JAVA高频面试题
JAVA高频面试题
1. Mybatis运行原理
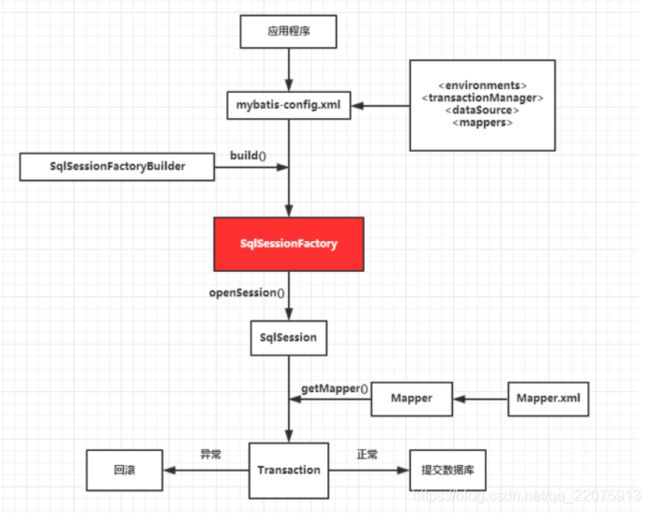 原理:
原理:
- 通过SqlSessionFactoryBuilder从mybatis-config.xml配置文件中构建出SqlSessionFactory。
- SqlSessionFactory开启一个SqlSession,
- 通过SqlSession实例获得Mapper对象并且运行Mapper映射的Sql语句。
- 完成数据库的CRUD操作和事务提交,关闭SqlSession。
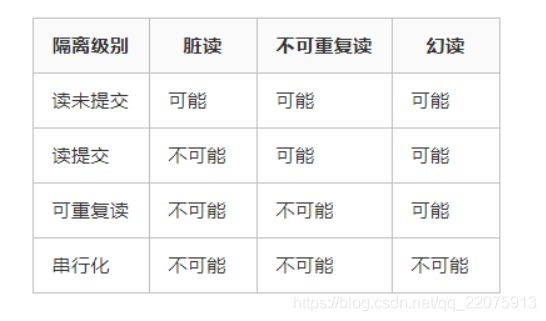
2.事务的隔离级别
-
Read uncommitted 读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。缺点:脏读
-
Read committed 读已提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。一个事务范围内两个相同的查询却返回了不同数据,前后两次查询到不同的数据 缺点:不可重复读
-
Repeatable read 重复读,就是在开始读取数据(事务开启)时,不再允许修改操作 重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
-
Serializable 序列化 Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
3. sql查询优化
-
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
-
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
# 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
-
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
-
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
|# 可以这样查询:
select id from t where num=10
union all
select id from t where num=20
- in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
# 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
- 下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
- 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
# 应改为:
select id from t where name like 'abc%'
- 很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
# 用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
-
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。(合理创建索引,大量数据重复的列不适合创建索引)
-
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率, 因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 -
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
-
尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
-
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
-
避免频繁创建和删除临时表,以减少系统表资源的消耗。
4. 谈谈Spring IOC的理解
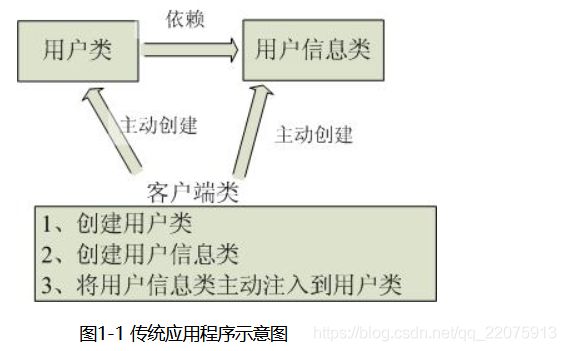
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好Ioc呢?理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
●谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对 象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
●为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
用图例说明一下,传统程序设计如图1-1,都是主动去创建相关对象然后再组合起来:
 当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图2-2所示:
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图2-2所示:

5. 什么是数据库索引?
一、数据索引是干什么用的呢?
- 数据库索引其实就是为了使查询数据效率快。
二、数据库索引有哪些呢?
- 聚集索引(主键索引):在数据库里面,所有行数都会按照主键索引进行排序。
- 非聚集索引:就是给普通字段加上索引。
- 联合索引:就是好几个字段组成的索引,称为联合索引。
key 'idx_age_name_sex' ('age','name','sex')
联合索引遵从最左前缀原则,什么意思呢,就比如说一张学生表里面的联合索引如上面所示,那么下面A,B,C,D,E,F哪个会走索引呢?
A:select * from student where age = 16 and name = '小张'
B:select * from student where name = '小张' and sex = '男'
C:select * from student where name = '小张' and sex = '男' and age = 18
D:select * from student where age > 20 and name = '小张'
E:select * from student where age != 15 and name = '小张'
F:select * from student where age = 15 and name != '小张'
-
A遵从最左匹配原则,age是在最左边,所以A走索引;
-
B直接从name开始,没有遵从最左匹配原则,所以不走索引;
-
C虽然从name开始,但是有索引最左边的age,mysql内部会自动转成where age = ‘18’ and name = ‘小张’ and sex = ‘男’ 这种,所以还是遵从最左匹配原则;
-
D这个是因为age>20是范围,范围字段会结束索引对范围后面索引字段的使用,所以只有走了age这个索引;
-
E这个虽然遵循最左匹配原则,但是不走索引,因为!= 不走索引;
-
F这个只走age索引,不走name索引,原因如上;
三、有哪些列子不走索引呢?
