吴恩达机器学习-7-支持向量机SVM
公众号:尤而小屋
作者:Peter
编辑:Peter
吴恩达机器学习-7-支持向量机SVM
本周主要是讲解了支持向量机SVM的相关知识点
- 硬间隔
- 支持向量
- 软间隔
- 对偶问题
优化目标Optimization Objectives
主要是讲解如何从逻辑回归慢慢的推导出本质上的支持向量机。逻辑回归的假设形式:

- 左边是假设函数
- 右边是
Sigmoid激活函数
令 z = θ T x z={\theta}^{T}x z=θTx,如果满足:
- 若 y = 1 y=1 y=1,希望 h ( θ ) h{(\theta)} h(θ)约为1,将样本正确分类,那么z必须满足 z > > 0 z>>0 z>>0
- 若 y = 0 y=0 y=0,希望 h ( θ ) h(\theta) h(θ)约为0,将样本正确分类,那么z必须满足 z < < 0 z<<0 z<<0
样本正确分类指的是:假设函数h(x)得到的结果和真实值y是一致的
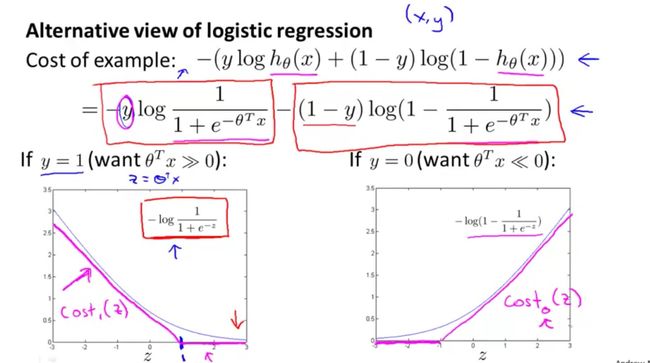
总代价函数通常是对所有的训练样本进行求和,并且每个样本都会为总代价函数增加上式的最后一项(还有个系数 1 m \frac{1}{m} m1,系数忽略掉)
如果 y = 1 y=1 y=1,目标函数中只有第一项起作用,得到了表达式 :
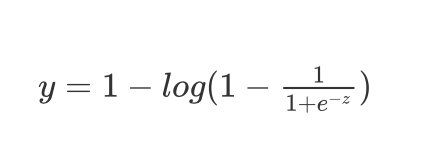
y = 1 − l o g ( 1 − 1 1 + e − z ) y=1-log(1-\frac{1}{1+e^{-z}}) y=1−log(1−1+e−z1)
支持向量机
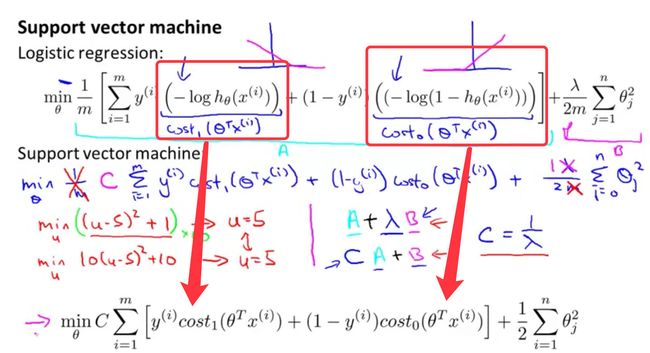
根据逻辑回归推导得到的支持向量机的公式 :
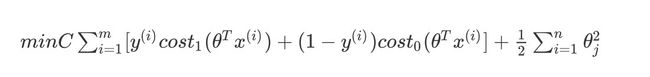
m i n C ∑ i = 1 m [ y ( i ) c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T x ( i ) ] + 1 2 ∑ i = 1 n θ j 2 min C\sum^m_{i=1}[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)}]+\frac{1}{2}\sum^n_{i=1}\theta_{j}^2 minCi=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i)]+21i=1∑nθj2
两个cost函数是上面提到的两条直线。对于逻辑回归,在目标函数中有两项:
- 第一个是训练样本的代价
- 第二个是正则化项
