不调包绘制音频语谱图并批量生成语谱图
什么是语谱图
语谱图(Spectrogam)是表示语音频谱随时间变化的图形,其实是一个二维的图像,但却能表示三个维度的信息,横坐标表示时间,纵坐标表示频率,颜色的深浅来映射能量的大小。任一给定频率成分在给定时刻的强弱用相应点的灰度或色调的浓淡来表示。颜色深,表示该点的语音能量越强,反之表示该点语音能量较弱。
绘制语谱图首先需要对载入的音频进行分帧和加窗处理,然后进行傅里叶变化,然后求出每一帧所对应的时间刻度,然后再将傅里叶变换后的数据取对数求出能量密度谱,将能量与颜色做一个映射,然后画出图像

分帧
语音信号是一个准稳态的信号,若把它分成较短的帧,每帧中可将其看做稳态信号,可用处理稳态信号的方法来处理。为了使一帧与另一帧之间的参数能够平稳过渡,应在相邻两帧之间互相有部分重叠。一般情况下,帧长取10 ~ 30ms,所以每秒的帧数约为33 ~ 100帧。帧移与帧长的比值一般取0~1/2。其中设每帧长度为win,后一帧对前一帧的位移量为inc。
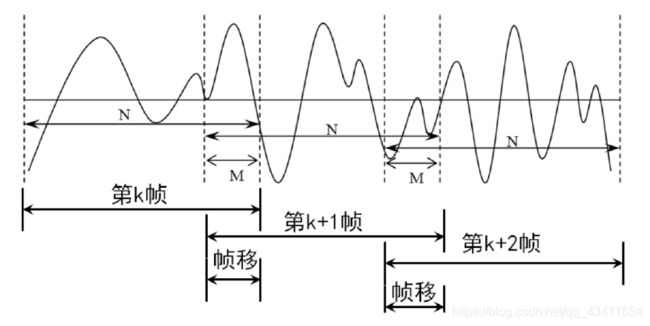
因此设计分帧函数就是在函数名中给三个参数,enframe(x, win, inc),其中x为加载的音频数据,win为帧长,inc为帧移,返回值为分帧后的数据。
代码如下:
#分帧函数
def enframe(x, win, inc=None):
'''
:param x: 音频数据
:param win: 帧长
:param inc: 帧移
:return: 分帧后的列表
'''
nx = len(x)# 获取音频的长度
if isinstance(win, list) or isinstance(win, np.ndarray):# 判断win是否为窗函数
nwin = len(win)
nlen = nwin # 帧长=窗长
elif isinstance(win, int):# 说明没有窗函数,将帧长设置为1
nwin = 1
nlen = win # 设置为帧长
if inc is None:# 帧移不为空则传给nlen
inc = nlen
nf = (nx - nlen + inc) // inc# 算出有多少帧
frameout = np.zeros((nf, nlen))# 填充一个零矩阵出来,行为帧,列为帧数据
indf = np.multiply(inc, np.array([i for i in range(nf)])) # 设置每帧在x中的位移量位置
for i in range(nf):# 将数据分帧存在frameout中
frameout[i, :] = x[indf[i]:indf[i] + nlen]
return frameout
加窗
在语音处理中,经常可以听到对语音进行分帧和加窗的操作,那加窗到底是什么,为什么要加窗呢?语音信号是一种非平稳的时变信号,要进行FFT或其他针对平稳信号而进行的信号处理时就十分困难。加窗和分帧就类似与高等数学中求积分一样,将曲线分成无限个小格,每个格就可以等似为矩形。在语音处理中也是这样,通过分帧和加窗可以把语音信号在一帧内看作是短时平稳的,加窗其实就是对分帧后的每一帧数据 s ( n ) s(n) s(n)分别乘上窗数据 w ( n ) w(n) w(n),从而形成加窗语音信号 s w ( n ) = s ( n ) ∗ w ( n ) s_w(n)=s(n) \ast w(n) sw(n)=s(n)∗w(n)。常见的窗函数有矩形窗、海宁窗、汉明窗。
矩形窗的函数表达式为:
w ( n ) = { 1 , 0 < = n < L − 1 0 , 其他 w(n)=\left\{\begin{array}{ll} 1, & 0<=n
海宁窗的表达式为:
w ( n ) = { 0.5 ( 1 − cos ( 2 π n / ( L − 1 ) ) , 0 < = n < L − 1 0 , 其他 w(n)=\left\{\begin{array}{ll} 0.5(1 - \cos (2 \pi n /(L-1)) , & 0<=n
汉明窗的表达式为:
w ( n ) = { 0.54 − 0.46 cos ( 2 π n / ( L − 1 ) ) , 0 < = n < L − 1 0 , 其他 w(n)=\left\{\begin{array}{ll} 0.54-0.46 \cos (2 \pi n /(L-1)), & 0<=n
代码如下所示:
#加窗
def hanning(N):
'''
:param N: 窗长度
:return: 窗数据
'''
len = [i for i in range(N)]
w = 0.5 * (1 - np.cos(np.multiply(len, 2 * np.pi) / (N - 1)))
return w
def rectangular(N):
'''
:param N: 窗长度
:return: 窗数据
'''
len = [i for i in range(N)]
w = np.ones(N)
return w
def hamming(N):
'''
:param N: 窗长度
:return: 窗数据
'''
len = [i for i in range(N)]
w = 0.54 - 0.46 * np.cos(np.multiply(len, 2 * np.pi) / (N - 1))
return w
短时傅里叶变换