表student中两个字段age,name加了索引
key 'idx_age' ('age'),
key 'idx_name' ('name')
1.Like这种就是%在前面的不走索引,在后面的走索引
A:select * from student where 'name' like '王%'
B:select * from student where 'name' like '%小'
A走索引,B不走索引
2.用索引列进行计算的,不走索引
A:select * from student where age = 10+8
B:select * from student where age + 8 = 18
A走索引,B不走索引
3.对索引列用函数了,不走索引
A:select * from student where concat('name','哈') ='王哈哈';
B:select * from student where name = concat('王哈','哈');
A不走索引,B走索引
- 索引列用了!= 不走索引,如下:
select * from student where age != 18
四、为什么索引用B+树?
什么是B+树呢?在说B+树之前我们先了解一下为什么要有B树,其实这些树最开始都是为了解决某种系统中,查询效率低的问题。B树其实最开始源于的是二叉树,二叉树是只有左右孩子的树,当数据量越大的时候,二叉树的节点越多,那么当从根节点搜索的时候,影响查询效率。所以如果这些节点存储在外存储器中的话,每访问一个节点,相当于进行了一次I/O操作。
这里面说下外存储器和内存储器:
-
外存储器:就是将数据存储到磁盘中,每次查找的某个元素的时候都要取磁盘中查找,然后再写入内存中,容量大,但是查询效率低。
-
内存储器:就是将数据放在内存中,查询快,但是容量小。
我们大致了解了B树和什么是外存储器,内存储器,那么就知道其实B+树就是为了解决数据量大的时候存储在外存储器时候,查找效率低的问题。接下来就说下B+树的特点:
- 中间元素不存数据,只是当索引用,所有数据都保存在叶子结点中。
- 所有的中间节点在子节点中要么是最大的元素要么是最小的元素 。
- 叶子结点包含所有的数据,和指向这些元素的指针,而且叶子结点的元素形成了自小向大这样子的链表。
如下这个图就很好的说明了B+的特点
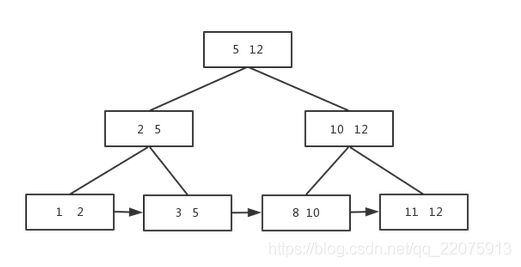
看图其实可以看到一个节点可以存放多个数据,查找一个节点的时候可以有多个元素,大大提升查找效率,这就是为什么数据库索引用的就是B+树,因为索引很大,不可能都放在内存中,所以通常是以索引文件的形式放在磁盘上,所以当查找数据的时候就会有磁盘I/O的消耗,而B+树正可以解决这种问题,减少与磁盘的交互,因为进行一次I/O操作可以得到很多数据,增大查找数据的命中率。
这就可以很明显的看出B+树的优势:
- 单个节点可以存储更多的数据,减少I/O的次数。
- 查找性能更稳定,因为都是要查找到叶子结点。
- 叶子结点形成了有序链表,便于查询。
B+树是怎么进行查找的呢,分为单元素查找和范围查找
单元素查找是从根一直查找到叶子结点,即使中间结点有这个元素也要查到叶子结点,因为中间结点只是索引,不存数据。比如要查元素3,如图:
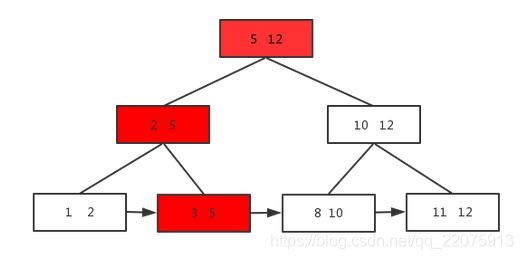 范围查找是直接从链表查,比如要查元素3到元素8的,如图:
范围查找是直接从链表查,比如要查元素3到元素8的,如图:
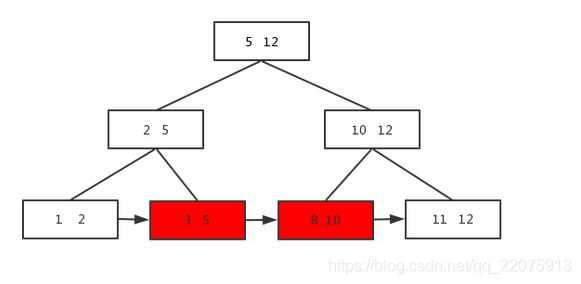 五、索引在磁盘上的存储?
五、索引在磁盘上的存储?
聚集索引和非聚集索引存储的不相同,那么来说下都是怎么存储的?