大边界的直观解释
下面是支持向量机的代价函数模型。

SVM决策边界

SVM鲁棒性:间隔最大化,是一种大间距分类器。
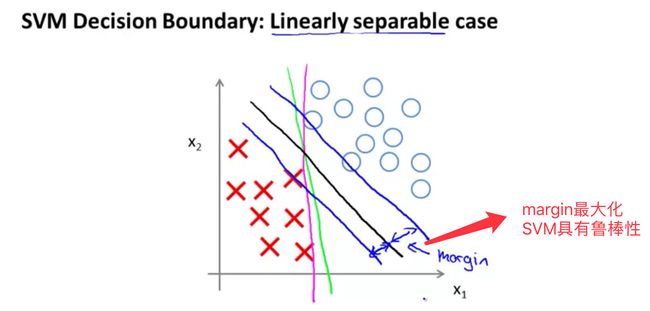
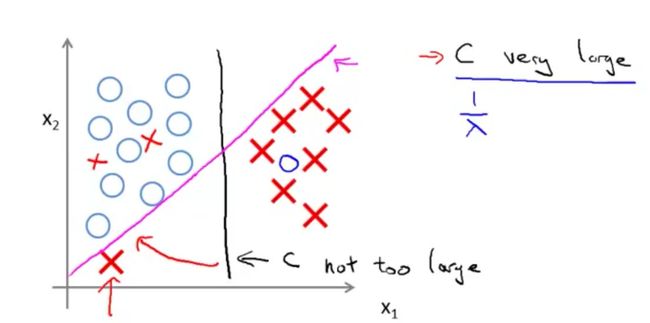
关于上图的解释:
C太大的话,将是粉色的线C不是过大的话,将是黑色的线
大间距分类器的描述,仅仅是从直观上给出了正则化参数C非常大的情形,C的作用类似于之前使用过的正则化参数 1 λ \frac{1}{\lambda} λ1
C较大,可能导致过拟合,高方差C较小,可能导致低拟合,高偏差
硬间隔模型
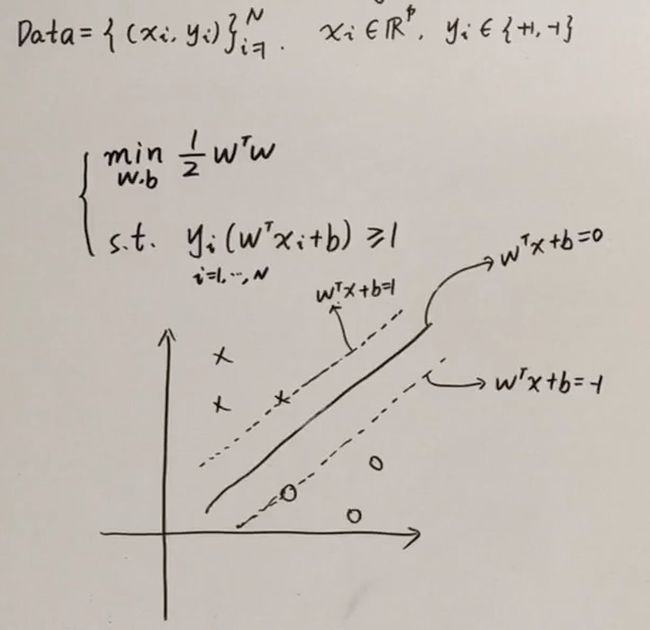
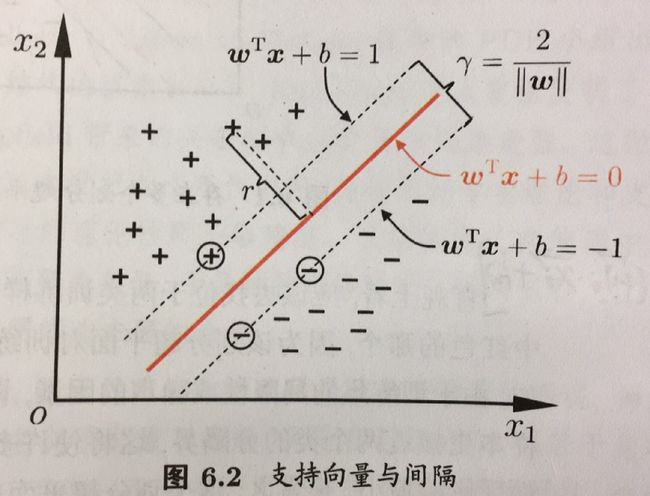
间隔和支持向量
注释:本文中全部采用列向量:
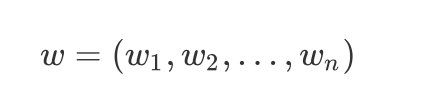
w = ( w 1 , w 2 , … , w n ) w=(w_1,w_2,…,w_n) w=(w1,w2,…,wn)
给定一个样本训练集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) D={(x_1,y_1),(x_2,y_2),…,(x_m,y_m)} D=(x1,y1),(x2,y2),…,(xm,ym),其中 y i ∈ ( − 1 , + 1 ) y_i \in {(-1,+1)} yi∈(−1,+1)
分类学习的基本思想就是:基于训练集D在样本空间上找到一个划分的超平面
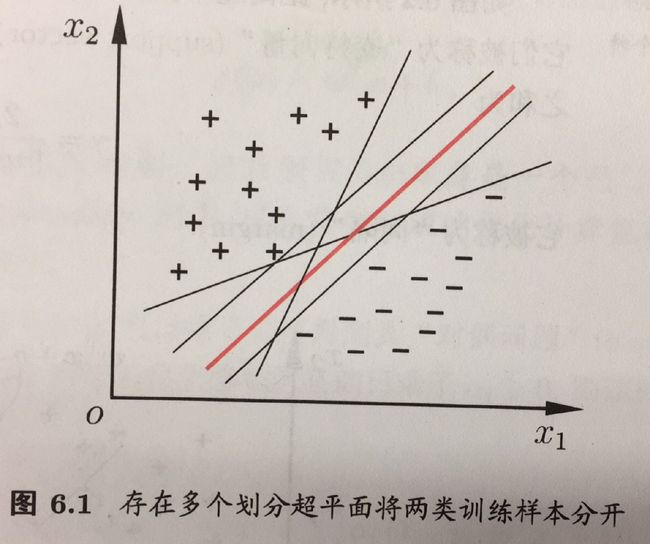
上面红色的线是最好的。所产生的分类结果是最鲁棒的,最稳定的,泛化能力是最好的。
划分超平面的的线性描述: w ⋅ x + b = 0 {w\cdot x+b=0} w⋅x+b=0
W称之为法向量(看做是列向量),决定平面的方向;b是位移项,决定了超平面和原点之间的距离。
空间中任意一点x到超平面(w,b)的距离是:
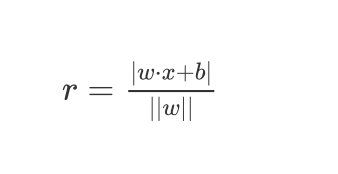
r = ∣ w ⋅ x + b ∣ ∣ ∣ w ∣ ∣ r=\frac{|w \cdot x + b|}{||w||} r=∣∣w∣∣∣w⋅x+b∣
在 + + +区域的点满足 y = + 1 y=+1 y=+1:
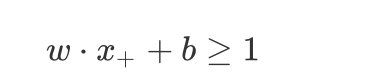
w ⋅ x + + b ≥ 1 w \cdot {x_+} + b \geq1 w⋅x++b≥1
在 − - −区域的点满足 y = − 1 y=-1 y=−1:
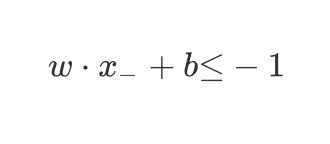
