Panoptic Segmentation 论文阅读笔记与感想
Panoptic Segmentation
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, Piotr Dollár
论文地址
- 作者介绍

于2018年1月3日提交至arXiv,最新一次arXiv提交为2019年4月10日。
第一作者毕业于德国海德堡大学。
- Introduction
什么是things:countable objects such as people, animals, tools – received the dominant share of attention. 也就是那些可以进行计数的物体,比如人,动物,工具等。
什么是stuff:amorphous regions of similar texture or material such as grass, sky, road. 是不定形状的物体或者纹理,如草地、天空、道路。
语义分割:将图片中所有的像素分配一个语义类别的标签,关键之处在于将所有的things类别也当成stuff来对待。
实例分割:为了检测出场景中的每个目标,并且用bounding box和一个分割的mask来进行描述。
如下图所示:语义分割图像给出了场景中所有像素的类别标签,但是没有区分一个一个的实例;实例分割给出了场景中每个目标的分割和bounding box,但是没有针对背景中的stuff类别进行标记,两者都有局限性。而全景分割则是将这两者进行结合,既区分每个类别的个体,又标记了背景中的stuff类别。

看上去两者之间是有很自然的联系的,但是目前两个任务之间存在着巨大的差异,是什么导致了这些差异。语义分割基本上是以FCN为基础的模型,在中间加上了dilations。而实例分割则更多的是倾向于目标检测,常用方法是object proposals,主要是region-based。
那有没有一种方法是可以将他们之间的gap填平呢?在pre-deep-learning阶段,有人已经提出了很多关于这些方面的研究,当时的叫法有很多,如scene parsing, image parsing, holistic scene understanding等名称。但是当时没有提出一套完整的体系,也就是说没有一个大牛挖一个大坑让大家往里面跳。
于是现在大家要恰饭,要发paper,而语义分割刷点已经刷不太动了,Kaiming He赶快给大家挖一个新的,就是全景分割,Panoptic Segmentation。解决这个问题需要以下几个条件:首先,针对我们刚才提到的stuff和thing的问题,不能完全将其割裂开来(如SemSeg和InsSeg);其次,需要有一个统一的输出形式;最后,需要有一个统一的评价指标(这个最关键,如果还用之前的指标,就还是将全景分割作为了两个任务来完成)。
接下来就是简单的定义:全景分割就是将图像中每个像素都分配一个语义标签和实例标签(实例标签代表这个物体是场景中的第几个实例)。请注意,这里所说的是每个像素,所以那些stuff也是有实例标签的,场景中所有的stuff像素都属于同一个实例,不要认为stuff不可计数所以没有实例标签啊,不然后面没法进行下去的。
然后就是目前可以支持研究全景分割的数据集,有Cityscapes, ADE20k, Mapillary Vistas datasets, COCO(目前COCO还不知道公开没有),同时COCO和Mapillary Vistas datasets都在2018 ECCV上面有全景分割的比赛,只能说他们动作是真的快。
- 全景分割Format
下面是全景分割问题中规定:
给出L个类别的标签,由