有一张学生表
create table `student` (
`id` int(11) not null auto_increment comment '主键id',
`name` varchar(50) not null default '' comment '学生姓名',
`age` int(11) not null default 0 comment '学生年龄',
primary key (`id`),
key `idx_age` (`age`),
key `idx_name` (`name`)
) ENGINE=InnoDB default charset=utf8 comment ='学生信息';
表中内容如下
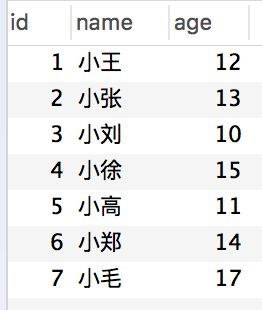
id 为主键索引,name和age为非聚集索引
1.聚集索引在磁盘中的存储
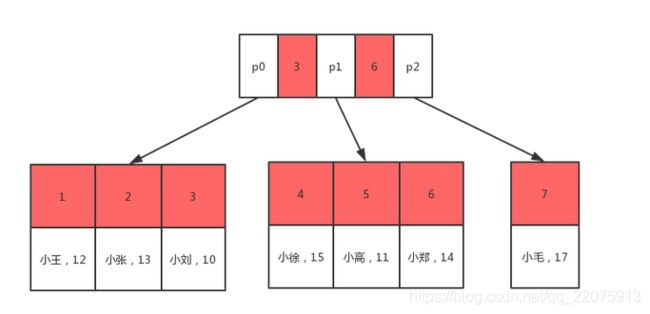 聚集索引叶子结点存储是表里面的所有行数据;
聚集索引叶子结点存储是表里面的所有行数据;
每个数据页在不同的磁盘上面;
如果要查找id=5的数据,那么先把磁盘0读入内存,然后用二分法查找id=5的数在3和6之间,然后通过指针p1查找到磁盘2的地址,然后将磁盘2读入内存中,用二分查找方式查找到id=5的数据。
2.非聚集索引在磁盘中的存储
 叶子结点存储的是聚集索引键,而不存储表里面所有的行数据,所以在查找的时候,只能查找到聚集索引键,再通过聚集索引去表里面查找到数据。
叶子结点存储的是聚集索引键,而不存储表里面所有的行数据,所以在查找的时候,只能查找到聚集索引键,再通过聚集索引去表里面查找到数据。
如果要查找到name = 小徐,首先将磁盘0加载到内存中,然后用二分查找的方法查到在指针p1所指的地址上,然后通过指针p1所指的地址可知道在磁盘2上面,然后通过二分查找法得知小徐id=4;
然后在根据id=4将磁盘0加载到内存中,然后通过二分查找的方法查到在指针p1所指的地址上,然后通过指针p1所指的地址可知道在磁盘2上面,然后通过id=4查找出郑正行数据,就查找出name=小徐的数据了。
6. 如何处理高并发?
- 系统拆分,将一个系统拆分为多个子系统,用dubbo来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,这样就可以抗高并发;
- 缓存,大部分的高并发场景,都是读多写少,读的时候走缓存,redis轻轻松松单机几万的并发;
- MQ(消息队列),将请求灌入mq中,控制在mysql承载范围之内,排队后面系统慢慢写,mq单机抗几万并也是可以的;
- 分库分表,一个库拆分为多个库,多个库来抗更高的并发;一个表拆分为多个表,减少每个表的数据量,提高sql跑的性能;
- 读写分离,可以搞个主从架构读写分离,主库写入,从库读取。流量太多的时候,还可以加更多的从库。
- 垂直升级:单机硬件 CPU,内存
- 水平扩展:加服务器
- 全文检索搜索引擎和页面静态化技术使用
7. Springboot
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
Spring Boot有哪些优点?
- 减少开发,测试时间和努力。
- 使用JavaConfig有助于避免使用XML。
- 避免大量的Maven导入和各种版本冲突。
- 没有单独的Web服务器需要。这意味着你不再需要启动Tomcat,Glassfish或其他任何东西。
- 需要更少的配置 因为没有web.xml文件。
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能:@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
开启 Spring Boot 特性有哪几种方式
- 继承spring-boot-starter-parent项目
- 导入spring-boot-dependencies项目依赖
Spring Boot 需要独立的容器运行吗?
- 可以不需要,内置了 Tomcat/ Jetty 等容器。
8. JAVA基本数据类型

9. 做项目遇到的难点 ,怎么解决这难点
- 数据库与redis缓存的数据一致性
- 问题:在使用了缓存的业务场景中,例如查询用户的可访问资源,在修改数据库中的这些数据时,可能导致用户查出的缓存数据还是旧数据。
解决方式
- 设置redis缓存数据过期时间,修改数据时清除对应的缓存,使用户下次查询直接使用数据库的数据。
- 缓存穿透
- 问题:恶意用户发起攻击,查询一个缓存和数据库中都不存在的数据,造成一直查询数据库导致数据库压力飙升甚至垮掉。
解决方案
- 在数据库中取不到的数据存一个空值到Redis,设置缓存有效时间较短,例如30秒后过期。
3. 分布式锁
问题
- 本系统功能允许一个家庭组中存在多名管理员,所以存在多名管理员同时操作一条数据的可能性,为保证数据的一致性,需要对操作进行加锁处理,微服务中每个服务可能有多个实例,所以存在多个进程的线程操作同一条数据的情况,于是普通单机系统的应用使用的java内存锁不再可靠。
解决方案
分布式锁提供了分布式系统中跨JVM的互斥机制的实现,常用的分布式锁的实现方式有三种:
1、基于数据库实现分布式锁
2、基于缓存(Reids等)实现分布式锁
3、基于Zookeeper实现分布式锁
其中基于数据库的分布式锁实现方式最为简单,但是太过依赖数据库。Redis和Zookeeper中,因为Redis已在本系统中有集成,而且实现起来简单,只要注意Redis实现分布式锁的方式中的几个问题就能做出来一个相对完善的方案。
4. 消息的延迟推送
问题:系统中一条消息推送给客户之后,如果客户没有及时处理需要在间隔一段时间后再发送一次。
解决方案
- 使用RabbitMQ的死信队列实现消息的延迟发送,其实现方式是设置第一个队列的消息存活时间(TTL),此队列不设置消费者,配置交换机,将过期的消息交换(死信交换DLX)到另一个队列,消费者消费此队列,此时距离消息产生就已经过了一段时间,实现了消息的延迟推送。
10.redis数据类型以及应用场景
- String:计算器:文章访问量,每当用户访问,阅读数加,商品库存,分布式锁
- Hash:存储对象 如购物车
- List:微博消息,微博公众号消息
- Set:微信微博点赞,收藏,标签
- SortedSet:排行榜
11.Springmvc的优点、工作流程
优点:
- 轻量级的框架,简单易学
- 与spring的兼容性好
- SpringMvc的功能强大,支持RESTful风格、数据验证等功能
12. equals和==的区别
- ==是判断两个变量或实例是不是指向同一个内存空间,equals是判断两个变量或实例所指向的内存空间的值是不是相同
- ==是指对内存地址进行比较 , equals()是对字符串的内容进行比较
- ==指引用是否相同, equals()指的是值是否相同

13. like关键字能不能匹配到索引
- 后通配 走索引
- 前通配 走全表
14.介绍几种生成分布式自增ID的方法
一、为什么要用分布式ID?
