机器学习之投毒攻击
1.投毒攻击
如果机器学习模型是根据潜在不可信来源的数据(例如Yelp、Twitter等)进行训练的话,攻击者很容易通过将精心制作的样本插入训练集中来操纵训练数据分布,以达到改变模型行为和降低模型性能的目的.这种类型的攻击被称为“数据投毒”(Data Poisoning)攻击,它不仅在学术界受到广泛关注,在工业界也带来了严重危害.例如微软Tay,一个旨在与Twitter用户交谈的聊天机器人,仅在16个小时后被关闭,只因为它在受到投毒攻击后开始提出种族主义相关的评论.这种攻击令我们不得不重新思考机器学习模型的安全
上一个实验(机器学习之逃逸攻击)我们学习了针对机器学习模型在预测阶段的逃避攻击,本次实验我们将会学习投毒攻击。
机器学习模型除了预测阶段容易受到对抗样例攻击之外,其训练过程本身也可能遭到攻击者攻击.特别地,如果机器学习模型是根据潜在不可信来源的数据(例如Yelp、Twitter等)进行训练的话,攻击者很容易通过将精心制作的样本插入训练集中来操纵训练数据分布,以达到改变模型行为和降低模型性能的目的.这种类型的攻击被称为“数据投毒”(Data Poisoning)攻击,它不仅在学术界受到广泛关注,在工业界也带来了严重危害.例如微软Tay,一个旨在与Twitter用户交谈的聊天机器人,仅在16个小时后被关闭,只因为它在受到投毒攻击后开始提出种族主义相关的评论.这种攻击令我们不得不重新思考机器学习模型的安全性。
下图是以小冰为例,它通过庞大的语料库来学习,还会将用户和它的对话数据收纳进自己的语料库里,因此攻击者也可以在和它们对话时进行“调教”,从而实现让其说脏话甚至发表敏感言论的目的

最早关于投毒攻击的研究可追溯到Newsome等人设计了一种攻击来误导检测恶意软件中的签名生成.Nelson等人表明,通过在训练阶段学习包含正面词汇的垃圾邮件,可以误训练垃圾邮件过滤器,从而使其在推理阶段将合法电子邮件误分类为垃圾邮件.Rubinstein等人[9]展示了如何通过注入干扰来毒害在网络传输上训练的异常探测器.Xiao等人研究了LASSO、岭回归(Ridge Regression)和弹性网络(Elastic Net)三种特征选择算法对投毒攻击的鲁棒性.在恶意软件检测任务上的结果表明,特征选择方法在受到投毒攻击的情况下可能会受到严重影响,例如毒害少于5%的训练样本就可以将LASSO选择的特征集减弱到几乎等同于随机选择的特征集.
Mei等人证明了最优投毒攻击可以表述为一个双层优化问题,并且对于某些具有库恩塔克(Karush-Kuhn-Tucker,KKT)条件的机器学习算法(例如支持向量机、逻辑回归和线性回归),利用隐函数的梯度方法可以有效地解决这一问题.Alfeld等人针对线性自回归模型提出了一个通用的数学框架,用于制定各种目标、成本和约束条件下的投毒攻击策略.Jagielski等人对线性回归模型的投毒攻击及其防御方法进行了系统研究,并提出了一个特定于线性回归模型设计的理论基础优化框架.除了传统的机器学习模型之外,投毒攻击还被扩展至深度神经网络、强化学习、生物识别系统[15]以及推荐系统等。Muñoz-González等人提出了一种基于梯度优化思想的投毒攻击算法,大大降低了攻击复杂度.Suciu等人提出了StringRay,这种方法不仅在四种分类任务上成功地实现了定向投毒攻击,同时能够绕过两种现有的防御机制。