分帧和加窗之后再进行傅里叶变换就称作短时傅里叶变换,先将加窗后的数据进行转置,再调用fft()函数进行快速傅里叶变换,从而达到所需要的效果。
代码如下所示:
#短时傅里叶变换
def STFFT(x, nfft):
'''
:param x: 需要fft变换的数据
:param win: 窗长
:param nfft: fft点数
:param inc: 帧移
:return: fft后的数据
'''
x = x.T#进行转置
y = np.fft.fft(x, nfft, axis=0)#进行点数为nfft的fft变换
return y[:nfft // 2, :]
生成语谱图
在进行完以上步骤后,我们还需要算出频率刻度,算出每一帧所对应的时间,再将傅里叶变换后的数据进行求取对数,调用pcolormesh()函数将三个维度的数据进行映射,从而可以用颜色来表示能量的强弱。
代码如下所示:
#绘制语谱图
#计算每帧对应的时间
def frametime(frameNum, frameLen, inc, fs):
'''
:param frameNum: 帧数值
:param frameLen: 帧长度
:param inc: 帧移
:param fs: 采样率
:return:
'''
ll = np.array([i for i in range(frameNum)])
return ((ll - 1) * inc + frameLen / 2) / fs
def spectrogram(filepath, wlen, inc, nfft, windows):
'''
:param filepath: 音频文件路径
:param wlen: 窗长度
:param inc: 帧移
:param nfft: fft点数
:param win: 窗口类型
:return:
'''
data, fs = librosa.load(filepath, sr=None, mono=False) # sr=None声音保持原采样频率, mono=False声音保持原通道数
# 分帧
xn = enframe(data, wlen, inc)
# 加窗
if windows == "hanning":
win = hanning(wlen)
elif windows == "hamming":
win = hamming(wlen)
elif windows == "rectangular":
win = rectangular(wlen)
xn = xn * win
# 短时傅里叶变换
y = STFFT(xn, nfft)
fre_scale = [i * fs / wlen for i in range(wlen // 2)] # 频率刻度
frameTime = frametime(y.shape[1], wlen, inc, fs) # 每帧对应的时间
abs_y = np.abs(y)
spe_data = 10 * np.log10((abs_y * abs_y)) # 取对数后的数据
plt.pcolormesh(frameTime, fre_scale, spe_data)
plt.ylabel('Frequency')
plt.xlabel('Time(s)')
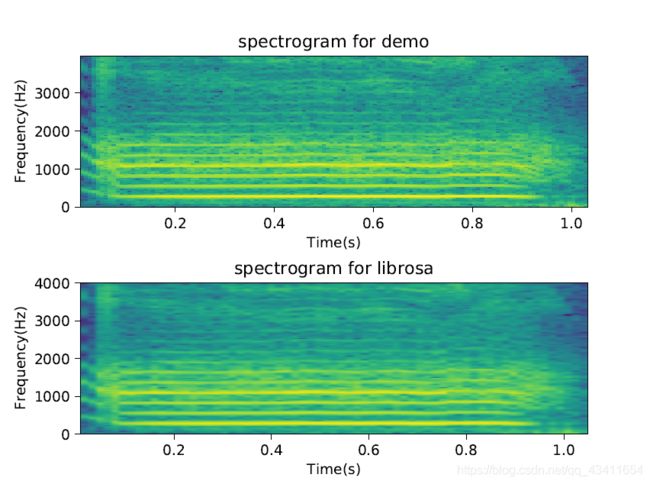
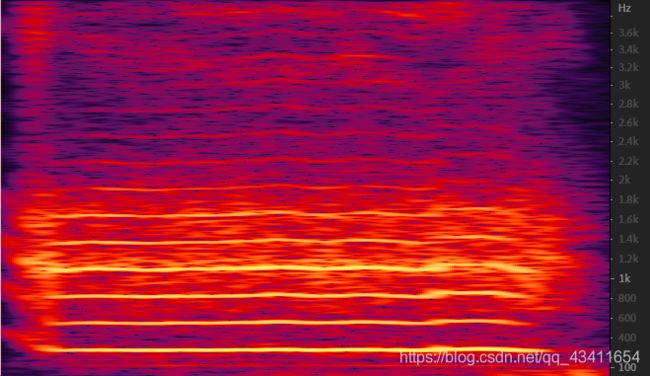
这样语谱图就绘制好了,将自己生成的语谱图和调用librosa绘制的语谱图进行对比,fft点数均为256,如图\ref{4}所示,在Audition中绘制出语谱图与之对比,所画出的语谱图基本一致。
批量生成语谱图
用Python自动生成语谱图显然比自己一个个改文件路径要快得多,因此设计一个批处理文件,首先在文件中输入音频所在的文件夹路径,输入生成语谱图所需保存的路径,程序就会从文件夹中识别出.wav文件,将其路径传递给spectrogram()的filename形参,这样就可以绘制出语谱图,再用savefig()函数将其以原音频名的格式保存为**.pdf的矢量格式图,也可以改为其他png或者jpeg格式。
代码如下所示:
import os
import matplotlib.pyplot as plt
import function as fun
wlen = 1024
inc = 128
nfft = wlen
filepath = "F:/audio/"#输入文件所在的录音
filepathout = "F:/audio/语谱图/"#语谱图输出路径
wavelist = []
filenames = os.listdir(filepath)
for filename in filenames:
name, category = os.path.splitext(filepath + filename) # 分解文件扩展名
if category == '.wav': # 若文件为wav音频文件
wavelist.append(filename)
names, cat = os.path.splitext(filename)
# print(names)
#以下部分是绘制语谱图
fun.spectrogram(filename, wlen, inc, nfft, windows="hanning")
plt.savefig(fname = filepathout + names + ".pdf")
plt.close()
print("图片" + names + "生成成功")