- 在说分布式ID的具体实现之前,我们来简单分析一下为什么用分布式ID?分布式ID应该满足哪些特征?
- 什么是分布式ID?
拿MySQL数据库举个栗子:
在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个MySQL主从同步读写分离也能对付。
但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;特别一点的如订单、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
- 那么分布式ID需要满足哪些条件?
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要快,否则反倒会成为业务瓶颈
- 高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
- 趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
二、 分布式ID都有哪些生成方式?
今天主要分析一下以下9种,分布式ID生成器方式以及优缺点:
- UUID
- 数据库自增ID
- 数据库多主模式
- 号段模式
- Redis
- 雪花算法(SnowFlake)
- 滴滴出品(TinyID)
- 百度 (Uidgenerator)
- 美团(Leaf)
那么它们都是如何实现?以及各自有什么优缺点?我们往下看
1、基于UUID
在Java的世界里,想要得到一个具有唯一性的ID,首先被想到可能就是UUID,毕竟它有着全球唯一的特性。那么UUID可以做分布式ID吗?答案是可以的,但是并不推荐!
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid);
}
UUID的生成简单到只有一行代码,输出结果 c2b8c2b9e46c47e3b30dca3b0d447718,但UUID却并不适用于实际的业务需求。像用作订单号UUID这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;而对于数据库来说用作业务主键ID,它不仅是太长还是字符串,存储性能差查询也很耗时,所以不推荐用作分布式ID。
优点:
- 生成足够简单,本地生成无网络消耗,具有唯一性
缺点:
- 无序的字符串,不具备趋势自增特性
- 没有具体的业务含义
- 长度过长16 字节128位,36位长度的字符串,存储以及查询对MySQL的性能消耗较大,MySQL官方明确建议主键要尽量越短越好,作为数据库主键 UUID 的无序性会导致数据位置频繁变动,严重影响性能。
2、基于数据库自增ID
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;
insert into SEQUENCE_ID(value) VALUES ('values');
当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点:
- 实现简单,ID单调自增,数值类型查询速度快
缺点:
- DB单点存在宕机风险,无法扛住高并发场景
3、基于数据库集群模式
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。
那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、3、5、7、9
2、4、6、8、10
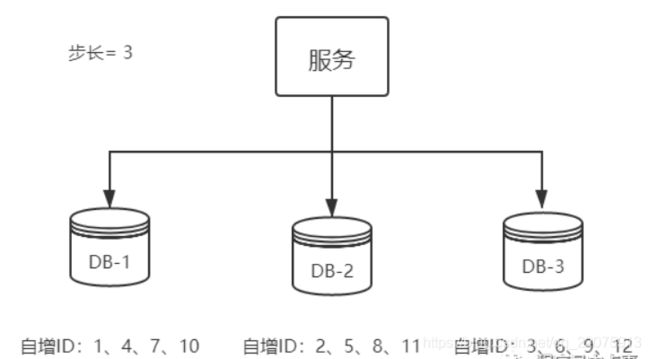
从上图可以看出,水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置。
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:
- 解决DB单点问题
缺点:
- 不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
4、基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的布长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,
update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = #{max_id+step},
version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
5、基于Redis模式
Redis也同样可以实现,原理就是利用redis的 incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
- RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。
- AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
6、基于雪花算法(Snowflake)模式
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。
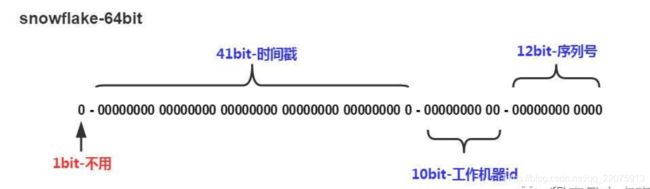 Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
-
第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
-
时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 -
固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 *60 * 24 * 365) = 69年 -
工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
-
序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
Java版本的Snowflake算法实现:
package com.igetcool.teach.mgt.service.impl;
/**
* * Twitter的SnowFlake算法,使用SnowFlake算法生成一个整数,然后转化为62进制变成一个短地址URL * * https://github.com/beyondfengyu/SnowFlake
*/
public class SnowFlakeShortUrl {
/**
* 起始的时间戳
*/
private final static long START_TIMESTAMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATA_CENTER_BIT = 5; //数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private long dataCenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastTimeStamp = -1L; //上一次时间戳
private long getNextMill() {
long mill = getNewTimeStamp();
while (mill <= lastTimeStamp) {
mill = getNewTimeStamp();
}
return mill;
}
private long getNewTimeStamp() {
return System.currentTimeMillis();
}
/**
* 根据指定的数据中心ID和机器标志ID生成指定的序列号 * * @param dataCenterId 数据中心ID * @param machineId 机器标志ID
*/
public SnowFlakeShortUrl(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("DtaCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0!");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("MachineId can't be greater than MAX_MACHINE_NUM or less than 0!");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID * * @return
*/
public synchronized long nextId() {
long currTimeStamp = getNewTimeStamp();
if (currTimeStamp < lastTimeStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currTimeStamp == lastTimeStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currTimeStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT;
//时间戳部分 | dataCenterId << DATA_CENTER_LEFT
// 数据中心部分 | machineId << MACHINE_LEFT
// 机器标识部分 | sequence;
// 序列号部分
}
public static void main(String[] args) {
SnowFlakeShortUrl snowFlake = new SnowFlakeShortUrl(2, 3);
for (int i = 0; i < (1 << 4); i++) {
//10进制
System.out.println(snowFlake.nextId());
}
}
}
15. 线程有几种状态,wait和sleep的区别?
