计划(CBO, cost based optimizer,基于成本)
> 成本:(根据对象(表、索引、列)的统计信息计算出访问成本)时间成本+从磁盘访问1个数据块的成本
#### 常见执行计划:
1\. TABLE ACCESS FULL 对于表小时有优势
2\. INDEX UNIQUE SCAN 等值查询index(分层定位)
3\. INDEX RANGE SCAN 范围查询,针对叶子节点(有序、双向链表)
4\. INDEX FAST FULL SCAN
1、index比原table小;2、index是按块访问=》若要查询非index的字段,则按rowid进行**回表操作**;
cost=索引高度(0~4,索引的特点决定大数据量表的查找不是问题)+回表(0~1)+聚集系数
回表操作,考虑index表和table的聚集情况,按照table的特点,如时间,可对index进行排序后再回表操作
5\. INDEX FULL SCAN
绝大多数情况下,index fast full scan性能优于index full scan,但前者在有order by时,一定会存在对读取的块重新排序的过程
rowid扫描 oracle定位单行数据最快的方式
- TABLE ACCESS BY USER ROWID 直接根据rowid值获取
- TABLE ACCESS BY INDEX ROWID 先根据index获取rowid,再根据rowid获取
6\. NESTED LOOPS
COST ≈驱动表访问成本+驱动表返回记录数*内部表访问成本
7\. HASH JOIN
探测成本受驱动表返回结果集影响,有3种情行:
1、结果集可放到内存,探测成本可忽略
2、One pass,不能一次性放到内存,探测成本≈驱动表返回结果集写入与读取成本+探测表返回结果集写入与读取成本
3、Multi pass,`探测成本≈驱动表返回结果集写入与读取成本+探测表返回结果集(写入成本+读取成本*次数)`
8\. MEGER JOIN
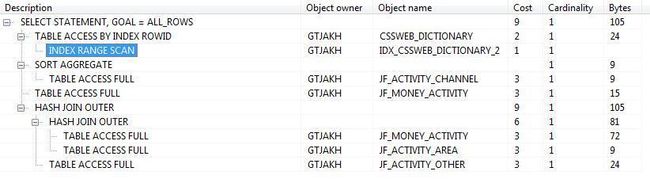
#### 执行计划结果分析
> 顺序:从上往下,从左往右,直到叶子节点;执行结果不断上移到父节点
```sql
SELECT T.ID activityId,
T.ACTIVITY_NAME ACTIVITYNAME,
T.ACTIVITY_NO ACTIVITYNO,
T.BONUS_RULE bonusRule,
(SELECT T2.KEY_DESC
FROM CSSWEB_DICTIONARY T2
WHERE T2.PARENT_ID = 90
AND T1.PROVINCE_ID = T2.KEY_CODE) PROVINCENAME,
(SELECT TO_CHAR(WM_CONCAT(C.CHANNEL_CODE))
FROM JF_ACTIVITY_CHANNEL C
WHERE C.JF_ACTIVITY_ID = T.ID) CHANNELCODE,
T1.PROVINCE_ID PROVINCEID,
T.ACTIVITY_STATUS ACTIVITYSTATUS,
TO_CHAR(T.BEGIN_TIME, 'yyyy-MM-dd') BEGINTIME,
TO_CHAR(T.END_TIME, 'yyyy-MM-dd') ENDTIME,
T.ACTIVITY_TOTAL_AMOUNT TOTALAMOUNT,
T.ACTIVITY_TYPE ACTIVITYTYPE,
TO_CHAR(T.JF_OVERDUE_DATE, 'yyyy-MM-dd') JFOVERDUEDATE,
NVL(T.JF_TOTAL_FLAG,1) JFTOTALFLAG,
T.JF_TOTAL JFTOTAL,
NVL(O.HLWCT, 0) HLWCT,
NVL(O.ZYTG, 0) ZYTG,
O.TGDZ,
NVL(O.TGGX, 0) TGGX,
NVL(O.CZHF, 0) CZHF,
T.SYN_BUSI_FLAG AS synBusiFlag ,
case when t.parent_id=0 then to_char(t.parent_id) else (select tt.activity_name from JF_MONEY_ACTIVITY tt where tt.id=t.parent_id) end as parentName
FROM JF_MONEY_ACTIVITY T
LEFT JOIN JF_ACTIVITY_AREA T1
ON T.ID = T1.JF_ACTIVITY_ID
LEFT JOIN JF_ACTIVITY_OTHER O
ON O.JF_ACTIVITY_ID = T.ID
WHERE T.ID ='894'
索引及优化
索引效率不高
原因:建立的字段如果经常增删改,或者按需求清楚历史数据,但删除记录对应的表和索引里占用的数据块空间并没有释放
解决:
-
-
alter table tbl move;可以释放已删除记录表占用的数据块空间,整理碎片
-
-
-
alter index idx_tbl_col rebuild;重建索引可以释放已删除记录索引占用的数据块空间。重建索引不仅能增加索引表空间空闲空间大小,还能够提高查询性能
-
-
-
alter index idx_tbl_col rebuild online;加online,可以防止rebuild会阻塞一切DML操作
-
强制指定索引:
一张表上创建了非常多的索引(不推荐),每一个索引都是针对特定业务查询而增加的。这极易导致SQL由于个别索引的引入出现性能问题。自己的sql可能命中其中的索引,但不是自己想要的,则使用Hint的方法实现强制SQL不走特定索引或强制使用
--使用hint强制使用或者不使用
select /*+ NO_INDEX(t t_idx1) */ object_name from t where object_name = 'T'
索引失效:
1、<>
2、单独的>,<
3、like "%_" 百分号在前
4、单独引用复合索引里非第一位置的索引列
5、字符型字段为数字时在where条件里不添加引号,或者merge中的on条件=》主要问题,数据库之间或者表之间的字段类型不一致,常用是number和char之间的比较
6、对索引列进行运算.需要建立函数索引
7、not in ,not exist
8、当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况
9、索引失效
10、基于cost成本分析(oracle因为走全表成本会更小):查询小表,或者返回值大概在10%以上;会优化走table access full
11、有时都考虑到了 但就是不走索引;可能index效率不高,需要重建
12、B-tree索引 is null不会走,is not null会走;位图索引 is null,is not null 都会走
13、联合索引 is not null 只要在建立的索引列(不分先后)都会走;is null时,其它索引列都要涉及