w ⋅ x − + b ≤ − 1 w \cdot {x_-} + b {\leq}-1 w⋅x−+b≤−1
综合上面的两个式子有:
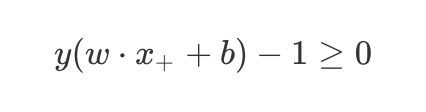
y ( w ⋅ x + + b ) − 1 ≥ 0 y(w \cdot {x_+} + b )-1 \geq0 y(w⋅x++b)−1≥0
支持向量
距离超平面最近的几个点(带上圆圈的几个点)称之为支持向量support vector,这个点到超平面到距离称之为间隔margin
刚好在决策边界上的点(下图中带上圆圈的点)满足上式中的等号成立:
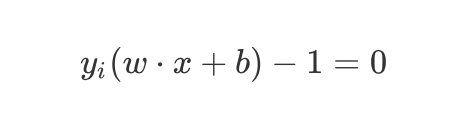
y i ( w ⋅ x + b ) − 1 = 0 y_i(w \cdot x + b) -1=0 yi(w⋅x+b)−1=0
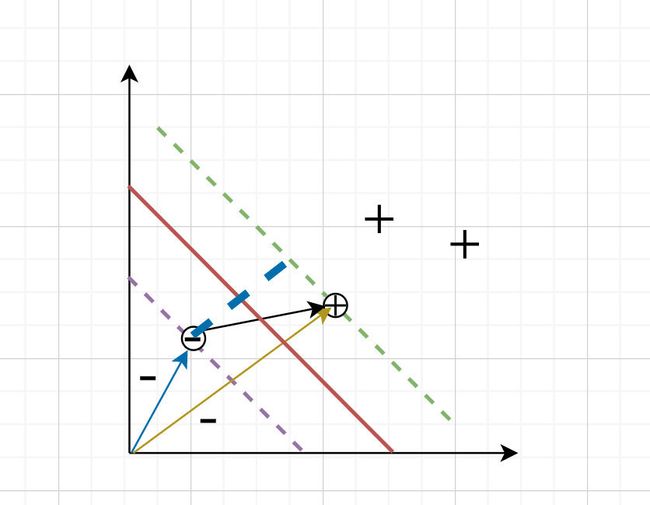
间距margin
求解间距margin就是求解向量 ( x + − x − ) {({x_+}-{x_-})} (x+−x−)在法向量上的投影
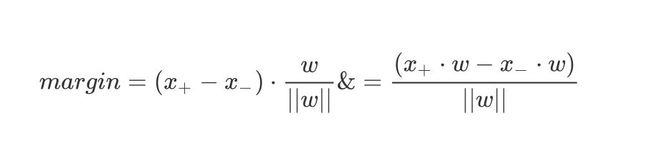
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲margin& = (x_+-…
决策边界上的正例表示为:
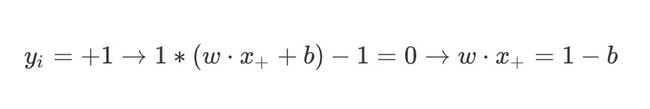
y i = + 1 → 1 ∗ ( w ⋅ x + + b ) − 1 = 0 → w ⋅ x + = 1 − b y_i=+1 \rightarrow 1*(w\cdot x_+ +b) - 1 =0 \rightarrow w\cdot x_+ =1-b yi=+1→1∗(w⋅x++b)−1=0→w⋅x+=1−b
决策边界行的负例表示为:
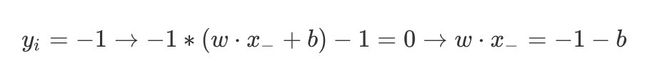
y i = − 1 → − 1 ∗ ( w ⋅ x − + b ) − 1 = 0 → w ⋅ x − = − 1 − b y_i=-1 \rightarrow -1*(w\cdot x_- +b) - 1 =0 \rightarrow w\cdot x_- =-1-b yi=−1→−1∗(w⋅x−+b)−1=0→w⋅x−=−1−b
将两个结果带入margin 的表达式中:
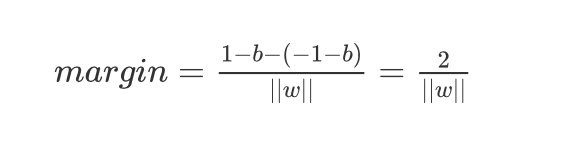
m a r g i n = 1 − b − ( − 1 − b ) ∣ ∣ w ∣ ∣ = 2 ∣ ∣ w ∣ ∣ margin=\frac {1-b-(-1-b)}{||w||}=\frac{2}{||w||} margin=∣∣w∣∣1−b−(−1−b)=∣∣w∣∣2