六个状态:
-
新建(New):创建后尚未启动的线程的状态
-
运行(Runnable):包含Running和Ready
-
无限期等待(Waiting):不会被分配CPU执行时间,需要显示被唤醒
- 没有设置Timeout参数的Object.wait()方法
- 没有设置Timeout参数的Thread.join()方法
- LockSupport.park()方法
-
限期等待(Timed Waiting):在一定时间后会由系统自动唤醒
- Thread.sleep()方法
- 设置了Timeout参数的Object.wait()方法
- 设置了Timeout参数的Thread.join()方法
- LockSupport.parkNanos()方法
- LockSupport.parkUntil()方法
-
阻塞(Blocked):等待获取排它锁
-
结束状态(Terminated):已终止线程的状态,线程已经结束执行
 wait和sleep的区别?
wait和sleep的区别?
基本的差别:
- sleep是Thread的方法,wait是Object类中定义的方法
- sleep()方法可以在任何地方使用
- wait()方法只能在synchronized方法或synchronized块中使用
最主要的本质区别:
- Thread.sleep只会让出CPU,不会锁行为的改变
- Object.wait不仅让出CPU,还会释放已经占有的同步资源锁
16.hashmap怎么实现线程安全
- 使用 java.util.Hashtable 类,此类是线程安全的。
- 使用 java.util.concurrent.ConcurrentHashMap,此类是线程安全的。
- 使用 java.util.Collections.synchronizedMap() 方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。
17.Hashtable是线程安全的吗
Hashtable是线程安全的,其实现方式是在对应的方法上加上synchronized关键字,效率不高,不建议使用。目前,如果要使用线程安全的哈希表的话,推荐使用ConcurrentHashMap
18. hashCode() 和 equals() 的区别?
一、hashCode()和equals()是什么?
- hashCode()方法和equals()方法的作用其实一样,在Java里都是用来对比两个对象是否相等一致。
二、hashCode()和equals()的区别
下边从两个角度介绍了他们的区别:一个是性能,一个是可靠性。他们之间的主要区别也基本体现在这里。
1、equals()既然已经能实现对比的功能了,为什么还要hashCode()呢?
因为重写的equals()里一般比较的全面比较复杂,这样效率就比较低,而利用hashCode()进行对比,则只要生成一个hash值进行比较就可以了,效率很高。
2、hashCode()既然效率这么高为什么还要equals()呢?
因为hashCode()并不是完全可靠,有时候不同的对象他们生成的hashcode也会一样(生成hash值得公式可能存在的问题),所以hashCode()只能说是大部分时候可靠,并不是绝对可靠,所以我们可以得出(PS:以下两条结论是重点,很多人面试的时候都说不出来):
- equals()相等的两个对象他们的hashCode()肯定相等,也就是用equals()对比是绝对可靠的。
- hashCode()相等的两个对象他们的equals()不一定相等,也就是hashCode()不是绝对可靠的。
三、hashCode()和equals()使用的注意事项
1、对于需要大量并且快速的对比的话如果都用equals()去做显然效率太低,所以解决方式是,每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equals()去再对比了),如果hashCode()相同,此时再对比他们的equals(),如果equals()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性!