最近,备受学界关注的“后门攻击(Backdoor Attack)”或“木马攻击(Trojan Attack)”就是一种危害性更大的投毒攻击,它使攻击者能够将“后门”或“木马”植入到模型中,并在预测阶段通过简单的后门触发器完成恶意攻击行为.被植入“后门”的深度神经网络在正常样本上表现很好,但会对具有特定后门触发器的输入样本做出特定的错误预测.“后门”可以无限期地保持隐藏直到被带有特定后门触发器的样本激活,隐蔽性极强,因而有可能给许多安全相关的应用(例如生物识别认证系统或自动驾驶汽车)带来严重的安全风险。例如,Gu等人通过将带有特殊标签(即后门触发器)的“停车”标志图像插入训练集中并标记为“速度限制”以在路标识别模型中生成后门.该模型虽然可以正确地分类正常街道标志,但会对拥有后面触发器的恶意停车标志产生错误的分类.因此,通过执行此攻击,攻击者可以通过在模型上贴上标签来欺骗模型,将任何停车标志归类为速度限制,从而给自动驾驶汽车带来严重的安全隐患.虽然后门攻击和对抗样例攻击都会导致模型误分类,但对抗样例的扰动特定于输入和模型,而后门攻击则可以使攻击者能够选择最方便用于触发错误分类的任何扰动(例如,在停止标志上贴标签).
如上图所示,为停车标志及其受后门攻击的版本,后门触发器(从左到右)为黄色方块、炸弹和花朵
一句话来概括投毒攻击,即攻击者通过篡改训练数据或添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性.
接下来进入本次实验的实践阶段。
首先是样本生成
![]()
这里我们生成的数据集包含200个样本,2个特征
我们将使用前100个样本来训练模型,后100个样本用于进行可视化表述模型是否训练得足够好
在我们的实验中,我们会使用MLP训练该数据集。MLP是一种简单的前馈神经网络,可以创建非线性决策边界。
![]()
为了检查发生了什么,我们对模型的决策函数进行可视化。我们在输入空间中创建一个二维网格点(X和y在-3到3之间,每个相邻点之间的间隔为0.01),然后提取此网格中每个点的预测概率。

然后我们根据这些信息生成一个轮廓图并覆盖测试集,图中纵轴显示X1,横轴显示X0

测试结果如下
Python3 1.py得到下图

可以看到MLP分类器的决策函数轮廓图基本拟合了我们的数据集(红点基本在红色阴影的部分,蓝点基本在蓝色阴影的部分)
在这里我们是以0.5的置信度阈值作为决策边界,也就是说,如果分类器预测P(y=1)>0.5,则预测y=1;否则预测y=0
接着我们定义一个效用函数plot_decision_boundary()来绘制这个决策边界
Python3 2.py
得到下图