进行编码,然后针对每个像素i,由
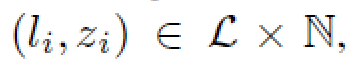
来进行描述。![]() 代表的是这个像素的instance id(在PFPN的论文中,作者说stuff类别的instance id是ignore了的,不知道究竟这个ignore代表的是有实际的值然后ignore掉了还是直接就不管什么值就统一ignore掉了)。
代表的是这个像素的instance id(在PFPN的论文中,作者说stuff类别的instance id是ignore了的,不知道究竟这个ignore代表的是有实际的值然后ignore掉了还是直接就不管什么值就统一ignore掉了)。
另外, ,其中
,其中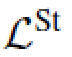 代表stuff类别,
代表stuff类别,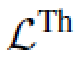 代表thing类别,那么,
代表thing类别,那么,  也就很好理解了,就是说他们互为补集。
也就很好理解了,就是说他们互为补集。
有了这些定义之后,一旦有两个像素的相同,那么就可以认为他们是同一个实例(这个时候也可以将stuff类别统一)。
- 全景分割评价指标Metric
之前也说过,语义分割和实例分割两者的评价指标都是特化的,无法互通,所以若想将两者融合在一起,必须要提出一个新的准则来衡量一个全景分割系统的优劣。而之前的的那些pre-deep-learning方法回避了这个问题,是分别用两套评价指标来评价性能。
那么,如果要定义一个评价准则,需要它具备什么性质呢?
完整性:同时评价stuff和thing的类别。
可解释性:能够解释和促进解决问题。(其实我感觉就是符合直觉,符合人类认知的就应该是好的)
简便性:这个评价准则应该是相对简单易于实现的。
首先给出了一个定理:给定一个预测图和一个GT图,那么针对于GT中每个实例,预测图中最多只有一个实例与它的IoU大于0.5。具体推导我就不给出来了,毕竟文章中写的非常简单清楚了,就是放缩了一下不等式。但是这个定理想告诉我们,不管是什么匹配方法(贪婪算法或者优化匹配),都能够得到唯一的匹配结果。我一开始一直不知道为什么非要先把这个写在前面,但是读了后面的就知道了,这个匹配定理真的是后面的基石。
接下来就是指标PQ,panoptic quality的定义了。
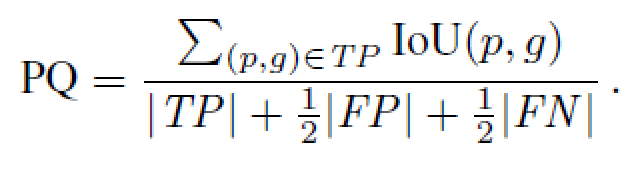
在具体说明公式含义之前,先要解释一下全景分割的TP,FP,FN等究竟是什么,作者给出了下图:
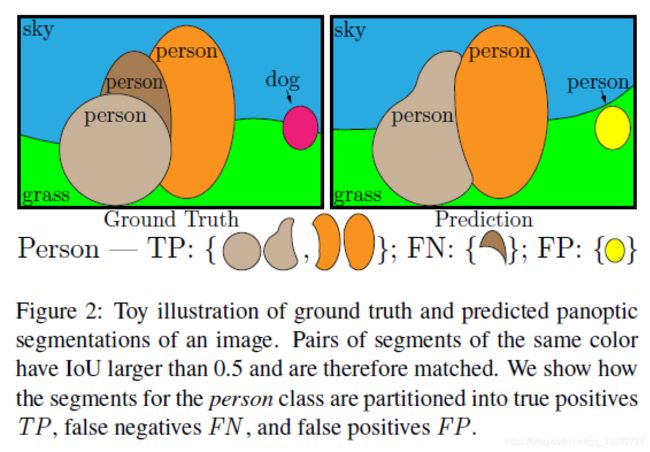
其中,IoU大于0.5的而且是正确的就是TP,IoU大于0.5但是类别错误的就是FP,GT中有、预测图中没有的部分就是FN。
然后看PQ的计算式,分子代表的是所有被认为是TP实例的IoU之和,分母则是TP,FP,FN的一个加权和。为什么要这么设计呢?
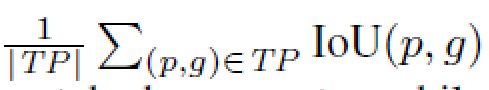 实际上就是针对所有匹配上了的实例的IoU取了一个均值。至于为什么要添加FP和FN呢?文章中说明了是为了惩罚FP和FN的出现。这里可能就会有一些疑问了,平白无故加了两项之后,那这个指标的上下界不会变化吗?后来仔细思考了一下,最差情况下,分子就是0,即PQ=0。没有匹配上的实例,最好情况下,所有实例都匹配上且IoU为1,正好等于分母前面|TP|,而后面的|FN|和|FP|都不存在,均为0,所以最好情况下PQ=1。
实际上就是针对所有匹配上了的实例的IoU取了一个均值。至于为什么要添加FP和FN呢?文章中说明了是为了惩罚FP和FN的出现。这里可能就会有一些疑问了,平白无故加了两项之后,那这个指标的上下界不会变化吗?后来仔细思考了一下,最差情况下,分子就是0,即PQ=0。没有匹配上的实例,最好情况下,所有实例都匹配上且IoU为1,正好等于分母前面|TP|,而后面的|FN|和|FP|都不存在,均为0,所以最好情况下PQ=1。
接下来就是变魔术了,将PQ的分子分母同时乘以|TP|,会得到这个表达式:
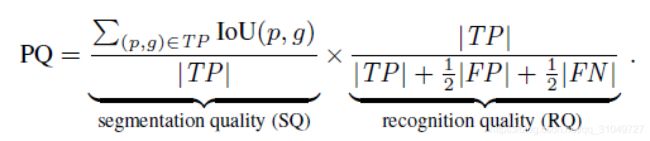
前面这个部分非常像语义分割里面的mIoU的定义,只不过稍微有所差别,因为语义分割中mIoU的指标计算的时候是不考虑匹配问题的,但是SQ是考虑了所有匹配上的实例来计算分子,也就是说分母相同分子不同。
后面这个RQ,其实很像F1指数,具体推导如下(字丑,重点看内容):