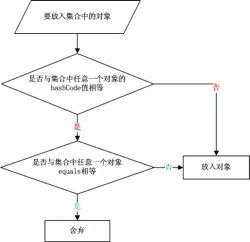
2、这种大量的并且快速的对象对比一般使用的hash容器中,比如HashSet,HashMap,HashTable等等,比如HashSet里要求对象不能重复,则他内部必然要对添加进去的每个对象进行对比,而他的对比规则就是像上面说的那样,先hashCode(),如果hashCode()相同,再用equals()验证,如果hashCode()都不同,则肯定不同,这样对比的效率就很高了。
3、然而hashCode()和equals()一样都是基本类Object里的方法,而和equals()一样,Object里hashCode()里面只是返回当前对象的地址,如果是这样的话,那么我们相同的一个类,new两个对象,由于他们在内存里的地址不同,则他们的hashCode()不同,所以这显然不是我们想要的,所以我们必须重写我们类的hashCode()方法,即一个类,在hashCode()里面返回唯一的一个hash值,比如下面:
class Person{
int num;
String name;
public int hashCode(){
return num*name.hashCode();
}
}
由于标识这个类的是他的内部的变量num和name,所以我们就根据他们返回一个hash值,作为这个类的唯一hash值。
所以如果我们的对象要想放进hashSet,并且发挥hashSet的特性(即不包含一样的对象),则我们就要重写我们类的hashCode()和equals()方法了。像String,Integer等这种类内部都已经重写了这两个方法。
当然如果我们只是平时想对比两个对象 是否一致,则只重写一个equals(),然后利用equals()去对比也行的。
19. session和cookie的区别
1、存储位置不同
- cookie的数据信息存放在客户端浏览器上。
- session的数据信息存放在服务器上。
2、存储容量不同
- 单个cookie保存的数据<=4KB,一个站点最多保存20个Cookie。
- 对于session来说并没有上限,但出于对服务器端的性能考虑,session内不要存放过多的东西,并且设置session删除机制。
3、存储方式不同
- cookie中只能保管ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据。
- session中能够存储任何类型的数据,包括且不限于string,integer,list,map等。
4、隐私策略不同
- cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的。
- session存储在服务器上,对客户端是透明对,不存在敏感信息泄漏的风险。
5、有效期上不同
- 开发可以通过设置cookie的属性,达到使cookie长期有效的效果。
- session依赖于名为JSESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session不能达到长期有效的效果。
6、服务器压力不同
- cookie保管在客户端,不占用服务器资源。对于并发用户十分多的网站,cookie是很好的选择。
- session是保管在服务器端的,每个用户都会产生一个session。假如并发访问的用户十分多,会产生十分多的session,耗费大量的内存。
7、浏览器支持不同
假如客户端浏览器不支持cookie:
- cookie是需要客户端浏览器支持的,假如客户端禁用了cookie,或者不支持cookie,则会话跟踪会失效。关于WAP上的应用,常规的cookie就派不上用场了。
- 运用session需要使用URL地址重写的方式。一切用到session程序的URL都要进行URL地址重写,否则session会话跟踪还会失效。
假如客户端支持cookie:
- cookie既能够设为本浏览器窗口以及子窗口内有效,也能够设为一切窗口内有效。
- session只能在本窗口以及子窗口内有效。
8、跨域支持上不同
- cookie支持跨域名访问。
- session不支持跨域名访问。
20. hashmap底层原理
HashMap是基于hash原理的。通过put()和get()方法获得和存储对象。当进行put()方法时,先通过key的hashCode()方法计算出hashCode,通过indexFor(hashCode,length)方法得到对象存储于table中的下标位置,也就是找到bucked的位置用来存储Entry。
JDK7中使用的是数组+链表的结构。JDK8中使用的是数组+链表+红黑树,在链表长度大于8时转为红黑树。
数组的优点:易查找,不易进行增加修改操作。(通过下标查找)
链表的优点:易进行增加修改,不易进行查找。(通过遍历查找)
21. 事务有哪些特性,如何手动操作事务?
事务有哪些特性?
在 MySQL 中只有 InnDB 引擎支持事务,它的四个特性如下:
原子性(Atomic):要么全部执行,要么全部不执行;
一致性(Consistency):事务的执行使得数据库从一种正确状态转化为另一种正确状态;
隔离性(Isolation):在事务正确提交之前,不允许把该事务对数据的任何改变提供给其他事务;
持久性(Durability):事务提交后,其结果永久保存在数据库中。
如何手动操作事务?
使用 begin 开启事务;rollback 回滚事务;commit 提交事务。具体使用示例如下:
begin;
insert person(uname,age) values('laowang',18);
rollback;
commit;
22. 分布式session问题
Session的作用?
- Session 是客户端与服务器通讯会话跟踪技术,服务器与客户端保持整个通讯的会话基本信息。
客户端在第一次访问服务端的时候,服务端会响应一个sessionId并且将它存入到本地cookie中,在之后的访问会将cookie中的sessionId放入到请求头中去访问服务器,如果通过这个sessionid没有找到对应的数据那么服务器会创建一个新的sessionid并且响应给客户端。
 分布式Session存在的问题?
分布式Session存在的问题?