SVM的基本模型
最大间隔化只需要将 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣最小化即可:
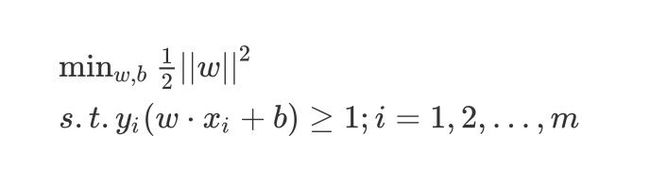
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w ⋅ x i + b ) ≥ 1 ; i = 1 , 2 , . . . , m \min_{w,b}\frac{1}{2}||w||^2 \\s.t. y_i(w\cdot x_i+b) \geq 1 ;i=1,2,...,m w,bmin21∣∣w∣∣2s.t.yi(w⋅xi+b)≥1;i=1,2,...,m
SVM-对偶模型
模型参数推导
希望求解上面基本模型对应超平面的模型:
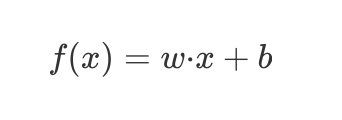
$f(x)= {w}{\cdot} {x}+{b} $
利用拉格朗日乘子 α i \alpha_i αi,改成拉格朗日函数:
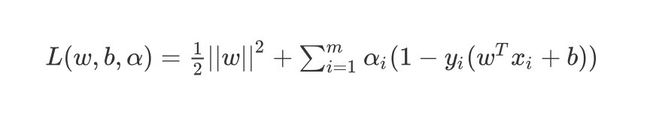
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) L(w,b,\alpha)=\frac{1}{2}||w||^2+\sum^m_{i=1}\alpha_i(1-y_i(w^Tx_i+b)) L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))
分别对 w , b w,b w,b求导,可以得到:

w = ∑ i = 1 m α i y i x i 0 = ∑ i = 1 m α i y i w = \sum^m_{i=1}\alpha_iy_ix_i \ 0 = \sum^m_{i=1}\alpha_iy_i w=i=1∑mαiyixi 0=i=1∑mαiyi
对偶模型
原始问题是极大转成最大值问题:
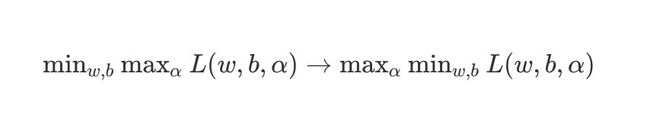
min w , b max α L ( w , b , α ) → max α min w , b L ( w , b , α ) \min_{w,b}\max_{\alpha}L(w,b,\alpha)\rightarrow\max_{\alpha}\min_{w,b}L(w,b,\alpha) w,bminαmaxL(w,b,α)→αmaxw,bminL(w,b,α)
带入拉格朗日函数中,得到对偶问题(全部是关于 α \alpha α系数):