与现有度量方法比较的话已经在上面说的很清楚了,这里再简单提一下,就是说语义分割度量没办法衡量things的好坏,instance的度量无法衡量stuff的好坏,而panoptic的标准同时可以衡量stuff和things的好坏,同时考虑了两个方面,所以作者认为这样更为全面。
- 全景分割的数据库:
目前全景分割有三个成型的数据库:
Cityscapes:这个数据库支持语义分割和实例分割,很自然的也就转变成了全景分割的数据库。一共5000张图像,2975训练,500评估,1525测试。一共包含19类目标。也算是我用的最多的数据库了。
ADE20K:是从ImageNet中间挑选出来的大概25000张室内或室外数据,共包含150类,约20000张用作训练,2000张用于评估,3000张用于测试。特别一提,做这个数据的团队还在网上release了一个pytorch的语义分割框架,目前是star最多的pytorch语义分割框架。
Mapillary Vistas:这个数据很少人用,应该是才出来的新数据库。18000张用于训练,2000张用于评估,5000张用于测试。里面给的example主要是语义分割的example,标注质量应该说是非常不错,但是要获取的话需要发邮件,分为reasearch版本和商用版本,商用版本的话可能需要收费。
- 人类标注一致性研究:
之前读了三遍,一直都不懂从这里开始的部分,也没有查到关于这部分有博客进行讲解,最后无奈只能自己上了。一开始还在奇怪为什么要起名叫人类标注一致性研究(Human Consistency Study),后来发现这个起名还是非常贴切的。
FAIR小组找现有的三个数据集制作团队要到了针对于同一张图像的多张标注,然后以其中的一张作为GT,另外所有的照片作为prediction来计算指标(文中专门提到了因为匹配的唯一性,所以用哪一张其实都是一样的)。计算出的指标,当然是小于1的了,因为每张标注不可能完全一样,这个指标的大小就反映了多个人或者一个人针对同一张图像的标注一致性到底是怎样的,所以这也是为什么取名叫一致性研究的原因。
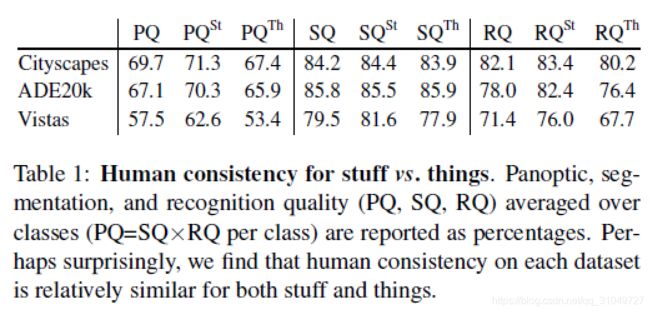
Stuff VS Things:下图是stuff和things的一致性比较结果。可以看到,针对Cityscape和Vistas的数据集,stuff的一致性都比较高,但是ADE20K数据集的话分割一致性是things比较高。我不负责任的觉得应该是因为数据集中的stuff和things的分布类别数量不一样,cityscape和vistas数据集是街景,stuff类别非常多,相比而言things就会少一些。而ADE20K重在室内场景多类别,things的类别非常多。所以我认为应该是因为分布不一样导致的。另外,RQ一般都偏低,可能还是匹配问题和标注难度的原因吧。
Scale对一致性的影响:差别还是很明显的,而且规律很简单,尺度越大的物体标注一致性越高,尺度越小标注一致性越低,这也比较好理解,大了谁都好确认边界,小的物体边界不好确认,一致性也就降低了。