接下来就进行数据投毒,即添加恶意数据来影响模型训练过程,最终降低其在预测阶段的准确性。我们生成5个点,相当于占训练集的5%

并绘图
![]()
Python3 add.py
得到下图

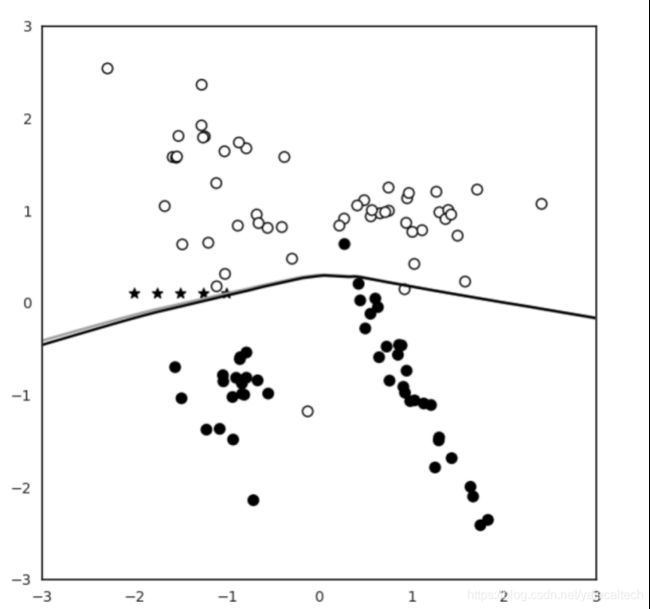
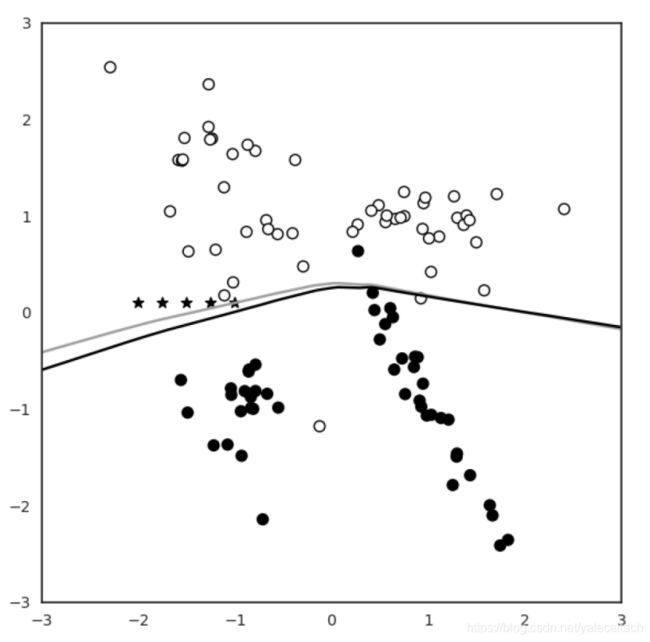
可以看到在目前的添加的5个点(由五角星表示)在y=1的空间(y=1由空心的圆圈表示,y=0由实心的圆圈表示)
接下来我们模拟攻击者动态地、增量地攻击机器学习模型,我们使用scikit-learning的partial_fit()API进行增量学习。我们通过将模型部分拟合到我们新增的5个点来递增地训练现有的分类器
![]()
这样分类器就会用这个新的恶意信息进行更新,我们看看更新后的决策边界发生了什么变化
使用Python3 3.py测试
得到下图
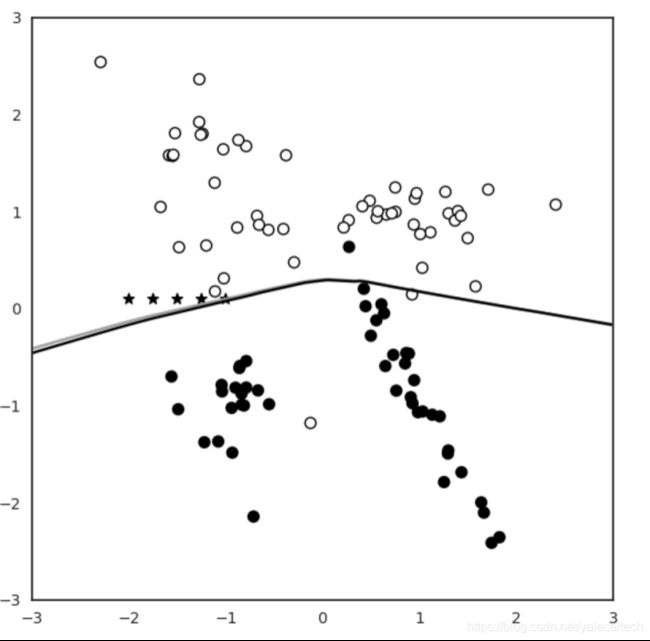
注意到此时多了一条灰色的线,这就是新的决策边界,我们注意到此时已经有偏移了。通过这次偏移,原先位于两个决策边界的之间的本应归类为y=0的部分,现在都会被归类为y=1.
说明攻击者已经成功导致样本进行针对性地错误分类。
当然,这还不是很明显。我们可以重复5次,为了呈现一个动态的效果,当使用python3 4.py测试时会连续打印出5张图
依次如下
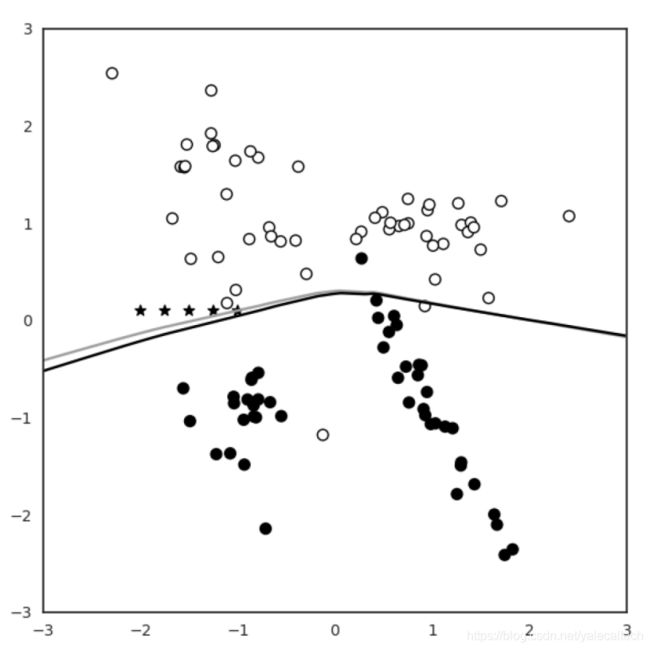
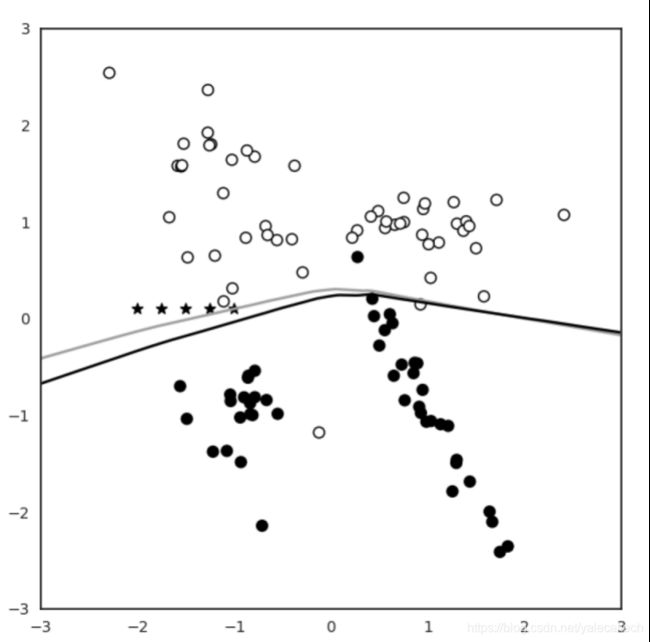