假设第一次访问服务A生成一个sessionid并且存入cookie中,第二次却访问服务B客户端会在cookie中读取sessionid加入到请求头中,如果在服务B通过sessionid没有找到对应的数据那么它创建一个新的并且将sessionid返回给客户端,这样并不能共享我们的Session无法达到我们想要的目的。
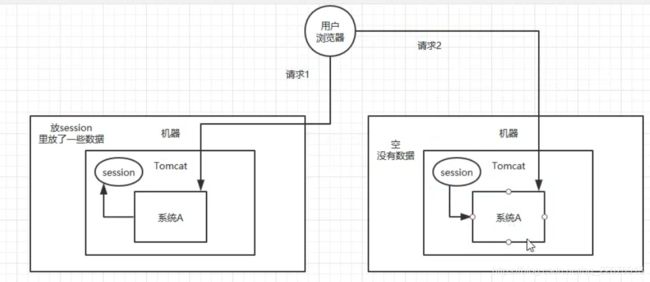 4种分布式session解决方案
4种分布式session解决方案
方案一:客户端存储
直接将信息存储在cookie中
cookie是存储在客户端上的一小段数据,客户端通过http协议和服务器进行cookie交互,通常用来存储一些不敏感信息
缺点:
- 数据存储在客户端,存在安全隐患
- cookie存储大小、类型存在限制
- 数据存储在cookie中,如果一次请求cookie过大,会给网络增加更大的开销
方案二:session复制
session复制是小型企业应用使用较多的一种服务器集群session管理机制,在真正的开发使用的并不是很多,通过对web服务器(例如Tomcat)进行搭建集群。
存在的问题:
session同步的原理是在同一个局域网里面通过发送广播来异步同步session的,一旦服务器多了,并发上来了,session需要同步的数据量就大了,需要将其他服务器上的session全部同步到本服务器上,会带来一定的网路开销,在用户量特别大的时候,会出现内存不足的情况
优点:
- 服务器之间的session信息都是同步的,任何一台服务器宕机的时候不会影响另外服务器中session的状态,配置相对简单
- Tomcat内部已经支持分布式架构开发管理机制,可以对tomcat修改配置来支持session复制,在集群中的几台服务器之间同步session对象,使每台服务器上都保存了所有用户的session信息,这样任何一台本机宕机都不会导致session数据的丢失,而服务器使用session时,也只需要在本机获取即可
如何配置:
在Tomcat安装目录下的config目录中的server.xml文件中,将注释打开,tomcat必须在同一个网关内,要不然收不到广播,同步不了session
在web.xml中开启session复制:< distributable/>
方案三:session绑定:
Nginx介绍:
- Nginx是一款自由的、开源的、高性能的http服务器和反向代理服务器
Nginx能做什么:
- 反向代理、负载均衡、http服务器(动静代理)、正向代理
如何使用nginx进行session绑定
- 我们利用nginx的反向代理和负载均衡,之前是客户端会被分配到其中一台服务器进行处理,具体分配到哪台服务器进行处理还得看服务器的负载均衡算法(轮询、随机、ip-hash、权重等),但是我们可以基于nginx的ip-hash策略,可以对客户端和服务器进行绑定,同一个客户端就只能访问该服务器,无论客户端发送多少次请求都被同一个服务器处理
在nginx安装目录下的conf目录中的nginx.conf文件
upstream aaa {
Ip_hash;
server 39.105.59.4:8080;
Server 39.105.59.4:8081;
}
server {
listen 80;
server_name www.wanyingjing.cn;
#root /usr/local/nginx/html;
#index index.html index.htm;
location / {
proxy_pass http:39.105.59.4;
index index.html index.htm;
}
}
缺点:
- 容易造成单点故障,如果有一台服务器宕机,那么该台服务器上的session信息将会丢失
- 前端不能有负载均衡,如果有,session绑定将会出问题
优点:
- 配置简单
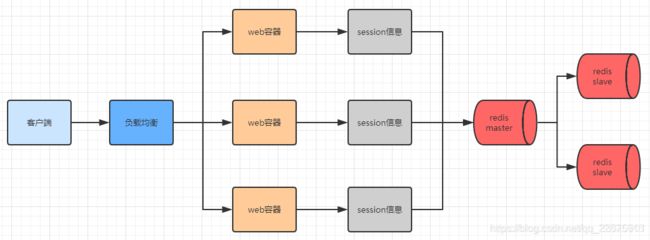
方案四:基于redis存储session方案
基于redis存储session方案流程示意图
 引入pom依赖:
引入pom依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-session-data-redisartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-data-starter-redisartifactId>
dependency>
配置redis
#redis数据库索引(默认是0)
spring.redis.database=0
spring.redis.host=127.0.0.1
spring.redis.port=6379
#默认密码为空
spring.redis.password=
#连接池最大连接数(负数表示没有限制)
spring.redis.jedis.pool.max-active=1000
#连接池最大阻塞等待时间(负数表示没有限制)
spring.redis.jedis.pool.max-wait=-1ms
#连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=10
#连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=2
#连接超时时间(毫秒)
spring.redis.timeout=500ms
优点:
- 这是企业中使用的最多的一种方式
- spring为我们封装好了spring-session,直接引入依赖即可
- 数据保存在redis中,无缝接入,不存在任何安全隐患
- redis自身可做集群,搭建主从,同时方便管理
缺点:
- 多了一次网络调用,web容器需要向redis访问
总结:
- 一般会将web容器所在的服务器和redis所在的服务器放在同一个机房,减少网络开销,走内网进行连接
23. jdk1.8的新特性
Lambda表达式、方法引用和默认方法
- Lambda表达式
Lambda表达式允许把函数作为一个方法的参数。
有几种常见的Lambda表达式:
// 1. 不需要参数,返回值为 5
() -> 5
// 2. 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 3. 接受2个参数(数字),并返回他们的差值
(x, y) -> x – y
// 4. 接收2个int型整数,返回他们的和
(int x, int y) -> x + y
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> System.out.print(s)
- 方法引用
JDK8支持了四种方式方法引用
- 类型方法引用 引用静态方法 ContainingClass::staticMethodName
- 引用特定对象的实例方法containingObject::instanceMethodName
- 引用特定类型的任意对象的实例方法String::compareToIngoreCase
- 引用构造函数ClassName::new
- 默认方法和静态方法
JDK1.8支持在接口中定义默认方法和静态方法, 默认方法可以被接口实现引用。
package defaultmethods;
import java.time.*;
public interface TimeClient {
void setTime(int hour, int minute, int second);
void setDate(int day, int month, int year);
void setDateAndTime(int day, int month, int year,
int hour, int minute, int second);
LocalDateTime getLocalDateTime();
// 静态方法
static ZoneId getZoneId (String zoneString) {
try {
return ZoneId.of(zoneString);
} catch (DateTimeException e) {
System.err.println("Invalid time zone: " + zoneString +
"; using default time zone instead.");
return ZoneId.systemDefault();
}
}
// 默认方法
default ZonedDateTime getZonedDateTime(String zoneString) {
return ZonedDateTime.of(getLocalDateTime(), getZoneId(zoneString));
}
}
24, redis缓存穿透及解决方案
- 缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案:如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//数据库查询不到,为空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果发现为空,设置个默认值,也缓存起来
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}
25,单例模式的理解
单例模式特点(什么是单例模式)?