至于类别,有很明显的趋势,就是占面积大的标签一致性就高,占面积小的或出现次数少的就低。

关于选取的0.5这个IoU阈值这上面,当然放松要求肯定PQ会更高,因为相当于增加了在其他部分变化一致的情况下,减少了FP和FN的量,自然PQ就上升了。增加这个阈值同理会降低PQ。

另外就是最后一个问题,之前我们计算RQ的时候,说过这个和F1指数其实就是一回事,但是其实不止有F1指数,根据下式中alpha的不同,实际上是有多种RQ可以选择的。
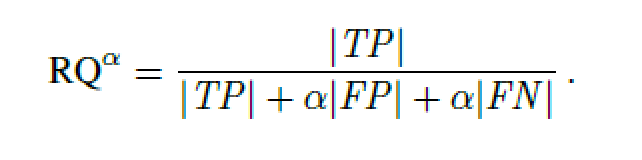
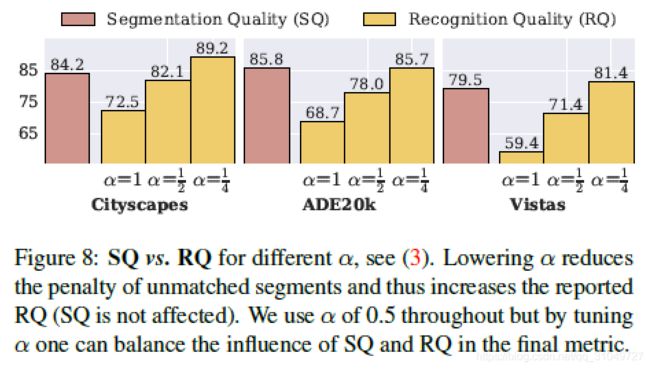
从下图可以看出来,alpha越小,代表FP和FN出现的时候的惩罚越小,自然同样错误的情况下,指标会更高了。
- 算法Baselines:
接下来就很好理解了,就是给这个问题设定一个baseline,最早做这方面工作的人可以跟这个baseline作比较,就像这篇文章最开始说到的,这个baseline很可能是一个sub-optimal的,但是毕竟是挖坑文章,并没人关心你的效果(这么说我也想去挖坑了,可惜我没这能力)。
这篇论文中的方法就是将语义分割和实例分割两个生成的图像做了一个合成,然后再合成的过程中为了能够计算PQ所以需要进行一些处理。
针对实例分割,先要处理里面的目标堆叠问题,所以他们设计了一个类似非极大抑制的操作,先将分割按照置信度从大到小排列,然后从大到小依次去掉和前面已经确定下来的像素重合的区域,去除完毕之后再看这个实例是否和GT中的实例能不能够匹配上(也就是IoU大于阈值),如果匹配上,就认为这个实例有效,否则,就将这个实例丢弃。这样一来就保证最后的输出中是没有像素的overlap的。
至于语义分割,因为语义分割本来就没有目标性,所以不存在overlap的情况,计算PQ的时候可以直接进行计算。
然后将两者的进行一个结合,生成全景分割图像,具体生成步骤如下:首先针对实力分割的预测图,先采取之前说过的类似NMS的步骤去掉overlap,然后再将其和语义分割图进行结合,结合的标准就是预测更倾向于things的类别,如果这个像素是things的类别且有instance id的话那么就把这个像素分配给对应的类别和instance id,如果这个像素只有stuff类别的标签的话,那么就认为这个像素是stuff。
下面给出一些实验结果:
实例分割指标:

语义分割指标:

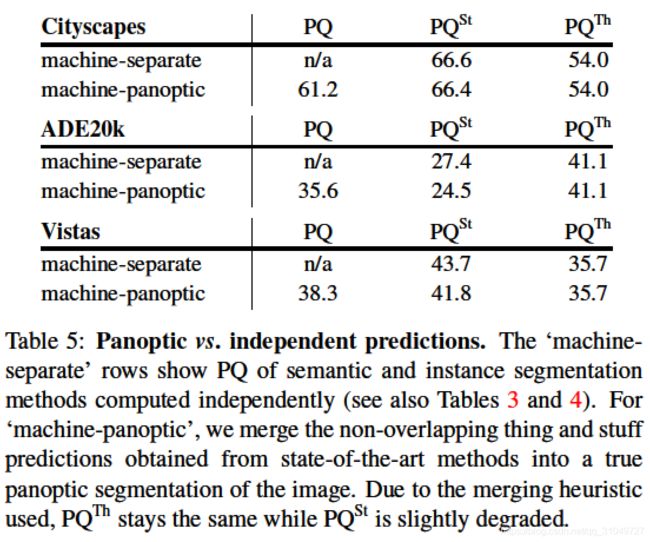
分开计算实例分割和语义分割的指标和用了上面说的方法进行结合之后的全景分割指标,放上来并不能比较好坏,只是给你看一下,因为分开计算的时候根本不存在PQ。
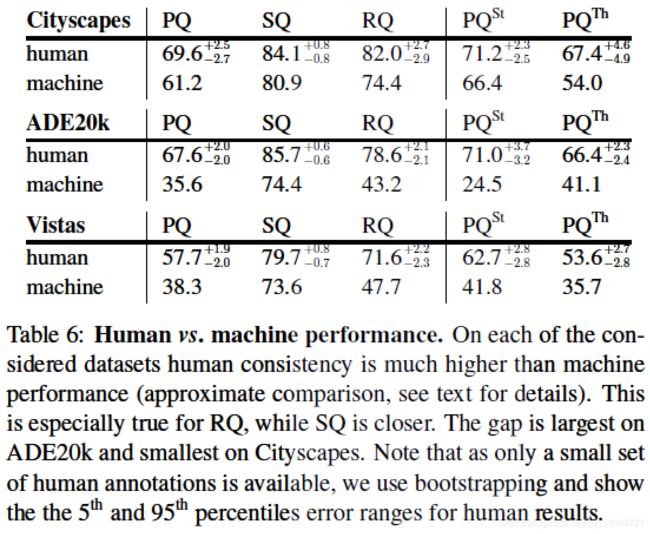
最后就是这个实验了,这个实验告诉我们目前为止,还是人标出来的PQ会高一些,不过也没有比机器高特别多吧,这就会带来一个非常严重的问题:之前也说了,人标注的时候会有不一致性,那如果算法发展到后面,已经完全能够和人工给出来的GT一致了,制约算法发展的就不会是算法本身了,而是数据的质量。所以这个问题还需要我们思考。
- Future of Panoptic Segmentation:
挖了个坑,文章肯定还是要告诉一下大家大概有哪些方面可以做。首先第一个就是一个end-to-end的模型,现在这篇文章还停留在一个启发式方法进行融合的阶段,后面怎么通过网络模型来进行自动融合,这是一个问题。另外,因为全景分割是不存在overlap的,所以一些推理的东西就可以派上用场了,这些推理能够增强理解场景,然后进一步提升全景分割性能(就像上面的NMS方法)。
最后是我自己的总结了,这篇论文是挖坑论文,重点不是在于这篇论文的方法,而是这篇文章给我们介绍的这个问题。首先说我最直观的感受,这个坑挖的还是很符合直觉的,毕竟人在进行场景感知的时候,就不会所有看到的人当成一类东西,而是很清楚的知道这些人是一个一个个体,而到天空等这些stuff的时候,我们就不会这样想。所以我觉得这个坑挖的还是很好很符合实际认知的。
另外,UPSNet的Hengshuang Zhao也在Valse上面讲了一下,然后提到了现在大家做的时候都是在想语义分割和实例分割的预测怎么进行融合,但是为什么没有人专门设计一个全景分割的网络头呢?另外,语义分割和实例分割的confilct究竟是什么呢?这些还没有研究清楚。所以这些也是后面需要思考的一些问题。