可以看到随着迭代地重复使用partial_fit(),新的边界偏移地越来越多
我们这里直接重复15次,进行测试python3 5.py
打印出了下图

注意上图中红色箭头指向的点,在原决策边界下应归类为y=1,但是在当前的决策边界下,被归类为了y=0。这样攻击者就通过数据投毒成功对机器学习模型进行了攻击。
那么对于这种攻击方式,有什么防御措施呢?
大多数针对投毒攻击的防御机制依赖于一个事实,即投毒样本通常在预期输入分布之外.因此,投毒样本可被视为异常值,并且可以使用数据清理(即攻击检测和删除)和鲁棒学习(即基于对边远训练样本本质上不太敏感的鲁棒统计的学习算法)来净化训练样本.
鲁棒学习.Rubinstein等人利用稳健统计的知识构建了一个基于主成分分析(Principal Component Analysis,PCA)的投毒攻击检测模型.为了限制异常值对训练分布的影响,该检测模型约束PCA算法搜索一个特定方向,该方向的投影最大化了基于鲁棒投影跟踪估计的单变量离散度量,而不是标准偏差.Liu等人假设特征矩阵可以很好地用低秩矩阵来近似,并在此基础上集成了稳健低秩矩阵近似和稳健主成分回归方法用于稳健回归.受稳健统计中利用修剪损失函数来提高鲁棒性这一做法的启发,Jagielski等人提出了一种名为TRIM的针对回归模型的防御方法,并提供关于其收敛的正式保证以及在实际部署时投毒攻击影响的上限.在每次迭代中,TRIM使用具有最低残差的子集计算修剪版的损失函数.本质上,这种方法是在对抗环境中应用经过修正的优化技术进行正则化线性回归.
数据清理.Shen等人针对不能接触到所有训练数据的间接协作学习系统提出了相应的防御方法Auror,这种方法首先识别与攻击策略对应的相关掩蔽特征(Masked Features),然后基于掩蔽特征的异常分布来检测恶意用户.Steindhardt等人尝试在训练模型之前检测并剔除异常值来防御投毒攻击,并在经验风险最小化的情况下,得出了任意投毒攻击影响的近似上限.Baracaldo等人利用tamper-free provenance框架提出利用训练集中原始和变换后数据点的上下文信息来识别有毒数据,从而实现在潜在的对抗性环境中在线和定期重新训练机器学习模型.Zhang等人提出一种利用一小部分可信样本来检测整个训练集中的恶意样本的算法(DUTI).具体地,该方法寻求针对训练集标签的最小更改集,以便从该校正训练集学习的模型能正确地预测可信样本的标签.最后,该方法将标签被更改的样本就被标记为潜在的恶意样本,以提供给领域专家人工审核.
后门攻击检测.模型后门攻击检测极具挑战性,因为只有当存在后门触发器时才会触发恶意行为,而后门触发器在没有进一步分析的情况下通常只有攻击者知道.因此,无论是提供训练数据的用户还是提供预训练模型的用户,都无法保证其基于机器学习模型的相关操作的安全性.为解决这一挑战,Chen等人提出了激活聚类(Activation Clustering, AC)方法,用于检测被植入后门触发器的训练样本.该方法通过分析训练数据的神经网络激活状态,以确定它是否遭受后门攻击以及哪些数据样本是恶意的.Wang等人提出了针对深度神经网络后门攻击的检测系统,利用输入过滤、神经元修剪和unlearning等方法能够识别深度神经网络中是否存在“后门”并重建可能的后门触发器,从而保证模型在实际部署应用中的安全性
参考
1.《机器学习模型安全与隐私研究综述》
2.https://flashgene.com/archives/118300.html