- a.单例类只能有一个实例。
- b.单例类必须自己创建自己的唯一实例。
- c.单例类必须给所有其他对象提供这一实例。
(2)单例模式的作用(用单例模式的目的)?
- Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
(3)一般Singleton模式通常有几种种形式:
通常有3中形式(回答2种的也对,因为第3种不常见)
第一种形式: 饿汉式单例类
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton {
private Singleton(){
}
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
}
第二种形式:懒汉式单例类
public class Singleton {
private Singleton(){
}
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
if (instance==null)instance=new Singleton();
return instance;
}
}
第三种形式:登记式单例(省略)
(4)哪一种模式更安全?为什么?
第一种形式要更加安全些
- instance = new Singleton();
- static属于类的资源,类资源在jvm加载类的时候就加载好了,instance一直引用这new Singleton() ,所以永远都不会释放一直存在与内存中直到程序结束运行
第2种的话如果两个线程同一时刻去访问getInstance的时候就可能创建两个实例,所以不安全
解决办法(加上同步锁)
26,Spring声明式事务
只要定义为spring的bean就可以对里面的方法使用@Transactional注解。
所谓事务传播行为就是多个事务方法相互调用时,事务如何在这些方法间传播。
- PROPAGATION_REQUIRED: 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。
项目的常用的方法**:增加,删除,更新方法**!
- PROPAGATION_SUPPORTS: 支持当前事务,如果当前没有事务,就以非事务方式执行。
项目的常用的方法:查询方法
27, Spring常用注解
在具体介绍IoC和AOP之前,我们先简要说明下Spring常用注解
1、@Controller:用于标注控制器层组件
2、@Service:用于标注业务层组件
3、@Component : 用于标注这是一个受 Spring 管理的组件,组件引用名称是类名,第一个字母小写。可以使用@Component(“beanID”) 指定组件的名称
4、@Repository:用于标注数据访问组件,即DAO组件
5、@Bean:方法级别的注解,主要用在@Configuration和@Component注解的类里,@Bean注解的方法会产生一个Bean对象,该对象由Spring管理并放到IoC容器中。引用名称是方法名,也可以用@Bean(name = “beanID”)指定组件名
6、@Scope(“prototype”):将组件的范围设置为原型的(即多例)。保证每一个请求有一个单独的action来处理,避免action的线程问题。
由于Spring默认是单例的,只会创建一个action对象,每次访问都是同一个对象,不会产生并发问题。
7、@Autowired:默认按类型进行自动装配。在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。
8、@Resource:默认按名称进行自动装配,当找不到与名称匹配的Bean时会按类型装配。
28,SpringIoc和Aop底层原理
一、Ioc 通过Spring配置来创建对象,而不是new的方式
两种方法:配置文件,注解
1.Ioc底层原理
(1)xml配置文件
(2)dom4j解析
(3)工厂设计模式
(4)反射
步骤:
第一步:创建类的.xml文件
<bean id="userService" class="....."/>
第二步:创建一个工厂类:使用dom4j解析配置文件+反射
public class UserFactory{
public static UserService getUserService(){
//使用dom4j解析配置文件
//根据id值获得class的属性值
String classValue="class属性值";
//使用反射来创建class对象
Class class=Class.forName(classValue);
UserService service=class.newInstatnce();
return service;
}
}
 通过IOC,我们如果改掉UserService类,只需更改bean里面的配置属性就行了,降低了类之间的耦合度
通过IOC,我们如果改掉UserService类,只需更改bean里面的配置属性就行了,降低了类之间的耦合度
2.Ioc和DI的区别:
(1)Ioc:控制反转,把创建对象交给Spring进行配置
(2)DI:依赖注入,向类里面的属性中设置值
(3)二者关系:DI不能单独存在,要在Ioc基础之上来完成操作,即要先创建对象才能注入属性值。
二、Aop:面向切面,扩展功能时不通过源代码,横向抽取机制。
底层使用动态代理方式—增强方法
具体分两种情况:
(1)有接口的情况:创建接口的实现类的代理对象,jdk动态代理
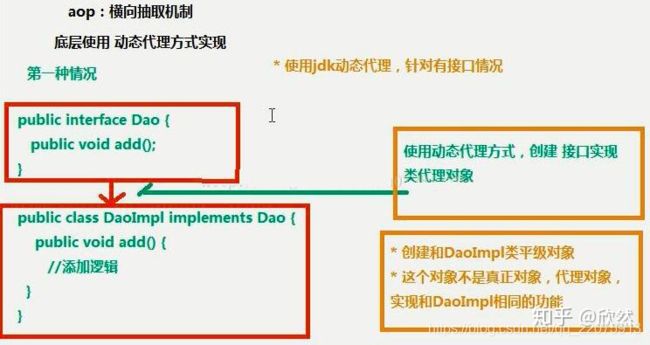
(2)没有接口的情况:创建User类的子类的代理对象,cglib动态代理。子类可以通过super调用父类方法
 增强:before,after,(前置,后置,异常,最终,环绕增强)
增强:before,after,(前置,后置,异常,最终,环绕增强)