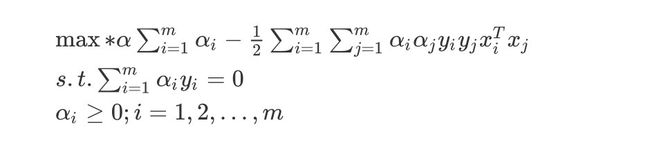
max ∗ α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 α i ≥ 0 ; i = 1 , 2 , . . . , m \max *{\alpha}\sum^m_{i=1}\alpha_i-\frac{1}{2}\sum^m_{i=1}\sum^m_{j=1}\alpha_i\alpha_jy_i y_jx_i^Tx_j \\s.t. \sum^m_{i=1}{\alpha}_i{y_i}=0 \\{\alpha}_{i} \geq0;i=1,2,...,m max∗αi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t.i=1∑mαiyi=0αi≥0;i=1,2,...,m
转换一下,变成最小值问题(上面的式子加上负号):
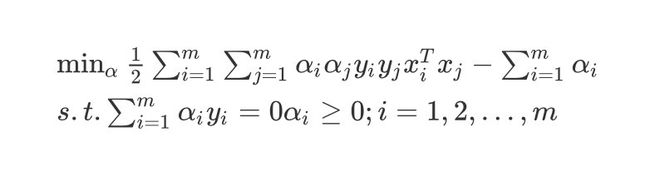
min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j − ∑ i = 1 m α i s . t . ∑ i = 1 m α i y i = 0 α i ≥ 0 ; i = 1 , 2 , . . . , m \min _{\alpha}\frac{1}{2}\sum^m_{i=1}\sum^m_{j=1}\alpha_i\alpha_jy_i y_jx_i^Tx_j - \sum^m_{i=1}\alpha_i\\s.t. \sum^m_{i=1}\alpha_iy_i=0 \alpha_i \geq0;i=1,2,...,m αmin21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαis.t.i=1∑mαiyi=0αi≥0;i=1,2,...,m
那么超平面的模型 :
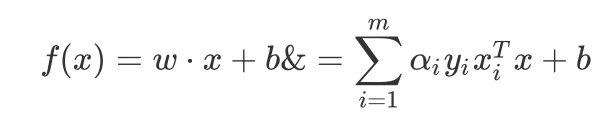
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲f(x)& = w\cdot …
SMO算法
思想
SMO算法指的是Sequential Minimal Optimization,序列最小优化算法。算法的根本思路是:
所有的 α \alpha α满足:
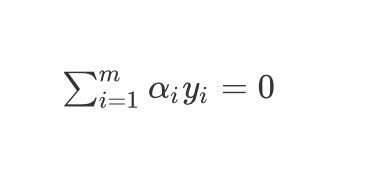
∑ i = 1 m α i y i = 0 \sum^m_{i=1}\alpha_iy_i=0 i=1∑mαiyi=0
-
先选取需要更新的变量 α i \alpha_i αi和 α j \alpha_j αj
-
固定变量 α i \alpha_i αi和 α j \alpha_j αj以外的参数,求解更新后的变量 α i \alpha_i αi和 α j \alpha_j αj
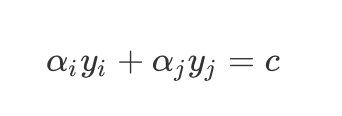
α i y i + α j y j = c {\alpha_i}{y_i}+{\alpha_j}{y_j}=c αiyi+αjyj=c
其中 c c c使得上式成立:
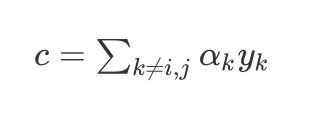
c = ∑ k ≠ i , j α k y k c= \sum_{k \neq i,j}\alpha_ky_k c=k=i,j∑αkyk
- 将变量 α i \alpha_i αi和 α j \alpha_j αj的其中一个用另一个来表示,得到关于 α i \alpha_i αi的单变量二次规划问题,就可以求出来变量 α i \alpha_i αi
软间隔最大化
上面的结论和推导都是针对的线性可分的数据。线性不可分数据意味着某些样本点 ( x i , y i ) (x_i,y_i) (xi,yi)不再满足函数间隔大于等于1的约束条件,比如下图中的红圈中的点,故引入了松弛变量 ξ i ≥ 0 \xi_i \geq0 ξi≥0,满足:
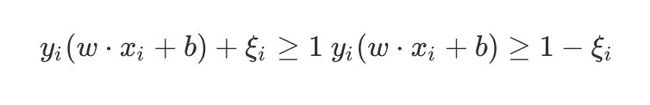
y i ( w ⋅ x i + b ) + ξ i ≥ 1 y i ( w ⋅ x i + b ) ≥ 1 − ξ i y_i(w \cdot x_i +b) +\xi_i \geq 1 \ y_i(w \cdot x_i +b) \geq 1-\xi_i yi(w⋅xi+b)+ξi≥1 yi(w⋅xi+b)≥1−ξi
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E0z0eMB7-1621474305132)(https://tva1.sinaimg.cn/large/0081Kckwgy1gkemu1fe7rj30xc0noww9.jpg)]
因此,目标函数由原来的 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}{||w||^2} 21∣∣w∣∣2变成了:
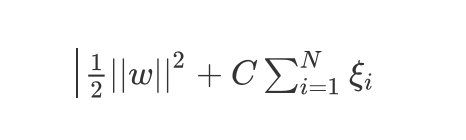
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||^2+C\sum^N_{i=1}\xi _i 21∣∣w∣∣2+Ci=1∑Nξi
其中 C ≥ 0 C\geq0 C≥0是惩罚项参数,C值越大对误分类的越大,C越小对误分类的惩罚越小。